




Exploring BERTopic: A New Era of Neural Topic Modeling
BERTopic is a novel topic modeling technique that allows for easily interpretable topics while keeping important words in the topic descriptions.
Read the entire series
- Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
- Primer on Neural Networks and Embeddings for Language Models
- Sparse and Dense Embeddings
- Sentence Transformers for Long-Form Text
- Training Your Own Text Embedding Model
- Evaluating Your Embedding Model
- Class Activation Mapping (CAM): Better Interpretability in Deep Learning Models
- CLIP Object Detection: Merging AI Vision with Language Understanding
- Discover SPLADE: Revolutionizing Sparse Data Processing
- Exploring BERTopic: A New Era of Neural Topic Modeling
- Streamlining Data: Effective Strategies for Reducing Dimensionality
- All-Mpnet-Base-V2: Enhancing Sentence Embedding with AI
- Time Series Embedding in Data Analysis
- Enhancing Information Retrieval with Learned Sparse Retrieval
- What is BERT (Bidirectional Encoder Representations from Transformers)?
- What is Mixture of Experts (MoE)?
As we navigate the vast ocean of digital information, the need for tools to extract meaningful insights from unstructured text data has never been more critical. BERTopic stands at the forefront of this transformative era, employing neural network-based techniques for generating topics and uncovering themes and patterns in large text corpora with unprecedented accuracy and depth.
In this blog, we will explore the intricacies of the BERTopic topic modeling technique, from its reliance on transformer models to its innovative approach to clustering and dimensionality reduction.
Before we dive into BERTopic, we should learn about Topic Modeling.
Topic modeling is a method for unearthing the latent themes or “topics” within a collection of documents. It involves examining the text within these documents to detect patterns and relationships that indicate the presence of these topics. For instance, a document focused on artificial intelligence will likely contain terms like “large language models” and “ChatGPT,” unlike a document centered on baking bread.
Topic modeling has existed since 1990, and some popular techniques include Latent Semantic Analysis (LSA), Latent Dirichlet Allocation (LDA), and non-negative Matrix Factorization (NMF). However, these conventional techniques either don’t present the semantic relation between words or struggle to extract the most representative topic for a given group of documents.
BERTopic is a novel topic modeling technique that simplifies the topic modeling process. It uses various embedding techniques and class-based TF-IDF (c-TF-IDF) to create dense clusters, allowing for easily interpretable topics while keeping important words in the topic descriptions. It can analyze latent topics in clusters of varying densities and extract topics with the most relevant keywords. BERTopic extends on existing document embedding-based topic modeling methodologies, but flexibility and robustness separate it from pre-existing solutions.
BERTopic approaches topic modeling in four steps on a high level:
Document Embedding: Convert documents into embeddings using a pre-trained transformer language model like Bidirectional Encoder Representations from Transformers (BERT).
Dimensionality Reduction: Compresses embeddings into a lower-dimensional space.
Clustering: Group these embeddings to gather similar documents in one category.
Topic Extraction: Extract topic names using a class-based variation of TF-IDF.
BERTopic starts with transforming our input documents into numerical representations called embeddings. BERTopic allows you to choose any state-of-the-art embedding model capable of capturing the semantic essence of the text. In the original BERTopic paper, Sentence BERT (SBERT) was employed as the embedding model due to its robust performance across various sentence embedding tasks. This model, specifically the all-MiniLM-L6-v2 model, is accessible through the HuggingFace Hub. Alternatively, proprietary models from OpenAI, such as text-embedding-ada-002, text-embedding-small, or text-embedding-large, represent other options for generating embeddings, though these are typically subscription-based.
Embeddings are high-dimensional, which might slow the following step of clustering. Furthermore, dimensionality reduction can help us visualize our data when assessing whether it can be clustered. Therefore, after building our embeddings, BERTopic compresses them into a lower-dimensional space.
In this step, the embedded document vectors are projected to a smaller embedding space, allowing the clustering algorithms to create coherent clusters. Many solutions are available for dimensionality reduction, like Principal Component Analysis (PCA) or t-SNE (t—t-distributed stochastic neighbor embeddings). Still, the paper’s author recommends using UMAP (Uniform Manifold Approximation and Projection), as it maintains the local and global information while projecting the matrices to lower dimensions.
