




Top 10 Natural Language Processing Tools and Platforms
An overview of the top ten NLP tools and platforms, highlighting their key features, applications, and advantages to help you select the best options for your needs.
Read the entire series
- An Introduction to Natural Language Processing
- Top 20 NLP Models to Empower Your ML Application
- Unveiling the Power of Natural Language Processing: Top 10 Real-World Applications
- Everything You Need to Know About Zero Shot Learning
- NLP Essentials: Understanding Transformers in AI
- Transforming Text: The Rise of Sentence Transformers in NLP
- NLP and Vector Databases: Creating a Synergy for Advanced Processing
- Top 10 Natural Language Processing Tools and Platforms
- 20 Popular Open Datasets for Natural Language Processing
- Top 10 NLP Techniques Every Data Scientist Should Know
- XLNet Explained: Generalized Autoregressive Pretraining for Enhanced Language Understanding
As artificial intelligence evolves quickly, its applications become increasingly diverse and important to our daily lives. One of the most significant areas where AI has made a significant impact is in Natural Language Processing (NLP). NLP is the branch of AI that focuses on the interaction between computers and human language, enabling machines to understand, interpret, and respond to human communication. The rise of big data has also increased the importance of NLP. This technology offers a wide range of real-world NLP applications, like chatbots utilizing large language models (LLM), virtual assistants, translation services, and sentiment analysis tools.
Top 10 NLP Tools and Platforms
The vast growth in NLP has led to the development of various tools and platforms designed to assist researchers, data scientists, and developers in their projects. These tools range from comprehensive libraries that offer a suite of functionalities to specialized platforms designed for specific tasks like text classification or entity recognition.
Understanding these tools' capabilities and advantages can greatly impact your project's success. Choosing the right tools will enhance your NLP projects' efficiency and effectiveness. This guide provides an overview of the top ten NLP tools and platforms, highlighting their key features, applications, and advantages to help you select the best options for your needs.
NLTK (Natural Language Toolkit)
The Natural Language Toolkit, or NLTK, is a comprehensive library for Python developers working with human language data. It is widely used in educational and research settings, offering essential tools for text processing and linguistic data analysis.
Key Features
NLTK has rich text-processing libraries for classification, tokenization, stemming, tagging, parsing, etc.
It benefits from a large, active community that provides support through forums, tutorials, and code examples.
NLTK's versatility makes it suitable for a wide range of NLP tasks, from text preprocessing to advanced analysis.
It integrates well with other libraries such as SciPy and NumPy, enhancing its capabilities for data analysis.
Applications
NLTK is ideal for educational purposes, providing extensive documentation and tutorials that make it perfect for teaching NLP concepts.
It supports the quick development of NLP applications like chatbots and text summarizers, making it a valuable tool for prototyping.
Additionally, NLTK is widely used in research for experiments involving text classification, parsing, and semantic analysis.
Advantages
NLTK offers extensive documentation with detailed examples and tutorials, making it easy for users to understand and utilize its features.
The library benefits from a large, active community that provides support through forums, tutorials, and code examples.
Below is how you can get started with NLTK quickly.
import nltk
from nltk.tokenize import word_tokenize
# Download the NLTK data packages
nltk.download('punkt')
# Tokenize a sample sentence
text = "This is a sample text."
tokens = word_tokenize(text)
print(tokens)
SpaCy
SpaCy is an open-source software library designed for advanced NLP in Python. It is known for its speed and accuracy, making it ideal for both research and industrial applications. Its ability to process large volumes of text rapidly and integrate with other tools makes it a powerful asset for any NLP project.
Key Features
SpaCy is built for performance, offering fast processing and highly accurate results, which is essential for real-time applications.
It provides pre-trained models for multiple languages, allowing users to immediately apply complex NLP tasks without extensive training.
The library includes an efficient pipeline for essential NLP tasks such as tokenization, part-of-speech tagging, named entity recognition, dependency parsing, and more.
SpaCy supports integration with other NLP libraries like Gensim and Scikit-learn, enabling users to expand their capabilities further.
Applications
SpaCy is widely used in commercial environments for large-scale NLP tasks, including real-time text processing, automated content generation, and sentiment analysis.
It is commonly applied to tasks like entity recognition, part-of-speech tagging, and dependency parsing, helping structure and understand large text datasets.
