




Exploring ColBERT: A Token-Level Embedding and Ranking Model for Efficient Similarity Search
Unlike traditional embedding models like BERT, which focus on pooling embeddings into a single vector, ColBERT retains individual token representations. Through its innovative late interaction mechanism, it enables more precise and granular similarity calculations.
Read the entire series
- Exploring BGE-M3 and Splade: Two Machine Learning Models for Generating Sparse Embeddings
- Comparing SPLADE Sparse Vectors with BM25
- Exploring ColBERT: A Token-Level Embedding and Ranking Model for Efficient Similarity Search
- Vectorizing and Querying EPUB Content with the Unstructured and Milvus
- What Are Binary Embeddings?
- A Beginner's Guide to Website Chunking and Embedding for Your RAG Applications
- An Introduction to Vector Embeddings: What They Are and How to Use Them
- Image Embeddings for Enhanced Image Search: An In-depth Explainer
- A Beginner’s Guide to Using OpenAI Text Embedding Models
- DistilBERT: A Distilled Version of BERT
- Unlocking the Power of Vector Quantization: Techniques for Efficient Data Compression and Retrieval
Vector search has experienced explosive growth in recent years, especially after the advent of large language models (LLMs). This popularity has prompted a significant focus in academic research on enhancing embedding models through expanded training data, advanced training methods, and new architectures.
In our previous article, we jumped into various types of vector embeddings and models tailored for effective information retrieval. These include dense, sparse, and binary embeddings designed for specific use cases with strengths and weaknesses. Additionally, we discussed various embedding models, such as BERT for dense vector generation and retrieval and SPLADE and BGE-M3 for sparse embedding generation and retrieval.
This article will dissect ColBERT, an innovative embedding and ranking model engineered for efficient similarity search.
A Quick Recap of BERT
ColBERT, a refined model, is a natural extension of the principles established by BERT. Before exploring the intricacies of ColBERT, let's briefly revisit BERT. This comparison will help us understand the advancements and improvements that ColBERT brings to the table.
BERT, short for Bidirectional Encoder Representations from Transformers, is a language model based on the transformer architecture and excels in dense embedding and retrieval models. Unlike traditional sequential natural language processing methods that move from left to right of a sentence or vice versa, BERT grasps word context by analyzing the entire word sequence simultaneously, thereby generating dense embeddings. So, how does BERT create these embeddings?