After reducing the dimensionality of our input embeddings, we can apply a clustering algorithm to create document clusters. This process is important because the more performant our clustering technique is, the more accurate our topic representations will be.
The density-based clustering approach (DBSCAN) is most recommended here as it allows for creating clusters with varying densities, which is more suited for topic modeling. In the BERTopic paper, the author recommends using a hierarchical density-based clustering approach (HDBSCAN), a variant of the original DBSCAN algorithm. HDBSCAN is more suited than DBSCAN because it:
Does not need to specify the number of topics beforehand.
Effectively handles outliers.
However, there is no perfect clustering model; you might want to use something entirely different for your use case.
The final step in BERTopic is extracting topics for each of our clusters. To do this, BERTopic uses a modified version of TF-IDF called class-based TF-IDF, also known as c-TF-IDF.
TF-IDF stands for Term Frequency, Inverse Document Frequency, an algorithm used to quantify a word’s relevance to a document. In a class-based variant of TF-IDF, all documents in a cluster are concatenated and represented as one document. Instead of identifying a word’s relevance to a document, the cTF-IDF reflects a word’s relevance to a cluster.
In addition to the four key steps mentioned above, the BERTopic approach also involves optional steps such as tokenization and representation fine-tuning based on users’ specific requirements.
 An overview of the BERTopic library
An overview of the BERTopic library
An overview of the BERTopic library; Image source
What is BERTopic?
BERTopic is a cutting-edge topic modeling technique that leverages transformer models and class-based TF-IDF (c-TF-IDF) to create dense clusters, allowing for easily interpretable topics while keeping important words in the topic descriptions. This innovative approach simplifies the topic modeling process, making it accessible even to those with limited experience in the field. With its high-level interface and default settings, BERTopic enables users to build powerful models in just a few lines of code. Moreover, it supports a wide range of topic modeling techniques, making it a versatile tool for various applications, from academic research to business analytics.
How BERTopic Works
BERTopic operates through a combination of three main steps: BERT embeddings, c-TF-IDF, and topic modeling. Initially, it uses BERT embeddings to transform a set of documents into numerical representations that capture the semantic essence of the text. Next, it applies c-TF-IDF to extract the most important words for each topic, treating all documents within a single category as a unified document. Finally, BERTopic employs topic modeling to generate topics and their corresponding probabilities. This comprehensive process allows BERTopic to create dense clusters and provide easily interpretable topic descriptions, making it a powerful tool for uncovering hidden themes in large text corpora.
Key Features of the BERTopic Model
The BERTopic model boasts several key features that make it a formidable tool for topic modeling:
Modularity: BERTopic’s modular design allows users to build their own topic model and experiment with several topic modeling techniques on top of their customized model. This flexibility enables users to tailor the model to their specific needs and preferences.
Fine-tune topic representations: Users can fine-tune topic representations using various techniques, such as KeyBERTInspired, ChatGPT, or other models from OpenAI. This feature ensures that the topics generated are highly relevant and accurate.
Multilingual support: BERTopic supports multilingual topic modeling, allowing users to select models that cater to over 50 languages. This broad language support makes BERTopic suitable for global applications.
Visualizations: BERTopic offers a range of visualization tools to help users understand and interpret the results. These include topic visualizations, document visualizations, and topic hierarchy visualizations, all of which provide valuable insights into the modeled topics.
BERTopic Practical Use Cases and Applications
BERTopic has seen a lot of applications across different sectors and industries in recent years, including use by top Fortune 500 companies like Meta, Microsoft, CISCO, NVIDIA, and Amazon. Developers and organizations use BERTopic in various use cases and domains, ranging from cancer research and voice perception studies to analyzing employee surveys and social media content. BERTopic provides interesting perspectives in understanding data clusters, enhancing the analysis experience in various domains.
