




Enhancing Information Retrieval with Learned Sparse Retrieval
Explore the inner workings, advantages, and practical applications of learned sparse embeddings with the Milvus vector database
Read the entire series
- Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
- Primer on Neural Networks and Embeddings for Language Models
- Sparse and Dense Embeddings
- Sentence Transformers for Long-Form Text
- Training Your Own Text Embedding Model
- Evaluating Your Embedding Model
- Class Activation Mapping (CAM): Better Interpretability in Deep Learning Models
- CLIP Object Detection: Merging AI Vision with Language Understanding
- Discover SPLADE: Revolutionizing Sparse Data Processing
- Exploring BERTopic: A New Era of Neural Topic Modeling
- Streamlining Data: Effective Strategies for Reducing Dimensionality
- All-Mpnet-Base-V2: Enhancing Sentence Embedding with AI
- Time Series Embedding in Data Analysis
- Enhancing Information Retrieval with Learned Sparse Retrieval
- What is BERT (Bidirectional Encoder Representations from Transformers)?
- What is Mixture of Experts (MoE)?
The growth of information retrieval methodologies has seen a journey from traditional statistical keyword matching to the transformative power of deep learning models like BERT. While conventional approaches provided a solid foundation, they often needed help capturing the text’s nuanced semantic relationships. Dense retrieval methods like BERT brought significant advancements by leveraging high-dimensional vectors to encapsulate contextual semantics. Yet, they face challenges in Out-Of-Domain situations due to their reliance on domain-specific knowledge.
Learned sparse embeddings offer a unique solution, combining the interpretability of sparse representations with the contextual understanding of deep learning models. In this blog, we explore the inner workings, advantages, and practical applications of learned sparse embeddings with the Milvus vector database. This discussion illuminates their potential to revolutionize information retrieval systems by enhancing both efficiency and interpretability. Here are a few brief notes on the topic of learned sparse retrieval.
Introduction to Sparse Retrieval
Sparse retrieval is a technique in information retrieval that focuses on efficiently retrieving a small set of highly relevant documents from a vast corpus. Unlike dense retrieval methods that use high-dimensional vectors, sparse retrieval represents queries and documents as sparse vectors. This approach leverages the sparsity of data, meaning that only a few dimensions (or terms) are non-zero, which significantly enhances retrieval efficiency.
The primary advantage of sparse retrieval lies in its ability to improve the accuracy of search results. By focusing on the most relevant terms and ignoring the less significant ones, sparse retrieval can more effectively match queries with pertinent documents. This is particularly beneficial in applications where multiple sources of information need to be combined, such as multimodal retrieval scenarios involving text, images, and other data types.
In recent years, sparse retrieval has gained traction due to its interpretability and efficiency. It allows for quick and precise searches, making it an invaluable tool in the ever-evolving landscape of information retrieval.
From Keyword Matching to Context Understanding: The Evolution of Information Retrieval Methodologies
In the early days, Information Retrieval systems relied heavily on statistics-based keyword matching methods such as Bag of Words algorithms like TF-IDF and BM25. These approaches assessed document relevance by analyzing term frequency and distribution across the entire document corpus. Despite their simplicity, these methods proved remarkably rich, becoming ubiquitous tools during the explosive growth of the Internet.
In 2013, Google introduced Word2Vec, the first attempt to use high-dimensional vectors to represent words and encapsulate their semantic nuances. This approach marked the initial shift toward machine learning-driven Information Retrieval methodologies. Additionally, the implementation of the inverted index became crucial for optimizing search operations, requiring adjustments to parameters like the output directory to enhance its functionality.
The landscape changed dramatically with the advent of BERT, a transformative pre-trained language model based on transformers that revolutionized best practices in Information Retrieval. Leveraging attention-powered Transformers, BERT captures the intricate contextual semantics of documents. It condenses them into dense vectors, allowing robust and semantically accurate retrieval for any given queries using nearest neighbor vector search. As a result, significant advancements have ensued, fundamentally enhancing the retrieval process.
