




Evaluating Your Embedding Model
Review some practical examples to evaluate different text embedding models.
Read the entire series
- Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
- Primer on Neural Networks and Embeddings for Language Models
- Sparse and Dense Embeddings
- Sentence Transformers for Long-Form Text
- Training Your Own Text Embedding Model
- Evaluating Your Embedding Model
- Class Activation Mapping (CAM): Better Interpretability in Deep Learning Models
- CLIP Object Detection: Merging AI Vision with Language Understanding
- Discover SPLADE: Revolutionizing Sparse Data Processing
- Exploring BERTopic: A New Era of Neural Topic Modeling
- Streamlining Data: Effective Strategies for Reducing Dimensionality
- All-Mpnet-Base-V2: Enhancing Sentence Embedding with AI
- Time Series Embedding in Data Analysis
- Enhancing Information Retrieval with Learned Sparse Retrieval
- What is BERT (Bidirectional Encoder Representations from Transformers)?
- What is Mixture of Experts (MoE)?
Latest update: Aug 9
Artificial intelligence plays a crucial role in generating custom Q/A datasets specifically designed to assess the performance of various embedding models.
E5 embeddings are a groundbreaking development in natural language processing, highlighting their ability to transform language comprehension in various applications like sentiment analysis and machine translation.
Introduction to Evaluating your Embedding Models
In the past couple of blog posts, we discussed the architecture of today’s dense embedding models and looked at some basic usage of the sentence-transformers library. Many pre-trained models are available via sentence-transformers. Still, nearly all use the same architecture as the original SBERT model - pooled features over a transformer encoder trained with masked language modeling.
From the perspective of building an application, choosing a proper text embedding model is crucial and often depends on the application’s specific needs. In this blog, we’ll review some key considerations for selecting a model. We’ll also review a practical example of using Arize Pheonix and RAGAS to evaluate different text embedding models, including new models and open source embedding models, comparing them with existing ones.
Contrastive learning is a key training method for embedding models, specifically within the context of the E5 model. It leverages a diverse dataset of text pairs, enabling the model to produce high-quality embeddings that effectively capture semantic similarities among words.
Key Considerations
Most applications today use OpenAI’s embedding endpoint to generate embeddings. While it’s an excellent general-purpose embedding model to get started with, it’s often prudent to move to a) either your embedding model or b) a different open- or closed-source model. Open source models offer cost-effectiveness and flexibility but come with complexities in integration and maintenance.
The e5-large model, for instance, has an embedding size of 1024 layers, which is a key feature contributing to its performance.
Be careful when evaluating these numbers - some overfit the benchmarks and may not be ideal for your use case. Always evaluate. Semantic relationships play a crucial role in embedding models like Word2Vec and BERT, enabling better language understanding and processing.
Task Type and Complexity
The complexity of the embedding task should greatly influence the choice of an embedding model. Simple tasks like sentiment analysis or keyword matching can likely use any general-purpose model on the MTEB leaderboard and achieve reasonable performance. Embedding models that support both monolingual and multilingual tasks can handle various languages effectively, making them highly adaptable. There are many applications, however, that require specialized embeddings. Take, for example, two sequences:
- "Let's eat, Chris."
- "Let's eat Chris."
In the context of information retrieval, it is important to recognize asymmetric tasks, which require the correct prefixes for different types of queries to ensure optimal model performance.
The first and second sequences are nearly identical except for an extra comma. As such, most general-purpose models would place these two sequences very close to each other in a high-dimensional embedding space. However, for specific applications (such as ones that emphasize “appropriateness”), these two sequences should be on opposite ends of the spectrum, with low similarity. Taking this one step further, more complex tasks such as question answering, language translation, or sentiment analysis will require models that can capture the subtleties and nuances of the task. There is never one correct answer.
In the context of text embedding tasks, symmetric tasks utilize the 'query:' prefix, which is crucial for tasks like semantic similarity and paraphrase retrieval to avoid performance degradation.