Some of the real-world applications of BERTopic include:
Telefonica, a multinational telecommunications company, adopted BERTopic for topic modeling and classification of customer reviews to improve user experience (UX) and reveal useful customer information.
In the U.S. Department of Homeland Security, BERTopic analyzes employee surveys by identifying key topics discussed and assessing the sentiments.
McMaster University uses BERTopic in a research project to categorize first impressions based on voice perception by analyzing descriptions from participants who listen to recordings of people saying “Hi.”
Iodine Software uses BERTopic to analyze physician-created documents from hospitals. They employ it to identify themes within the text and ensure a clear interpretation of medical documentation.
Visualizing and Interpreting Results
Visualizing and interpreting the results of BERTopic is crucial for understanding the topic model. BERTopic provides various visualization tools that help users grasp the intricacies of the topics, documents, and topic hierarchy. Some of the key visualization tools include:
Topic visualizations: These visualizations help users understand the topics and their corresponding important words, providing a clear picture of the themes present in the text data.
Document visualizations: These visualizations allow users to see how documents are distributed across different topics, offering insights into the relationship between documents and topics.
Topic hierarchy visualizations: These visualizations illustrate the hierarchical structure of topics, showing the relationships between different topics and subtopics. This helps users comprehend the broader context and connections within the data.
Evaluating the Effectiveness of BERTopic
Evaluating the effectiveness of BERTopic is essential for understanding its performance and identifying areas for improvement. Several metrics are used to assess BERTopic, including:
Topic coherence: This metric evaluates the coherence of topics by measuring the similarity and significance of the words within each topic. High topic coherence indicates that the topics are meaningful and well-defined.
Topic hierarchy: This metric assesses the hierarchical structure of topics, examining the relationships and coherence between parent and child topics. A well-structured topic hierarchy enhances the interpretability of the model.
Document-topic alignment: This metric measures the alignment between documents and their assigned topics, evaluating the similarity and coherence of the document-topic pairs. Strong document-topic alignment ensures that the topics accurately represent the content of the documents.
By evaluating these metrics, users can gain insights into the effectiveness of BERTopic and make necessary adjustments to fine-tune the model for optimal performance.
Challenges and Considerations in Topic Modeling
Using BERTopic for topic modeling can pose challenges like choosing the right embedding model, multilingual support, offline running, slow inference, and more. Let’s shed light on some of the more detailed overviews of the common issues and their solutions when generating topics when using BERTopic:
Memory: BERTopic tends to run into out-of-memory issues when modeling topics for larger datasets. The primary cause of that usually is UMAP, which could be executed in a low memory footprint. Secondly, we can skip the calculation of a considerable document topic distribution in the topic extraction phase and limit the probability matrix to relevant top-K topics. Thirdly, we can decrease the size of the TF-IDF matrix by setting the minimum frequency of a word to be considered a potential topic as a large number.
Speed: BERTopic runs slow on a larger collection of documents due to the embedding phase. To speed up your algorithm, you can do it asynchronously in parallel beforehand. Another solution is to use a GPU if you can access one or utilize the free tiers from Google Colab or Kaggle.
Topic Number: BERTopic usually generates many topics, which is not helpful. An easier way to reduce the number of topics is to set the minimum topic size. In another scenario, when the number of generated documents is very few, one can increase the number of documents and their diversity in the dataset or decrease the minimum topic size.
BERTopic allows users to create a customized topic model by swapping or removing components of the modeling steps.
BERTopic is an open-source project hosted on GitHub. The package has over 5,000 stars and provides extensive documentation for getting started with the framework. BERTopic offers a modular approach to using different algorithms for each step, allowing you to build your own customized topic model.
BERTopic essentially allows you to build your own topic model. Image source
Each step is a building block, and the library offers multiple options for each phase. For example, if we choose spaCy for document embedding, with PCA for dimensionality-reduction, K-means for clustering for clustering methods, and CountVectorizer for combining documents, and finally, using c-TF-IDF for topic extraction, we have an end-to-end customized BERTopic model.
To start with BERTopic, first install this package using:
!pip install bertopic
!pip install bertopic[visualization]
Next, set up the dataset for which you want to model the topics. I am using the 20newsgroup dataset with English documents in it.
