




All-Mpnet-Base-V2: Enhancing Sentence Embedding with AI
Delve into one of the deep learning models that has played a significant role in the development of sentence embedding: MPNet.
Read the entire series
- Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
- Primer on Neural Networks and Embeddings for Language Models
- Sparse and Dense Embeddings
- Sentence Transformers for Long-Form Text
- Training Your Own Text Embedding Model
- Evaluating Your Embedding Model
- Class Activation Mapping (CAM): Better Interpretability in Deep Learning Models
- CLIP Object Detection: Merging AI Vision with Language Understanding
- Discover SPLADE: Revolutionizing Sparse Data Processing
- Exploring BERTopic: A New Era of Neural Topic Modeling
- Streamlining Data: Effective Strategies for Reducing Dimensionality
- All-Mpnet-Base-V2: Enhancing Sentence Embedding with AI
- Time Series Embedding in Data Analysis
- Enhancing Information Retrieval with Learned Sparse Retrieval
- What is BERT (Bidirectional Encoder Representations from Transformers)?
- What is Mixture of Experts (MoE)?
Natural Language Processingg (NLP) is a rapidly evolving field. This comes as no surprise, given that text representation is a crucial concept used in various deep learning applications, such as text classification, named-entity recognition, text generation, document summarization, machine translation, information retrieval, and many more. In the context of deep learning, raw text needs to be transformed into numerical forms that a deep learning model can understand. This numerical representation of a text is commonly referred to as an embedding.
Traditional embedding approaches often relied on bag-of-words (BoW) or n-gram methods to represent text. While these methods are effective to some extent, they often fail to capture the semantic meaning and context of the text. With advancements in deep learning techniques, sentence embedding has emerged as a revolutionary approach to address this limitation. Efficient deep learning frameworks, such as JAX and Flax, play a crucial role in these advancements by enhancing the training process on large datasets.
