




Exploring Three Key Strategies for Building Efficient Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is a useful technique for using your own data in an AI-powered Chatbot. In this blog post, I'll walk you through three key strategies to get the most out of RAG:
Smart Text Chunking 📦:
- The first step is to break down your text data into meaningful, manageable chunks. This step ensures that your Vector Database can retrieve the most relevant information quickly and accurately.
Iterating on Different Embedding Models 🔍:
- Iterating on the embedding model is crucial. The embedding model determines how your data is represented as vectors. Vectors are the lingua franca of AI, enhancing how the Vector Database can retrieve the right pieces of information.
Experimenting with Different LLMs or Generative Models 🧪:
- Each Language Model (LLM) API has different costs, latencies, and accuracies. Testing them allows you to choose the one that best works for your workload.
Let's dive in and explore how these strategies work and how you can identify the best-performing configurations for your real-world RAG applications with evaluations! 🚀📚
Smart Text Chunking
Text chunking is like cutting a long story into smaller, bite-sized pieces so a computer can easily find and use the most important parts when answering questions or helping with tasks.
Below, I’ll explain a few different techniques. These techniques are nicely explained in-depth in this original article by Greg Kamradt.
Recursive Character Text Splitting 🔄:
- Breaking text into chunks based on character count ensures each piece is manageable and coherent.
Small-to-Big Text Splitting 📏:
- Starting with larger chunks and progressively breaking them down into smaller ones. Search using small, but retrieve using Big.
Semantic Text Splitting 🧠:
- Dividing text based on meaning so that each chunk represents a complete idea or topic, ensuring that the context is preserved.
These methods will help you organize and retrieve text effectively for various applications. Dive in to explore how each technique works!
Recursive Character Text Splitting 🔄
Start by splitting text into fixed-size chunks with fixed-size overlap using LangChain’s RecursiveCharacterTextSplitter.
from langchain.text_splitter import RecursiveCharacterTextSplitter
CHUNK_SIZE = 512
chunk_overlap = np.round(CHUNK_SIZE * 0.10, 0)
print(f"chunk_size: {CHUNK_SIZE}, chunk_overlap: {chunk_overlap}")
# The splitter to use to create smaller (child) chunks.
child_text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=chunk_overlap,
length_function = len, # use built-in Python len function
separators = ["\n\n", "\n", " ", ". ", ""], # defaults
)
# Child docs directly from raw docs
sub_docs = child_text_splitter.split_documents(docs)
# Inspect chunk lengths
print(f"{len(docs)} docs split into {len(sub_docs)} child documents.")
plot_chunk_lengths(sub_docs, 'Recursive Character')

Image by author: Matplotlib plot of RecursiveCharacterTextSplitter chunk lengths, full code available on GitHub.
Small-to-Big Text Splitting 📏
This technique searches using small (child) chunks but retrieves using big (parent) chunks of text. Two memory stores are used: 1) doc storage and 2) vector storage. The code below uses LangChain’s MultiVectorRetriever.
from langchain_milvus import Milvus
from langchain.text_splitter import RecursiveCharacterTextSplitter
import uuid
from langchain.storage import InMemoryByteStore
from langchain.retrievers.multi_vector import MultiVectorRetriever
# Create doc storage for the parent documents
store = InMemoryByteStore()
id_key = "doc_id"
# Create vectorstore for vector index and retrieval.
COLLECTION_NAME = "MilvusDocs"
vectorstore = Milvus(
collection_name=COLLECTION_NAME,
embedding_function=embed_model,
connection_args={"uri": "./milvus_demo.db"},
auto_id=True,
# Set to True to drop the existing collection if it exists.
drop_old=True,
)
# The MultiVectorRetriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
PARENT_CHUNK_SIZE = 1586
# The splitter to use to create bigger (parent) chunks
parent_text_splitter = RecursiveCharacterTextSplitter(
chunk_size=PARENT_CHUNK_SIZE,
length_function = len, # use built-in Python len function
# separators=["\n\n"], # split at end of paragraphs
)
# Parent docs directly from raw docs
parent_docs = parent_text_splitter.split_documents(docs)
doc_ids = [str(uuid.uuid4()) for _ in parent_docs]
# Inspect chunk lengths
print(f"{len(docs)} docs split into {len(parent_docs)} parent documents.")
plot_chunk_lengths(parent_docs, 'Parent')