# Load the Data
from sklearn.datasets import fetch_20newsgroups
docs2 = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))['data']
docs2
Initialize the BERTopic model and find the topics.
# Initialize the BERTopic model
model = BERTopic(verbose=True,nr_topics=10)
# Let’s find the latent topics
topics, probs = model.fit_transform(docs2)
Display the top topics extracted and inspect one topic closely to see its top words, to understand the relation between the topic and its relevant documents.
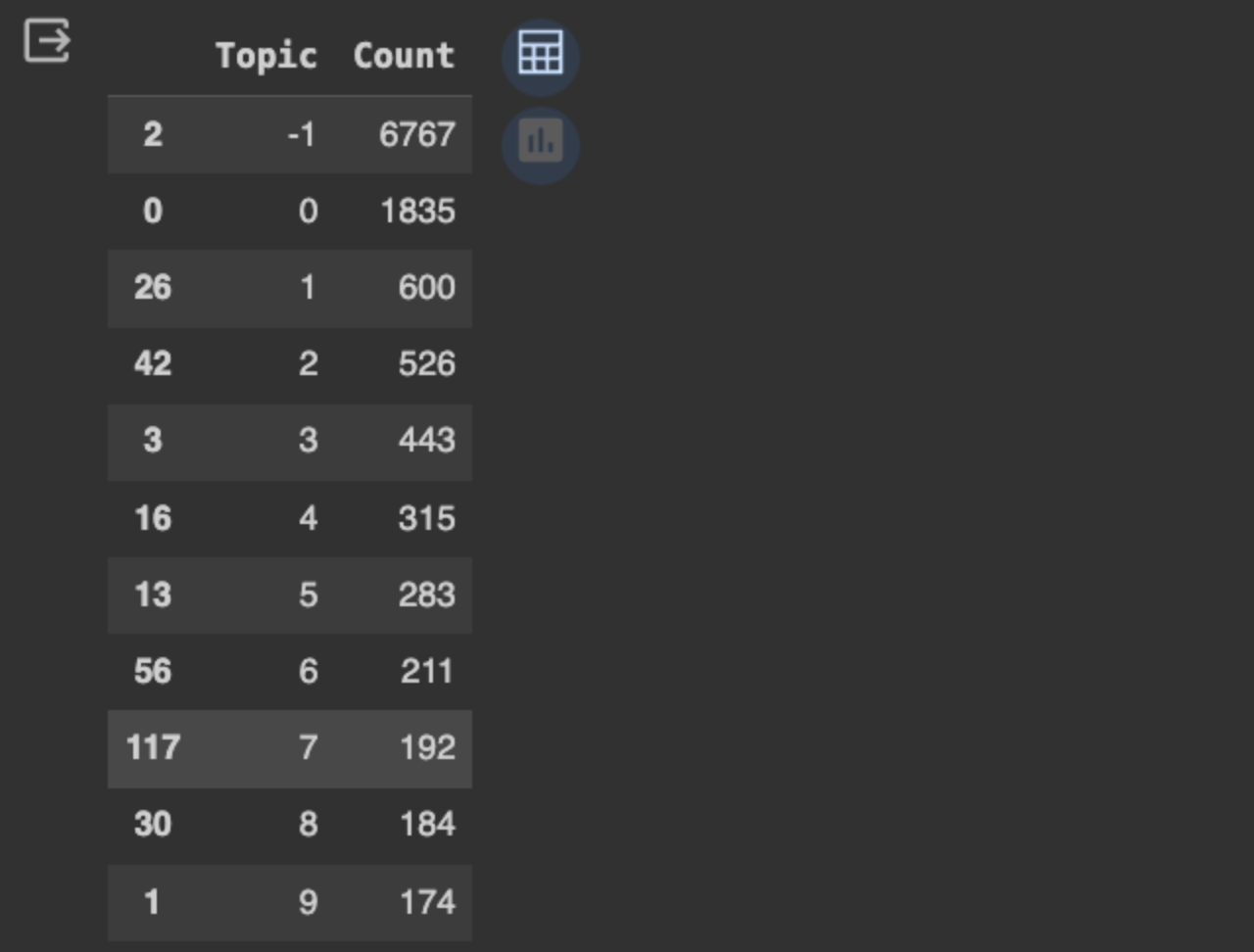
# Select top topics
model.get=topic+freq().head(11)
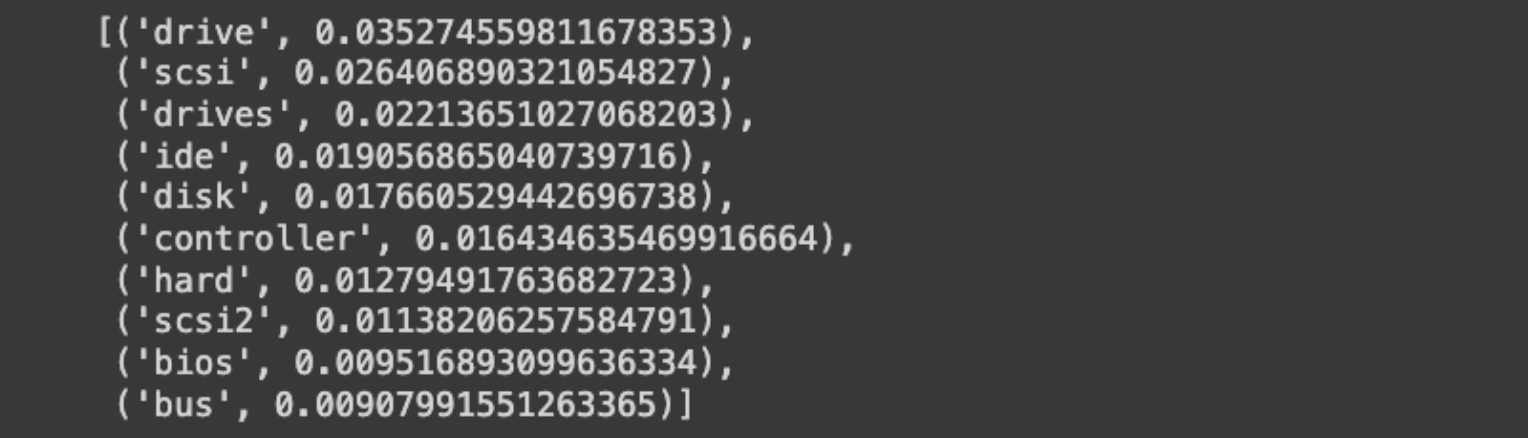
# Let’s look at the top words of the topic
model/get_topic(3)
Visualize the topics using many supported visualizations in BERTopic. Let’s visualize the cluster's density distribution:
# Visualize topic clusters
model.visualize_topics()

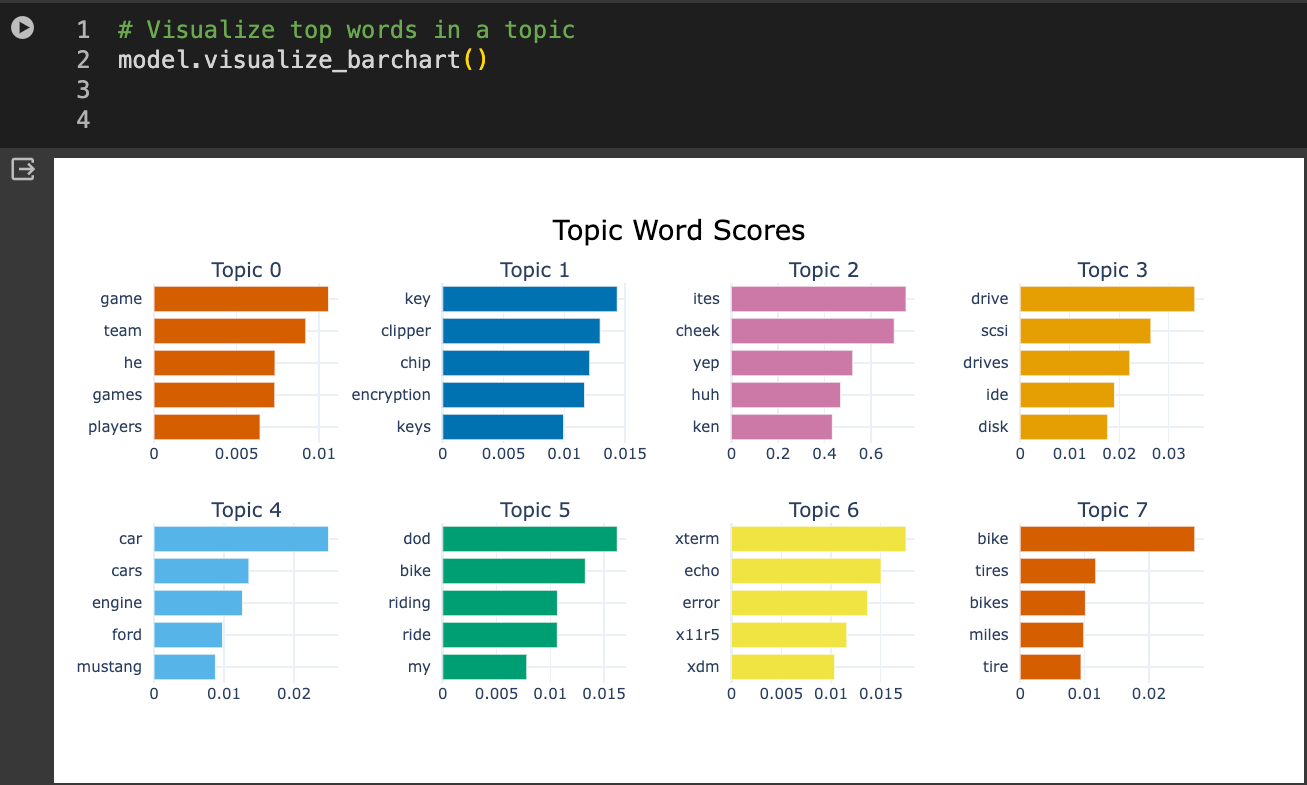
Finally, we can also look at the top words in a cluster or in a topic:
# Visualize top words in a topic
model.visualize_barchart()
