




What is Information Retrieval?
Information retrieval (IR) is the process of efficiently retrieving relevant information from large collections of unstructured or semi-structured data.
Read the entire series
- Introduction to Unstructured Data
- What is a Vector Database and how does it work: Implementation, Optimization & Scaling for Production Applications
- An Introduction to Vector Embeddings: What They Are and How to Use Them
- Introduction to Vector Similarity Search
- Understanding Vector Databases: Compare Vector Databases, Vector Search Libraries, and Vector Search Plugins
- What is Information Retrieval?
- Everything You Need to Know about Vector Index Basics
- Choosing the Right Vector Index for Your Project
In today's data-driven world, over 2.5 quintillion bytes of data are generated daily. The sheer volume and velocity of data creation make navigating the Internet akin to exploring a dense jungle. Without Information Retrieval (IR), finding specific information would be nearly impossible.
Today, we will uncover the concept of information retrieval from the ground up, discussing each and every aspect of this technology.
What is Information Retrieval?
Information retrieval (IR) is the process of efficiently retrieving relevant information from large collections of unstructured or semi-structured data. The main part of the IR system is an IR model that ranks documents based on a user's query by representing both queries and documents similarly. It uses a matching function to assign each document a retrieval status value (RSV).
For example, a search engine might rank pages based on their relevance to a keyword query.
The importance of IR can be summarized with the following points:
Efficient Information Access: Facilitates quick and relevant access to vast amounts of data and documents.
Personalization: Tailors search results based on user preferences and previous interactions.
Scalability: Handles large volumes of data and diverse types of content, from text to multimedia.
Accessibility: Makes information easily accessible to a broad audience, including those without specialized knowledge.
It’s a good time to detangle the confusion between two concepts: Information retrieval and data retrieval. Like a search engine, information retrieval finds relevant documents or data based on a query. Data retrieval fetches specific, structured data from a database, such as customer records.
Here are the other differences between the two:
| Feature | Information retrieval | Data retrieval |
| Data Type | Free text, unstructured data like documents and web pages. | Structured data in database tables. |
| Query Type | Keywords, Natural language for intuitive searches. | SQL, Relational algebra for precise, structured queries. |
| Matching | Approximate matches based on relevance. | Exact matches are based on specific criteria. |
| Result Organization | Results ranked by relevance. | Results are often unordered unless explicitly sorted. |
| User Capability | Usable by non-experts, suitable for the general public. | Requires knowledgeable users or automated processes for complex queries. |
History and Evolution of Information Retrieval
The origins of information retrieval (IR) trace back to the pre-digital era, well before the advent of the Internet.
Early Beginnings: Early IR systems were developed as far back as the 1940s, inspired by innovations from the early 20th century. These initial computer-based search systems were designed for commercial and intelligence applications long before search engines became ubiquitous in the modern digital space. Over time, as processor speeds and storage capacities increased, IR systems evolved from manual to more automated and sophisticated approaches.
Development of Modern IR Systems: Modern information retrieval (IR) systems have evolved significantly from basic keyword searches to advanced algorithms. In the 1940s and 1950s, early IR systems like the Univac used simple text-matching techniques. The 1960s saw more sophisticated methods, such as vector space models and relevance feedback, pioneered by Gerard Salton. The 1970s introduced the tf-idf weighting scheme, enhancing document ranking accuracy. By the 1980s and 1990s, the introduction of Latent Semantic Indexing (LSI) and the BM25 ranking function marked significant advances.
Impact of the Internet: The rise of the Internet in the mid-1990s revolutionized IR by automating content acquisition through web crawlers and introducing link analysis techniques like PageRank and HITS to combat manipulation. This led to improvements in correcting spelling mistakes, expanding search queries, and offering a variety of relevant results.
Role of Search Engines: Yahoo and Google were major search engines with distinct algorithms. Yahoo’s early search engine relied heavily on human-curated directories and basic keyword matching. Google's PageRank algorithm evaluates the quantity and quality of links pointing to a page. Despite its popularity, Yahoo's weaker algorithm allowed Google, a new entrant, to surpass it and quickly become a dominant force in the search engine market.
Having explored the history of IR, let's now discuss the key concepts of modern IR systems.