In this article, we will delve into one of the deep learning models that has played a significant role in the development of sentence embedding: MPNet. So, without further ado, let’s dive in!
In the early days of NLP and AI, bag-of-words or n-gram-based models, such as Word2Vec and GloVe, were the go-to methods for transforming text into embeddings. While these models can effectively capture the semantic meaning of individual words, they often fail to capture the entire text’s semantic meaning and contextual nuances.
Consider the word “park” in two different sentences: “I park my car in the garage” and “I spend the whole day relaxing in a park.” With Word2Vec or GloVe, the word “park” would have the same embedding in both sentences, even though it is used in two different contexts. This can lead to significant inaccuracies when inferring the meaning of a text, highlighting the urgent need for a more accurate model. Moreover, these models produce embeddings at the word level, which can be problematic when working with text at the sentence level.
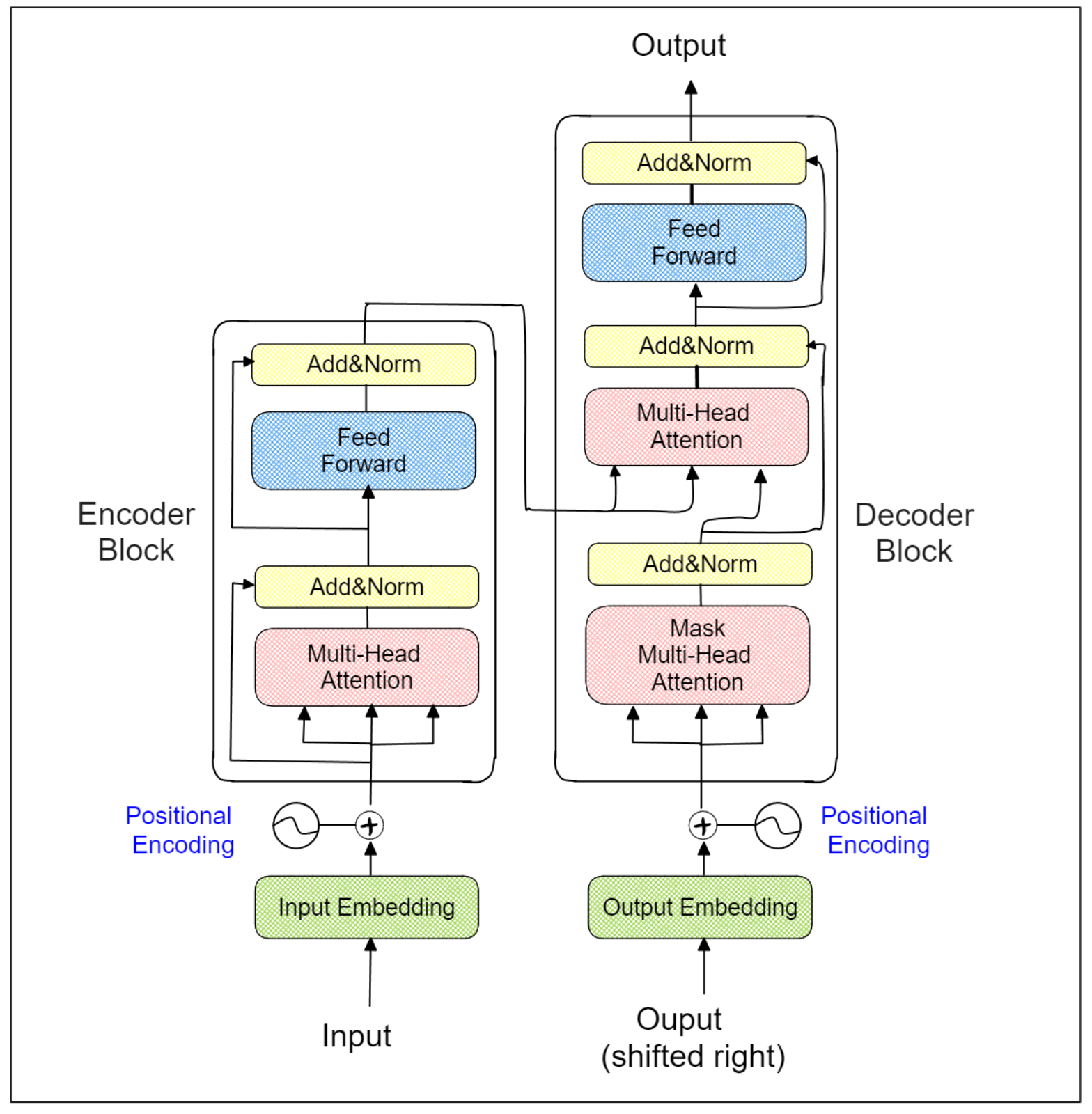
The emergence of Sentence Transformers has addressed this issue. As the name suggests, Sentence Transformers uses the popular Transformers architecture as its backbone. The architecture of a Transformer model consists of several encoder-decoder blocks, as illustrated below:
 Transformers architecture.png
Transformers architecture.png
Transformers architecture.png
The specialized multi-head attention layer within each Transformer encoder block allows the model to learn the context of each word (or token) in relation to the entire sentence. This is why Sentence Transformers only utilize the encoder part of the Transformers in their architecture. With the help of the Transformers architecture, the words “park” in the sentences “I park my car in the garage” and “I spend the whole day relaxing in a park” will be embedded differently.
