




Relational Databases vs Vector Databases
Databases have long posed challenges for application performance, often necessitating extensive fine-tuning. In response, new database designs have emerged to improve scalability, performance, and developer productivity, simplifying the creation of specific types of applications.
Nonetheless, these new database solutions come with their trade-offs. Each design involves compromises, where certain advantages are gained at the expense of others. Understanding these options and their trade-offs is essential for choosing the best tool for your needs. In this article, we'll explore vector databases and compare them with traditional relational databases to help you make a well-informed decision.
Why choose a specialized database for your application?
In recent years, there has been a surge in specialized databases tailored to specific use cases:
Graph Database: Designed for efficiently storing and analyzing highly connected data, graph databases excel at managing relationships between data points (knowledge graph).
Search Database: These databases handle unstructured or semi-structured data and are optimized for fast, efficient searching and querying.
Time Series Database: Optimized for high write throughput and time-based queries, time series databases handle workloads with frequent and large-scale time-stamped data entries.
Key-Value Database: Known for its high performance and scalability, key-value databases store data as simple key-value pairs without additional metadata, making them ideal for fast read and write operations.
In-Memory Database: These databases store data in RAM rather than on disk, eliminating disk access delays and significantly improving performance.
Vector Database: These databases are built to store vector embeddings and are optimized to handle the computationally intense semantic search.
While relational databases (RDBMS) remain dominant in market share, purpose-built databases are rapidly gaining traction, with vector, time series, key-value, and graph databases seeing the most significant growth in the past two years.
The shift toward specialized databases is driven by increasing demands for performance and advanced features, as users expect software to meet the high standards set by leading tech companies. Additionally, the rise of microservice architectures has facilitated the adoption of specialized databases. Microservices, independently deployable and abstracted from one another, allow teams to select the best tools for specific application functions without extensive knowledge of other services' technologies.
However, integrating another database into an architecture adds complexity. It's crucial to assess whether the advantages of a specialized database outweigh the costs and complexities. Evaluating the pros and cons thoroughly is essential before making decisions that will affect your application in the long term.
"In practice, achieving a unified data management system that supports various workloads and applications is challenging. Comparing it to the automobile industry, we can't envision a single vehicle that serves all purposes—SUVs, trucks, sedans, and school buses designed with specific functions in mind. Similarly, systems are optimized for different needs in the database world, and a one-size-fits-all solution is unlikely. The future lies in developing more specialized databases tailored to specific requirements. While we may see unified interfaces or SDKs to interact with diverse database systems, the trend will continue toward increasingly specialized solutions." Charles Xie, Founder and CEO of Zilliz.**
Relational database overview
Relational databases, also known as traditional databases, are versatile tools that manage data in a tabular format. This structure, organized into rows and columns, enables efficient data storage and retrieval, typically managed on disk. The use of SQL further enhances their versatility, supporting a wide range of queries. This adaptability makes relational databases suitable for a variety of applications. They are particularly valued for their ability to enforce structured relationships between datasets, ensuring data consistency and integrity through predefined schemas.
Data Storage: Rows and Columns
Relational databases utilize a systematic arrangement of rows and columns to store data. Each row represents a single record, while each column represents a data field or attribute. This organized format facilitates easy access and management of data, allowing users to navigate data stores and update information within the database efficiently.
Query Capabilities
Structured Query Language (SQL) is a key feature of relational databases, enabling users to formulate precise queries to extract and manipulate complex data together. SQL provides a robust framework for filtering, sorting, and retrieving data, making it easy to perform complex searches and operations on large datasets. By using SQL, users can quickly identify relevant information and generate detailed reports based on specific criteria.
ACID properties
Relational database transactions are governed by four key properties known as ACID: atomicity, consistency, isolation, and durability. Atomicity ensures that all aspects of a transaction are completed as a whole, leaving no partial updates. Consistency maintains the integrity of the data, ensuring that transactions lead to valid states. Isolation prevents transactions from affecting each other until they are fully committed, thus avoiding conflicts. Finally, durability guarantees that once a transaction is committed, the changes are permanent, even in the event of a system failure.
Vector database overview
So, what exactly is a vector database? At its core, a vector database is a specialized system designed to handle unstructured data by leveraging its vector representations and embeddings. This approach allows for rapid retrieval of semantic information and efficient similarity searches.
