




Top 10 NLP Techniques Every Data Scientist Should Know
In this article, we will explore the top 10 techniques widely used in NLP with clear explanations, applications, and code snippets.
Read the entire series
- An Introduction to Natural Language Processing
- Top 20 NLP Models to Empower Your ML Application
- Unveiling the Power of Natural Language Processing: Top 10 Real-World Applications
- Everything You Need to Know About Zero Shot Learning
- NLP Essentials: Understanding Transformers in AI
- Transforming Text: The Rise of Sentence Transformers in NLP
- NLP and Vector Databases: Creating a Synergy for Advanced Processing
- Top 10 Natural Language Processing Tools and Platforms
- 20 Popular Open Datasets for Natural Language Processing
- Top 10 NLP Techniques Every Data Scientist Should Know
- XLNet Explained: Generalized Autoregressive Pretraining for Enhanced Language Understanding
The ability to understand and analyze human language is important. Whether it's through virtual assistants, email filtering, or social media analysis, the need for machines to process and comprehend natural language is expanding. This growing demand has sparked the development of numerous techniques that allow computers to interpret, generate, and manipulate human languages. Natural Language Processing (NLP) stands at the forefront of this effort, bridging the gap between human communication and machine understanding.
In this article, we’ll look into the top 10 techniques used in NLP, offering clear explanations, practical applications, and even some code snippets to help you get started. Additionally, we’ll explore how vector databases play a role in various NLP use cases, enhancing the power and efficiency of these techniques.
What is Natural Language Processing (NLP)?
Natural language processing (NLP) is a field that combines artificial intelligence (AI) and computational linguistics. It uses algorithms and models to analyze, understand, and generate natural language for various applications. It enables machines to process large amounts of natural language data and extract meaningful information, making it a key component in many AI systems.
Natural language processing has found top applications across a wide range of industries. Discover the top-10 real-world applications of NLP in detail. Some of the examples of NLP in real-world scenarios are:
Chatbots: NLP is widely used to build intelligent chatbots that can understand and respond to customer queries in real time, enhancing customer service experiences.
Sentiment Analysis: Businesses use sentiment analysis to gauge public opinion and understand customer feedback by analyzing social media posts, reviews, and surveys.
Translation: NLP powers language translation services, allowing users to translate text from one language to another accurately and quickly.
Voice Assistants: Virtual assistants like Siri, Alexa, and Google Assistant rely on NLP to process spoken language, understand commands, and provide relevant responses or actions. These assistants are used in smart homes and personal devices.
Content Moderation: Social media platforms and online communities use NLP to automatically detect and filter inappropriate or harmful content, ensuring a safer online environment. This includes flagging offensive language, detecting fake news, and preventing cyberbullying.
Text Summarization: NLP can automatically summarize lengthy documents, making it easier for users to extract key points without reading through entire texts. This is useful in legal and academic fields, where large volumes of text need to be reviewed efficiently.
Overview of the Top 10 NLP Techniques
Natural Language Processing covers a wide range of techniques and technologies, allowing machines to understand, interpret, and generate human language. Each technique has its own unique applications and strengths, making NLP an essential and powerful tool for everything from text analysis to machine translation.
Before we discuss each technique in detail, let’s take a quick look at these top 10 NLP techniques that every data scientist should know. These techniques are the backbone of many advanced NLP applications, powering everything from chatbots to translation services.
Tokenization
Lemmatization and Stemming
Named Entity Recognition (NER)
Part-of-Speech (POS) Tagging
Parsing
Word Embeddings
Machine Translation
Text Summarization
Sentiment Analysis
Topic Modeling
Now, let’s explore each of these techniques in more detail.
Tokenization
Tokenization divides a text into smaller segments known as tokens. These tokens can be words, sentences, or even subwords, depending on the task at hand. By segmenting text into tokens, NLP models can better understand the structure and meaning of the language, making it easier to perform tasks like text analysis, translation, and sentiment analysis.