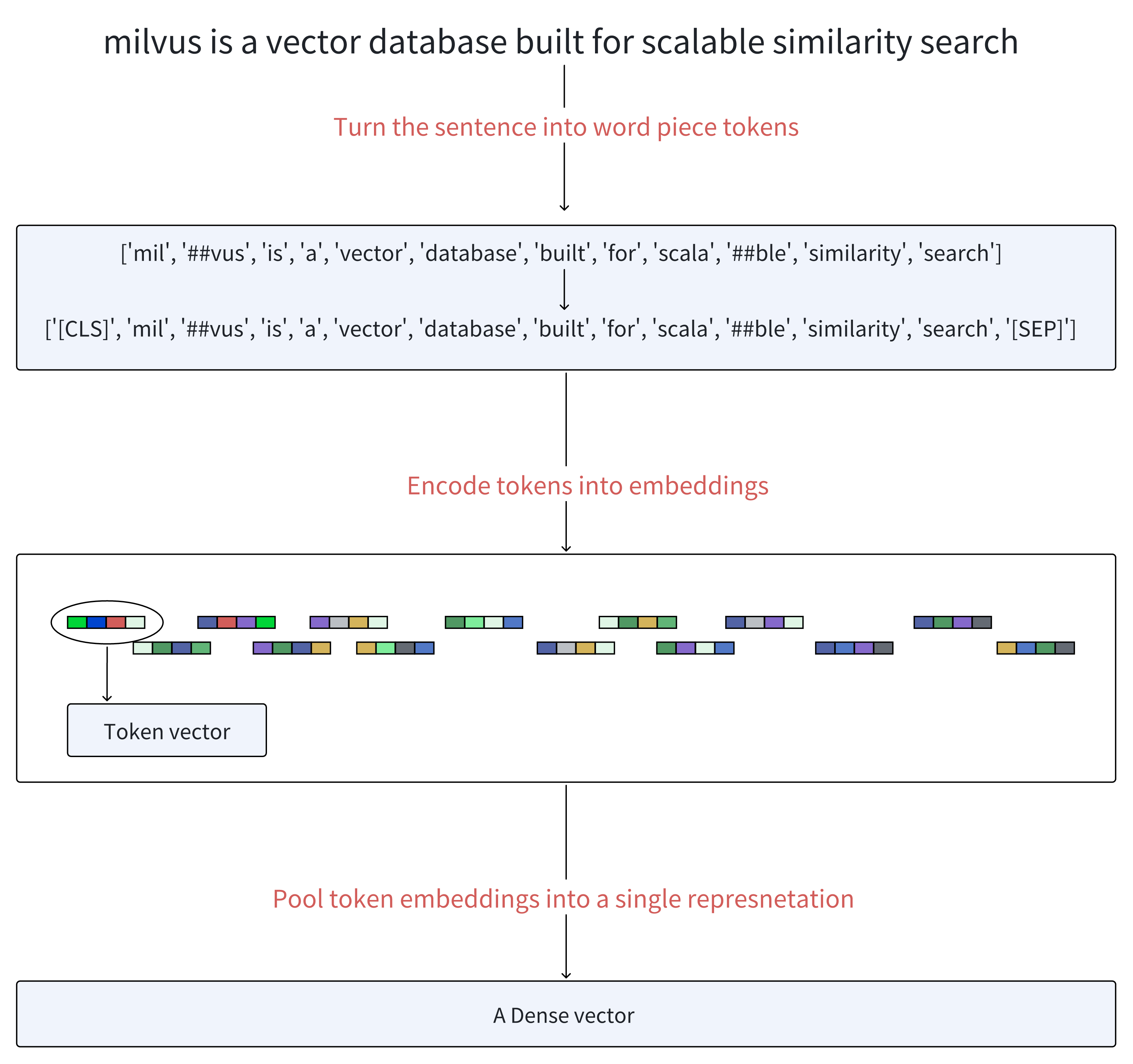 How BERT generates vector embeddings
How BERT generates vector embeddings
Firstly, BERT tokenizes the sentence into word pieces known as tokens. Then, it adds a special token [CLS] at the beginning of the sequence of generated tokens and a token [SEP] at the end of these tokens to separate sentences and indicate the end.
Next comes embedding and encoding. BERT transforms each token into a vector through an embedding matrix and multiple layers of encoders. These layers refine the representation of each token based on the contextual information provided by all other tokens in the sequence.
Finally, all token vectors are combined using pooling operations to form a unified dense representation.
For more comprehensive insights into BERT's workings, refer to this detailed blog post on BERT.
What is ColBERT?
ColBERT, short for Contextualized Late Interaction over BERT, marks a paradigm shift from traditional embedding models like BERT. Unlike BERT, which consolidates token vectors into a singular representation, ColBERT maintains per-token representations, offering a finer granularity in similarity calculation. What sets ColBERT apart is its introduction of a novel late interaction mechanism, a term we'll elaborate on shortly for query-document similarity comparisons. This mechanism enables efficient and precise ranking and retrieval by handling queries and documents separately until the final stages of the retrieval process.
In essence, while BERT or other conventional embedding models generate a single vector for each document and yield a single numeric score indicating its relevance to the query, ColBERT furnishes a list of vectors illustrating how each token in the query aligns with each token in the document. This approach provides a more detailed and nuanced understanding of the semantic relationship between queries and documents.
Understanding ColBERT Architecture
The diagram below demonstrates the general architecture of ColBERT, which comprises:
A query encoder
A document encoder, and
The late interaction mechanism.
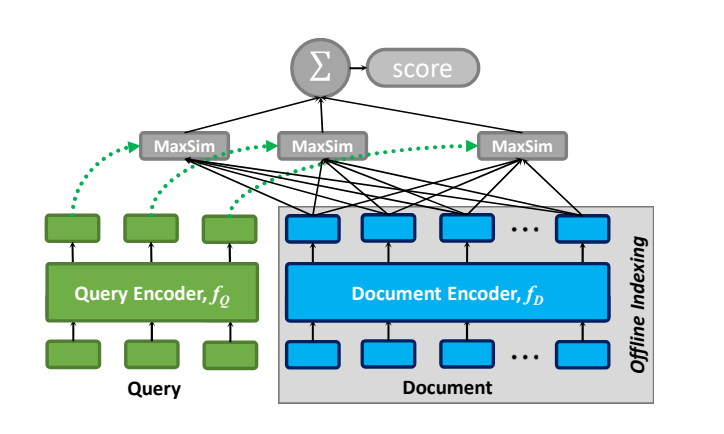 The general architecture of ColBERT, given a query q and a document d.
The general architecture of ColBERT, given a query q and a document d.
When processing a query Q and a document D, ColBERT utilizes a query encoder to transform Q into a set of fixed-size embeddings denoted as Eq, and a document encoder transforms D into another set of embeddings, Ed. Each embedding in Eq and Ed is contextually informed by the surrounding terms within Q and D.