SpaCy is useful for extracting structured data from unstructured text, such as names, dates, and other entities from documents.
Advantages
Designed to handle large volumes of text quickly and efficiently, which is critical in processing big data.
Integrates seamlessly with other Python libraries and frameworks, making it versatile for various applications.
Comprehensive and clear documentation, with numerous examples and tutorials, helps users get started quickly and efficiently.
Below is how you can get started with SpaCy quickly.
import spacy
# Load the spaCy model
nlp = spacy.load('en_core_web_sm')
# Process a sample sentence
text = "Natural Language Processing with spaCy is efficient."
doc = nlp(text)
# Extract tokens
tokens = [token.text for token in doc]
print(tokens)
TensorFlow Text
TensorFlow Text is a specialized library built on TensorFlow, designed for working with a range of NLP tasks. It leverages TensorFlow’s robust machine-learning capabilities to provide state-of-the-art tools for building and training complex NLP models.
Key Features
Offers comprehensive tools for building and training models for text classification, translation, and sentiment analysis.
Provides pre-trained models that can be fine-tuned and also allows custom model training from scratch.
Seamlessly integrates with the TensorFlow ecosystem, utilizing its machine learning and neural network capabilities.
Supports advanced NLP functions like sequence-to-sequence modeling, transformers, and BERT.
Applications
Ideal for developing and deploying advanced deep learning models for NLP tasks like neural machine translation, question answering, and text summarization, sentiment analysis, entity recognition, and language generation.
Frequently used in advanced research to develop new models and algorithms, leveraging TensorFlow's flexibility and power.
Advantages
Utilizes TensorFlow’s powerful machine learning framework to provide high performance and scalability.
Offers extensive customization options, allowing users to tailor models and workflows to their specific needs.
Backed by TensorFlow’s large community and extensive resources, including documentation, tutorials, and forums, providing strong support for users at all levels.
Below is how you can get started with TensorFlow quickly.
import tensorflow as tf
import tensorflow_text as text # Imports TF ops for text processing.
# Create a TextVectorization layer
vectorize_layer = tf.keras.layers.TextVectorization(output_mode='int', output_sequence_length=10)
# Example data
text_data = ["TensorFlow NLP makes text processing easy."]
# Fit the layer to the data
vectorize_layer.adapt(text_data)
# Vectorize the text data
vectorized_text = vectorize_layer(text_data)
print(vectorized_text)
Hugging Face Transformers
Hugging Face Transformers is a popular open-source library that provides access to various pre-trained transformer models for NLP tasks. It is highly regarded for its ease of use and expensive collection of models.
Key Features
Includes a broad range of transformer models such as BERT, GPT-2, T5, and many others.
Provides pre-trained models on vast datasets, allowing users to apply them with minimal additional training.
Easily integrates with popular frameworks like TensorFlow and PyTorch, offering flexibility in deployment.
Offers a user-friendly API that simplifies loading, fine-tuning, and using transformer models.
Applications
Models like GPT-2 generate coherent and contextually relevant text, which is useful in applications like chatbots and content creation.
Models such as T5 can be used to translate text between different languages.
Transformer models can generate concise summaries of lengthy documents, making them useful for information retrieval and content aggregation.
Pre-trained models can be fine-tuned to answer questions based on context, useful in building intelligent search engines and virtual assistants.
Advantages
The simple API allows even those with minimal NLP experience to implement advanced models easily.
The extensive collection of pre-trained models covers a wide range of tasks and languages, providing ready-to-use solutions for diverse NLP challenges.
Hugging Face has a vibrant community and extensive documentation, including tutorials and example projects, facilitating quick learning and troubleshooting.
Below is how you can get started with Hugging Face Transformers quickly.
from transformers import pipeline
# Load a pre-trained pipeline for sentiment analysis
classifier = pipeline('sentiment-analysis')
# Analyze a sample sentence
result = classifier("My experience with Hugging Face Transformers is great.")
print(result)
Gensim
Gensim is a Python library that analyzes document similarity and performs topic modeling. It is known for its efficiency and scalability in processing large text datasets.
Key Features
Implements well-known algorithms like Word2Vec, FastText, and Doc2Vec for creating word embeddings and analyzing text.