Three months after its debut, Nogueira and Cho applied BERT to the MS MARCO passage ranking tasks. BERT achieved a 30% enhancement in effectiveness compared to IRNet, the previous best method, surpassing the BM25 baseline by a factor of two. Fast-forward to March 2024, and the text ranking scores have soared even higher, reaching an impressive 0.450 and 0.463 for evaluation and development, respectively.
Source)
These advancements underscore the relentless evolution of Information Retrieval methodologies, ushering in what can aptly be termed the neural era of Natural Language Processing (NLP).
Learned Sparse Retrieval Techniques
Learned sparse retrieval techniques represent a significant advancement in the field by combining the strengths of traditional lexical bag-of-words models with modern vector embedding algorithms. These techniques aim to represent both queries and documents as sparse vectors, enriched with contextual information learned through machine learning models.
Some of the most notable learned sparse retrieval techniques include SPLADE, SPLADE v2, DeepCT, uniCOIL, EPIC, DeepImpact, TILDE, TILDEv2, Sparta, SPLADE-max, and DistilSPLADE-max. These methods enhance the accuracy of search results by learning the relationships between different modalities, such as text and images, and effectively capturing the semantic nuances within the data.
For instance, SPLADE (Sparse Lexical and Dense Embeddings) generates sparse lexical representations that retain the interpretability of traditional sparse vectors while incorporating the contextual understanding of dense embeddings. This hybrid approach allows for more precise and meaningful retrieval, bridging the gap between exact term matching and semantic search.
By leveraging these learned sparse techniques, information retrieval systems can achieve higher accuracy and efficiency, making them more robust and versatile in handling diverse retrieval tasks.
Out-of-Domain Information Retrieval Challenges: Multimodal Retrieval Remains Underexplored
Dense vector techniques like BERT offer distinct advantages over traditional Bag of Words models in information retrieval. BERT’s strength lies in its ability to grasp intricate contextual nuances within the text, a feature that significantly enhances its performance in handling queries within familiar domains.
However, BERT encounters challenges when venturing beyond familiar territories into Out-of-Domain (OOD) retrieval. Its training process inherently biases it towards the characteristics of the training data, making it less adept at generating meaningful embeddings for unseen text snippets in OOD datasets. This limitation becomes pronounced in datasets rich with domain-specific terminology.
One potential approach to alleviating this issue is fine-tuning. However, this solution is not always viable or cost-effective. Fine-tuning necessitates access to a medium—to large-sized annotated dataset comprising triplets of query, positive document, and negative document relevant to the target domain. Moreover, creating such datasets demands domain specialists’ expertise to ensure data quality, making the process both labor-intensive and potentially costly. A unified framework for learned sparse retrieval can provide a structured method for defining, training, and evaluating various retrieval methods, offering a flexible toolkit that emphasizes modularity and customization according to specific requirements.
On the other hand, traditional Bag of Words algorithms outperform BERT in OOD information retrieval despite grappling with the vocabulary mismatch issue (the typical lack of term overlap between queries and relevant documents). This is because unrecognized terms are not “learned” but “matched” exactly in Bag of Words algorithms.
](https://assets.zilliz.com/2_table_3905ed16ea.png) BEIR, a robust and heterogeneous evaluation benchmark for information retrieval, shows that BM25 performs superior in many Out Of Domain (OOD) retrieval cases. [Source](http://arxiv.org/abs/2104.08663)
BEIR, a robust and heterogeneous evaluation benchmark for information retrieval, shows that BM25 performs superior in many Out Of Domain (OOD) retrieval cases. [Source](http://arxiv.org/abs/2104.08663)
Learned Sparse Embeddings: a Fusion of Traditional Sparse Vector Representations With Contextualized Information
Combining the strengths of exact term matching techniques such as Bag of Words for Out-of-Domain retrieval and dense retrieval methods like BERT for in-domain or semantic retrieval has long been a quest in information retrieval. Fortunately, a promising solution emerges: learned sparse embeddings.
But what exactly are learned sparse embeddings?
