




Exploring BGE-M3 and Splade: Two Machine Learning Models for Generating Sparse Embeddings
In this blog, we’ve journeyed through the intricate world of vector embeddings and explored how BGE-M3 and Splade generate learned sparse embeddings.
Read the entire series
- Exploring BGE-M3 and Splade: Two Machine Learning Models for Generating Sparse Embeddings
- Comparing SPLADE Sparse Vectors with BM25
- Exploring ColBERT: A Token-Level Embedding and Ranking Model for Efficient Similarity Search
- Vectorizing and Querying EPUB Content with the Unstructured and Milvus
- What Are Binary Embeddings?
- A Beginner's Guide to Website Chunking and Embedding for Your RAG Applications
- An Introduction to Vector Embeddings: What They Are and How to Use Them
- Image Embeddings for Enhanced Image Search: An In-depth Explainer
- A Beginner’s Guide to Using OpenAI Text Embedding Models
- DistilBERT: A Distilled Version of BERT
- Unlocking the Power of Vector Quantization: Techniques for Efficient Data Compression and Retrieval
In my previous blog, we explored the evolution of information retrieval techniques from simple keyword matching to sophisticated context understanding and introduced the concept that sparse embeddings can be "learned." These clever embeddings merge the strengths of both dense and sparse retrieval methods. Learned sparse embeddings address the typical out-of-domain issues prevalent in dense retrieval and enhance traditional sparse methods by integrating contextual information.
Given the numerous benefits of learned sparse embeddings, you might wonder what models generate them and how they do that. This article will look at two cutting-edge models for crafting these embeddings: BGE-M3 and Splade. We'll jump into their designs and the principles behind them.
A Quick Recap of Vector Embeddings
Vector embeddings, or vector representations, are numerical representations of objects, concepts, or entities within a high-dimensional vector space. Each entity is represented by a vector comprising real numbers, usually fixed in length, with each vector dimension representing a distinct attribute or feature of the entity. There are typically three main embedding types: (traditional) sparse embeddings, dense embeddings, and "learned" sparse embeddings.
Traditional sparse embeddings, typically used in language processing, are high-dimensional, with many dimensions containing zero values. These dimensions often represent different tokens across one or more languages, with non-zero values indicating the token's relative importance in a specific document. Sparse embeddings, such as those generated by the BM25 algorithm—which refines the TF-IDF approach by adding a term frequency saturation function and a length normalization factor—are perfect for keyword-matching tasks.
In contrast, dense embeddings are lower-dimensional but packed with information, with all dimensions containing non-zero values. These vectors are often produced by models like BERT and used in semantic search tasks, where results are ranked based on the closeness of the semantic meaning rather than exact keyword matches.
“Learned” sparse embeddings are an advanced type of embedding that combines the precision of traditional sparse embeddings with the semantic richness of dense embeddings. They enhance the sparse retrieval approach by incorporating contextual information. Machine learning models like Splade and BGE-M3 generate learned sparse embeddings. They can learn the importance of related tokens that may not be explicitly present in the text, resulting in a 'learned' sparse representation that effectively captures all relevant keywords and classes.
Check out this step-by-step guide for more information about performing sparse or hybrid sparse and dense vector search with a vector database like Milvus.
BERT: The Foundation Model for BGE-M3 and Splade
BGE-M3 and Splade models are built upon the foundational BERT architecture. So, before we dig into their capabilities, we need to understand the underlying mechanics of BERT and how it serves as a cornerstone for advancing embedding technology. Let's dive in.
BERT, or Bidirectional Encoder Representations from Transformers, represents a leap in Natural Language Processing (NLP). Unlike traditional models that process text sequentially, either from left to right or right to left, BERT captures the context of words by examining the entire sequence of words simultaneously rather than in one direction.
The essence of BERT lies in its pre-training process, which is not just a routine but a combination of two innovative strategies:
Masked Language Modeling (MLM): This task randomly hides a portion of the input tokens and then trains the model to predict these masked tokens. Unlike previous language models that might only understand unidirectional context, BERT fills in the blanks by considering the entire context of the sentence, both the left and right of the masked word.