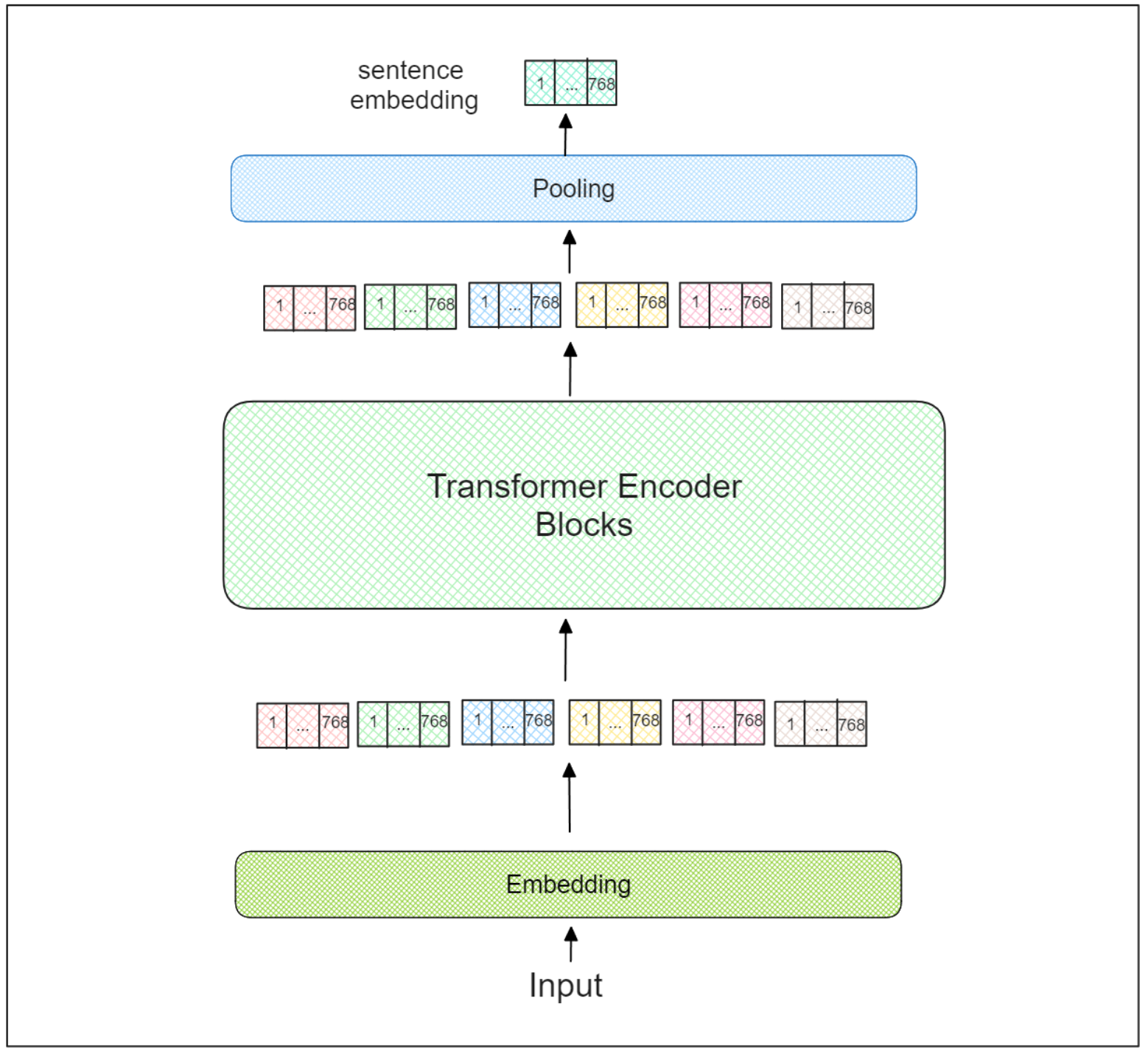
However, the output of Transformers itself is still the embedding of each word (or token). Therefore, sentence Transformers use an additional pooling layer on top of the last Transformer encoder block to derive the final aggregated embedding representing the entire input text.
 Sentence Transformers architecture.png
Sentence Transformers architecture.png
Sentence Transformers architecture.png
There are many variants of sentence Transformers available, but MPNet is one of the most influential. MPNet leverages the strengths of both the BERT and XLNet models while also addressing their main disadvantages. So, before we delve deeper into this model, it’s essential to understand the BERT and XLNet models at a high level.
