




What is Mixture of Experts (MoE)?
Mixture of Experts (MoE): a neural network architecture to improve model efficiency and scalability by selecting specialized experts for different tasks.
Read the entire series
- Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
- Primer on Neural Networks and Embeddings for Language Models
- Sparse and Dense Embeddings
- Sentence Transformers for Long-Form Text
- Training Your Own Text Embedding Model
- Evaluating Your Embedding Model
- Class Activation Mapping (CAM): Better Interpretability in Deep Learning Models
- CLIP Object Detection: Merging AI Vision with Language Understanding
- Discover SPLADE: Revolutionizing Sparse Data Processing
- Exploring BERTopic: A New Era of Neural Topic Modeling
- Streamlining Data: Effective Strategies for Reducing Dimensionality
- All-Mpnet-Base-V2: Enhancing Sentence Embedding with AI
- Time Series Embedding in Data Analysis
- Enhancing Information Retrieval with Learned Sparse Retrieval
- What is BERT (Bidirectional Encoder Representations from Transformers)?
- What is Mixture of Experts (MoE)?
Imagine a team of specialists working together to solve complex problems. Each expert possesses unique skills, and the team achieves unparalleled success by dividing tasks efficiently. This is the fundamental idea behind the Mixture-of-Experts (MoE) model architecture, a method that allows machine learning systems, especially neural networks, to scale efficiently. Instead of having a single neural network handle every task, MoE divides the work among multiple specialized "experts" with a gating network determining which experts should be activated for each input.
As models get bigger and more complex, especially in NLP and LLMs, one of the biggest challenges is to keep efficiency and accuracy as you scale to billions or even trillions of parameters. Traditional models which activate all layers and neurons for every input have huge computational cost, slow down inference and consume lots of memory. Deploying such large models in real world applications where speed and scalability matters is a tough task.
Mixture of Experts solves this problem by only activating a small subset of experts at a time, so you get to reduce the computational overhead without sacrificing performance. This collaborative approach in MoE is becoming increasingly important in natural language processing (NLP) and large language models (LLMs) like OpenAI's GPT, where models need to scale up to billions of parameters while maintaining efficiency and accuracy.
This post will discuss MoE's core concepts, large language models, training, inferences, and their role in modern AI models.
What is MoE and Its Core Concepts
Simply put, Mixture of Experts (MoE) is an advanced neural network architecture designed to improve model efficiency and scalability by dynamically selecting specialized sub-models, or "experts," to handle different parts of an input. The concept can be likened to a division of labor, where each expert focuses on specific tasks within a broader problem, resulting in faster and more accurate outcomes.
The Mixture-of-Experts model consists of three key components:
Experts: Sub-models specialized for specific tasks.
Gating Network: A selector that routes input data to the relevant experts.
Sparse Activation: The method by which only a few experts are activated per input, optimizing computational efficiency.
Experts
Experts in MoE architecture are individual sub-networks (neural networks or layers) trained to handle specific data or tasks. For instance, in an image classification task, one expert might specialize in recognizing textures, while another might identify edges or shapes. This division helps the overall model to approach problems more effectively because each expert only handles the type of data it is best suited for.
Gating Network or Router
The gating network acts as a selector that determines which input data is sent to which expert. Instead of all experts working simultaneously, the gating network routes the data to the most relevant experts. Like a token choice routing strategy, the routing algorithm picks the best one or two experts for each token. For example, in the image below, the input token 1, “We,” is sent to the second expert, and the input token 2, "Like,” is sent to the first network.
