




Ensuring High Availability of Vector Databases
Ensuring high availability is crucial for the operation of vector databases, especially in applications where downtime translates directly into lost productivity and revenue.
Read the entire series
- How to Evaluate RAG Applications
- Benchmarking Vector Database Performance: Techniques and Insights
- How to Spot Search Performance Bottleneck in Vector Databases
- Ensuring High Availability of Vector Databases
- Safeguard Data Integrity: Backup and Recovery in Vector Databases
- Scaling Vector Databases to Meet Enterprise Demands
- Introducing an Open Source Vector Database Benchmark Tool for Choosing the Ideal Vector Database for Your Project
Database systems must be highly available to provide uninterrupted access despite potential disruptions like power failures, network issues, or human errors. Without high availability, there's a significant risk of system downtime and data loss, leading to customer churn, damage to reputation, and financial losses.
This is equally true for vector databases, which have gained prominence with the advent of large language models and have become an integral component of various GenAI stacks, such as Retrieval Augmented Generation (RAG). Moreover, as vector databases evolve from being used for prototyping to large-scale deployments in enterprise-ready AI applications, ensuring high availability has become even more important to maintain business continuity and deliver a superior user experience.
In this post, we will explore the essence of high availability for vector databases and examine how the Milvus vector database and Zilliz Cloud (the managed Milvus service) achieve this critical capability.
What is High Availability?
High availability (HA) in database systems refers to providing continuous operational service, minimizing downtime, and ensuring that the system is accessible nearly all the time, even during routine maintenance or minor failures. The primary high availability approach eliminates single points of failure and ensures that users can always access the necessary data without interruption. This approach is typically achieved through redundant systems, failover mechanisms, and load balancing to manage and distribute traffic.
High Availability vs. Fault Tolerance
High availability (HA) and fault tolerance are closely related concepts in database system design aimed at ensuring system reliability. However, they differ in their approach and outcomes. High availability focuses on minimizing downtime through quick recovery of system components after a failure, ensuring services are accessible most of the time with minimal disruption. On the other hand, fault tolerance is designed to achieve zero downtime and data loss by using a dedicated infrastructure that mirrors the primary system, allowing it to operate seamlessly even when components fail. This requirement makes fault tolerance more costly and resource-intensive than high availability.
Despite their differences in scope and significance, high availability and fault tolerance are exchangeable since high availability efficiently addresses faults by restoring services quickly.
High Availability Gold Standards
High Availability, while not promising 100% uptime, is designed to come as close as possible. The gold standard, often called 'five nines,' ensures the system is accessible 99.999% of the time. This concept encompasses various levels of Availability, including 'four nines' (99.99%), 'three nines' (99.9%), and 'two nines' (99%). Each level, while not perfect, offers a significant reduction in potential downtime, providing a reassuring level of system reliability.
But what exactly do these standards mean? Let's do the math.
- 99.999% (five nines) annually restricts downtime to a mere 5.26 minutes.
- 99.99% (four nines) means only 52.60 minutes of downtime are acceptable annually.
- 99.9% (three nines) limits downtime to 8.77 hours annually.
- 99% (two nines) results in 3.65 days of downtime annually.
As the level of high availability increases, so do the associated costs. This is due to the need for more advanced infrastructure and technologies to minimize potential downtime. The choice of a high availability level is crucial, as it directly impacts how your business operates. It's not just about the highest level of availability, but about finding the right balance between costs and your business requirements. Understanding this balance is key to making a decision that can significantly reduce the risk of operational disruptions.
How Milvus Vector Database Achieves High Availability
Milvus is an open-source vector database renowned for its high availability. It is cloud-native, distributed, and easily deployed on Kubernetes. It provides an in-memory replica mechanism and various backup, restore, and syncing tools to help you achieve system reliability. In this section, we’ll discuss Milvus’s availability from perspectives of architecture design, functionality, and supporting tools.
A cloud-native architecture for rapid deployment on Kubernetes
Milvus adopts a cloud-native distributed architecture that separates storage and computing, enabling straightforward deployment to Kubernetes (K8s) clusters.