Background and Motivation
The all-mpnet-base-v2 model was developed to address the growing need for efficient and effective sentence embedding models capable of handling long-form text. Traditional models often struggled with capturing the full semantic meaning and context of lengthy texts, which is crucial for various natural language processing applications. By leveraging the strengths of both BERT and XLNet, the MPNet model captures bidirectional and autoregressive information, making it an ideal choice for sentence embedding tasks. This combination allows the model to excel in semantic search tasks, where understanding the nuanced meaning of sentences is paramount. The motivation behind the all-mpnet-base-v2 model is to provide a robust and reliable solution for these challenges, ensuring high performance and accuracy in diverse NLP applications.
 BERT pre-training approach.png
BERT pre-training approach.png
BERT and XLNet as MPNet Predecessors
BERT is a Transformer-encoder-based model that has set state-of-the-art performance in many tasks, such as sentiment analysis, named-entity recognition, question-answering, and more. One of the key techniques applied in BERT during the training procedure pre training after-training is Masked Language Modeling (MLM). In this approach, a certain percentage of input tokens are randomly replaced by a [MASK] token. The objective is then to predict this [MASK] token with the most probable token given the context of the entire input sequence. Additionally, incorporating a contrastive learning objective could further enhance the training process by enabling the model to accurately predict paired sentences from a large dataset, thereby improving the effectiveness of the training methodology.
BERT pre-training approach.png
The main disadvantage of BERT is that the predicted [MASK] tokens are independent. For example, if we have two [MASK] tokens in a sequence, the prediction of the first [MASK] token would not influence the prediction of the second [MASK] token, even though the prediction from the first [MASK] token could be useful for predicting the second [MASK] token.
If you look at the visualization above, the prediction of the second token, x2, won’t influence the prediction of the fifth token, x5, although x2 will definitely be helpful in enhancing the prediction of x5. This can sometimes lead to a sequence prediction that makes less sense. XLNet, on the other hand, is an Auto-Regressive (AR) model designed specifically to overcome the limitations of BERT. With the AR approach, the token to be predicted always depends on the preceding tokens. Therefore, the prediction of the second [MASK] token takes the prediction of the first [MASK] token into account, addressing the issue of independent token predictions in BERT.
However, the AR approach also has its drawbacks. It only considers the preceding tokens when predicting a token at a particular position. This is not an issue if the token to be predicted is located at the end of the sequence. However, if it is at the beginning of the sequence, using this approach becomes problematic, highlighting a potential limitation of XLNet.
To address this issue, XLNet introduced permuted language modeling (PLM). This method randomly permutes the entire input sequence and then predicts the token at the end of the permuted sequence.
 XLNet pre-training approach.png
XLNet pre-training approach.png
XLNet pre-training approach.png
For example, given an input sequence of (x1, x2, x3, x4, x5), it might be permuted to (x3, x2, x5, x1, x4). Then, the task of XLNet is to predict the token x1 given (x3, x2, x5) and x4 given (x3, x2, x5, x1).
However, the introduction of PLM does not mean that XLNet is a perfect model, as it is still a Transformer-encoder-based model. The essence of the Transformer-encoder block lies in its bidirectional nature, meaning that the model should know the positional information of all tokens in the input sequence. This concept is not fully realized in the AR approach XLNet uses, which only considers the positional information of preceding tokens.
Additionally, the AR concept applied in XLNet introduces a mismatch between the two pre training procedure in-training and fine-tuning processes. When using XLNet for downstream tasks such as text classification, the positional information of the entire input sequence is available from the start.
Therefore, to leverage the advantages of both BERT and XLNet while avoiding their limitations, a unified model called MPNet was introduced.
Understanding MPNet Training Procedure
The advantage of MLM is its ability to consider the positional information of the entire input sequence, while the advantage of PLM is its ability to model the dependency between the masked tokens through its autoregressive approach. MPNet combines the strengths of MLM and PLM in its operation. MPNet maps sentences to dense vector spaces, enabling effective clustering and semantic search. So, how exactly does MPNet combine MLM and PLM?