Learn sparse embeddings denote sparse vector representations of data crafted through sophisticated machine learning models such as SPLADE and BGE-M3. Unlike traditional sparse vectors, which rely solely on statistical methods like BM25, learned sparse embeddings enrich the sparse representation with contextual information while retaining keyword search capabilities. They can discern the significance of adjacent or correlated tokens, even if not explicitly present in the text, resulting in a “learned” sparse representation adept at capturing relevant keywords and classes.
Consider SPLADE as an example. When encoding a given text, SPLADE produces a sparse embedding in the form of a token-to-weight mapping, such as:
{"hello": 0.33, "world": 0.72}
At first glance, these embeddings look similar to conventional sparse embeddings generated by statistical methods. However, a pivotal difference lies in their composition: both the dimensions (terms) and the weights. Machine learning models imbued with contextualized information determine both dimensions (terms) and weights of learned sparse embeddings. This amalgamation of sparse representation with learned context affords a potent tool for information retrieval tasks, seamlessly bridging the gap between exact term matching and semantic understanding.
 NDCG@ 10 results on BEIR
NDCG@ 10 results on BEIR
Image source: http://arxiv.org/abs/2109.10086
In contrast to dense embeddings, which encapsulate extensive details within lengthy vectors, learned sparse embeddings adopt a more concise approach, retaining only essential text information. This deliberate simplification safeguards against overfitting to training data, enhancing the model’s ability for generalization when encountering novel data patterns in Out-Of-Domain information retrieval scenarios.
By prioritizing key textual elements while discarding extraneous details, learned sparse embeddings balance capturing relevant information and avoiding the pitfalls of overfitting, thereby bolstering their utility in diverse retrieval tasks.
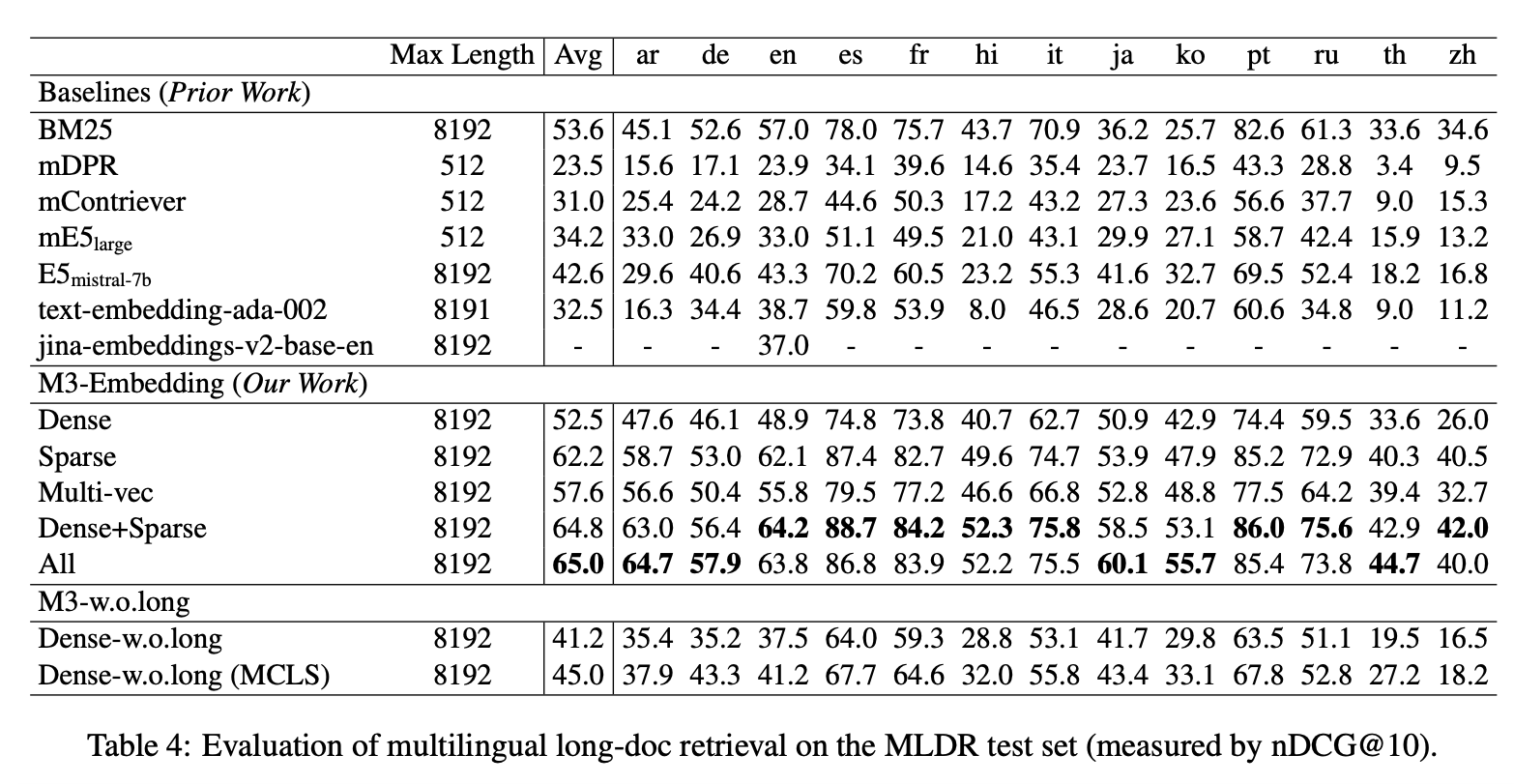 Table 4. Evaluation of multilingual long-doc retrieval on the MLDR test set measured by NDCG@10
Table 4. Evaluation of multilingual long-doc retrieval on the MLDR test set measured by NDCG@10
Image source: https://arxiv.org/abs/2402.03216
