




Harnessing Product Quantization for Memory Efficiency in Vector Databases
Exploring product quantization's intricacies and practical implementation through hands-on examples.
Read the entire series
- Introduction to Unstructured Data
- What is a Vector Database and how does it work: Implementation, Optimization & Scaling for Production Applications
- Understanding Vector Databases: Compare Vector Databases, Vector Search Libraries, and Vector Search Plugins
- Introduction to Milvus Vector Database
- Milvus Quickstart: Install Milvus Vector Database in 5 Minutes
- Introduction to Vector Similarity Search
- Everything You Need to Know about Vector Index Basics
- Scalar Quantization and Product Quantization
- Hierarchical Navigable Small Worlds (HNSW)
- Approximate Nearest Neighbors Oh Yeah (Annoy)
- Choosing the Right Vector Index for Your Project
- DiskANN and the Vamana Algorithm
- Safeguard Data Integrity: Backup and Recovery in Vector Databases
- Dense Vectors in AI: Maximizing Data Potential in Machine Learning
- Integrating Vector Databases with Cloud Computing: A Strategic Solution to Modern Data Challenges
- A Beginner's Guide to Implementing Vector Databases
- Maintaining Data Integrity in Vector Databases
- From Rows and Columns to Vectors: The Evolutionary Journey of Database Technologies
- Decoding Softmax Activation Function
- Harnessing Product Quantization for Memory Efficiency in Vector Databases
- How to Spot Search Performance Bottleneck in Vector Databases
- Ensuring High Availability of Vector Databases
- Mastering Locality Sensitive Hashing: A Comprehensive Tutorial and Use Cases
- Vector Library vs Vector Database: Which One is Right for You?
- Maximizing GPT 4.x's Potential Through Fine-Tuning Techniques
- Deploying Vector Databases in Multi-Cloud Environments
- An Introduction to Vector Embeddings: What They Are and How to Use Them
Introduction
Today, data science and machine learning have been important in driving operational efficiency within organizations and businesses. At the core of every data science initiative lies the pressing task of efficiently managing data storage and retrieval.
Vector databases are built to handle the intricacies of complex and high-dimensional datasets, wherein data points are transformed and stored as vectors through embedding. These vectors can span multiple dimensions, ranging from tens to thousands, accommodating diverse data structures. Vector databases benefit many use cases, such as retrieval augmented generation (RAG) and recommender systems, enabling streamlined search operations based on similarity metrics.
However, vector databases have many challenges when processing large-scale datasets, such as high memory usage and slower query retrieval speeds. Yet, strides have been made to address these hurdles, notably through techniques like Product Quantization (PQ). This approach reduces memory requirements by a remarkable 90%, laying the groundwork for deploying scalable, efficient, and cost-effective vector databases.
So, grab a cup of coffee and brace yourself as we explore product quantization's intricacies and practical implementation through hands-on examples.
What is Product Quantization, and How Does It Work?
Product Quantization (PQ) is a technique for compressing high-dimensional data vectors into compact representations with minimal information loss. It provides a significant edge over traditional dimensionality reduction methods like PCA. Then, how does product quantization work? Below are the key steps.
Step 1: Splitting the Vector into Subspaces
We break down a high-dimensional vector into smaller, more manageable subspaces of equal size. For instance, a 128-dimensional vector could be divided into 16 subspaces, each containing eight dimensions.
Step 2: Quantization & Encoding of Sub-vectors
Each of these subspaces is then quantized separately. Quantization refers to mapping vectors to a finite set of reference points in each subspace. These reference points are usually centroids computed from clustering algorithms like K-means. The original values are replaced with the index of the closest centroid. As each index requires significantly less memory than the original vector, this approach substantially reduces data size.
Step 3: Product of Quantization
Finding the closest centroid and assigning its index is repeated for all subvectors. The indices of each subvector are concatenated to obtain the final compressed representation, which can be used for searching and retrieving data. An approximate version of the original vectors can be retrieved by combining the reference points corresponding to the indices of each subspace with minimal loss of information.