Key Concepts in Information Retrieval Systems
In information retrieval, user queries are processed to identify relevant terms, which are then used to rank documents based on their relevance. The system indexes various data objects (text, images, etc.) and uses IR models to calculate scores for matching documents. Results are presented in a ranked list, differentiating IR search from database search. Let’s look at each component one by one.
Indexing
Indexing in IR is the process of creating data structures (indexes) that allow efficient retrieval of documents based on the terms they contain. Indexes store mappings between terms and documents, allowing for quick search operations.
Indexing is crucial because it significantly speeds up the search process. It enables large-scale search engines and IR systems to handle vast amounts of data efficiently. Without it, retrieving relevant information would be computationally expensive and time-consuming.
Types of Indexing Methods:
Inverted Index: This is the most common indexing method, in which each term is associated with a list of documents in which it appears.
Signature Files: Uses bit strings (signatures) to represent documents, allowing for quick filtering before more detailed checking.
Suffix Trees and Arrays: Indexes that store suffixes of documents, useful for substring searches.
B-Trees: A balanced tree data structure that can index numerical or alphabetical data.
k-d Trees: A spatial data structure for organizing points in a k-dimensional space, useful for indexing multidimensional data.
Query Processing
Understanding how an index works, we can now explore how a query is processed within an Information Retrieval (IR) system. Here are the steps of a query that is passed to an IR system:
How Queries are Processed in an IR System:
Query Parsing: Breaking down the query into components (e.g., terms, operators) and interpreting the user's intent.
Query Transformation: This may involve stemming, lemmatization, or expanding the query with synonyms.
Search Operation: The transformed query is matched against the index to retrieve relevant documents.
Scoring and Ranking: Retrieved documents are scored based on relevance and ranked accordingly.
Result Presentation: The ranked documents are presented to the user, often with snippets or highlights showing the query terms in context.
Types of Queries:
Boolean Model:
Uses logical operators (AND, OR, NOT) to combine terms.
Example: "machine AND learning" returns documents containing both terms.
Vector Space Model:
Represents documents and queries as vector embeddings in a multi-dimensional space.
Similarity is measured using cosine similarity between document and query vectors.
Example: Queries return documents with high cosine similarity with the query vector.
Probabilistic Model:
Based on the probability that a given document is relevant to the query.
Example: Uses Bayes' theorem to rank documents based on relevance probability.
Relevance and Ranking
Relevance is the degree to which a document satisfies the information need expressed by the query. It is subjective and can vary based on user intent, context, and other factors. Factors such as term frequency, document length, document recency, user behavior (click-through rate), and more influence relevance.
Ranking algorithms measure relevance:
Overview of Ranking Algorithms:
TF-IDF (Term Frequency-Inverse Document Frequency): A weighting scheme that considers the importance of a term in a document relative to its importance across the corpus.
BM25: An advanced ranking function that improves upon TF-IDF by incorporating term saturation and document length normalization.
PageRank: Used by search engines like Google, it ranks documents based on the number and quality of links pointing to them.
Learning to Rank: This method uses machine learning models to rank documents, learning from features such as click-through rates, relevance feedback, etc.
Evaluation Metrics
To assess the performance of Information Retrieval (IR) systems, several metrics are commonly used. Common Metrics Used to Evaluate IR Systems are:
- Precision: The fraction of retrieved documents that are relevant.
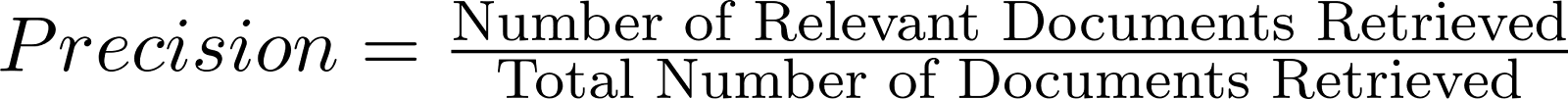 formula - precision.png
formula - precision.png
- Recall: The fraction of relevant documents that are retrieved.
 formula - recall.png
formula - recall.png
- F1-Score: The harmonic mean of precision and recall, balancing the two metrics.
 formula-f1score.png
formula-f1score.png
Mean Average Precision (MAP): The mean of the average precision scores for a set of queries, reflecting the precision at different recall levels.
Normalized Discounted Cumulative Gain (nDCG): Measures the ranking quality by comparing the actual ranking with the ideal ranking, giving higher scores to relevant documents appearing earlier in the result list.