Learned sparse embeddings exhibit remarkable synergy with dense retrieval methods in in-domain information retrieval. According to experiments conducted by the BGE-M3 authors, learned sparse embeddings consistently outperform dense embeddings in multi- or cross-lingual retrieval tasks, boasting higher levels of accuracy. Moreover, when these embeddings are integrated, their combined usage yields even greater enhancements in accuracy, underscoring the complementary nature of sparse and dense retrieval techniques.
 Table 5. Evaluation on NarrativeQA (nDCG@10).
Table 5. Evaluation on NarrativeQA (nDCG@10).
Image source: https://arxiv.org/abs/2402.03216
Additionally, the sparsity inherent in such embeddings facilitates effortless vector similarity searches, demanding minimal computing resources. Furthermore, the term-matching characteristic of learned sparse embeddings enhances interpretability, as you can quickly examine the matched documents to identify the corresponding matched words. This feature enables more precise insights into the underlying retrieval process, enhancing the overall transparency and usability of the system.
A Showcase
This section demonstrates how learned sparse embeddings excel in situations where dense retrieval falls short.
Dataset: MIRACL.
Query: What years did Zhu Xi live?
Notes:
- Zhu Xi was a Chinese calligrapher, historian, philosopher, poet, and politician during the Song dynasty.
- The MIRACL dataset is multilingual, and we only use the “train” split of the English part in this showcase. It contains 26746 passages, seven of which are related to Zhu Xi.
We retrieved these seven relevant stories based on the query using dense and sparse retrieval methodologies, respectively. Initially, we encoded all stories into dense or sparse embeddings, respectively, and stored them in the Milvus vector database. Subsequently, we encoded the query and identified the top 10 stories closest to the query embedding using KNN search. Notably, the stories related to Zhu Xi are highlighted in bold in the following result:
Sparse Search Results(IP distance, larger is closer):
Score: 26.221 Id: 244468#1 Text: Zhu Xi, whose family originated in Wuyuan County, Huizhou ...
Score: 26.041 Id: 244468#3 Text: In 1208, eight years after his death, Emperor Ningzong of Song rehabilitated Zhu Xi and honored him ...
Score: 25.772 Id: 244468#2 Text: In 1179, after not serving in an official capacity since 1156, Zhu Xi was appointed Prefect of Nankang Military District (南康軍) ...