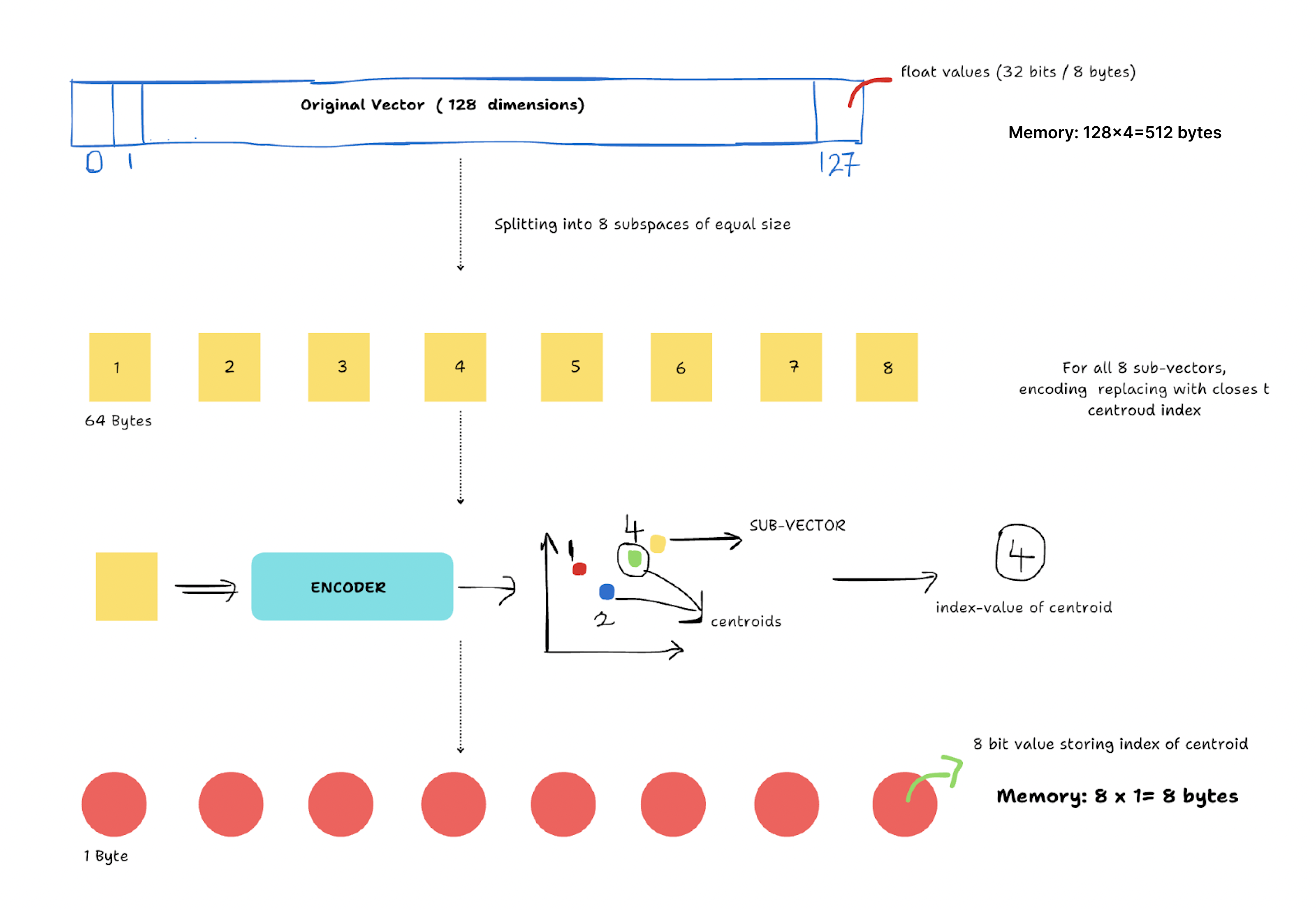 Fig 1- How does product quantization work?
Fig 1- How does product quantization work?
Why Use Product Quantization for Similarity Search?
Product Quantization can provide multi-fold benefits during vector search operations on large-scale datasets such as:
Faster Search Speeds: PQ allows vector databases to perform similarity searches faster because they only need to compare the compact code rather than the full high-dimensional vectors. This approach is particularly beneficial in nearest-neighbor searches, which are widely used in systems for recommendations, image retrieval, and similar tasks.
Reduced Memory Footprint: PQ drastically reduces the memory required to store vectors by replacing original data points with smaller indices. This is crucial when dealing with massive datasets containing millions or even billions of high-dimensional data points.
Scalability: The compressed nature of PQ data allows for storing and searching through much larger datasets on resource-constrained systems or real-time applications where fast response times are critical.
PQ does not suffer from the limitations of traditional techniques like PCA, as it focuses on preserving similarity relationships between data points
Product Quantization supports complex machine learning models and large-scale data analytics tasks. It is indispensable in many modern AI and data-driven applications, offering the right trade-off between accuracy and memory usage. Major use cases include recommender systems, facial recognition systems, anomaly detection to prevent fraud, and more.
Challenges of Product Quantization
Every coin has two sides. While product quantization is an innovative quantization approach in vector search, it also comes with challenges.
Loss of Accuracy: The quantization of vectors inherently leads to a loss of information. The approximations mean that some similar vectors might be considered different due to the quantization error, impacting the recall and precision of query results.