With Eq and Ed in hand, ColBERT calculates the relevance score between Q and D through a late interaction approach, which we define as the aggregation of maximum similarity (MaxSim) operations. Specifically, this approach identifies the maximum cosine similarity of each v within Eq with vectors in Ed, then combines these results through summation. Aside from cosine similarity, ColBERT also uses squared L2 distance as a metric for measuring vector similarity.
Conceptually, this late interaction mechanism compares each query term tq against the document's embeddings, considering its context within the query. This process quantifies the degree of "match" by identifying the highest similarity score between tq and the term td within the document. ColBERT estimates the document's relevance by aggregating these term scores by integrating the matching evidence across all query terms.
The Query Encoder
When processing a query Q, the query encoder utilizes a BERT-based model to tokenize Q into word piece tokens, denoted as q1, q2, ..., ql. Additionally, it inserts a special [Q] token immediately after BERT's sequence start token [CLS]. If the query contains fewer tokens than a predefined threshold Nq, it is padded with [mask] tokens until reaching length Nq. Conversely, if it exceeds Nq tokens, it is truncated to the first Nq tokens. This adjusted sequence of input tokens is then fed into BERT's deep transformer architecture to generate contextualized representations for each token. The resulting output comprises a set of embedding vectors defined as follows:
Eq := Normalize( CNN( BERT("[Q], q0, q1, ...ql, [mask], [mask], …, [mask]") ) )
Here, Eq represents the normalized output obtained by passing the adjusted token sequence, including the special [Q] token and padded tokens, through BERT's transformer layers and applying convolutional neural network (CNN) operations for further refinement.
The Document Encoder
The document encoder operates similarly to the query encoder. When presented with a document D, it tokenizes it into word piece tokens, denoted as d1, d2, ..., dn. Following this process, the document encoder inserts a special [D] token immediately after BERT's start token [CLS] to indicate the document's beginning. Unlike the query tokenization process, no [mask] tokens are added to documents.
After feeding this input sequence through BERT and a subsequent linear layer, the document encoder identifies and removes embeddings corresponding to punctuation symbols based on a predefined list. This filtration step aims to reduce the number of embeddings per document, operating under the hypothesis that even contextualized embeddings may benefit from such filtering.
The output comprises a set of vectors denoted as Ed:
Ed := Filter( Normalize( CNN( BERT("[D], d0, d1, ..., dn") ) ) )
Here, Ed represents the normalized and filtered output obtained by processing the tokenized document through BERT's transformer layers, applying convolutional neural network operations, and filtering out embeddings associated with punctuation symbols.
The Late Interaction Mechanism
In information retrieval, "interaction" refers to assessing the relevance between a query and a document by comparing their vector representations. "Late interaction" signifies that this comparison occurs after the query and document have been independently encoded. This approach contrasts "early interaction" models like BERT, where query and document embeddings interact at earlier stages, often before or during their encoding.
ColBERT adopts a late interaction mechanism that enables the pre-computation of query and document representations. It then employs a streamlined interaction step towards the end to compare the similarity of the already encoded representations. Compared to the early interaction approach, late interaction results in faster retrieval times and reduced computational requirements, making it well-suited for processing extensive document collections efficiently.
So, how does the late interaction process work?
As discussed earlier, the encoders transform the query and document into lists of token-level embeddings Eq and Ed. The late interaction stage then performs a series of maximum similarity (MaxSim) computations using either cosine similarity or squared L2 distance metrics. Then, it aggregates these computations to calculate the relevance score, denoted as Sq,d, for these token vectors. The mathematical representation for this calculation is shown below:
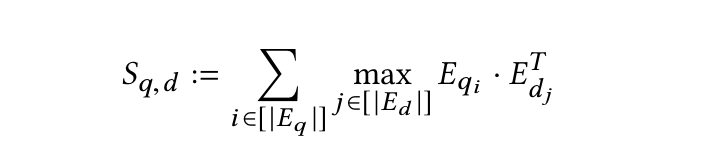 maxsim calculation
maxsim calculation
This approach's unique value allows for a detailed, fine-grained comparison of token embeddings, effectively capturing the similarities between phrases or sentences of varying lengths within the query and the document. This method is especially useful in use cases where precise matching between text segments is required, enhancing the overall accuracy of the search or match process.
ColBERTv2: an Improved ColBERT for Better Retrieval Effectiveness and Storage Efficiency
ColBERT has established its efficacy by encoding queries and documents individually and employing detailed late interaction for accurate similarity measurement. Unlike Sentence-BERT, which generates a single vector per sentence, ColBERT generates one vector for each word piece token within a sentence. This approach is effective in similarity retrieval but inflates the space footprint of these models by order of magnitude, requiring heightened storage consumption during practical deployment in retrieval systems.
