




Choosing the Right Vector Index for Your Project
Read the entire series
- Introduction to Unstructured Data
- What is a Vector Database and how does it work: Implementation, Optimization & Scaling for Production Applications
- An Introduction to Vector Embeddings: What They Are and How to Use Them
- Introduction to Vector Similarity Search
- Understanding Vector Databases: Compare Vector Databases, Vector Search Libraries, and Vector Search Plugins
- What is Information Retrieval?
- Everything You Need to Know about Vector Index Basics
- Choosing the Right Vector Index for Your Project
A quick recap
In our Vector Database 101 series, we’ve learned that vector databases are purpose-built databases meant to conduct approximate nearest neighbor search across large datasets of high-dimensional vectors (typically over 96 dimensions and sometimes over 10k). These vectors are meant to represent the semantics of unstructured data, i.e., data that cannot be fit into traditional databases such as relational databases, wide-column stores, or document databases.
Conducting an efficient similarity search requires a data structure known as a vector index. These indexes enable efficient traversal of the entire database; rather than having to perform brute-force search with each vector. There are a number of in-memory vector search algorithms and indexing strategies available to you on your vector search journey. Here's a quick summary of each:
Brute-force search (FLAT)
Brute-force search, also known as "flat" indexing, is an approach that compares the query vector with every other vector in the database. While it may seem naive and inefficient, flat indexing can yield surprisingly good results for small datasets, especially when parallelized with accelerators like GPUs or FPGAs.
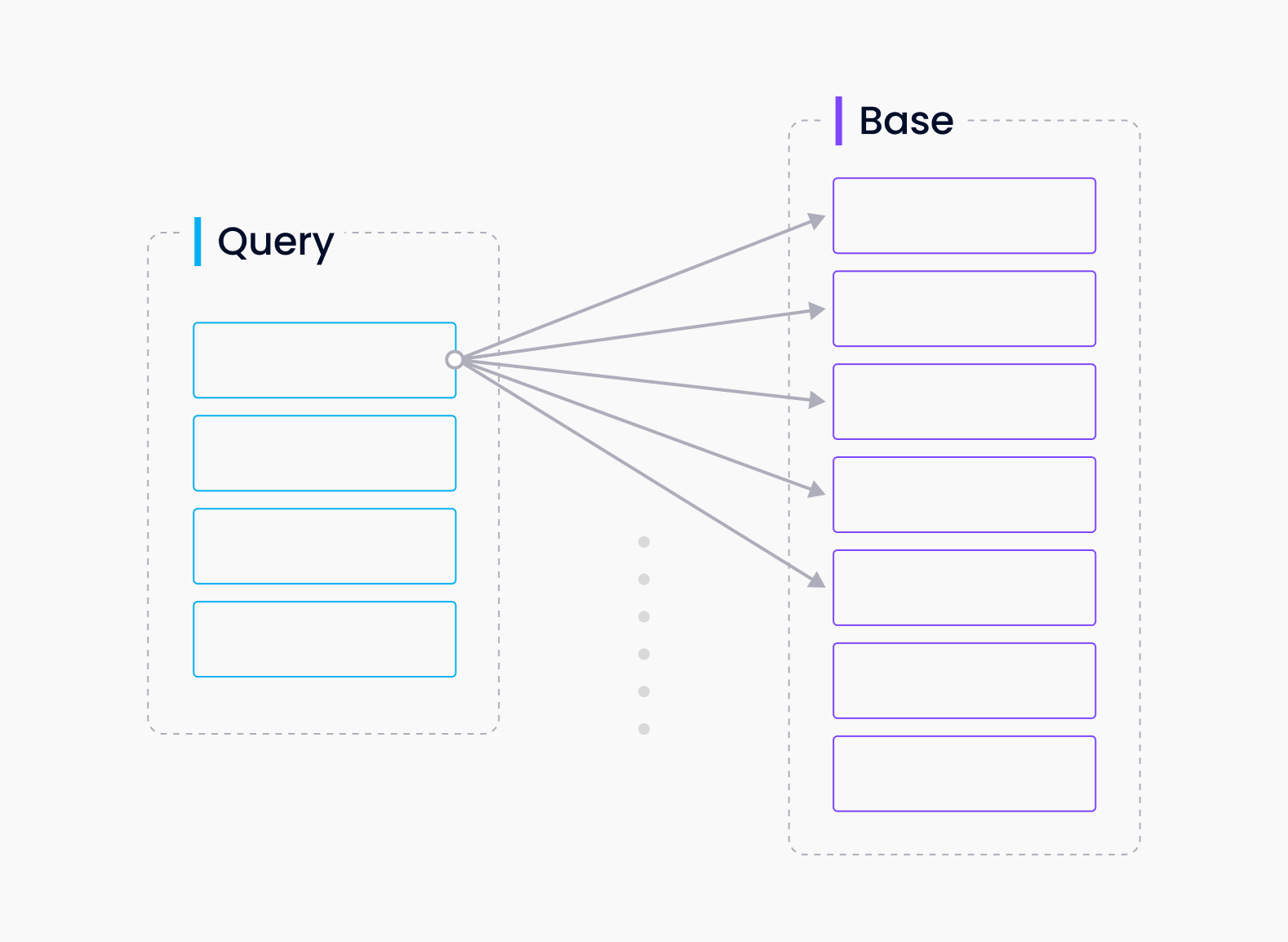 Flat visualized
Flat visualized
Inverted file index (IVF)
IVF is a partition-based indexing strategy that assigns all database vectors to the partition with the closest centroid. Cluster centroids are determined using unsupervised clustering (typically k-means). With the centroids and assignments in place, we can create an inverted index, correlating each centroid with a list of vectors in its cluster. IVF is generally a solid choice for small- to medium-size datasets.