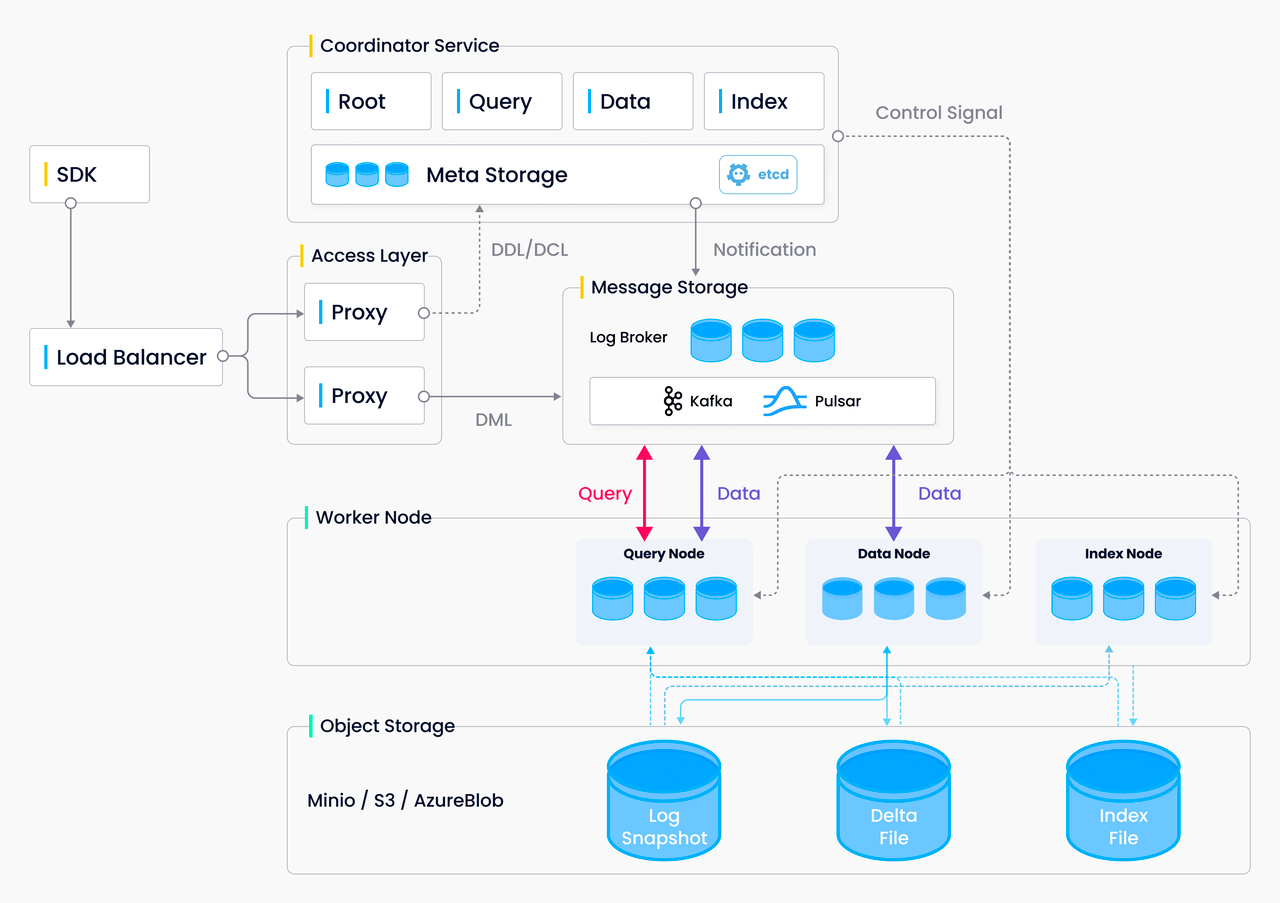 Milvus architecture.png
Milvus architecture.png
By leveraging the inherent high-availability features of Kubernetes and Milvus distributed architecture, Milvus can easily facilitate:
- Multi-Availability Zone Deployment: Milvus supports deployments across multiple availability zones, distributing replicas to various zones for added reliability. Should one zone encounter issues, replicas in other zones continue to operate, thus enhancing overall system availability.