Supports techniques like Latent Dirichlet Allocation (LDA) and Latent Semantic Indexing (LSI) to uncover hidden thematic structures in a corpus.
Provides tools to measure the semantic similarity between documents, aiding in clustering and recommendation systems.
Optimized to handle large corpora efficiently, making it suitable for big data applications.
Applications
Helps discover hidden topics within large collections of documents, useful for content categorization, trend analysis, and information retrieval.
Identifies similar documents based on content, useful in search engines, recommendation systems, and clustering tasks.
Generates dense vector representations of words, capturing their semantic relationships for various NLP tasks like sentiment analysis and machine translation.
Facilitates summarization, keyword extraction, and other text analysis tasks.
Advantages
Optimized for performance, capable of processing large datasets quickly and effectively.
Designed to handle large text corpora without compromising speed.
User-friendly interfaces and comprehensive documentation make it accessible to both beginners and experienced users.
Here is how you can get started with Gensim quickly.
from gensim.models import Word2Vec
# Sample data
sentences = [["Gensim", "is", "a", "library", "for", "topic", "modeling"],
["It", "supports", "Word2Vec", "FastText", "and", "Doc2Vec"]]
# Train a Word2Vec model
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# Get the vector for a word
vector = model.wv['Gensim']
print(vector)
OpenNLP
OpenNLP is an Apache project that provides a machine learning-based toolkit for processing natural language text. It offers a comprehensive set of tools to handle various NLP tasks effectively.
Key Features
Breaks text into individual tokens, such as words or phrases, essential for further text analysis.
Identifies and tags parts of speech in text, facilitating grammatical analysis.
Detects and classifies entities like names, dates, and locations within text.
Analyzes the syntactic structure of sentences to understand grammatical relationships.
Identifies when different expressions in a text refer to the same entity, enhancing text understanding.
Applications
Extracts structured information from unstructured text, such as identifying entities and relationships in documents.
Used in various tasks like summarization, translation, and question answering.
Prepares raw text data for machine learning models by performing tasks like tokenization, tagging, and parsing.
Advantages
Designed to handle large and complex text data, ensuring reliable performance across different NLP tasks.
Well-integrated with other Apache tools and libraries, enhancing its functionality and usability in broader data processing pipelines.
Modular design allows users to extend and customize the toolkit to fit their needs.
Here is how you can get started with OpenNLP quickly.
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import java.io.FileInputStream;
import java.io.InputStream;
// Load the sentence detection model
InputStream modelIn = new FileInputStream("en-sent.bin");
SentenceModel model = new SentenceModel(modelIn);
// Create a sentence detector
SentenceDetectorME sentenceDetector = new SentenceDetectorME(model);
// Detect sentences in a sample text
String sentences[] = sentenceDetector.sentDetect("OpenNLP is great. It helps in sentence detection.");
for (String sentence : sentences) {
System.out.println(sentence);
}
AllenNLP
AllenNLP is an open-source library designed specifically for deep learning-based natural language processing. Developed by the Allen Institute for AI, it provides researchers and developers with the tools needed to create, evaluate, and deploy state-of-the-art NLP models.
Key Features
Utilizes PyTorch as its backend, offering flexibility and ease of use for developing deep learning models.
Provides high-level abstractions for common NLP tasks such as text classification, named entity recognition, and machine translation, simplifying model development.
Designed to be highly customizable, allowing users to modify and extend its components to suit their specific needs.
Includes a collection of pre-trained models and model architectures, facilitating quick experimentation and prototyping.
Applications
Widely used in academic and industrial research for developing and testing new NLP models and algorithms.
Ideal for rapidly prototyping new ideas and approaches in NLP due to its user-friendly design and comprehensive toolset.
Provides tools for evaluating model performance on various NLP tasks, ensuring robust and reliable results.
Advantages
Highly customizable, allowing users to tailor the library to their specific requirements and integrate it with other tools and libraries.
Backed by an active community and extensive documentation, including tutorials and example projects, aiding learning and troubleshooting.
Seamless integration with PyTorch, leveraging its powerful deep learning capabilities and extensive ecosystem.