 A two-dimensional Voronoi diagram. Image by Balu Ertl
A two-dimensional Voronoi diagram. Image by Balu Ertl
Scalar quantization (SQ)
Scalar quantization converts floating-point vectors (typically float32 or float64) into integer vectors by dividing each dimension into bins. The process involves:
Determining each dimension's maximum and minimum values.
Calculating start values and step sizes.
Performing quantization by subtracting start values and dividing by step sizes.
The quantized dataset typically uses 8-bit unsigned integers, but lower values (5-bit, 4-bit, and even 2-bit) are also common.
Product quantization (PQ)
Scalar quantization disregards distribution along each vector dimension, potentially leading to underutilized bins. Product quantization (PQ) is a more powerful alternative that performs both compression and reduction: high-dimensional vectors are mapped to low-dimensional quantized vectors assigning fixed-length chunks of the original vector to a single quantized value. PQ typically involves splitting vectors, applying k-means clustering across all splits, and converting centroid indices.
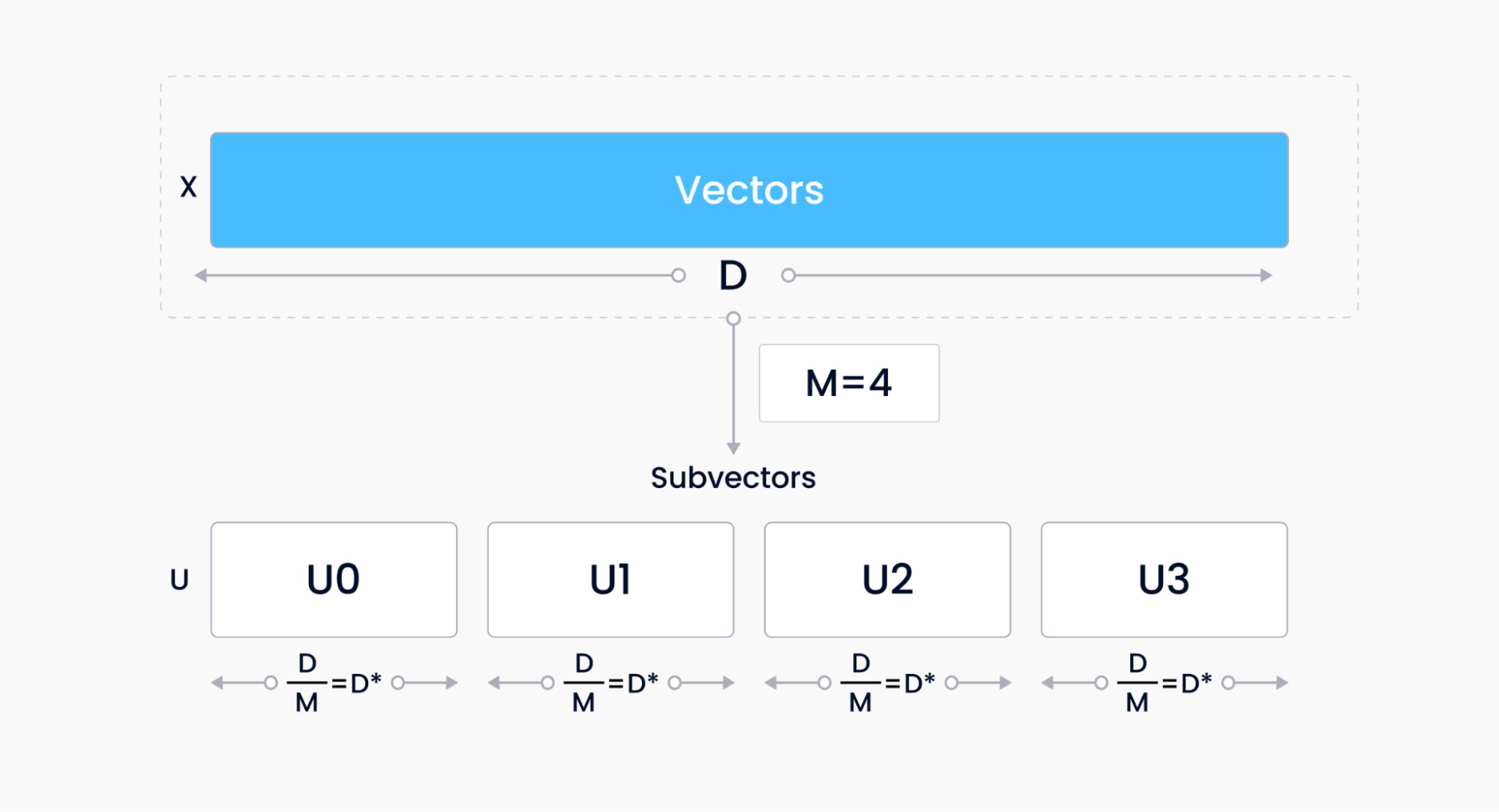 PQ, visualized
PQ, visualized
Hierarchical Navigable Small Worlds (HNSW)