Next Sentence Prediction (NSP): In this task, BERT learns to predict whether one sentence logically follows another, which is crucial for understanding relationships between sentences, such as those found in paragraph structures.
An integral feature of BERT's architecture is its self-attention mechanism. Each encoder layer in the transformer uses self-attention to weigh the importance of other words in the sentence when interpreting a specific word, allowing for a rich understanding of word meaning in different contexts.
Positional encoding is another critical element that allows BERT to understand the order of words, adding a sense of "sequence" to the otherwise position-agnostic self-attention process.
How Does BERT Work?
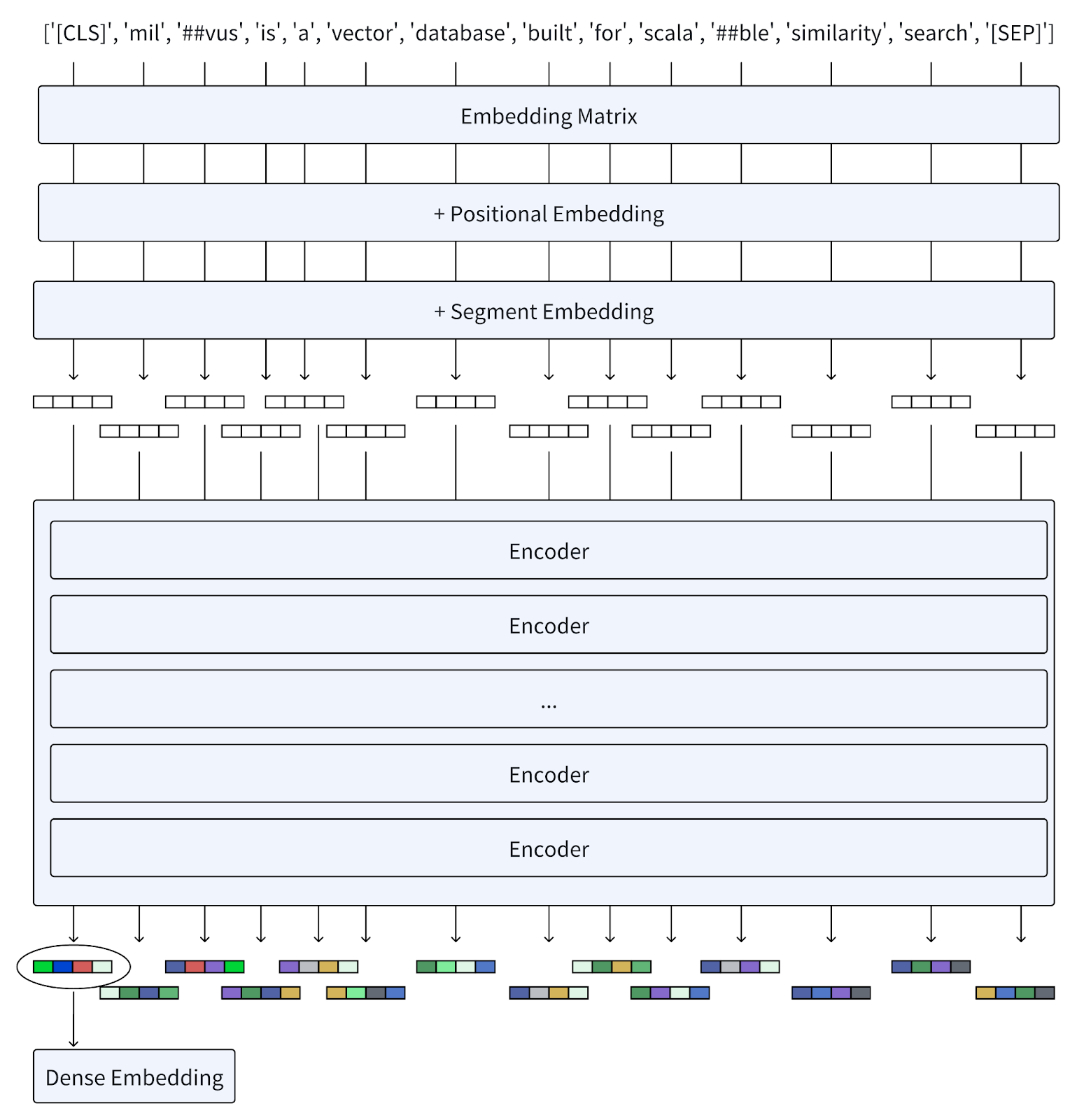
So, how does BERT work? Let’s ask BERT to embed the following sentence into embeddings.