Here is how you can get started with AllenNLP quickly.
from allennlp.predictors.predictor import Predictor
import allennlp_models.structured_prediction
# Load a pre-trained model for semantic role labeling
predictor = Predictor.from_path("https://storage.googleapis.com/allennlp-public-models/bert-base-srl-2020.03.24.tar.gz")
# Analyze a sample sentence
result = predictor.predict(sentence="AllenNLP is designed for deep learning-based NLP.")
print(result)
TextBlob
TextBlob is a simple library for processing textual data, designed to provide an easy-to-use API for common NLP tasks. It is particularly suitable for beginners and for quickly prototyping NLP applications.
Key Features
Offers a straightforward and user-friendly API for performing various NLP tasks like identifying parts of speech in text, and extracting noun phrases from the text, which is useful for understanding the main subjects and objects.
Examines text to identify its sentiment, classifying it as either positive, negative, or neutral.
Provides tools for text classification, allowing categorization of text into predefined labels.
Supports translation between different languages.
Applications
Great for teaching and learning NLP concepts, providing a clear and accessible introduction to various text-processing tasks.
Suitable for simple and quick text analysis tasks using prototyping such as sentiment analysis, tagging, and translation.
Advantages
Designed to be intuitive and easy to use, making it accessible for beginners.
Allows rapid development and testing of NLP applications, facilitating experimentation and learning.
Here is how you can get started with TextBlob quickly.
from textblob import TextBlob
# Create a TextBlob object
text = "TextBlob simplifies NLP tasks."
blob = TextBlob(text)
# Perform sentiment analysis
sentiment = blob.sentiment
print(sentiment)
CoreNLP
CoreNLP is a comprehensive suite of NLP tools provided by Stanford University. It offers a range of tools for processing natural language text, known for their high accuracy and robust performance.
Key Features
Provides syntactic parsing tools to analyze the grammatical structure of sentences.
Evaluates text to classify its sentiment, sorting it into positive, negative, or neutral categories.
Identifies and classifies named entities within text, such as names, dates, and locations.
Tags words in a text with their respective parts of speech.
Determines which words refer to the same entities in a text, enhancing text understanding.
Reduces words to their base or root form.
Applications
Widely used in academic settings for conducting research in NLP and computational linguistics.
Suitable for large-scale text processing tasks in various industries, including sentiment analysis, information extraction, and text summarization.
Advantages
Known for its precise and reliable performance in various NLP tasks.
Capable of handling large datasets efficiently, making it suitable for both research and industrial applications.
Developed and maintained by Stanford University, ensuring it stays up-to-date with the latest advancements in NLP research.
Here is how you can get started with CoreNLP quickly.
from stanfordcorenlp import StanfordCoreNLP
# Initialize StanfordCoreNLP
nlp = StanfordCoreNLP(r'/path/to/stanford-corenlp-full-2018-10-05')
# Analyze a sample sentence
sentence = 'CoreNLP provides accurate and robust NLP tools.'
tokens = nlp.word_tokenize(sentence)
print(tokens)
# Close the NLP pipeline
nlp.close()
IBM Watson NLP
IBM Watson NLP is a cloud-based natural language processing platform developed by IBM. It provides a comprehensive suite of NLP services designed to handle various text-processing tasks at an enterprise level.
Key Features
Translates text between multiple languages, facilitating global communication.
Analyzes text to determine sentiment, categorizing it as positive, negative, or neutral.
Detects and categorizes named entities in text, including individuals, organizations, and places.
Converts text to spoken words and vice versa, useful for voice-driven applications.
Allows users to train custom NLP models tailored to specific business needs.
Seamlessly integrates with other IBM Cloud services for enhanced functionality.
Applications
Ideal for large organizations needing robust NLP capabilities for applications like customer service, automated support, and content management.
Used by businesses to provide multilingual customer support and global communication solutions.
Advantages
Designed to handle large volumes of data, making it suitable for enterprise-scale applications.
Provides dedicated support and resources for businesses, ensuring reliability and performance.
Offers extensive customization options, allowing businesses to tailor NLP models to their specific needs.
Being cloud-based, it provides easy access and integration, reducing the need for complex on-premise setups.