Here’s a link to read more about the evaluation metrics.
Different Types of Information Retrieval Models
Information retrieval models are developed to address specific challenges in retrieving relevant information. The most common types include:
Boolean Retrieval Model
The Boolean retrieval model relies on Boolean logic (AND, OR, NOT) to match documents that satisfy specific query conditions exactly. Users create queries by combining terms with these operators. This model is simple and precise, making it effective for exact matches. However, it doesn’t handle partial relevance, lacks a ranking mechanism, and may either return too many or too few results, limiting its flexibility.
Vector Space Model
In the vector space model, documents and queries are represented as vectors in a multi-dimensional space. Relevance is calculated by measuring the cosine similarity between the vectors. Terms are weighted based on their importance using Term Frequency-Inverse Document Frequency (TF-IDF), which adjusts for term frequency and rarity across documents.
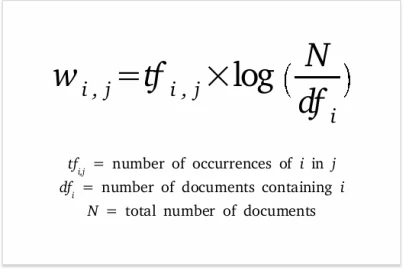 Fig 1 Formula for TF-IDF.png
Fig 1 Formula for TF-IDF.png
Fig 1: Formula for TF-IDF
Probabilistic Retrieval Model
Probabilistic retrieval models estimate the probability that a document is relevant to a given query. Documents are ranked based on this estimated relevance probability, with the most likely relevant documents presented first. BM25 is a popular probabilistic model that uses term frequency and document length normalization to score and rank documents.
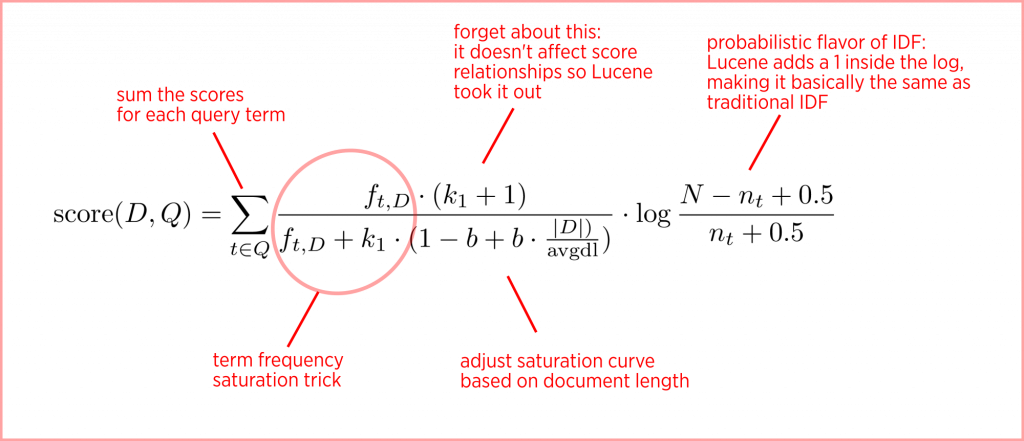 Fig 2 Overview of the BM25 algorithm.png
Fig 2 Overview of the BM25 algorithm.png
Fig 2: Overview of the BM25 algorithm
While BM25 incorporates similar ideas (like term frequency and inverse document frequency) from TF-IDF, it also considers document length normalization and adjusts the term frequency's impact probabilistically. This makes it more sophisticated and flexible than the basic TF-IDF.
Latent Semantic Analysis
Latent Semantic Analysis (LSA) is based on the principle that words appearing in similar contexts tend to have related meanings. For instance, in several articles about health, terms like 'nutrition,' 'exercise,' and 'wellness' might frequently co-occur.
LSA involves constructing a matrix that represents the frequency of words in documents. It then applies a mathematical technique called Singular Value Decomposition (SVD) to reduce the number of rows while maintaining the similarity structure among columns. This reduction converts the original large matrix into a smaller one that captures the essential relationships between words and documents.
