




From Rows and Columns to Vectors: The Evolutionary Journey of Database Technologies
From structured SQL and NoSQL and cutting-edge vector databases, this journey undertakes a significant transformation in data management strategies.
Read the entire series
- Introduction to Unstructured Data
- What is a Vector Database and how does it work: Implementation, Optimization & Scaling for Production Applications
- Understanding Vector Databases: Compare Vector Databases, Vector Search Libraries, and Vector Search Plugins
- Introduction to Milvus Vector Database
- Milvus Quickstart: Install Milvus Vector Database in 5 Minutes
- Introduction to Vector Similarity Search
- Everything You Need to Know about Vector Index Basics
- Scalar Quantization and Product Quantization
- Hierarchical Navigable Small Worlds (HNSW)
- Approximate Nearest Neighbors Oh Yeah (Annoy)
- Choosing the Right Vector Index for Your Project
- DiskANN and the Vamana Algorithm
- Safeguard Data Integrity: Backup and Recovery in Vector Databases
- Dense Vectors in AI: Maximizing Data Potential in Machine Learning
- Integrating Vector Databases with Cloud Computing: A Strategic Solution to Modern Data Challenges
- A Beginner's Guide to Implementing Vector Databases
- Maintaining Data Integrity in Vector Databases
- From Rows and Columns to Vectors: The Evolutionary Journey of Database Technologies
- Decoding Softmax Activation Function
- Harnessing Product Quantization for Memory Efficiency in Vector Databases
- How to Spot Search Performance Bottleneck in Vector Databases
- Ensuring High Availability of Vector Databases
- Mastering Locality Sensitive Hashing: A Comprehensive Tutorial and Use Cases
- Vector Library vs Vector Database: Which One is Right for You?
- Maximizing GPT 4.x's Potential Through Fine-Tuning Techniques
- Deploying Vector Databases in Multi-Cloud Environments
- An Introduction to Vector Embeddings: What They Are and How to Use Them
Database systems have long been the backbone of information technology, underpinning the functionality of everything from everyday applications to complex corporate systems. They are pivotal in organizing, storing, and retrieving vast amounts of data, thus enabling informed decision-making and strategic planning.
In a timewhere data generation is almost incomprehensible, with the digital universe doubling in size every two years, the evolution of database technology has become a critical narrative in the tech world. From the structured precincts of SQL to the dynamic realms of NoSQL and the cutting-edge landscapes of vector databases, this journey encapsulates a significant transformation in data management strategies.
The Advent of SQL Databases
In the 1970s and 1980s, the advent of relational database management systems (RDBMS) revolutionized the way data was stored and managed. These systems, such as Oracle, IBM DB2, and Microsoft SQL Server, organized data into tables with predefined schemas, where rows represented records and columns represented attributes. The introduction of SQL (Structured Query Language) enabled efficient data manipulation and retrieval, making RDBMS solutions ideal for applications requiring strict data consistency and integrity, such as banking, finance, and enterprise resource planning (ERP) systems.
Emergence of NoSQL
As the digital landscape evolved, organizations encountered new challenges posed by the rapid growth of unstructured and semi-structured data, such as social media content, sensor data, and multimedia files. Traditional relational databases struggled to handle this data's scale, variety, and complexity, leading to the rise of NoSQL (Not only SQL) databases in the late 2000s. These flexible, schema-less databases, including MongoDB, Cassandra, and Couchbase, were designed to handle diverse data types and provide better scalability and performance for modern data-intensive applications, such as real-time analytics, content management systems, and Internet of Things (IoT) platforms.
The Rise of Vector Databases
Vector databases are the latest frontier in this evolutionary path of database systems. They represent a paradigm shift in database technology, addressing the complexities and nuances of gaining insights into unstructured data. Unlike traditional databases that manage data in rows and columns or even the diverse structures accommodated by NoSQL systems, Vector Databases excel in processing and storing data in the form of vectors — sequences of numbers in multi-dimensional spaces that can represent anything from text, images, sounds, and beyond.
This capability makes vector databases adept at managing data types inherent to machine learning and AI applications. Vector databases' core strength lies in their ability to efficiently and accurately perform similarity and semantic searches. They utilize advanced algorithms, such as Approximate Nearest Neighbor (ANN) search, to quickly identify the most similar data points in large datasets, a process critical for tasks like personalized recommendations, image and speech recognition, interactive AI chatbots, and real-time decision-making.