Here is how you can get started with IBM Watson NLP quickly.
import json
from ibm_watson import NaturalLanguageUnderstandingV1
from ibm_watson.natural_language_understanding_v1 import Features, SentimentOptions
# Initialize IBM Watson NLP
nlu = NaturalLanguageUnderstandingV1(
version='2019-07-12',
iam_apikey='YOUR_API_KEY',
url='YOUR_SERVICE_URL'
)
# Analyze a sample sentence
response = nlu.analyze(
text='IBM Watson NLP is highly scalable and offers great enterprise support.',
features=Features(sentiment=SentimentOptions())
).get_result()
print(json.dumps(response, indent=2))
The below table provides quick insights to compare all the tools and platforms based on their language support, whether they are open-source, licensed, and their price.
| Tools | Language Support | Open Source | License | Cost |
| NLTK (Natural Language Toolkit) | Python | Yes | Apache 2.0 | Free |
| spaCy | Python | Yes | MIT | Free |
| TensorFlow NLP | Python (built on TensorFlow) | Yes | Apache 2.0 | Free |
| Hugging Face Transformers | Python | Yes | Apache 2.0 | Free |
| Gensim | Python | Yes | LGPL | Free |
| OpenNLP | Java | Yes | Apache 2.0 | Free |
| AllenNLP | Python (built on PyTorch) | Yes | Apache 2.0 | Free |
| TextBlob | Python | Yes | MIT | Free |
| CoreNLP | Java | Yes | GPL | Free |
| IBM Watson NLP | Various | No | Proprietary | Starts at $0.003 per item |
Table: Top 10 NLP tools and platforms comparison
How Does Zilliz Help With Natural Language Processing?
Developers are transforming Natural Language Processing (NLP) with vector databases, which allow efficient storage and retrieval of NLP model-generated vector embeddings. This innovation simplifies finding similar documents, phrases, or words based on semantic similarity.
Another popular use case of vector databases is Retrieval Augmented Generation (RAG). It is a technique to address the hallucination issues of Large Language Models (LLMs). These models are typically trained on publicly available data and may lack domain-specific or proprietary information. Developers can store such specialized data in a vector database like Milvus, perform a similarity search to find the top-K relevant results and feed these results into the LLM. This approach ensures that the LLM generates accurate responses based on both general and domain-specific information.
Hence, by leveraging Milvus, developers can enhance the capabilities of NLP applications, ensuring more precise and contextually relevant outputs.
Developers are transforming Natural Language Processing (NLP) by integrating vector databases. This technology enables efficient storage and retrieval of vector embeddings generated by NLP models, making it easier to identify similar documents, phrases, or words based on semantic similarity.