Vector databases are crucial in the modern AI ecosystem, particularly in Retrieval Augmented Generation (RAG). RAG enhances the performance of large language models (LLMs) by integrating external knowledge, which helps mitigate AI hallucinations and improves the accuracy of generated responses. These databases manage and retrieve contextual information that the LLMs use to produce more reliable answers.
They are widely applied in various domains, including chatbots, recommendation systems, and multimedia searches such as image, video, and audio retrieval.
Vector databases vs relational databases
Traditional relational databases excel in managing structured data, using predefined schemas, and conducting precise searches within tabular data formats. In contrast, vector databases, with their unique ability to handle unstructured data such as images, audio, videos, and text by representing these data types as high-dimensional vectors, open up a world of possibilities. Unlike relational databases, which use rows and columns, vector databases store data as vectors with multiple dimensions, clustering them based on similarity.
While relational databases like MySQL and PostgreSQL have long been the go-to choice for many developers, there's a noticeable shift in the industry towards incorporating vector search capabilities into these systems. PostgreSQL users, for instance, are increasingly turning to Pgvector for their vector database needs, signaling a growing trend in the database landscape.
To support vector-based operations, relational databases typically add on indexing technologies like HNSW (Hierarchical Navigable Small World) to perform approximate nearest neighbor searches in vector space. This is essential for finding similar items in AI-driven applications. Additionally, these databases offer vector storage alongside traditional data and maintain SQL compatibility, allowing users to leverage familiar SQL commands for managing and querying vector data.
However, unlike Pgvector, which is not a complete vector search engine but rather a plugin for the PostgreSQL databases, dedicated vector databases such as Milvus and Zilliz Cloud are purpose-built from the ground up to manage and query billions of high-dimensional vectors with near real-time performance. These specialized databases leverage advanced indexing techniques to handle similarity searches efficiently, provide superior performance for similarity-based operations, and support large-scale vector data management. They also offer robust APIs tailored for AI and machine learning applications, making them well-suited for complex and large-scale vector data needs.
Why Vector Indexes are important
During the prototyping phase, loading all data into memory is common for faster processing and more straightforward development. However, as data scales up in production, this approach becomes impractical due to:
Memory Limitations: Memory is both limited and more expensive than disk storage.
Capacity Issues: Large datasets can exceed available memory.
Performance Impact: Storing all data in memory can increase startup time and resource consumption.
To handle large datasets efficiently in production, selecting the right indexing strategy is crucial and significant. An appropriate vector index optimizes your Retrieval Augmented Generation (RAG) application's performance by balancing query speed, storage needs, and latency. The diagram below helps visualize how different indexes perform based on three key metrics, underlining the significance of your role in the process.
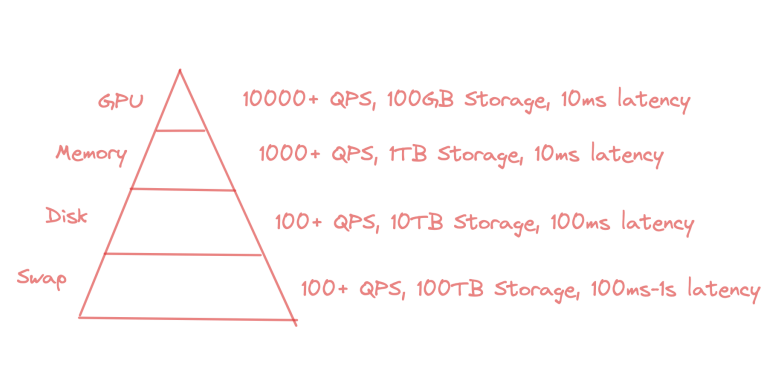 Indices Milvus supports
Indices Milvus supports
Queries Per Second (QPS): Measures the index's query handling capacity per second, indicating throughput and efficiency.
Storage: Reflects the disk space required for the index, impacting infrastructure costs and scalability.
Latency: Represents the time to process and return query results, affecting application responsiveness.
By comparing these metrics, you can choose the index that best fits your use case and performance needs.
Milvus offers a flexible index selection framework tailored to various storage and performance requirements:
GPU Index: Ideal for high-performance environments, supporting rapid data processing and retrieval.
Memory Index: Provides a balance between performance and capacity, suitable for queries per second (QPS) rates, and scales up to terabytes of storage with an average latency of around ten milliseconds.
Disk Index: Handles tens of terabytes with a latency of about 100 milliseconds, suitable for larger, less time-sensitive datasets. Milvus is unique as the only open-source vector database supporting disk indexes.