Score: 23.905 Id: 5823#39 Text: During the Song dynasty, the scholar Zhu Xi (AD 1130–1200) added ideas from Daoism and Buddhism into Confucianism ...
Score: 23.639 Id: 337115#2 Text: ... During the Song Dynasty, the scholar Zhu Xi (AD 1130–1200) added ideas from Taoism and Buddhism into Confucianism ...
Score: 23.061 Id: 10443808#22 Text: Zhu Xi was one of many critics who argued that ...
Score: 22.577 Id: 55800148#11 Text: In February 1930, Zhu decided to live the life of a devoted revolutionary after leaving his family at home ...
Score: 20.779 Id: 12662060#3 Text: Holding to Confucius and Mencius' conception of humanity as innately good, Zhu Xi articulated an understanding of "li" as the basic pattern of the universe ...
Score: 20.061 Id: 244468#28 Text: Tao Chung Yi (around 1329~1412) of the Ming dynasty: Whilst Master Zhu inherited the orthodox teaching and propagated it to the realm of sages ...
Score: 19.991 Id: 13658250#10 Text: Zhu Shugui was 66 years old (by Chinese reckoning; 65 by Western standards) at the time of his suicide ...
Dense Search Results(L2 distance, smaller is closer):
Score: 0.600 Id: 244468#1 Text: Zhu Xi, whose family originated in Wuyuan County, Huizhou ...
Score: 0.706 Id: 244468#3 Text: In 1208, eight years after his death, Emperor Ningzong of Song rehabilitated Zhu Xi and honored him ...
Score: 0.759 Id: 13658250#10 Text: Zhu Shugui was 66 years old (by Chinese reckoning; 65 by Western standards) at the time of his suicide ...
Score: 0.804 Id: 6667852#0 Text: King Zhaoxiang of Qin (; 325–251 BC), or King Zhao of Qin (秦昭王), born Ying Ji ...
Score: 0.818 Id: 259901#4 Text: According to the 3rd-century historical text "Records of the Three Kingdoms", Liu Bei was born in Zhuo County ...
Score: 0.868 Id: 343207#0 Text: Ruzi Ying (; 5 – 25), also known as Emperor Ruzi of Han and the personal name of Liu Ying (劉嬰), was the last emperor ...
Score: 0.876 Id: 31071887#1 Text: The founder of the Ming dynasty was the Hongwu Emperor (21 October 1328 – 24 June 1398), who is also known variably by his personal name "Zhu Yuanzhang" ...
Score: 0.882 Id: 2945225#0 Text: Emperor Ai of Tang (27 October 89226 March 908), also known as Emperor Zhaoxuan (), born Li Zuo, later known as Li Chu ...
Score: 0.890 Id: 33230345#0 Text: Li Xi or Li Qi (李谿 per the "Zizhi Tongjian" and the "History of the Five Dynasties" or 李磎 per the "Old Book of Tang" ...
Score: 0.893 Id: 172890#1 Text: The Wusun originally lived between the Qilian Mountains and Dunhuang (Gansu) near the Yuezhi ...
Look closer at the result: all 7 stories are ranked top 10 in sparse retrieval, while only 2 are ranked in the top 10 in dense retrieval. Both sparse and dense methods correctly identify passages numbered 244468#1 and 244468#3, yet dense retrieval fails to include any additional relevant stories. Instead, the eight other stories returned by the dense method pertain to Chinese historical narratives, which the model deems relevant but unrelated to our focal character, Zhu Xi.
If you're eager to delve into the mechanics behind our approach, jump ahead to the next section, where we detail our vector search process using Milvus.
A Step-by-Step Guide: How to Perform Vector Search with Milvus
Milvus is an open-source vector database renowned for scalability and performance. The latest release, Milvus 2.4, offers beta support for both sparse and dense vectors. In this demo, we’ll use Milvus 2.4 to store the dataset and conduct vector searches.
We'll also walk you through how to perform the query above, What years did Zhu Xi live? in Milvus against the MIRACL dataset.