Neural Information Retrieval
Neural ranking models for IR utilize shallow or deep neural networks to rank search results based on a query. Traditional learning-to-rank models rely on supervised machine learning (ML) techniques, including neural networks, applied to hand-crafted IR features. In contrast, newer neural models learn language representations directly from raw text, helping to bridge the vocabulary gap between queries and documents. Unlike classical learning-to-rank models and non-neural IR approaches, these advanced ML techniques require large-scale training data before being effectively deployed.
Applications of Information Retrieval
IR powers many applications in the modern world. Here are some of them:
Search Engines
How IR Powers Search Engines: IR algorithms index and rank web pages to match user queries, returning the most relevant search results.
Example: Google PageRank uses link analysis to determine the importance and relevance of web pages, enhancing search result accuracy.
Digital Libraries
Use of IR in Digital Libraries and Archives: IR techniques help in indexing, searching, and retrieving digital documents and historical records, making large volumes of text accessible and manageable.
Example: The Digital Public Library of America (DPLA) utilizes IR to provide access to millions of photographs, manuscripts, and other cultural heritage items.
Recommendation Systems
Role of IR in Building Recommendation Systems: IR methods analyze user preferences and behaviors to suggest relevant items, improving user experience through personalized recommendations.
Example: Netflix's Recommendation Engine uses IR techniques to suggest movies and TV shows based on user viewing history and preferences.
E-Commerce
IR Applications in E-commerce for Product Search and Recommendations: IR techniques are used to enhance product search functionality and recommend products based on user queries and browsing history, increasing customer satisfaction and sales.
Example: Amazon’s Product Search and Recommendation System employs IR algorithms to help users find products and receive personalized recommendations based on their browsing and purchasing behavior.
Healthcare
IR Applications: Retrieves medical literature and patient records for research, diagnosis, and treatment.
Example: PubMed employs IR techniques to access a comprehensive database of medical research and clinical studies.
Challenges in Information Retrieval
Information retrieval tackles search challenges, but sifting through vast data presents obstacles. Here are a few:
Scalability: Scaling Information Retrieval (IR) systems to handle large datasets presents challenges such as increased storage requirements and longer processing times. Efficient management of vast amounts of data often necessitates distributed computing solutions.
Relevance and Accuracy: Ensuring high relevance and accuracy in search results is challenging due to the need for effective ranking algorithms and continuous model updating to accommodate evolving user queries and content.
User Privacy: Balancing effective IR with user privacy involves implementing robust data protection measures while still providing personalized and accurate search results. Techniques like anonymization and secure data handling are crucial.
Handling Multimodal Data: Processing and retrieving information from diverse data types, such as text, images, and videos, requires integrating different data processing techniques. Retrieval systems must effectively handle and combine these modalities for comprehensive search results.
Conclusion
The 20th and early 21st centuries revolutionized information access. In 1912, finding information involved visiting libraries and using card catalogs, limiting the scope of knowledge to the library's collection. Apple's 1987 Knowledge Navigator envisioned advanced IR systems with speech recognition, natural dialogue, and extensive database access, including the ability to connect with experts. The vision resulted in modern IR systems powering the search engines of today.
Today, we are witnessing another vision promised by artificial intelligence (AI), which is changing the dynamics of every field. Advanced IR systems are emerging thanks to large language models (LLMs) like OpenAI’s ChatGPT and Google’s Gemini, which can generate precise information directly without inundating users with numerous links for research. With technology evolving rapidly, it’s crucial to stay ahead of the competition. Here are some further readings and resources.
Books and Research Papers
"Introduction to Information Retrieval" by Manning, Raghavan, and Schütze
"Modern Information Retrieval: The Concepts and Technology behind Search" by Ricardo Baeza-Yates and Berthier Ribeiro-Neto
Community and Forums
Stack Overflow - Information Retrieval Visit Stack Overflow
Reddit - r/MachineLearning: Join the discussion
Zilliz Resources about GenAI, RAG, and Vector Databases
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- What is Information Retrieval?
- History and Evolution of Information Retrieval
- Key Concepts in Information Retrieval Systems
- Different Types of Information Retrieval Models
- Applications of Information Retrieval
- Challenges in Information Retrieval
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Introduction to Unstructured Data
Buckle up for the first tutorial in our Vector Database 101 series and untangle the intricacy around Milvus with us every week.

Introduction to Vector Similarity Search
Learn what vector search is and the metrics pertinent to decide the distance (or similarity) between objects.