First, the masked tokens from both MLM and PLM are fused. Consider an input sequence (x1, x2, x3, x4, x5). The sequence is then randomly permuted, resulting in (x3, x2, x5, x1, x4).
MPNet selects the tokens at the right end of the sequence (e.g., x1, x4) as the masked tokens. The non-masked tokens are then arranged as (x3, x2, x5, [M], [M]) with their corresponding positional information (p3, p2, p5, p1, p4). The training process involves predicting which sentence from a dataset is paired with a given sentence by examining a set of randomly sampled other sentences.
MPNet self-attention for each token.png
As shown in the visualization above, MPNet utilizes two-stream self-attention, a common characteristic of PLM. For instance, when predicting token x4, the model can consider (x3+p3, x2+p2, x5+p5) and the previously predicted token (x1+p1). This approach alleviates the limitations associated with MLM.
MPNet also incorporates the mask symbol and positional information of the masked tokens ([M]+p1, [M]+p4) to ensure that each token can see the context and positional information of the entire input sequence. For example, when predicting token x1, the model can consider (x3+p3, x2+p2, x5+p5) and also the masked token that follows it via ([M]+p4). This approach alleviates the limitations associated with PLM.
MPNet has performed better in various Natural Language Inference (NLI) tasks than previous state-of-the-art models such as BERT, XLNet, and RoBERTa. MPNet is also used to train sentence embedding models on extensive datasets using a self-supervised contrastive learning approach.
MPet performance on NLI tasks compared to other models.png
Implementation of MPNet
Due to its performance in various NLI tasks, it’s no surprise that MPNet has become the go-to Sentence Transformers model for obtaining a sentence-level embedding of text. All-MPNet-Base-V2 is a popular MPNet model for sentence embedding, having been trained on approximately 1 billion text pairs. You can generate sentence embeddings using this model through a popular library called sentence-transformers
In the following section, we'll provide an example of how to generate a sentence embedding from a text using the All-MPNet-Base-V2 model to address one of the most popular tasks in NLP: information retrieval. To do this, we'll utilize the sentence-transformers library and PyTorch.
First, let's load our model.
!pip install sentence-transformers
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-mpnet-base-v2")
Let’s assume that we have several texts in our database, and we want to transform each of them into sentence embedding with our All-MPNet-Base-V2 model. We can do so by simply calling model_encode() function.
corpus = [
"A man is eating food.",
"The girl is carrying a baby.",
"A man is riding a horse.",
"A woman is playing violin.",
]
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
Let's consider a scenario where we have a query: “A man is sitting at the dinner table. What’s he doing?”. In an information retrieval task, the goal is to retrieve the most probable answer from a collection of texts in our database.
To do so, we can compute the similarity between the query with each text. We can compute the sentence similarity by using cos_sim() method from sentence-transformers library or popular machine learning libraries like scikit-learn.
query = "A man is sitting at the dinner table. What's he doing?"
query_embedding = model.encode(query, convert_to_tensor=True)
# We use cosine-similarity to find text in the corpus with highest similarity to our query
similar_text_idx = util.cos_sim(query_embedding, corpus_embeddings)[0].argmax().item()
print("Query:", query)
print("Most probable answer:")
print(corpus[similar_text_idx])
"""
Output:
Query: A man is sitting at the dinner table. What's he doing?
Most probable answer:
A man is eating food
"""
This is just one of many use cases for sentence embeddings. They can also be used to solve tasks like text classification, question-answering, document summarization, document clustering, and chatbots.
Since the emergence of powerful LLM models like GPT-4 and LLAMA, sentence embeddings generated by sentence Transformers models have been commonly used to complement predictions made by LLMs via a Retrieval-Augmented Generation (RAG) technique. This ensures that the responses generated are contextually relevant to the query.