Swap Index: Facilitates data swapping between S3 or other object storage and memory, reducing costs by about ten times while managing latency. Typical access times are around 100 milliseconds but can extend to a few seconds for less frequently accessed data, making it suitable for offline use and cost-sensitive applications.
After selecting an index, evaluate its performance based on build time, accuracy, performance, and resource usage. For example, a non-optimized index might support only 20 queries per second, while an optimized index could increase QPS tenfold with each tuning iteration, though this may also increase build time.
To effectively choose and fine-tune your index:
Select the index type based on your needs.
Tune index parameters for performance optimization.
Benchmark your use cases to ensure expected performance.
Adjust search parameters to enhance results further.
For guidance through the optimization process, use benchmarking tools like VectorDBBench. Developed and open-sourced by Zilliz, VectorDBBench evaluates various vector databases, enabling comprehensive experiments and system fine-tuning for optimal performance.
A cheat sheet is available for quick reference, outlining the performance of each index in our GPU index catalog, helping you optimize performance and cost-efficiency by guiding you to the best index for your application.
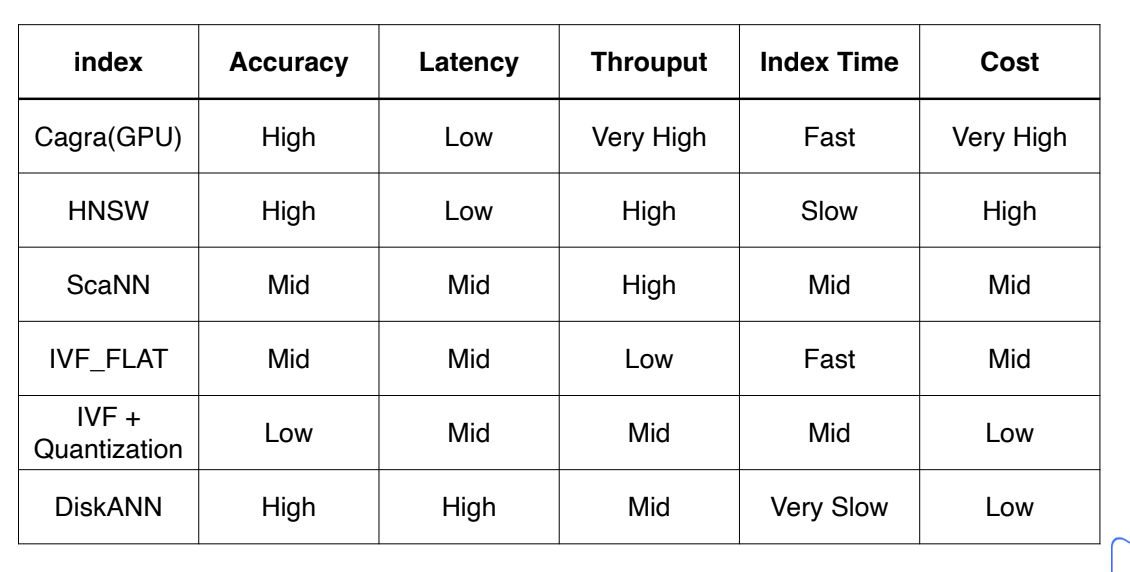 An index cheat sheet
An index cheat sheet
Performance Benchmarks of Relational databases for vector search
As mentioned, traditional relational databases often use 1-2 vector indexes, which can lead to performance issues when handling large-scale vector data. To highlight this challenge, VectorDBBench is an open-source tool designed for benchmarking vector databases. It evaluates various mainstream, vector index, databases, and cloud services, providing unbiased metrics on queries per second (QPS), queries per dollar (QP$), and P99 latency.
For instance, VectorDBBench can compare Pgvector with Milvus or Zilliz. Benchmark results consistently show that Milvus and Zilliz offer superior performance in QPS, speed, and latency compared to Pgvector.