User query: Milvus is a vector database built for scalable similarity search.
 From words to tokens
From words to tokens
 From tokens to BERT dense embeddings
From tokens to BERT dense embeddings
When we feed a query into BERT, the process unfolds as follows:
Tokenization: The text is first tokenized into a sequence of word pieces. The
[CLS]token is prepended to the input for sentence-level tasks, and[SEP]tokens are inserted to separate sentences and indicate the end.Embedding: Each token is converted into vectors using an embedding matrix, similar to models like Word2Vec. Positional embeddings are added to these token embeddings to preserve information about the order of words, while segment embeddings distinguish different sentences.
Encoders: The vectors pass through multiple layers of encoders, each composed of self-attention mechanisms and feed-forward neural networks. These layers iteratively refine the representation of each token based on the context provided by all other tokens in the sequence.
Output: The final layer outputs a sequence of embeddings. Typically, for sentence-level tasks, the embeddings of the
[CLS]token are the aggregate representation of the entire input. Embeddings of individual tokens are utilized for fine-grained tasks or combined via operations like max or sum pooling to form a singular dense representation.
BERT generates dense embeddings that capture the meaning of individual words and their interrelations within sentences. This approach has proven immensely successful in various language understanding tasks, setting new standards in NLP benchmarks.
Since we’ve understood how BERT generates dense embeddings, let’s explore BGE-M3 and Splade and how they generate learned sparse embeddings.
BGE-M3
BGE-M3 is an advanced machine-learning model that extends BERT's capabilities. It focuses on enhancing text representation through Multi-Functionality, Multi-Linguisticity, and Multi-Granularity. Its design goes beyond generating dense embeddings, integrating the ability to produce learned sparse embeddings that balance semantic meaning with lexical precision, a feature particularly useful for nuanced information retrieval.
How does BGE-M3 work?
How does BGE-M3 work to generate learned sparse embeddings? Let’s use the same user query above to illustrate this process.
From words to tokens
Generating these learned sparse embeddings begins with the same foundational steps as BERT—tokenization and encoding the input text into a sequence of contextualized embeddings ( H ).
 From tokens to sparse embeddings.png
From tokens to sparse embeddings.png
However, BGE-M3 innovates this process by utilizing a more granular approach to capture the significance of each token:
- Token Importance Estimation: Instead of relying solely on the
[CLS]token representation ( H[0] ), BGE-M3 evaluates the contextualized embedding of each token ( H[i] ) within the sequence. - Linear Transformation: An additional linear layer is appended to the output of the stack of encoders. This layer computes the importance weights for each token. By passing the token embeddings through this linear layer, BGE-M3 obtains a set of weights ( W_{lex} ).
- Activation Function: A Rectified Linear Unit (ReLU) activation function is applied to the product of ( W_{lex} ) and ( H[i] ) to compute the term weight ( w_{t} ) for each token. Using ReLU ensures that the term weight is non-negative, contributing to the sparsity of the embedding.
- Learned Sparse Embedding: The output result is a sparse embedding, where each token is associated with a weight value, indicating its importance in the context of the entire input text.
This representation enriches the model's understanding of language nuances and tailors the embeddings for tasks where both semantic and lexical elements are critical, such as search and retrieval in large databases. It's a significant step towards more precise and efficient mechanisms for sifting through and making sense of vast textual data.