ColBERTv2 was introduced to address these challenges. This iteration enhances ColBERT by integrating product quantization (PQ) with centroid-based encoding strategies. The application of product quantization allows ColBERTv2 to compress token embeddings without significant information loss, thus reducing storage costs while maintaining the model's retrieval effectiveness. This change optimizes the storage efficiency and retains the model's capability for fine-grained similarity assessments, making ColBERTv2 a more viable solution for large-scale retrieval systems.
Centroid-Based Encoding in ColBERTv2
In ColBERTv2, token vectors generated by decoders are clustered into distinct groups, each presented by a centroid. This approach allows the centroid index to describe each vector and a residual component that captures the deviation from its centroid. Each dimension of this residual is efficiently quantized into just one or two bits. As a result, the original vector can be effectively represented by a combination of a centroid index and a quantized residual, with only minor discrepancies from the actual vector. These discrepancies have a minimal impact on the overall retrieval accuracy.
How to Conduct Similarity Retrieval with Centroid-Based Vectors
 How to conduct similarity retrieval with centroid-based vectors
How to conduct similarity retrieval with centroid-based vectors
First, ColBERTv2 efficiently encodes documents using the centroid-based method previously described, wherein centroids and their associated quantized residuals represent each document. Similarly, the encoder transforms queries into a set of token-level vectors, denoted as {q1, q2, q3, ..., qn}.
During the retrieval phase, for each query vector qi, we start by retrieving a predetermined number of centroids, known as nprobe. We then reconstruct the vectors corresponding to these centroids from their low-bit quantized residuals and organize them into groups based on their document IDs. This organization streamlines the subsequent matching process.
Once we have categorized the vectors by document ID, the goal shifts to identifying the vectors most similar to each qi. For example, if query vector q1 closely aligns with vector d1 from document 1, and the group for this document includes {d1, d3, d5}, there is no need to compute the full MaxSim for {d1, d2, d3, d4, d5}. This is because vectors d2 and d4, not part of the initial nprobe clusters, are less likely to closely match any query vector qi. After identifying the most relevant groupings, the system retrieves the Top-K most similar documents. We load all complete vectors of these documents for final reranking, including those not initially within the nprobe clusters.
Summary
Our review of ColBERT has unveiled a novel approach to token-level embeddings and ranking, specifically engineered to optimize efficiency in similarity search tasks. Unlike traditional embedding models like BERT that focus on aggregating embeddings into a single vector, ColBERT retains individual token representations, enabling more precise and granular similarity calculations through its innovative late interaction mechanism.
We also took a look at ColBERTv2, an iteration that mitigates the storage demands of its predecessor through product quantization and centroid-based encoding. These innovations improve storage efficiency and maintain the model's retrieval effectiveness. The ongoing enhancements and innovations in ColBERT models highlight the dynamic progression in embedding technologies, indicating promising prospects for even greater accuracy and efficiency in future retrieval systems.
References
Colbert paper: https://arxiv.org/pdf/2004.12832.pdf
Colbert v2 paper: https://arxiv.org/pdf/2112.01488.pdf
Introduction to Vector Similarity Search: https://zilliz.com/learn/vector-similarity-search
Exploring BGE-M3 and Splade: https://zilliz.com/learn/bge-m3-and-splade-two-machine-learning-models-for-generating-sparse-embeddings
 David Wang
David WangDavid Wang, Algorithm Engineer at Zilliz, brings extensive expertise in computer vision and natural language processing. His contributions to advanced embedding algorithm research, including projects like Towhee and GPTCache, reflect his commitment to advancing AI technologies. Before joining Zilliz, he worked at Alibaba Cloud for large-scale object recognition and classification projects. David holds a Master's degree from Dalian University of Technology.
- A Quick Recap of BERT
- What is ColBERT?
- Understanding ColBERT Architecture
- ColBERTv2: an Improved ColBERT for Better Retrieval Effectiveness and Storage Efficiency
- Summary
- References
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

An Introduction to Vector Embeddings: What They Are and How to Use Them
In this blog post, we will understand the concept of vector embeddings and explore its applications, best practices, and tools for working with embeddings.

A Beginner’s Guide to Using OpenAI Text Embedding Models
A comprehensive guide to using OpenAI text embedding models for embedding creation and semantic search.

DistilBERT: A Distilled Version of BERT
DistilBERT maintains 97% of BERT's language understanding capabilities while being 40% small and 60% faster.