We'll use SPLADE and MiniLM-L6-v2 models to transform the query and the MIRACL source dataset into sparse and dense embeddings, respectively.
To begin our journey, let's make a directory and set up the environment and the Milvus service. Make sure you have installed python(>=3.8), virtualenv, docker and docker-compose.
mkdir milvus_sparse_demo && cd milvus_sparse_demo
# spin up a milvus local cluster
wget https://github.com/milvus-io/milvus/releases/download/v2.4.0-rc.1/milvus-standalone-docker-compose.yml -O docker-compose.yml
docker-compose up -d
# create a virtual environment
virtualenv -p python3.8 .venv && source .venv/bin/activate
touch milvus_sparse_demo.py
Starting from version 2.4, pymilvus, the Python SDK for Milvus, introduces an optional model module. This module simplifies the process of encoding texts into sparse or dense embeddings using your preferred models. Additionally, to access the necessary datasets from HuggingFace, we utilize pip for installation.
pip install "pymilvus[model]" datasets tqdm
First, download the dataset using the HuggingFace Datasets library, and collect all passages.
from datasets import load_dataset
miracl = load_dataset('miracl/miracl', 'en')['train']
# collect all passages in the dataset
docs = list({doc['docid']: doc for entry in miracl for doc in entry['positive_passages'] + entry['negative_passages']}.values())
print(docs[0])
# {'docid': '2078963#10', 'text': 'The third thread in the development of quantum field theory...'}
Encode the queries:
from pymilvus import model
sparse_ef = model.sparse.SpladeEmbeddingFunction(
model_name="naver/splade-cocondenser-selfdistil",
device="cpu",
)
dense_ef = model.dense.SentenceTransformerEmbeddingFunction(
model_name='all-MiniLM-L6-v2',
device='cpu',
)
query = "What years did Zhu Xi live?"
query_sparse_emb = sparse_ef([query])
query_dense_emb = dense_ef([query])
We can inspect the sparse embedding generated and find the tokens with the highest weights:
sparse_token_weights = sorted([(sparse_ef.model.tokenizer.decode(col), query_sparse_emb[0, col])
for col in query_sparse_emb.indices[query_sparse_emb.indptr[0]:query_sparse_emb.indptr[1]]], key=lambda item: item[1], reverse=True)
print(sparse_token_weights[:7])
# [('zhu', 3.0623178), ('xi', 2.4944391), ('zhang', 1.4790473), ('date', 1.4589322), ('years', 1.4154341), ('live', 1.3365831), ('china', 1.2351396)]
Encode all the documents:
from tqdm import tqdm
doc_sparse_embs = [sparse_ef([doc['text']]) for doc in tqdm(docs, desc='Encoding Sparse')]
doc_dense_embs = [dense_ef([doc['text']])[0] for doc in tqdm(docs, desc='Encoding Dense')]
Next, we create a collection in Milvus to store everything, including the doc id, texts, dense and sparse embeddings and insert the entire dataset.