SPLADE
SPLADE represents an evolution in generating learned sparse embeddings, building upon the foundational BERT architecture with a unique methodology to refine the embedding sparsity. To grasp this methodology, we should revisit the core of BERT’s training mechanism, the Masked Language Modeling (MLM).
MLM is a powerful unsupervised learning task that conceals a fraction of the input tokens, compelling the model to deduce the hidden words based solely on their context. This technique enriches the model's linguistic comprehension and structural awareness of language, as it depends on adjacent tokens to fill the gaps with accurate predictions.
![MLM predicts the original token based on the BERT embedding of [MASK]](https://assets.zilliz.com/MLM_predicts_the_original_token_based_on_the_BERT_embedding_of_MASK_9473778df6.png) MLM predicts the original token based on the BERT embedding of [MASK]
MLM predicts the original token based on the BERT embedding of [MASK]
In practice, for every masked slot during the pre-training, the model utilizes the contextualized embedding ( H[i] ) from BERT to output a probability distribution ( w_i ), with ( w_{ij} ) denoting the likelihood that a specific BERT vocabulary token occupies the masked position. This output vector ( w_i ), whose length matches the size of BERT's extensive vocabulary (typically 30,522 words), serves as a pivotal learning signal for refining the model's predictions.
 MLM aggregates the score of each token from all positions.
MLM aggregates the score of each token from all positions.
Note: The probabilities in this diagram are made up, but you’ll get the idea.
SPLADE leverages the power of MLM during the encoding phase. After initial tokenization and conversion to BERT embeddings, SPLADE applies MLM across all token positions, calculating the probability that each token corresponds to every word in BERT's vocabulary. SPLADE then aggregates these probabilities for each vocabulary word across all positions, applying a regularization method to promote sparsity by implementing a log saturation effect. The resulting weights refer to the relevance of each vocabulary word to the input tokens, thus creating a learned sparse vector.
A significant advantage of SPLADE's embedding technique is its inherent capacity for term expansion. It identifies and includes relevant terms not present in the original text. For instance, in the example provided, tokens such as "exploration" and "created" emerge in the sparse vector despite their absence from the initial sentence. Remarkably, for a brief input like "milvus is a vector database built for scalable similarity search," SPLADE can enrich the context by expanding it to include 118 tokens. It significantly enhances exact term-matching capabilities in retrieval tasks and improves the model's precision.
This elaborate process underscores how SPLADE extends the traditional BERT embeddings, imbuing them with higher granularity and utility for tasks such as search and retrieval, where the breadth and specificity of term relevance matter.
Wrapping Up
In this blog, we've journeyed through the intricate world of vector embeddings, from the traditional sparse and dense forms to the innovative learned sparse embeddings. We also explored two machine learning models— BGE-M3 and Splade–and how they work to generate learned sparse embeddings.
The ability to refine search and retrieval systems with these sophisticated embeddings opens new possibilities for developing intuitive and responsive platforms. Stay tuned for future posts on practical applications and use cases that showcase these technologies' impact, promising to redefine information retrieval standards.
 Buqian Zheng
Buqian ZhengBuqian Zheng is a Senior Software Engineer at Zilliz, specializing in developing the core vector index engine of Milvus. Before joining Zilliz, he was a Software Engineer at Google, where he contributed to projects such as Google Cloud Dataflow and managed Google-scale data analytic services. With a wealth of industry experience in managing massive data and infrastructures, Buqian brings invaluable expertise to his role. He holds a Master’s degree from Carnegie Mellon University.
- A Quick Recap of Vector Embeddings
- BERT: The Foundation Model for BGE-M3 and Splade
- BGE-M3
- SPLADE
- Wrapping Up
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

An Introduction to Vector Embeddings: What They Are and How to Use Them
In this blog post, we will understand the concept of vector embeddings and explore its applications, best practices, and tools for working with embeddings.

A Beginner’s Guide to Using OpenAI Text Embedding Models
A comprehensive guide to using OpenAI text embedding models for embedding creation and semantic search.

DistilBERT: A Distilled Version of BERT
DistilBERT maintains 97% of BERT's language understanding capabilities while being 40% small and 60% faster.