HNSW is the most commonly used vectoring indexing strategy today. It combines two concepts: skip lists and Navigable Small Worlds (NSWs). Skip lists are effectively layered linked lists for faster random access (O(log n) for skip lists vs. O(n) for linked lists). In HNSW, we create a hierarchical graph of NSWs. Searching in HNSW involves starting at the top layer and moving toward the nearest neighbor in each layer until we find the closest match. Inserts work by finding the nearest neighbor and adding connections.
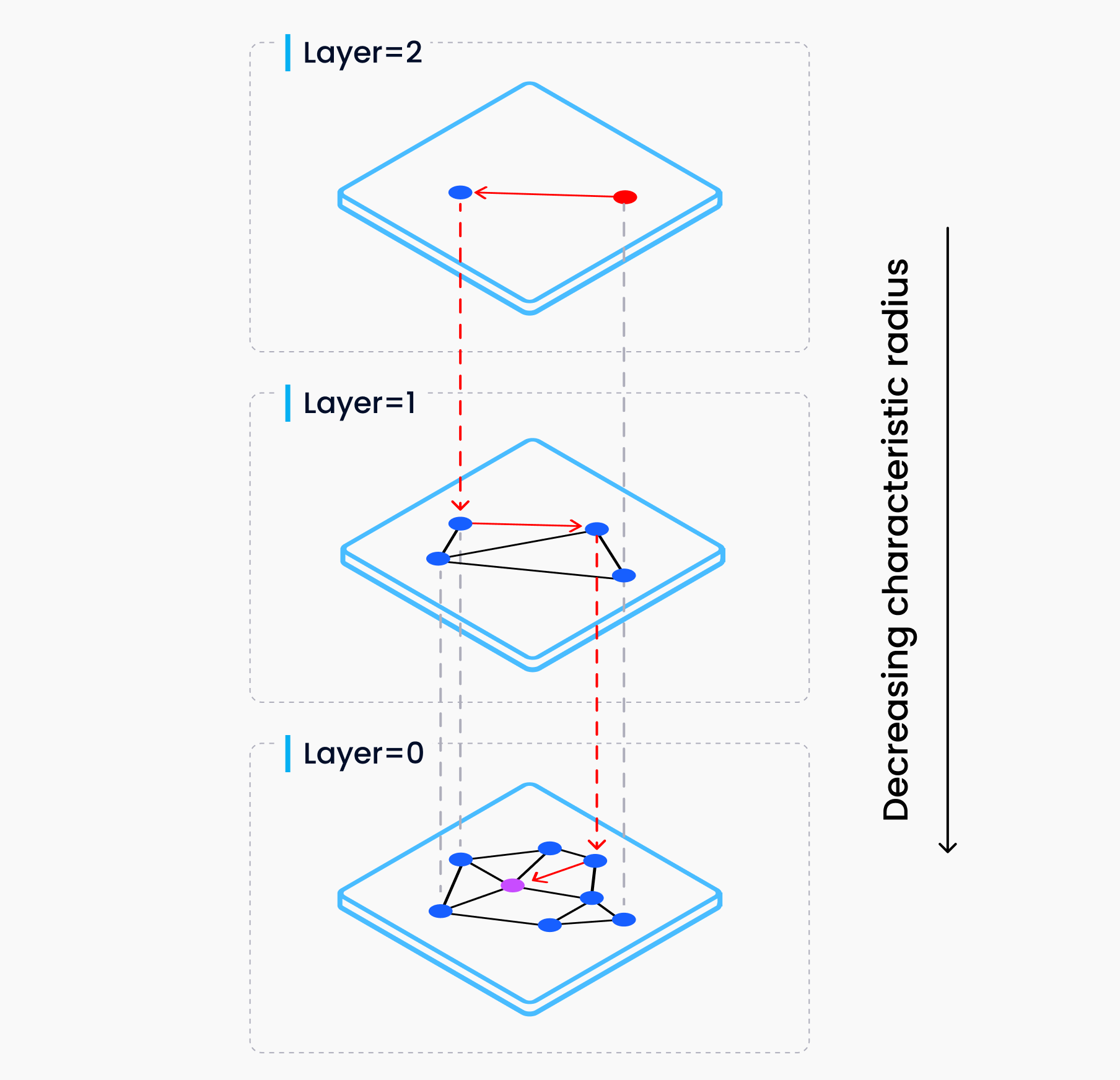 HNSW, visualized. Credit: Yu. A. Malkov & D. A. Yashunin
HNSW, visualized. Credit: Yu. A. Malkov & D. A. Yashunin
Approximate Nearest Neighbors Oh Yeah (Annoy)
Annoy is a tree-based index that uses binary search trees as its core data structure. It partitions the vector space recursively to create a binary tree, where each node is split by a hyperplane equidistant from two randomly selected child vectors. The splitting process continues until leaf nodes have fewer than a predefined number of elements. Querying involves iteratively the tree to determine which side of the hyperplane the query vector falls on.
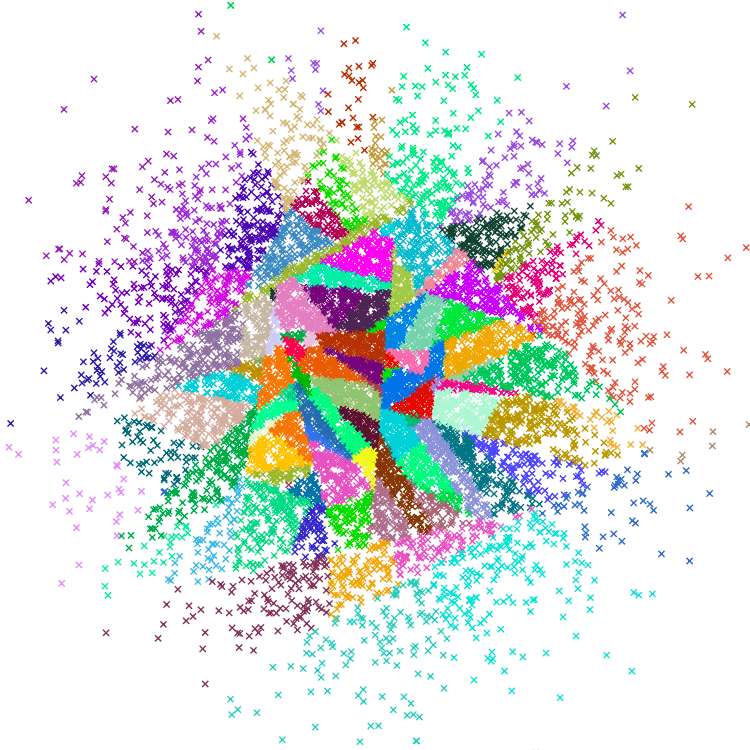 Annoy, visualized
Annoy, visualized
Don't worry if some of these summaries feel a bit obtuse. Vector search algorithms can be fairly complex but are often easier to explain with visualizations and a bit of code.
Picking a vector index
So, how exactly do we choose the right vector index? This is a fairly open-ended question, but one key principle to remember is that the right index will depend on your application requirements. For example: are you primarily interested in query speed (with a static database), or will your application require a lot of inserts and deletes? Do you have any constraints on your machine type, such as limited memory or CPU? Or perhaps the domain of data that you'll be inserting will change over time? All of these factors contribute to the most optimal index type to use.
Here are some guidelines to help you choose the right index type for your project:
100% recall: This one is fairly simple - use FLAT search if you need 100% accuracy. All efficient data structures for vector search perform approximate nearest neighbor search, meaning that there's going to be a loss of recall once the index size hits a certain threshold.
index_size < 10MB: If your total index size is tiny (fewer than 5k 512-dimensional float32 vectors), just use FLAT search. The overhead associated with index building, maintenance, and querying is simply not worth it for a tiny dataset.