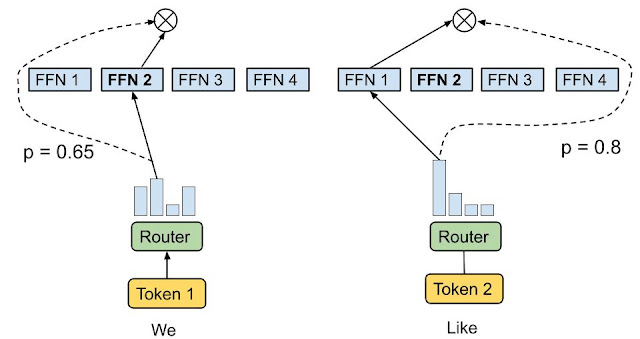
Token Choice Routing | Source
Various token routing techniques are available. Below are some popular methods.
Top-k routing: This is the simplest method. The gating network selects the top-k experts with the highest affinity scores and sends the input data to them.
Expert choice routing: Instead of the data choosing the experts, the experts decide which data they can handle best. This strategy aims to achieve the best load balancing and allows various ways of mapping data to experts.
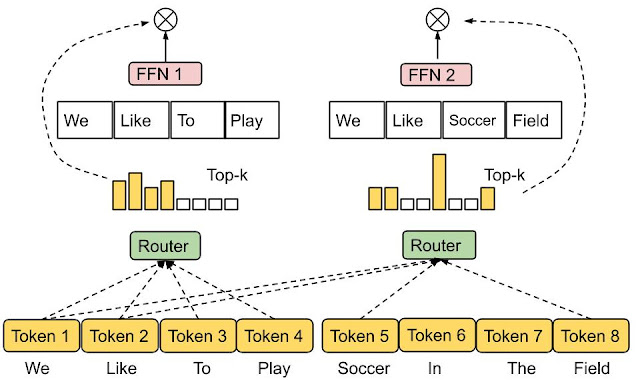
Expert Choice Routing | Source
Sparse Activation
Sparse activation is one of the key advantages of Mixture-of-Experts (MoE) models. Unlike dense models, where all experts or parameters are active for every input, sparse activation ensures that only a small subset of experts are activated based on the input data. This method reduces computational requirements while maintaining performance, as only the most relevant experts are active at any time.
- Sparse routing: A specific technique of sparse activation where the gating network activates only a few experts per input.
MoE in Deep Learning: Historical Evolution
The roots of MoEs come from the 1991 paper Adaptive Mixture of Local Experts. This paper introduced the idea of dividing a complex problem into subproblems and assigning them to multiple specialized models. This divide-and-conquer strategy became the core of MoE architectures.
The evolution of MoE was further shaped by two key research areas:
Experts as components: Initially, MoEs were applied in models such as Support Vector Machines (SVMs) and Gaussian Processes. However, work by Eigen, Ranzato, and Ilya extended this approach by integrating MoEs as components within deep neural networks, allowing them to function as layers within larger models.
Conditional computation: Traditional neural networks process all inputs through every layer, but Yoshua Bengio’s research introduced conditional computation, selectively activating or deactivating network components based on the input. This dynamic approach led to more efficient computation, as only necessary parts of the model were used for each input.
MoE in Large-Scale NLP Models: GShard and Switch Transformer
MoE’s impact on natural language processing (NLP) was cemented with models like GShard and the Switch Transformer. In 2021, Google’s Switch Transformer, which went to 1.6 trillion parameters, showed MoE can handle tasks that require a lot of computation. By only activating a few experts per input, the model remained efficient as the number of parameters grew.
Another big milestone was in 2017 when Shazeer et al. introduced the Sparsely Gated Mixture-of-Experts Layer which allowed sparse activation in deep learning. This enabled models to go to 137 billion parameters for tasks like machine translation and remain low inference cost by only activating the most relevant experts per input.
Beyond NLP: MoE in Vision and Multimodal Models
MoE has gone beyond NLP. For example Google’s V-MoE architecture uses a sparse MoE framework for computer vision tasks, using Vision Transformers (ViT) to do image classification with expert specialization. This allows us to scale image models just like text models.
As research progresses MoE’s applicability to complex tasks across different domains will only continue to grow. It’s part of a broader trend towards more efficient, scalable and task specific models in deep learning so it’s one of the building blocks of modern AI architectures.