from pymilvus import (
MilvusClient, FieldSchema, CollectionSchema, DataType
)
milvus_client = MilvusClient("http://localhost:19530")
collection_name = 'miracl_demo'
fields = [
FieldSchema(name="doc_id", dtype=DataType.VARCHAR, is_primary=True, auto_id=False, max_length=100),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=65530),
FieldSchema(name="sparse_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
FieldSchema(name="dense_vector", dtype=DataType.FLOAT_VECTOR, dim=384),
]
milvus_client.create_collection(collection_name, schema=CollectionSchema(fields, "miracl demo"), timeout=5, consistency_level="Strong")
batch_size = 30
n_docs = len(docs)
for i in tqdm(range(0, n_docs, batch_size), desc='Inserting documents'):
milvus_client.insert(collection_name, [
{
"doc_id": docs[idx]['docid'],
"text": docs[idx]['text'],
"sparse_vector": doc_sparse_embs[idx],
"dense_vector": doc_dense_embs[idx]
}
for idx in range(i, min(i+batch_size, n_docs))
])
To speed up the search process, we create indexes for the vector fields:
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="sparse_vector",
index_type="SPARSE_INVERTED_INDEX",
metric_type="IP",
)
index_params.add_index(
field_name="dense_vector",
index_type="FLAT",
metric_type="L2",
)
milvus_client.create_index(collection_name, index_params=index_params)
milvus_client.load_collection(collection_name)
Now we can perform the search and inspect the result:
k = 10
sparse_results = milvus_client.search(collection_name, query_sparse_emb, anns_field="sparse_vector", limit=k, search_params={"metric_type": "IP"}, output_fields=['doc_id', 'text'])[0]
dense_results = milvus_client.search(collection_name, query_dense_emb, anns_field="dense_vector", limit=k, search_params={"metric_type": "L2"}, output_fields=['doc_id', 'text'])[0]
print(f'Sparse Search Results:')
for result in sparse_results:
print(f"\tScore: {result['distance']} Id: {result['entity']['doc_id']} Text: {result['entity']['text']}")
print(f'Dense Search Results:')
for result in dense_results:
print(f"\tScore: {result['distance']} Id: {result['entity']['doc_id']} Text: {result['entity']['text']}")
You'll see the following output. In the results of dense retrieval, only the first two stories are related to Zhu Xi. I trimmed the texts for readability.
Sparse Search Results:
Score: 26.221 Id: 244468#1 Text: Zhu Xi, whose family originated in Wuyuan County, Huizhou ...
Score: 26.041 Id: 244468#3 Text: In 1208, eight years after his death, Emperor Ningzong of Song rehabilitated Zhu Xi and honored him ...
Score: 25.772 Id: 244468#2 Text: In 1179, after not serving in an official capacity since 1156, Zhu Xi was appointed Prefect of Nankang Military District (南康軍) ...
Score: 23.905 Id: 5823#39 Text: During the Song dynasty, the scholar Zhu Xi (AD 1130–1200) added ideas from Daoism and Buddhism into Confucianism ...
Score: 23.639 Id: 337115#2 Text: ... During the Song Dynasty, the scholar Zhu Xi (AD 1130–1200) added ideas from Taoism and Buddhism into Confucianism ...
Score: 23.061 Id: 10443808#22 Text: Zhu Xi was one of many critics who argued that ...
Score: 22.577 Id: 55800148#11 Text: In February 1930, Zhu decided to live the life of a devoted revolutionary after leaving his family at home ...
Score: 20.779 Id: 12662060#3 Text: Holding to Confucius and Mencius' conception of humanity as innately good, Zhu Xi articulated an understanding of "li" as the basic pattern of the universe ...
Score: 20.061 Id: 244468#28 Text: Tao Chung Yi (around 1329~1412) of the Ming dynasty: Whilst Master Zhu inherited the orthodox teaching and propagated it to the realm of sages ...
Score: 19.991 Id: 13658250#10 Text: Zhu Shugui was 66 years old (by Chinese reckoning; 65 by Western standards) at the time of his suicide ...
Dense Search Results:
Score: 0.600 Id: 244468#1 Text: Zhu Xi, whose family originated in Wuyuan County, Huizhou ...
Score: 0.706 Id: 244468#3 Text: In 1208, eight years after his death, Emperor Ningzong of Song rehabilitated Zhu Xi and honored him ...
Score: 0.759 Id: 13658250#10 Text: Zhu Shugui was 66 years old (by Chinese reckoning; 65 by Western standards) at the time of his suicide ...
Score: 0.804 Id: 6667852#0 Text: King Zhaoxiang of Qin (; 325–251 BC), or King Zhao of Qin (秦昭王), born Ying Ji ...
Score: 0.818 Id: 259901#4 Text: According to the 3rd-century historical text "Records of the Three Kingdoms", Liu Bei was born in Zhuo County ...
Score: 0.868 Id: 343207#0 Text: Ruzi Ying (; 5 – 25), also known as Emperor Ruzi of Han and the personal name of Liu Ying (劉嬰), was the last emperor ...