Model Performance vs. Cost for Optimal Performance
There’s often a trade-off between the performance of an embedding model and its computational efficiency. Different models handle input data of varying lengths, which is defined by their maximum context length. High-performing models such as e5-large-v2 offer can be more “accurate” but require more parameters and much higher runtime. This can be a limiting factor for applications with real-time requirements or limited hardware capabilities. Not using the correct prefixes for input texts can lead to performance degradation, impacting the model's effectiveness in tasks such as passage retrieval and semantic similarity. Real-time, high-throughput applications such as user-facing chatbots or recommender systems need fast results with low latency. In such cases, choosing a more compact model to minimize costs is often prudent. On the other hand, it’s often better to use a much bigger model for applications where accuracy is paramount, such as semantic search across a company’s limited internal corpus of legal or financial documents.
Domain of Text
The domain specificity of the language used in the application’s text data is another crucial consideration. Natural language processing (NLP) methodologies like BERT and text embeddings play a vital role in enabling machines to interpret and understand human language more accurately. Many embedding models are trained on general language data, which might not capture the nuances of specialized vocabularies or jargon. Models trained or fine-tuned on domain-specific datasets can provide more accurate embeddings for texts within those domains. In applications like medical diagnosis from patient records, legal document analysis, or technical support for specific products, domain-specific models can significantly outperform general-purpose models by better understanding the specialized language used in these fields.
Properly formatting 'input texts' with specific prefixes like 'query:' and 'passage:' for different types of tasks is crucial, as it affects model performance. Correct labeling is essential for tasks such as passage retrieval and semantic similarity to prevent performance degradation.
Evaluating Text Embeddings for Semantic Similarity
With the right tools for evaluation, embedding models can be powerful tools. Advanced text-embedding models, such as ada-002, are particularly effective in various applications, including code search, by mapping text into high-dimensional vectors to enhance text similarity assessments. Linear probing classification is crucial in this context, especially for tasks like semantic similarity and passage retrieval, where proper input formatting and prefixing can significantly impact model performance. In this section, we’ll look at two ways to evaluate text embedding models.
Arize-phoenix
Arize AI's Phoenix library is an excellent multipurpose tool that helps evaluate LLMs and embed models. In particular, it provides an easy and flexible way to log and view high-dimensional embeddings to understand where things may go wrong. Additionally, it considers the 'context length' which impacts the processing capabilities of texts with varying token limits. According to the README: “Phoenix provides an A/B testing framework to help you understand how your embeddings are changing over time and how they are changing between different versions of your model.”
Let’s run a quick example of using Phoenix to understand problematic embeddings. To do this, we’ll first revisit the IMDb dataset from before. Recall how we previously generated embeddings with the sentence-transformers library:
from datasets import load_dataset
from sentence_transformers import SentenceTransformer
# load the IMDB dataset
dataset = load_dataset("imdb", split="test")
# instantiate the model
model = SentenceTransformer("intfloat/e5-small-v2")
def generate_embeddings(dataset):
"""Generates embeddings for the input dataset.
"""
global model
return model.encode([row["text"] for row in dataset])
# generate embeddings
embeddings = generate_embeddings(dataset)
Words are represented as vectors in a continuous vector space, which helps capture semantic relationships and facilitates various AI applications by preserving the underlying meanings and connections among words.
We can load these into a pandas dataframe:
import pandas as pd
# create the pandas dataframe
df = pd.DataFrame({"embedding": embeddings.tolist()})
df["text"] = [row["text"] for row in dataset]
df["label"] = [row["label"] for row in dataset]
Which can then be directly used in Phoenix:
% pip install -U arize-phoenix
import phoenix as px
# create the schema
schema = px.Schema(
feature_column_names=["text"],
actual_label_column_name="label",
embedding_feature_column_names={
"text_embedding": px.EmbeddingColumnNames(
vector_column_name="embedding",
#link_to_data_column_name="text",
),
},
)
ds = px.Dataset(df, schema)
session = px.launch_app(primary=ds)
session.url
Here, we first created a `Schema` object. This schema defines the data associated with each embedding, which, in our case, is the text and the label. Once that’s done, we specify the data frame we created earlier and its schema for Phoenix before launching the app.