Choice of Subspaces and Codebooks: Deciding on the optimal number of subspaces and the size of the codebooks (number of centroids in each subspace) can be challenging. Dividing the vector into very small subspaces will compress it greatly but may cause a significant loss of accuracy.
Scalability of Training: Training the quantizers (like k-means clustering ) can be computationally intensive, especially as the dataset's dimensionality and size increase. Efficiently scaling this process is crucial for practical applications.
Managing costs: The computational cost for encoding and decoding vectors can impact query speed when real-time responses are crucial.
Researchers are developing techniques to address these challenges and improve PQ's robustness. For example, using dynamic adjustments of codebooks based on ongoing data ingestion can provide more accurate quantization. Parallel processing techniques like multithreading are used to offset the computational costs associated with PQ.
Experiment Results: Product Quantization in Practice
Before using product quantization, it is essential to understand how to evaluate the technique. While assessing PQ in a vector database, you need to keep a few things in mind: the volume of memory savings, recall accuracy during data retrieval, and costs.
In this section, we will examine the performance of different vector databases using VectorDBBench, an open-source benchmark tool for vector databases.
VectorDBBench is a tool for data professionals to compare various vector databases and find the optimal solution. This tool includes real-world testing scenarios and public datasets from OpenAI and Cohere. It provides a comprehensive performance analysis report with latency metrics, QPS (queries per second score), Cost-Performance Ratio (cost incurred per QPS), and The cost incurred for every one million queries. For example, according to this benchmarking result, Zilliz Cloud (the fully managed Milvus) has shown over 10x higher QPS scores than Pinecone.
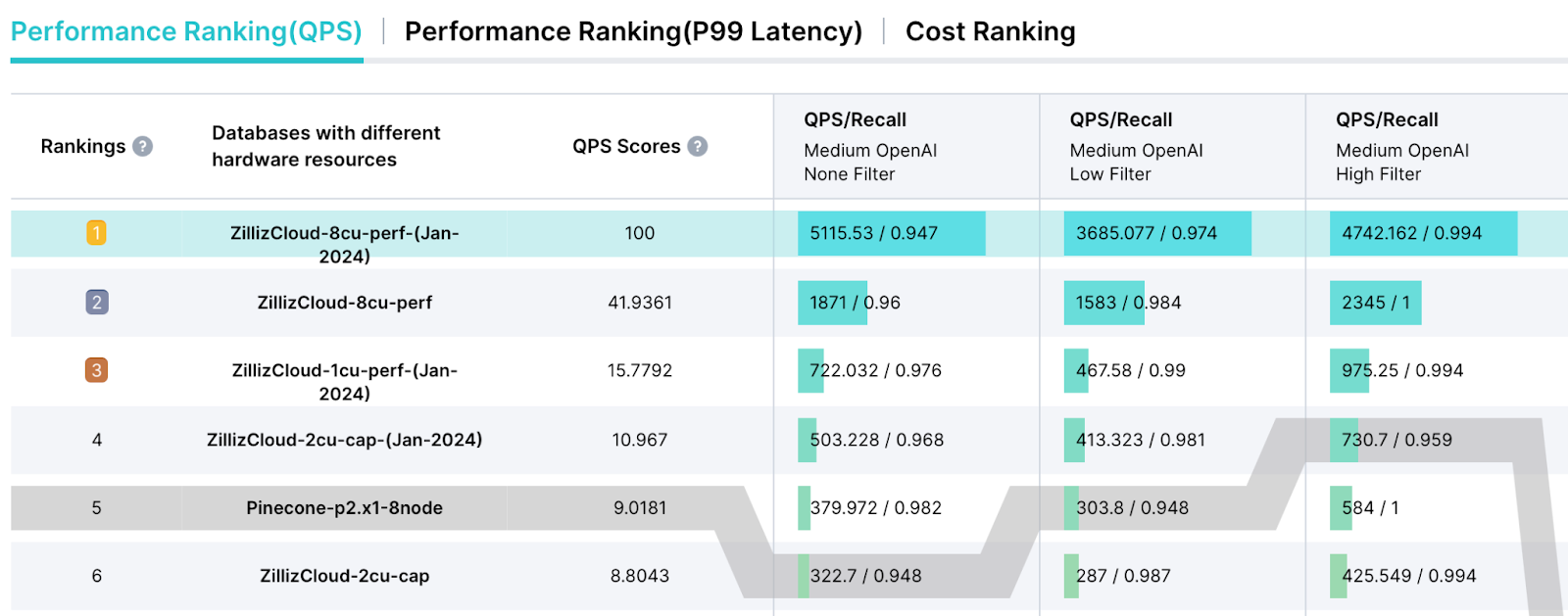 Performance comparison- Zilliz Cloud vs. Pinecone.