Score: 0.876 Id: 31071887#1 Text: The founder of the Ming dynasty was the Hongwu Emperor (21 October 1328 – 24 June 1398), who is also known variably by his personal name "Zhu Yuanzhang" ...
Score: 0.882 Id: 2945225#0 Text: Emperor Ai of Tang (27 October 89226 March 908), also known as Emperor Zhaoxuan (), born Li Zuo, later known as Li Chu ...
Score: 0.890 Id: 33230345#0 Text: Li Xi or Li Qi (李谿 per the "Zizhi Tongjian" and the "History of the Five Dynasties" or 李磎 per the "Old Book of Tang" ...
Score: 0.893 Id: 172890#1 Text: The Wusun originally lived between the Qilian Mountains and Dunhuang (Gansu) near the Yuezhi ...
Finally, clean up.
docker-compose down
cd .. && rm -rf milvus_sparse_demo
Summary
In summary, exploring learned sparse embeddings reveals a paradigm shift in information retrieval methodologies. By leveraging the fusion of traditional sparse representations with contextualized information, these embeddings offer a versatile solution that addresses the inherent challenges of exact term matching and semantic understanding.
We witnessed how learned sparse embeddings excel in capturing relevant keywords and classes while maintaining interpretability, thus striking a delicate balance between efficiency and clarity in information retrieval tasks. Their synergistic integration with dense retrieval methods further enhances accuracy and performance, underscoring their indispensable role in modern information retrieval systems.
Through a practical demonstration using Milvus, we illustrated the tangible benefits of learned sparse embeddings in real-world scenarios, showcasing their prowess in retrieving relevant information with precision and efficiency.
Evaluating Sparse Retrieval Models
Evaluating the performance of sparse retrieval models is crucial to ensure their effectiveness and identify areas for improvement. Common evaluation metrics used in this context include precision, recall, and F1-score, which measure the accuracy and relevance of the retrieved documents.
To further enhance the performance of sparse retrieval models, techniques such as query expansion and dense retrieval can be employed. Query expansion involves augmenting the original query with additional terms to improve retrieval accuracy, while dense retrieval uses high-dimensional vectors to capture the semantic context of the queries and documents.
A conceptual framework for information retrieval techniques can also guide the development of new sparse retrieval models and applications. This framework encompasses various aspects of neural information processing systems, including the integration of sparse and dense retrieval methods, the use of multimodal data, and the continuous refinement of retrieval algorithms.
By systematically evaluating and refining sparse retrieval models, researchers and practitioners can develop more effective and efficient information retrieval systems, capable of handling the complexities of modern data landscapes.
 Buqian Zheng
Buqian ZhengBuqian Zheng is a Senior Software Engineer at Zilliz, specializing in developing the core vector index engine of Milvus. Before joining Zilliz, he was a Software Engineer at Google, where he contributed to projects such as Google Cloud Dataflow and managed Google-scale data analytic services. With a wealth of industry experience in managing massive data and infrastructures, Buqian brings invaluable expertise to his role. He holds a Master’s degree from Carnegie Mellon University.
- Introduction to Sparse Retrieval
- From Keyword Matching to Context Understanding: The Evolution of Information Retrieval Methodologies
- Learned Sparse Retrieval Techniques
- Out-of-Domain Information Retrieval Challenges: Multimodal Retrieval Remains Underexplored
- Learned Sparse Embeddings: a Fusion of Traditional Sparse Vector Representations With Contextualized Information
- A Showcase
- A Step-by-Step Guide: How to Perform Vector Search with Milvus
- Summary
- Evaluating Sparse Retrieval Models
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

CLIP Object Detection: Merging AI Vision with Language Understanding
CLIP Object Detection combines CLIP's text-image understanding with object detection tasks, allowing CLIP to locate and identify objects in images using texts.

Streamlining Data: Effective Strategies for Reducing Dimensionality
In this article, we'll discuss how having too much data can hinder the performance of our machine-learning model and what we can do to address this problem.

All-Mpnet-Base-V2: Enhancing Sentence Embedding with AI
Delve into one of the deep learning models that has played a significant role in the development of sentence embedding: MPNet.