Opening the URL in a browser, we get a GUI that looks like this:
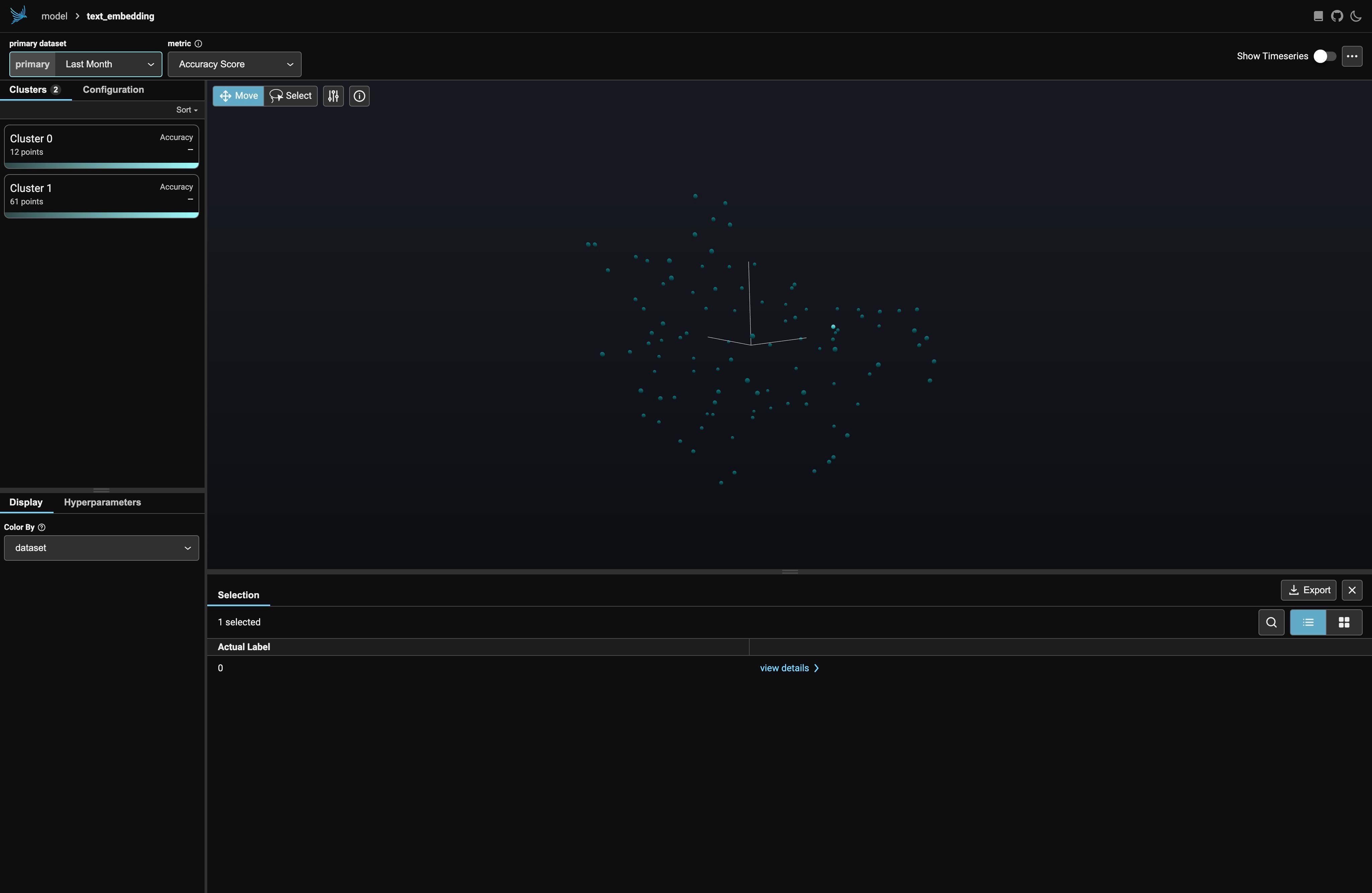
I’ve only displayed the first 100 elements of the IMDB test dataset here, along with an extra “mystery” embedding that isn’t a movie review. We might expect that embedding to look like an outlier among the rest of the data. Indeed, it is:
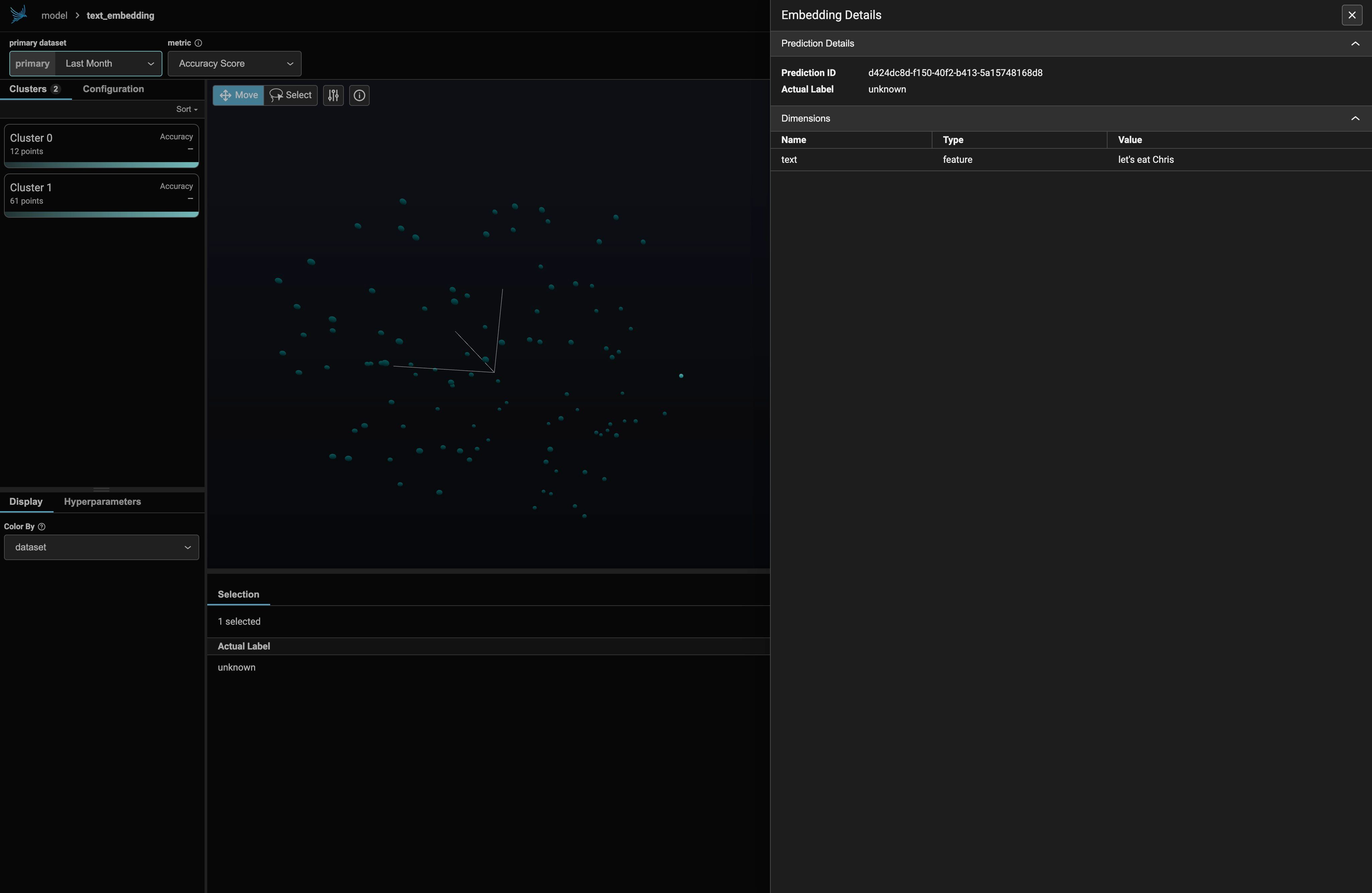
Ragas
Ragas (Retrieval-Augmented Generation ASsessment) is an open-source library for evaluating RAG pipelines. The transformer model, particularly BERT, is known for its ability to understand context from both directions, leading to improved performance in natural language processing tasks. I will only go over these in a bit of detail here, but check out our page) on RAG if you’d like to learn more.