Performance comparison- Zilliz Cloud vs. Pinecone.
Performance comparison: Zilliz Cloud vs. Pinecone
Zilliz Cloud: eight performance-optimized CU
Pinecone: one p2 (performance-optimized) pod and eight nodes
Dataset: OpenAI, 500,000 vectors with 1536 dimensions
Benchmarking PQ with Your Dataset
In this section, I’ll illustrate how to benchmark Product Quantization (PQ) on your datasets using Milvus in Python. Before you get started, please make sure you’ve installed Milvus. Refer to our Milvus installation documentation for more details.
After you install Milvus, install Milvus and the necessary Python client. You can pip-install the Milvus client.
pip install pymilvus
The next step is to prepare your dataset. Clean your data to remove noise and outliers that can skew your benchmark results. The dataset should have vectors as features. Each piece of data (e.g., an image or text document) should be converted into a numerical vector. You can also synthetically generate a sample dataset with random values.
import numpy as np
# Generating a simple 1000 128-dimensional vectors
dataset = np.random.random((1000, 128)).tolist()
Set up your Milvus connection and configure a collection with PQ settings. Decide how to split your vectors into subspaces. The number of subspaces (M) and the dimensions of each subspace (K) are crucial factors that affect both compression and accuracy.
from pymilvus import CollectionSchema, FieldSchema, DataType, Collection
# Connect to Milvus server
from pymilvus import connections
connections.connect("default", host='127.0.0.1', port='19530')
# Define the schema of the collection where vectors are stored
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128)
]
schema = CollectionSchema(fields, description="Test collection with PQ")
# Create a collection with PQ enabled
collection_name = "vector_search_collection"
collection = Collection(name=collection_name, schema=schema, using="default")
# Configure the index with PQ
index_params = {
"metric_type": "L2",
"index_type": "IVF_PQ",
"params": {"nlist": 100, "m": 16, "nbits": 8 } # 'm' is the number of sub quantizers; 'nbits' is the number of bits in which each low-dimensional vector is stored.
}
collection.create_index(field_name="embedding", index_params=index_params)
Insert your data and perform a query to measure performance:
# Insert data into Milvus
mr = collection.insert([dataset])
# Conduct a search
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
results = collection.search(dataset[:10], "embedding", search_params, limit=3)
print(results)
Evaluate the results, adjust parameters if needed, and test again. If the recall rate is unsatisfactory, consider adjusting the number of subspaces or the dimensions per subspace. Increasing the granularity of quantization can improve recall at the cost of increased memory use and possibly slower query times.
# Rerun the search
results = collection.search(dataset[:10], "embedding", search_params, limit=3)
print(results)
Continue refining your approach based on the results. Benchmarking is often an iterative process to find the optimal balance between efficiency and accuracy. These code samples provide a basic framework for benchmarking PQ with Milvus. Always validate the settings and results with your specific dataset and use case requirements.
Tips and Best Practices for Product Quantization
Start Small: Based on the recall rates, begin with smaller subspaces and gradually increase as needed.
Cluster Quality: Ensure high-quality clustering in the quantization step; poor clusters can significantly degrade the quality of the approximation.
Hardware Utilization: If available, use hardware acceleration (e.g., GPUs), especially when processing large datasets.
Parallel Processing: Use Milvus's parallel processing capabilities to speed up the training of quantizers and querying phases.
 Applications of PQ in vector search
Applications of PQ in vector search
Conclusion
Product Quantization (PQ) is an innovative approach to similarity search. By compressing data into compact representations without significantly compromising retrieval accuracy, PQ allows businesses and researchers to manage larger datasets on existing hardware, reducing costs while maintaining performance. Milvus is an advanced open-source vector database that supports product quantization for efficient vector search. Whether you're a data scientist seeking to improve search functionalities or a business looking to optimize your data infrastructure, Milvus is an optimal solution for your application.

- Introduction
- What is Product Quantization, and How Does It Work?
- Why Use Product Quantization for Similarity Search?
- Challenges of Product Quantization
- Experiment Results: Product Quantization in Practice
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Dense Vectors in AI: Maximizing Data Potential in Machine Learning
This article zooms in on dense vectors, uncovering their advantages compared to sparse vectors and how they are used in ML algorithms across various areas.

Maintaining Data Integrity in Vector Databases
Guaranteeing that data is correct, consistent, and dependable throughout its lifecycle is important in data management, especially in vector databases

Ensuring High Availability of Vector Databases
Ensuring high availability is crucial for the operation of vector databases, especially in applications where downtime translates directly into lost productivity and revenue.