Although the sentence embeddings obtained from the pretrained model of MPNet are generally of high quality, there are scenarios where we have a collection of highly contextualized texts or texts from foreign languages. In such cases, the sentence embeddings from pretrained models might not be enough.
When faced with this situation, one solution is to fine-tune the model ourselves. To do this, we need to prepare our training data. A single training example for All-MPNet-Base-V2 consists of a pair of texts and the degree of similarity between them as the label. The degree of similarity between a pair of texts can vary based on your specific use case. The official sentence-transformers library offers comprehensive documentation detailing the steps to prepare your training data for fine-tuning. The primary objective of fine-tuning the All-MPNet-Base-V2 model is to push dissimilar pairs of texts farther apart while keeping the distance between similar pairs of texts close. However, it’s crucial to choose an appropriate cost function depending on your use case and how you label each pair of texts. This ensures that the fine-tuning process aligns with your specific objectives.
If you’re unsure which cost function is appropriate for your use case, you can refer to the official documentation of the sentence-transformers library. There, you’ll also find guidance on how to fine-tune the model using your training data and the chosen loss function.
MPNet is a model that combines the strengths of BERT and XLNet while addressing their limitations. As a result, it often outperforms both BERT and XLNet in many Natural Language Inference (NLI) tasks and has become a popular choice for generating contextual sentence embeddings from text.
Initially, sentence embeddings were primarily used for various NLP tasks, such as text classification, question-answering, document summarization semantic search, text clustering, information retrieval, and chatbots. However, since the introduction of powerful Large Language Models (LLMs), sentence embeddings from MPNet have also been utilized to complement predictions generated by LLMs. This allows us to obtain responses from LLMs that are contextually relevant to the query.
We hope this article provides a solid foundational overview of MPNet!
Semantic Search Applications
The all-mpnet-base-v2 model shines in semantic search applications, where the goal is to retrieve documents or passages based on their semantic meaning rather than just keyword matching. This capability is particularly valuable in fields like academic paper retrieval, technical report search, and lengthy web page analysis. The model’s ability to handle long-form text and generate high-quality sentence embeddings ensures that it can accurately capture the context and meaning of complex documents. Moreover, the all-mpnet-base-v2 model is designed to be efficient, making it suitable for use in low-resource settings where computational power may be limited. This versatility makes it a valuable tool for a wide range of semantic search tasks, providing precise and contextually relevant results.
Model Evaluation and Performance
The all-mpnet-base-v2 model has undergone rigorous evaluation on a variety of benchmark tasks, including the Sentence Embeddings Benchmark (SEB). The results have been impressive, with the model achieving top-5 rankings in tasks such as clustering. Additionally, the model has been fine-tuned on a large dataset of sentence pairs, which has significantly enhanced its performance on sentence similarity tasks. This fine-tuning process ensures that the model can accurately map sentences to their semantic meanings, making it highly effective for tasks like document retrieval and question answering. The model’s strong performance across these tasks demonstrates its robustness and reliability, solidifying its position as a leading choice for generating contextual sentence embeddings.
MPNet: Beyond Language Understanding
So now that we’ve looked at the details of MPNet, you’re probably wondering how it stacks up against BERT, XLNet and RoBERTa. Well, the results are in and they’re impressive! MPNet has been tested on a range of NLP tasks and it’s done well across the board. Here’s the breakdown from the tests conducted in the MPNet: Song et al. (2020) Masked and Permuted Pre-training for Language Understanding paper:
GLUE Benchmark: The Decathlon of NLP
The General Language Understanding Evaluation (GLUE) benchmark is like the decathlon of NLP tasks. It tests models on everything from sentiment analysis to question answering. MPNet scored 87.7 on average across these tasks, beating RoBERTa (86.4), XLNet (84.5) and BERT (83.1).
What’s particularly impressive is MPNet’s performance on tough tasks like RTE (Recognizing Textual Entailment). Here MPNet scored 85.2%, way ahead of RoBERTa’s 78.7%. This shows MPNet has a better understanding of language subtleties.