- Health Checks and Self-Healing: The Kubernetes' health check mechanisms regularly monitor service status. If a Milvus node is found to be faulty or unhealthy, Kubernetes automatically restarts or replaces it, maintaining service continuity.
- Load Balancing and Traffic Management: Milvus efficiently distributes network traffic among containers to prevent bottlenecks, aiding performance and availability.
- Storage Redundancy: Milvus utilizes Kubernetes' Persistent Volumes (PV) and Persistent Volume Claims (PVC) to ensure data is stored on reliable storage systems, safeguarding data durability and availability.
In-Memory Replica Mechanism
Milvus supports an In-Memory Replica feature in its distributed deployment mode. This functionality loads complete data segments onto separate query nodes and enables multiple segment replications in the working memory to improve performance and availability. If a node with a replica fails or encounters an error, query requests are swiftly redirected to another replica node without reloading the data again, thus maintaining continuous query service.
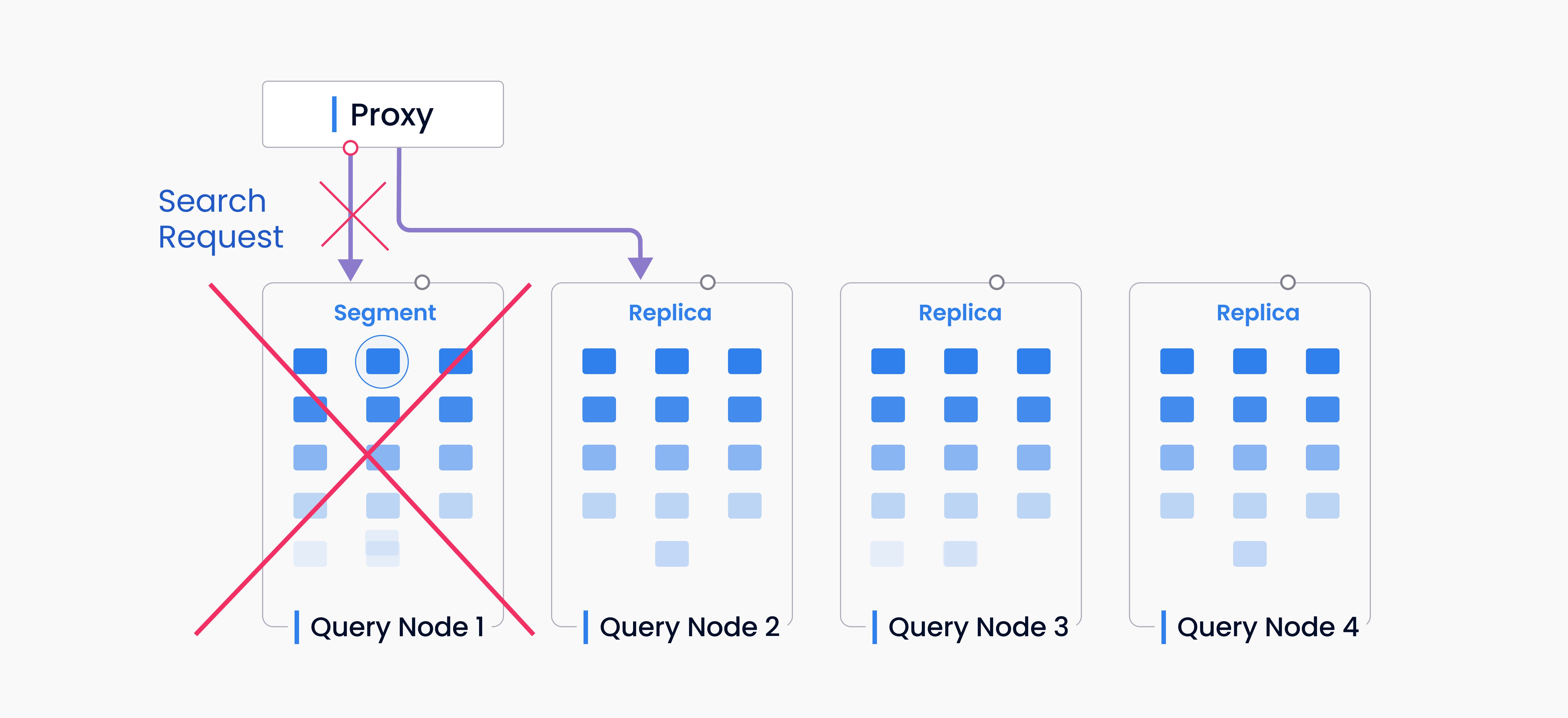 Miluvs in-memory replica mechanism
Miluvs in-memory replica mechanism
For a detailed exploration of the design and implementation of In-Memory Replicas, see this document.