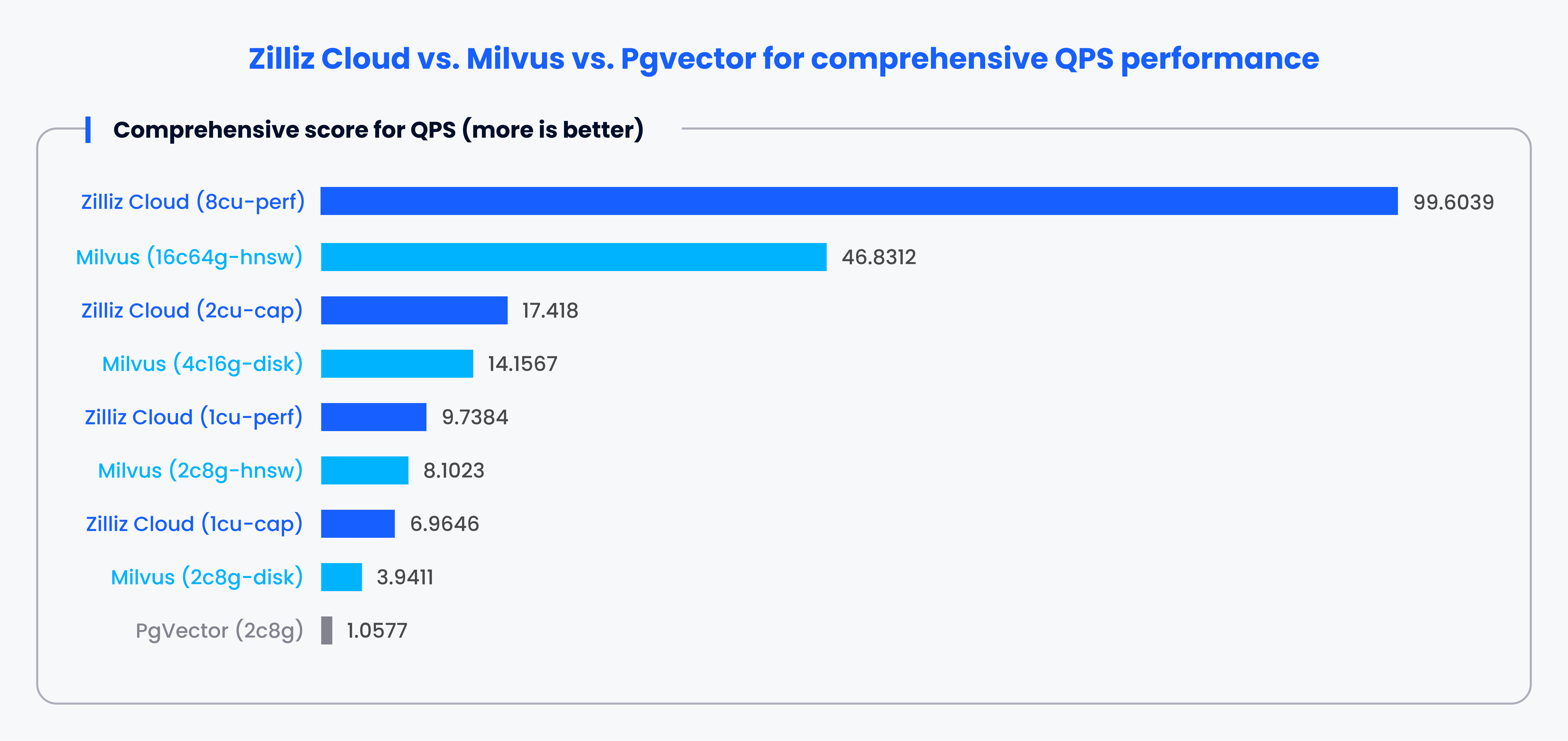
Note: This is a 1-100 score based on each system's performance in different cases according to a specific rule. A higher score denotes better performance.