Question Answering
When it comes to answering questions based on a given text (the SQuAD task), MPNet is again the winner. On SQuAD v2.0 which includes questions that may not have an answer in the text, MPNet scored 82.8% Exact Match and 85.6% F1. Compare that to RoBERTa’s 80.5% and 83.7% respectively and you can see the difference.
Reading Comprehension: RACE to the Finish
The ReAding Comprehension from Examinations (RACE) dataset is tough because it’s based on middle and high school English exams. MPNet scored 72.0% overall, beating BERT (65.0%) and XLNet (66.8%). This means MPNet is better at understanding and reasoning about long passages of text.
What’s Special about MPNet?
You’re probably wondering, “Why does MPNet do so well across these tasks?” The answer is its pre-training method. By combining the strengths of masked language modeling (used in BERT) and permuted language modeling (used in XLNet), MPNet learns language more holistically.
Plus MPNet’s ability to see auxiliary position information helps to bridge the gap between pre-training and fine-tuning. So when MPNet is pre trained models fine-tuned for a specific task, it can use its pre-trained knowledge better.
MPNet is a model that combines the strengths of BERT and XLNet while addressing their limitations. As a result, it often outperforms both BERT and XLNet in many Natural Language Inference (NLI) tasks and has become a popular choice for generating contextual sentence embeddings from text.
Initially, sentence embeddings were primarily used for various NLP tasks, such as text classification, question-answering, document summarization semantic search, text clustering, information retrieval, and chatbots. However, since the introduction of powerful Large Language Models (LLMs), sentence embeddings from MPNet have also been utilized to complement predictions generated by LLMs. This allows us to obtain responses from LLMs that are contextually relevant to the query.
We hope this article provides a solid foundational overview of MPNet!
Semantic Search Applications
The all-mpnet-base-v2 model shines in semantic search applications, where the goal is to retrieve documents or passages based on their semantic meaning rather than just keyword matching. This capability is particularly valuable in fields like academic paper retrieval, technical report search, and lengthy web page analysis. The model’s ability to handle long-form text and generate high-quality sentence embeddings ensures that it can accurately capture the context and meaning of complex documents. Moreover, the all-mpnet-base-v2 model is designed to be efficient, making it suitable for use in low-resource settings where computational power may be limited. This versatility makes it a valuable tool for a wide range of semantic search tasks, providing precise and contextually relevant results.
Model Evaluation and Performance
The all-mpnet-base-v2 model has undergone rigorous evaluation on a variety of benchmark tasks, including the Sentence Embeddings Benchmark (SEB). The results have been impressive, with the model achieving top-5 rankings in tasks such as clustering. Additionally, the model has been fine-tuned on a large dataset of sentence pairs, which has significantly enhanced its performance on sentence similarity tasks. This fine-tuning process ensures that the model can accurately map sentences to their semantic meanings, making it highly effective for tasks like document retrieval and question answering. The model’s strong performance across these tasks demonstrates its robustness and reliability, solidifying its position as a leading choice for generating contextual sentence embeddings.

- Background and Motivation
- BERT and XLNet as MPNet Predecessors
- Understanding MPNet Training Procedure
- Implementation of MPNet
- Semantic Search Applications
- Model Evaluation and Performance
- MPNet: Beyond Language Understanding
- What’s Special about MPNet?
- Semantic Search Applications
- Model Evaluation and Performance
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Evaluating Your Embedding Model
Review some practical examples to evaluate different text embedding models.

What is BERT (Bidirectional Encoder Representations from Transformers)?
Learn what Bidirectional Encoder Representations from Transformers (BERT) is and how it uses pre-training and fine-tuning to achieve its remarkable performance.

What is Mixture of Experts (MoE)?
Mixture of Experts (MoE): a neural network architecture to improve model efficiency and scalability by selecting specialized experts for different tasks.