10MB < index_size < 2GB: If your total index size is small (fewer than 1M 512-dimensional float32 vectors), my recommendation is to go with a standard inverted-file index (e.g. IVF). An inverted-file index can reduce the search scope by around an order of magnitude while still maintaining fairly high recall.
2GB < index_size < 20GB: Once you reach a mid-size index (fewer than 10M 512-dimensional float32 vectors), you'll want to start considering other PQ and HNSW index types. Both will give you reasonable query speed and throughput, but PQ allows you to use significantly less memory at the expense of low recall, while HNSW often gives you 95%+ recall at the expense of high memory usage - around 1.5x the total size of your index. For dataset sizes in this range, composite IVF indexes (IVF_SQ, IVF_PQ) can also work well, but I would use them only if you have limited compute resources.
20GB < index_size < 200GB: For large datasets (fewer than 100M 512-dimensional float32 vectors), I recommend the use of composite indexes: IVF_PQ for memory-constrained applications and HNSW_SQ for applications that require high recall. A composite index is an indexing technique combining multiple vector search strategies into a single index. This technique effectively combines the best of both indexes; HNSW_SQ, for example, retains most of HNSW's base query speed and throughput but with a significantly reduced index size. We won't dive too deep into composite indexes here, but [FAISS's documentation](https://github.com/facebookresearch/faiss/wiki/Faiss-indexes-(composite) provides a great overview for those interested.
One last note on Annoy - we don't recommend using it simply because it fits into a similar category as HNSW since, generally speaking, it is less performant. Annoy is the most uniquely named index, so it gets bonus points there.
A word on disk indexes
Another option we haven't dove into explicitly in this blog post is disk-based indexes. In a nutshell, disk-based indexes leverage the architecture of NVMe disks by colocating individual search subspaces into their own NVMe page. In conjunction with zero seek latency, this enables efficient storage of both graph- and tree-based vector indexes.
These index types are becoming increasingly popular since they enable the storage and search of billions of vectors on a single machine while maintaining a reasonable performance level. The downside to disk-based indexes should be obvious as well. Because disk reads are significantly slower than RAM reads, disk-based indexes often experience increased query latencies, sometimes by over 10x! If you are willing to sacrifice latency and throughput for the ability to store billions of vectors at minimal cost, disk-based indexes are the way to go. Conversely, if your application requires high performance (often at the expense of increased compute costs), you'll want to stick with IVF_PQ or HNSW_SQ.
Wrapping up
In this post, we covered some of the vector indexing strategies available. Given your data size and compute limitations, we provided a simple flowchart to help determine the optimal strategy. Please note that this flowchart is a general guideline, not a hard-and-fast rule. Ultimately, you'll need to understand the strengths and weaknesses of each indexing option, as well as whether a composite index can help you squeeze out the last bit of performance your application needs. All these index types are freely available to you in Milvus, so you can experiment as you see fit. Go out there and experiment!
Take another look at the Vector Database 101 courses
- Introduction to Unstructured Data
- What is a Vector Database?
- Comparing Vector Databases, Vector Search Libraries, and Vector Search Plugins
- Introduction to Milvus
- Milvus Quickstart
- Introduction to Vector Similarity Search
- Vector Index Basics and the Inverted File Index
- Scalar Quantization and Product Quantization
- Hierarchical Navigable Small Worlds (HNSW)
- Approximate Nearest Neighbors Oh Yeah (ANNOY)
- Choosing the Right Vector Index for Your Project
- DiskANN and the Vamana Algorithm
 Frank Liu
Frank LiuFrank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai and worked as an ML engineer at Yahoo in San Francisco. In his free time, Frank enjoys playing chess, swimming, and powerlifting. Frank holds MS and BS degrees in Electrical Engineering from Stanford University.
- A quick recap
- Picking a vector index
- A word on disk indexes
- Wrapping up
- Take another look at the Vector Database 101 courses
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

What is a Vector Database and how does it work: Implementation, Optimization & Scaling for Production Applications
A vector database stores, indexes, and searches unstructured data through vector embeddings for fast information retrieval and similarity search.

An Introduction to Vector Embeddings: What They Are and How to Use Them
In this blog post, we will understand the concept of vector embeddings and explore its applications, best practices, and tools for working with embeddings.

Introduction to Vector Similarity Search
Learn what vector search is and the metrics pertinent to decide the distance (or similarity) between objects.