CHUNK_SIZE = 512
chunk_overlap = np.round(CHUNK_SIZE * 0.10, 0)
print(f"chunk_size: {CHUNK_SIZE}, chunk_overlap: {chunk_overlap}")
# The splitter to use to create smaller (child) chunks.
child_text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=chunk_overlap,
length_function = len, # use built-in Python len function
separators = ["\n\n", "\n", " ", ". ", ""], # defaults
)
# Child docs directly from parent docs
sub_docs = child_text_splitter.split_documents(parent_docs)
# Inspect chunk lengths
print(f"{len(docs)} docs split into {len(sub_docs)} child documents.")
plot_chunk_lengths(sub_docs, 'Small-to-big')

 small-to-big chunking.png
small-to-big chunking.png
Image by author: Matplotlib plot of small-to-big chunk lengths; full code is available on github.
Semantic Text Splitting 🧠
This chunker works by determining when to "break" apart sentences. It does this task by calculating cosine distances between adjacent sentences. Looking across all these cosine distances, it looks for outlier distances past some threshold. These outlier distances determine when chunks are split.
There are a few ways to determine that threshold, which are controlled by the breakpoint_threshold_type kwarg.
from langchain_experimental.text_splitter import SemanticChunker
semantic_docs = []
for doc in docs:
# Extract and clean document content.
cleaned_content = clean_text(doc.page_content)
# Initialize the SemanticChunker with the embedding model.
text_splitter = SemanticChunker(embed_model)
semantic_list = text_splitter.create_documents([cleaned_content])
# Append the list of semantic chunks to semantic_docs.
semantic_docs.extend(semantic_list)
# Inspect chunk lengths
print(f"Created {len(semantic_docs)} semantic documents from {len(docs)}.")
plot_chunk_lengths(semantic_docs, 'Semantic')

We will use the Milvus documentation as our data and Ragas as the evaluation method for your RAG. Read my blog about how to use RAGAS.
Result was:
- Chunking Method = Recursive Character Text Splitter with top_k=2 was the best.
Different Embedding Models
Fixing the chunking method to Recursive Character Text Splitter with top_k=2, I tried two different Embedding models.
BAAI/bge-large-en-v1.5
Text-embedding-3-small with embedding-dim = 512
Using Milvus docs and evaluation method Ragas, the result was:
- Embedding model = BAAI/bge-large-en-v1.5 was the best.

Different LLMs
After fixing the chunking method to be a Recursive Character Text Splitter with top_k=2 and the Embedding model to be BAAI/bge-large-en-v1.5, I tried six different LLM API endpoints.
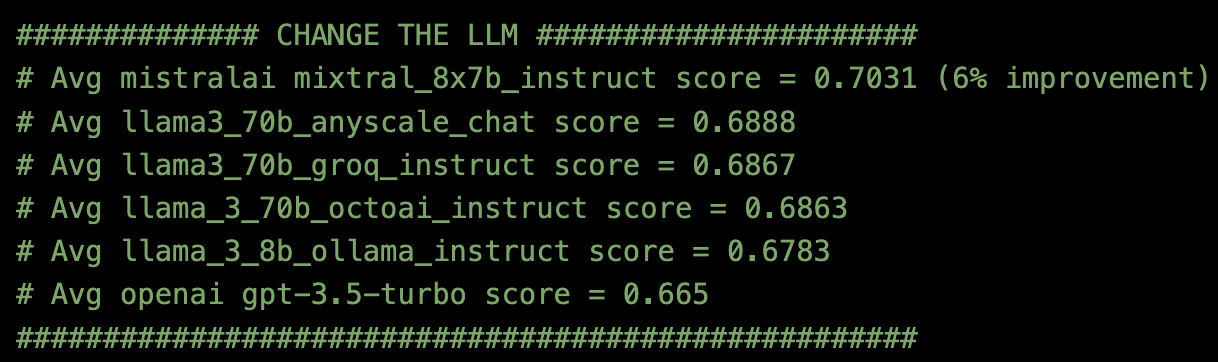
Using Milvus docs and evaluation method Ragas, the result was:
- LLM = MistralAI mixtral_8x7b_instruct using Anyscale Endpoints was the best.
Conclusion
RAG pipeline evaluation will vary depending on your particular data and use case. One key takeaway from personal experience and literature is that the most significant improvements often come from refining your retrieval strategies. 🛠️
Using Milvus docs data and Ragas evaluation, this blog observed:
35% Improvement by Changing the Chunking Strategy 📦
27% Improvement by Changing the Embedding Model 🔍
6% Improvement by Changing the LLM Model 🤖
Iterating on these elements can help optimize your RAG pipeline for better results!
References
Greg Kamradt Tutorial on 5 different Levels of Text Splitting: https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/tutorials/LevelsOfTextSplitting/5_Levels_Of_Text_Splitting.ipynb
LangChain Recursive Character Text Splitter: https://python.langchain.com/v0.2/docs/how_to/recursive_text_splitter/
LangChain Multivector Retriever: https://python.langchain.com/v0.2/docs/how_to/multi_vector/#smaller-chunks
LangChain Semantic Chunker: https://python.langchain.com/v0.2/docs/how_to/semantic-chunker/#standard-deviation
How to use RAGAS to evaluate your RAG pipeline: https://medium.com/towards-data-science/rag-evaluation-using-ragas-4645a4c6c477

Keep Reading

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.