One prominent application of vector databases is Retrieval Augmented Generation (RAG), a technique that addresses the hallucination issues in Large Language Models (LLMs). LLMs are often trained on publicly available data and may not include domain-specific or proprietary information. By storing this specialized data in a vector database like Milvus, developers can perform a similarity search to retrieve the top-K relevant results and feed these into the LLM. This ensures that the LLM generates accurate and contextually relevant responses by combining general and domain-specific information.
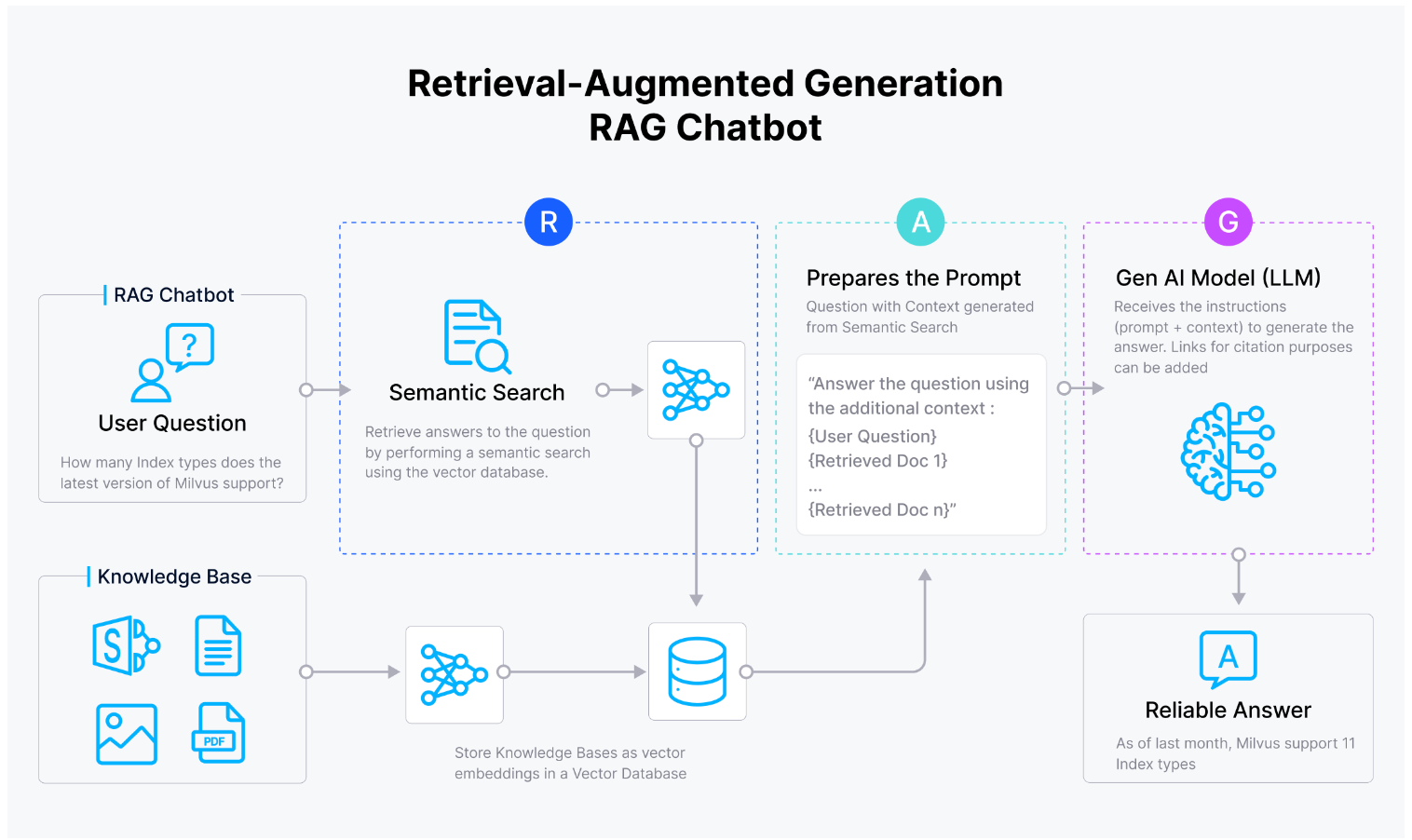 Figure- Vector database facilitating RAG chatbot
Figure- Vector database facilitating RAG chatbot
Check out this video to learn more about Milvus and vector databases.
Conclusion
Natural Language Processing (NLP) tools and platforms are crucial in enhancing the efficiency and effectiveness of various text-processing tasks. From NLTK and spaCy to IBM Watson and Hugging Face Transformers, each tool offers unique features and advantages tailored to specific needs, whether for educational purposes, research, or large-scale industrial applications. Among these tools, integrating vector databases like Milvus can transform various areas by enabling efficient storage, retrieval, and analysis of vector embeddings.
Related Resources
 Fariba Laiq
Fariba LaiqDescription: Fariba Laiq is a freelance content writer at Zilliz. She has studied Computer Science, been a coding instructor, and published research papers in the domain of AI and cyber-security. She is passionate about learning more about LLMs and vector databases in the ever evolving era of AI. Along with technical skills, she is also a self-taught artist.
- Top 10 NLP Tools and Platforms
- NLTK (Natural Language Toolkit)
- SpaCy
- TensorFlow Text
- Hugging Face Transformers
- Gensim
- OpenNLP
- AllenNLP
- TextBlob
- CoreNLP
- IBM Watson NLP
- How Does Zilliz Help With Natural Language Processing?
- Conclusion
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

An Introduction to Natural Language Processing
Learn the intricacies of Natural Language Processing and how vector databases, like Zilliz Cloud, transform NLP with efficient embedding storage and retrieval.

Everything You Need to Know About Zero Shot Learning
A comprehensive guide to Zero-Shot Learning, covering its methodologies, its relations with similarity search, and popular Zero-Shot Classification Models.

Top 10 NLP Techniques Every Data Scientist Should Know
In this article, we will explore the top 10 techniques widely used in NLP with clear explanations, applications, and code snippets.