The Massive Text Embedding Benchmark (MTEB) serves as a critical evaluation standard for text embedding models, validating their performance and effectiveness in real-world applications.
While building these RAG pipelines is supported by many existing tools such as Llamaindex or Haystack, measuring their performance can be challenging. That’s where Ragas comes into play. It offers tools to evaluate the text generated by LLMs, providing insights into how well your RAG pipeline is performing. Additionally, Ragas is built to integrate with CI/CD processes, allowing for regular performance checks to maintain and improve the quality of outcomes.
Let’s look at how we can use ragas to evaluate the performance of our embedding model. We’ll need to use a different dataset, but before we do that, let’s add in our OpenAI key so Ragas can use it for specific metrics:
import os
os.environ["OPENAI_API_KEY"] = "your-openai-key"
% pip install ragas
from ragas.metrics import context_recall, context_precision
From here, we’ll import metrics associated with the quality of our embedding model. The amnesty_qa dataset on Huggingface datasets is purpose-built for Ragas. It contains twenty rows with four pieces of data (columns) each: the question given to the LLM, a ground truth response, a response from the LLM, and the relevant context retrieved using our embedding model and vector database.
amnesty_qa = load_dataset("explodinggradients/amnesty_qa", "english_v2")
amnesty_qa
DatasetDict({
eval: Dataset({
features: ['question', 'ground_truth', 'answer', 'contexts'],
num_rows: 20
})
})
from ragas import evaluate
result = evaluate(
amnesty_qa["eval"],
metrics=[
context_precision,
context_recall,
],
)
result
We can do the same for the IMDb dataset by storing all the dataset vectors in a vector database, creating a couple of sample questions, and running through the same insertion and search process documented in an earlier blog.
Wrapping up
In this post, we looked at high-level strategies for evaluating embedding models, in particular open source embedding models and e5 large v2. Word embeddings are a critical component in natural language processing, utilizing statistical relationships between words to enhance language models and improve the representation of semantic information. Choosing the correct text embedding model is a reasonably strategic decision - you’ll need to understand the data each model was trained on and how they were trained. Various models yield different outputs in terms of quality and pertinence, making it essential to achieve consistency in delivering relevant results within specific ranks. By carefully considering the requirements of the underlying task you’re trying to solve in addition to using tools for visualizing embeddings (such as arize-phoenix) or retrieval systems (such as ragas), you can optimize your embeddings as well.
 Frank Liu
Frank LiuFrank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai and worked as an ML engineer at Yahoo in San Francisco. In his free time, Frank enjoys playing chess, swimming, and powerlifting. Frank holds MS and BS degrees in Electrical Engineering from Stanford University.
- Introduction to Evaluating your Embedding Models
- Key Considerations
- Evaluating Text Embeddings for Semantic Similarity
- Wrapping up
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Primer on Neural Networks and Embeddings for Language Models
Exploring neural network language models, specifically recurrent neural networks, and taking a sneak peek at how embeddings are generated.
Class Activation Mapping (CAM): Better Interpretability in Deep Learning Models
Class Activation Mapping (CAM) is used to visualize and understand the decision-making of convolutional neural networks (CNNs) for computer vision tasks.

All-Mpnet-Base-V2: Enhancing Sentence Embedding with AI
Delve into one of the deep learning models that has played a significant role in the development of sentence embedding: MPNet.