Efficient Backup, Restoration, and Synchronization Tools
Milvus provides specialized tools, such as Milvus-backup and Milvus-CDC, to enhance data backup recovery and facilitate online incremental data synchronization. These tools bolster both service recovery and data protection.
Milvus-backup
Milvus-backup is a tool that assists users in efficiently backing up and restoring original data, whether for entire or specific collections. It offers flexible solutions tailored to business needs, enabling:
- Regular backups of online data.
- Data transfer or migration between different Milvus clusters.
- Restoration to a pristine historical version in cases of accidental or malicious data modifications.
- Data backup before significant changes or maintenance activities, such as system upgrades.
Milvus-CDC (Change Data Capture)
Milvus-CDC is a tool that captures and synchronizes changes of upstream Milvus collections and sinks them to downstream Milvus instances in real time. It allows users to designate one instance as the source and the other as the target, enabling real-time and seamless data syncing for all or selected parts of collections. When combined with Milvus-backup, Milvus-CDC allows users to implement robust solutions for high availability or disaster recovery.
High Availability in Zilliz Cloud
Zilliz Cloud is a fully managed vector database built on Milvus. It empowers you to unlock the full potential of unstructured data for your GenAI applications.
Zilliz Cloud offers physical isolation via resource groups, multi-tenancy features, reliable backup and restoration mechanisms, and a 99.9% service uptime through our SLA. Resource groups and multi-tenancy allow for the isolation of multi-tenant data and services to safeguard your data against accidental or intentional deletion. As a result, Zilliz Cloud provides an even higher degree of data protection and service resilience than Milvus's offline deployment.
For more details, refer to our Zilliz Cloud system availability status.
Summary
Ensuring high availability is crucial for the operation of vector databases, especially in applications where downtime translates directly into lost productivity and revenue.
As we have explored, Milvus leverages a sophisticated, cloud-native architecture optimized for Kubernetes deployment, enhancing its resilience and reliability. This setup supports robust failover capabilities and seamless scalability and incorporates advanced features such as in-memory replication and comprehensive backup and synchronization tools.
Building on this foundation, Zilliz Cloud, a fully managed vector database built on Milvus, offers enhanced data protection and service resilience. It provides physical isolation through resource groups, multi-tenancy features, reliable backup and restoration mechanisms, and a 99.9% service uptime guaranteed by our SLA. These features safeguard data against disruptions, offering higher reliability than traditional deployments.
Take a look at this blog on Safeguarding Data: Security and Privacy in Vector Database Systems to learn why robust security and privacy measures are important.
 Fendy Feng
Fendy FengFendy Feng is the Product Marketing Manager at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.
 Yanliang Qiao
Yanliang QiaoYanliang Qiao is a Senior Quality Assurance Engineer at Zilliz.
- What is High Availability?
- High Availability vs. Fault Tolerance
- High Availability Gold Standards
- How Milvus Vector Database Achieves High Availability
- High Availability in Zilliz Cloud
- Summary
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

How to Evaluate RAG Applications
Effective Evaluation strategies for your RAG Application

Safeguard Data Integrity: Backup and Recovery in Vector Databases
This blog explores data backup and recovery in vectorDBs, their challenges, various methods, and specialized tools to fortify the security of your data assets.

Introducing an Open Source Vector Database Benchmark Tool for Choosing the Ideal Vector Database for Your Project
Introducing VectorDBBench, an open-source vector database benchmark tool for choosing the ideal vector database for your project.