Vector Database Key Benefits
Vector databases offer several key benefits, particularly in handling complex and high-dimensional data, which are crucial for modern applications in artificial intelligence and machine learning. Here are the main advantages:
Efficient Similarity search: Vector databases excel at finding the nearest neighbors or most similar items to a given query vector. This is essential for applications like recommendation systems, where it's crucial to quickly identify items similar to a user's interests.
Handling High-Dimensional Data: They are specifically designed to manage high-dimensional data efficiently, which is often challenging for traditional relational databases. This makes them ideal for dealing with data types like images, videos, and complex patterns common in AI and ML tasks.
Advanced Semantic search: By leveraging the vector space model, these databases can perform semantic searches and understand the context and meaning of words or entities. This capability is particularly useful for natural language processing (NLP) applications, enhancing the accuracy of search results and content relevancy.
Scalability: Vector databases can scale to accommodate large volumes of data, a critical requirement for big data applications and services that process and analyze growing datasets efficiently.
Enhanced AI and ML Integration: Vector databases are built to integrate seamlessly with various AI and ML technologies such as LlamaIndex, LangChain, and Semantic Kernel, facilitating the development and deployment of intelligent applications.
Retrieval Augmented Generation (RAG) is a trending technology for addressing the hallucinations of large language models. Vector databases act as the vector store in the RAG system, storing domain-specific knowledge outside the LLM and providing the LLM with query contexts.
Vector Databases for RAG
Vector databases are also an indispensable component of the Retrieval-Augmented Generation (RAG) technology, which is used to address the hallucination issues and lack of domain-specific knowledge of large language models (LLMs) like OpenAI’s ChatGPT and Google’s Gemini. A RAG application usually consists of a vector database, an LLM, and prompts as code.
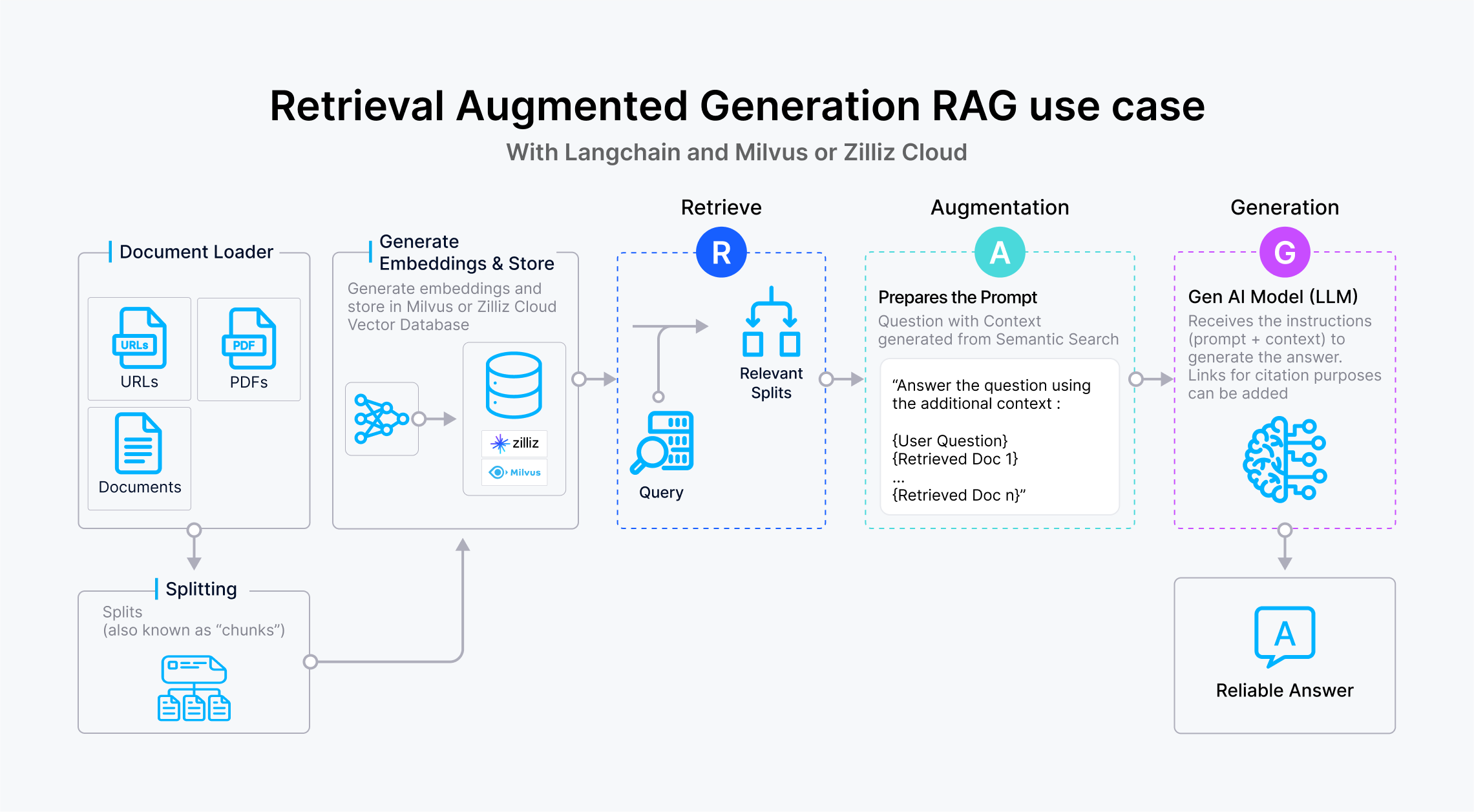 RAG use case with LangChain and Zilliz Cloud
RAG use case with LangChain and Zilliz Cloud
Then how does a vector database function in a RAG application? In short, the vector database stores the external information outside the LLM and provides the LLM contexts of user queries. When a user inputs a question through the RAG application, the vector database conducts ANN searches to retrieve the Top-K results most similar to the user query. Then it sends the retrieved results as additional context to the LLM together with the original user query. This way, the RAG application can answer domain-specific questions that are not pre-trained.
Differences Between SQL, NoSQL, and Vector Databases
The table below demonstrates the key differences between SQL databases, NoSQL databases, and vector databases.
| Feature | SQL Database | NoSQL Database | Vector Database |
|---|---|---|---|
| Data Model | Relational tables | Varied models (document, key-value, columnar, graph) | High-dimensional vectors (both Dense and Sparse) with scalar data for filtering |