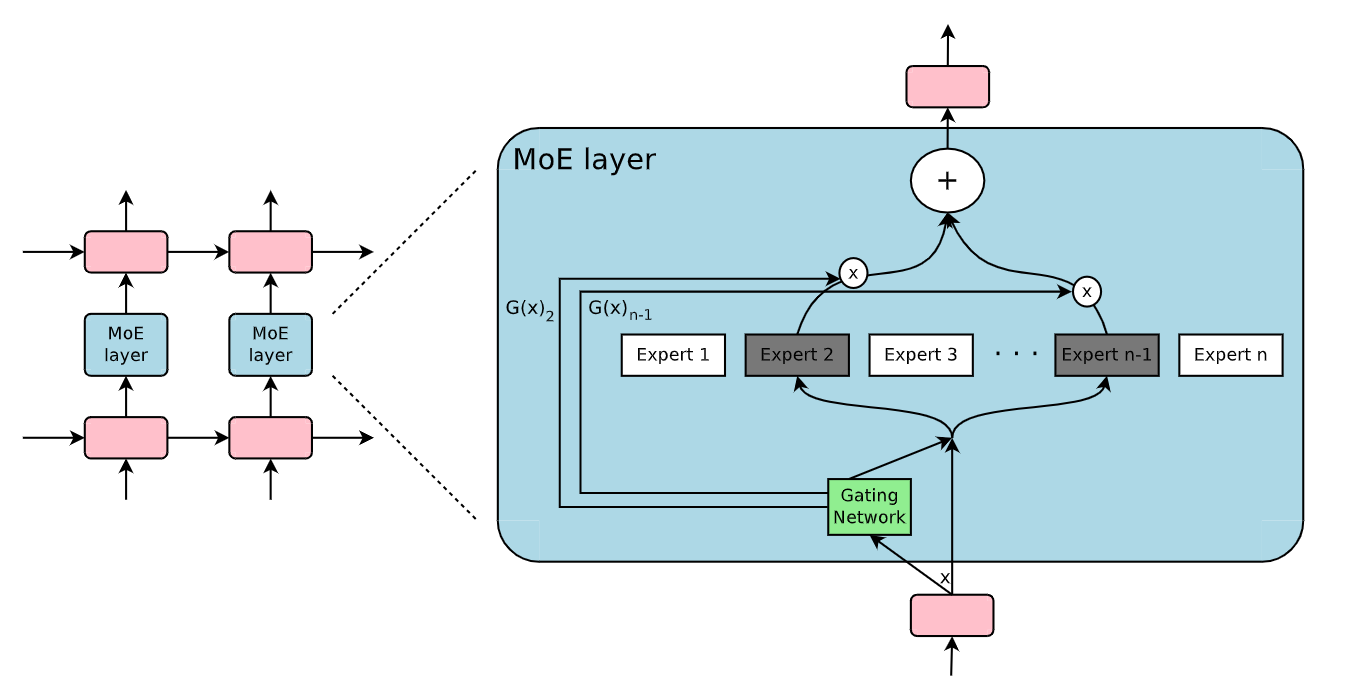
Mixture of Experts (MoE) layer | Source
MoE Architecture in Detail (How it Works)
The Mixture-of-Experts architecture can be operated in two primary processes:
Training
Inference
Training
Like other machine learning models, MoE models learn from data, but their training process is unique. Instead of training the entire model as a single entity, MoE focuses on separately training its individual components—the experts and the gating network. In this way, each expert becomes specialized in its designated task, while the gating network learns to route inputs to the appropriate experts effectively.
Expert training
Each expert in a MoE model is treated as an individual neural network and undergoes training on a subset of data or tasks. The training of each expert follows a standard neural network training process in which the model learns to minimize the loss function for its specific data subset.
For instance, in a natural language processing model, one expert might be trained on a dataset of formal documents to specialize in formal language. In contrast, another might be trained on social media conversations to become proficient in informal communication. This individualized training allows experts to become highly proficient in their specific domains.