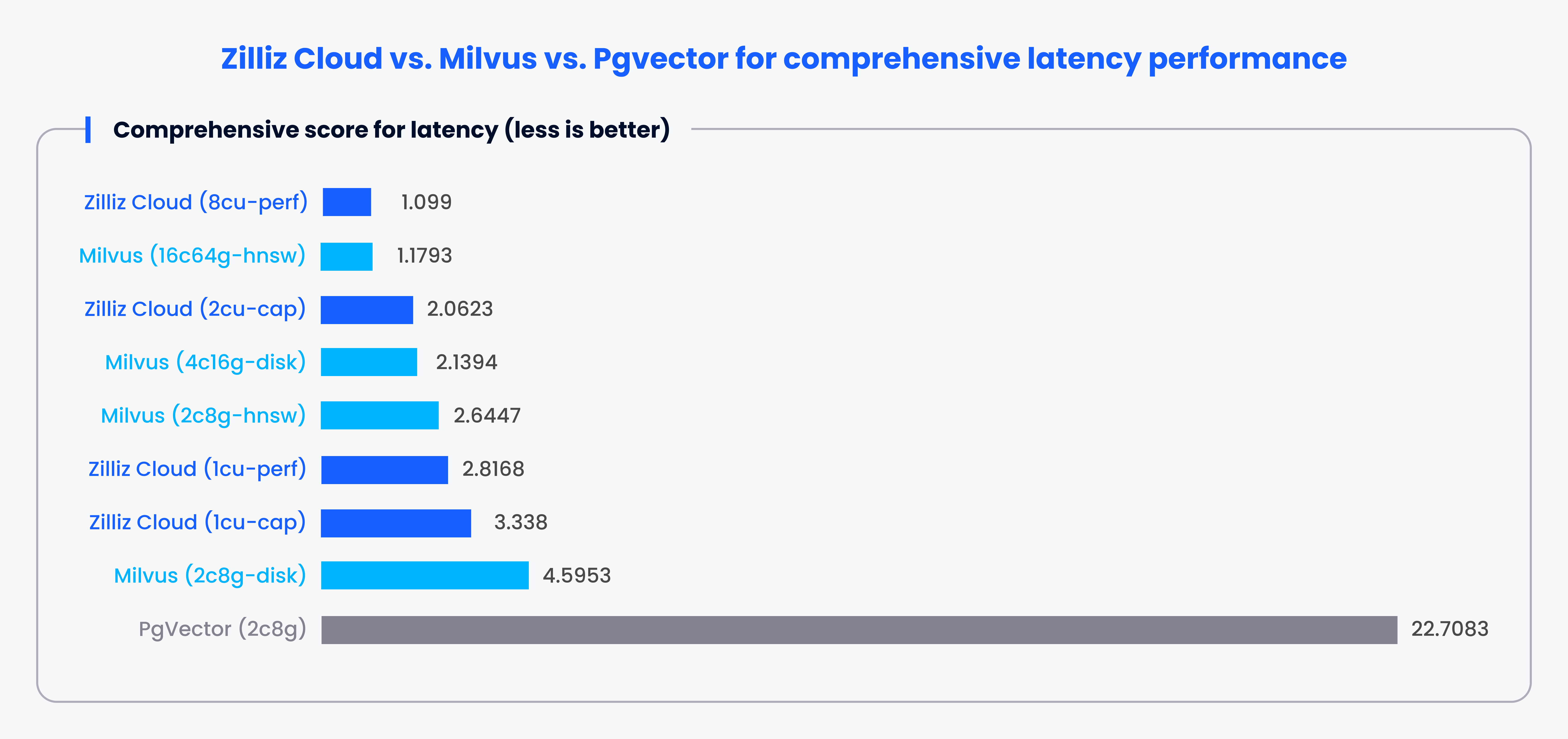
Note: This is a >1 score based on each system's performance in different cases according to a specific rule. A lower score denotes better performance.
With VectorDBBench, you can quickly understand which database performs better in terms of various metrics. You can also determine which database best suits your specific needs.
Vector Database Use Cases
Traditional databases are primarily used for processing transactions, tracking inventory, or payroll management, vector databases excel at supporting the development of some impressive AI driven use cases.
Retrieval Augmented Generation (RAG)
Expand LLMs' knowledge by incorporating external data sources into LLMs and your AI applications.
Recommender System
Recommend information or products to users based on their past behaviors and preferences.
Multimodal Similarity Search
Query across different modalities such as texts, videos, audio, and images.
Molecular Similarity Search
Search for similar substructures, superstructures, and other structures for a specified molecule.
Conclusion: Vector database vs relational database
Choosing the right database for your application is not just important; it's essential. Relational databases are strong in managing structured data and running complex queries with SQL. In contrast, vector databases are designed to handle unstructured data and high-dimensional searches, offering better performance for AI and machine learning tasks. The weight of this decision cannot be overstated.
With their advanced indexing and search capabilities, Vector databases often outperform traditional relational databases in handling large-scale, high-dimensional data. However, adding specialized vector databases may add more to your setup and can increase complexity, so evaluating if the benefits justify the added complexity is important.
Selecting the right indexing strategy and benchmarking tools like VectorDBBench can help optimize performance and ensure you make the best choice for your needs.
For more information on database solutions and performance, check out Zilliz Cloud.

Keep Reading

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.