| Schema | Fixed | Flexible or none | Fixed, Flexible, or none. The options help with quick prototyping or delivering performant and accurate search results in production. |
| Use Cases | A general use case where data is relational and structured | Applications that require flexibility, the ability to store unstructured data, or use cases not covered in SQL database | RAG, semantic search, similarity search, recommender systems, interactive AI chatbots etc. |
Looking Ahead: The Future of Database Technology
The future of vector databases holds immense potential as artificial intelligence (AI) and machine learning (ML) continue to permeate every industry. With the rapid advancement of natural language processing (NLP), computer vision, and other AI technologies, the demand for efficient storage, indexing, and retrieval of high-dimensional vector data will only intensify.
As the field of vector databases matures, we expect to see further innovations in areas such as specialized indexing techniques, distributed architectures for scalability, and advanced query optimizations tailored for high-dimensional vector spaces. Additionally, integrating vector databases with other data management solutions, such as graph and time-series databases, could unlock new possibilities for complex analytics and decision-making processes. The future may also bring tighter integration with AI frameworks and platforms, enabling more seamless end-to-end workflows for training, deploying, and querying AI models at scale. Ultimately, vector databases will play a crucial role in empowering organizations to harness the full potential of their data assets, driving innovation and fostering a more intelligent, data-driven future.
Conclusion
The evolution of database technology from SQL to vector databases encapsulates a remarkable innovation journey. Starting with the structured, relational model of SQL databases, the technology evolved to embrace NoSQL databases as the volume and complexity of data exploded. NoSQL databases brought flexibility, scalability, and the ability to handle unstructured data, meeting the demands of modern applications and big data challenges.
The advent of vector databases represents the latest frontier. They are tailored for the intricacies of AI and machine learning, efficiently handling high-dimensional data and similarity searches. As database technology evolves, staying informed about the latest developments is crucial. Understanding these advancements can help professionals and organizations refine their data management strategies, drive insights, and remain competitive.

- The Advent of SQL Databases
- Emergence of NoSQL
- The Rise of Vector Databases
- Differences Between SQL, NoSQL, and Vector Databases
- Looking Ahead: The Future of Database Technology
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Introduction to Milvus Vector Database

Scalar Quantization and Product Quantization
A hands-on dive into scalar quantization (integer quantization) and product quantization with Python.

Mastering Locality Sensitive Hashing: A Comprehensive Tutorial and Use Cases
Understand Locality Sensitive Hashing as an effective similarity search technique. Learn practical applications, challenges, and Python implementation of LSH.