Gating network training
The gating network acts as a decision-maker, selecting the most suitable expert for a given input. It is trained alongside the expert networks but plays a different role. The input to the gating network is the same data fed into the model as a whole, which can include raw data like text, images, or any input based on the model’s task. The gating network's output is a probability distribution that indicates which expert(s) is best suited to handle the current input.
The gating network's training is usually supervised and provided with labeled data during the training phase. The gating network learns to classify the input and assign it to the correct expert(s) based on the labels provided. During training, the gating network is optimized to be accurate in its expert selection and improve the MoE model's overall performance.
Joint training
During the joint training phase, the entire Mixture of Experts (MoE) system, including the expert models and the gating network, undergoes training. This strategy ensures that both the gating network and the experts are optimized to work in harmony. The loss function in joint training combines the losses from the individual experts and the gating network, ensuring that both components contribute to the overall performance.
The combined loss gradients are then propagated through the gating network and the expert models, facilitating updates that improve the MoE system's performance.
Inference phase
During inference, the gating network takes the input and selects the top k experts most likely to provide the correct output. The selected experts process the input and generate their predictions, which are then combined to produce the final output. This selective activation of experts allows MoE to make predictions with a fraction of the computational cost of a fully connected model.
The Power of Sparse Activation
One of the key advantages of MoE is its use of sparse activation, which stems from the concept of conditional computation. Unlike traditional "dense" models where all parameters are activated for every input, MoE selectively activates only the necessary network parts. This approach provides several benefits:
Efficiency: MoE models can handle massive amounts of data with far fewer computational resources by activating only the most relevant experts. This is particularly important for large-scale models like those used in NLP, where processing time and memory requirements can quickly become prohibitive. A notable example is Mistral 8x7B–a high-quality sparse mixture of experts model (SMoE)--which uses a Mixture of Experts framework with eight experts. Each expert has 11B parameters and 55B shared attention parameters, totaling 166B per model. What's interesting is that during inference, only two experts are used for each token, making AI processing more efficient and focused.
Load balancing: One important consideration with sparse activation is ensuring that all experts receive sufficient training. If only a few experts are consistently activated by gating networks, they can become over-specialized while others remain underutilized. To prevent this imbalance, modern MoE implementations use techniques like Noisy Top-k Gating, Shazeer et al. (2017), which adds a small amount of (tunable) noise to the expert selection process, ensuring a more balanced distribution of training across all experts.
MoE's Advantages Over Traditional Models and its Challenges
Advantages
The mixture of Expert (MoE) architecture offers several advantages over traditional deep learning models.
Enhanced scalability: MoE models scale easily to billions or even trillions of parameters due to sparse activation, which reduces the need for massive computational power.
Increased flexibility: One unique benefit of MoE is that new experts can be added to the existing model without retraining the entire system. This adaptability allows the model to readily accommodate new tasks and domains.
Efficiency: Since MoE activates only the most relevant experts for each input, it can handle diverse tasks more efficiently than traditional models. This makes it faster and more accurate, as experts can focus on what they do best.
Parallel processing: Experts can work independently, which allows for efficient parallel processing. This approach can cause faster training and inference times.
Challenges
Despite the above advantages, MoE models also have certain challenges and limitations.
Training complexity: Training MoE models can be challenging, particularly in managing the gating network and balancing the contributions of individual experts. It's important to ensure that the gating network learns to assign appropriate weights to experts effectively, which prevents overfitting or underutilizing specific experts.
Communication costs: MoE models require significant infrastructure resources during training and inference due to managing multiple experts and the gating mechanism. Additionally, when deployed at scale, especially across various devices or distributed systems, the communication overhead becomes a major challenge. Coordinating and synchronizing outputs from various experts on different servers can lead to increased latency and computational load. ****
Expert Capacity: Thresholds are set on the number of inputs each expert can process simultaneously to prevent overloading specific experts and ensure a balanced workload. A common approach is to use top-2 routing with a 1.25 capacity factor, meaning that two experts are selected per input, and each expert processes 1.25 times its usual capacity. This strategy also assigns one expert per core, optimizing performance and resource management.