If you want to build more sophisticated topic modeling solutions with more control, check these resources:
BERTopic is an amazing framework that allows quick off-the-shelf topic modeling to help understand a large collection of documents. BERTopic has many advantages, including:
No need for data preprocessing.
Flexibility to try different document embeddings from Gensim, Flair, Spacy, and now even a state-of-the-art LLM form OpenAI or HuggingFace.
Awesome range of visualizations to inspect and analyze the modeled topics.
The wide applicability of BERTopic, from scholarly research in cancer and voice perception to practical analyses in corporate settings like employee feedback and social media monitoring, underscores its significance and potential impact across different sectors. Companies like Meta, Microsoft, and Amazon, among others, have already harnessed the power of BERTopic to improve their operations and strategies.
As we continue to generate and rely on vast amounts of text data, tools like BERTopic become indispensable in our toolkit for data analysis and knowledge discovery. It democratizes the power of advanced topic modeling for a broader audience and sets a new standard in the field, promising ongoing evolution and enhancement to meet the dynamic demands of data-driven industries.
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- What is BERTopic?
- How BERTopic Works
- Key Features of the BERTopic Model
- BERTopic Practical Use Cases and Applications
- Visualizing and Interpreting Results
- Evaluating the Effectiveness of BERTopic
- Challenges and Considerations in Topic Modeling
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
This post covers Natural Language Processing fundamentals that are essential to understanding all of today’s language models.

Training Your Own Text Embedding Model
Explore how to train your text embedding model using the `sentence-transformers` library and generate our training data by leveraging a pre-trained LLM.

CLIP Object Detection: Merging AI Vision with Language Understanding
CLIP Object Detection combines CLIP's text-image understanding with object detection tasks, allowing CLIP to locate and identify objects in images using texts.