Interpretability: Opacity is already a notable problem in AI, including for leading LLMs. Mixture-of-experts (MoE) models can make this even harder because they are more complicated. Instead of just looking at how one model makes decisions, we must figure out how different experts and the gating system work together. This extra complexity can make it much harder to understand why the model made a certain choice.
Applications of MoE
Mixture-of-Experts is already being used in a wide range of applications.
Natural language processing: Mixture-of-experts (MoE) models are great for language tasks like translation, sentiment analysis, and answering questions because they can assign each task to specialists. For example, it's been reported that OpenAI's GPT-4 large language model uses an MoE setup with 16 experts, although OpenAI hasn't officially confirmed its design details. Another example is Microsoft’s translation API, Z-code. The MoE architecture in Z-code allows the model to support a massive scale of model parameters while still using the same computing power.
Computer vision: Google's V-MoEs, a sparse architecture based on Vision Transformers (ViT), show how effective MoE can be for computer vision tasks. MoE models can help with image processing by giving different tasks to specialized experts. For example, one expert might focus on certain types of objects, specific visual features, or other parts of an image.
Multimodal learning: MoE can combine data from multiple sources, such as text, images, and audio, into a model. This makes MoE ideal for applications like multimodal search or content recommendation, where data from different modalities needs to be integrated.
Future Directions for MoE
In the coming years, research on Mixture-of-Experts (MoE) will focus on making the models more efficient and easier to understand. This includes improving how experts work together and finding better ways to assign tasks to the right experts.
Further scaling: MoE models can be scaled to even larger sizes while minimizing computational costs. This includes optimizing training and inference phases to handle the increasing size of experts and data. Techniques such as distributed computing are being explored to spread tasks across multiple machines more efficiently, reducing bottlenecks and speeding up the model’s operation.
Innovative routing mechanisms: Another area of research focuses on developing more efficient routing strategies. While existing methods like top-k routing are commonly used, advanced techniques such as Expert Choice Routing aim to improve task assignment to experts. This can lead to more efficient load balancing and improved task-to-expert matching, ensuring the model performs optimally under different conditions.
Real-World applications: MoE models have great potential in real-world applications like healthcare and autonomous systems due to their ability to handle complex tasks. In healthcare, they could be used for personalized treatment plans, while autonomous systems could use them for tasks like object recognition and decision-making.
Conclusion
Mixture-of-Experts is a powerful model architecture that allows neural networks to scale efficiently by dividing tasks among specialized experts. With sparse activation, MoE models can handle massive datasets and complex tasks with a fraction of the computational cost of traditional models. While MoE does present challenges in terms of training complexity and communication costs, its advantages in terms of scalability, flexibility, and efficiency make it an increasingly popular choice for modern AI applications. From natural language processing to computer vision and multimodal tasks, MoE models are proving their value by allowing experts to specialize in different areas, improving both speed and accuracy.
Further Resources
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- What is MoE and Its Core Concepts
- MoE in Deep Learning: Historical Evolution
- MoE Architecture in Detail (How it Works)
- The Power of Sparse Activation
- MoE's Advantages Over Traditional Models and its Challenges
- Applications of MoE
- Future Directions for MoE
- Conclusion
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
This post covers Natural Language Processing fundamentals that are essential to understanding all of today’s language models.

Training Your Own Text Embedding Model
Explore how to train your text embedding model using the `sentence-transformers` library and generate our training data by leveraging a pre-trained LLM.

Discover SPLADE: Revolutionizing Sparse Data Processing
SPLADE is a technique that uses pre-trained transformer models to process sparse data. This post explores SPLADE, its benefits, and real-world apps.