There are two types of tokenization:
Word Tokenization: Word tokenization is the process of dividing a text into separate words. This is one of the most common forms of tokenization and is used in tasks such as text classification, sentiment analysis, and word embeddings.
Sentence Tokenization: It breaks down a text file into sentences. This is useful for tasks like summarization, translation, and parsing, where understanding the sentence structure is important. :
Word Tokenization with NLTK
```
import nltk
from nltk.tokenize import word_tokenize
# Download necessary resources
nltk.download('punkt')
# Sample text
text = "Tokenization is essential for NLP."
# Word tokenization
tokens = word_tokenize(text)
print(tokens)
```
Output: ['Tokenization', 'is', 'essential', 'for', 'NLP', '.']
Applications of Tokenization
Some of the well-known use cases for tokenization are:
Text Classification: Tokenization is the first step in preparing text data for classification tasks. By converting text into tokens, models can analyze the content and classify it into categories such as spam detection or sentiment analysis.
Machine Translation: In translation tasks, text is tokenized into words or subwords to accurately translate from one language to another. Sentence tokenization helps maintain the context of translations.
Search Engines: Tokenization is used in search engines to index and retrieve relevant documents. By breaking down search queries into tokens, search engines can match them with documents that contain similar tokens.
Text Summarization: Sentence tokenization is used to break down large texts into smaller sentences, which can then be summarized by selecting the most important sentences or phrases.
Speech Recognition: In speech-to-text applications, tokenization helps in breaking down spoken language into manageable text units for further processing.
Stop Word Removal
Stop words are common words in a language, such as "and," "the," "is," and "in," that often carry little meaningful information and are frequently removed from the text during preprocessing in NLP tasks. These words are so common that they can overshadow more important words that contribute to the meaning of a sentence or document. By removing stop words, NLP models can focus on the more significant terms that carry the core meaning of the text, improving the efficiency and accuracy of text analysis.
There are two main Techniques for stop-word removal:
Using Predefined Stop Word Lists: Many NLP libraries provide lists of stop words that can filter out common, non-essential words from text. These lists are language-specific and typically include the most frequently occurring words unlikely to contribute to the analysis.
Customizing Stop Word Lists: Depending on the specific application, you may need to customize the stopword list by adding or removing words. For instance, if you're analyzing legal documents, certain words that are common in general language might be important in that context and shouldn't be removed. Custom stopword lists allow for more precise filtering based on the domain and task at hand.
Stop Word Removal with NLTK
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# Download the stopwords corpus
nltk.download('stopwords')
nltk.download('punkt')
# Sample text
text = "This is a simple example to demonstrate stop word removal."
# Tokenize the text
tokens = word_tokenize(text)
# Load the list of stop words
stop_words = set(stopwords.words('english'))
# Remove stop words from the tokens
filtered_tokens = [word for word in tokens if word.lower() not in stop_words]
print(filtered_tokens)
Output: ['This', 'simple', 'example', 'demonstrate', 'stop', 'word', 'removal', '.']
Stop Word Removal Applications
Improving Text Analysis: The removal of unimportant words allows the model to focus on the terms that contribute the most to the overall meaning of the text.
Boosting Model Performance: Stop word removal reduces the number of features the model needs to process, leading to faster training times and better generalization on unseen data.
Search Engines: Stop word removal is commonly used in search engines to improve search results by ignoring common words that are unlikely to change the relevance of the search query.
Summarization: When summarizing text, removing stop words helps the algorithm focus on the key points, ensuring that the summary captures the essence of the document without unnecessary filler words.
Stemming and Lemmatization
Stemming is the process of reducing words to their base or root form by removing suffixes and prefixes. The idea is to simplify words into their basic form, allowing NLP models to treat different word forms as the same entity. This approach helps reduce the text data's dimensionality and ensures that different inflections of a word are treated uniformly.
Example of Stemming:
"Playing," "played," and "plays" would all be reduced to "play."
"Cats" would be reduced to "cat."
On the other hand, lemmatization, like stemming, is the process of reducing words to their base form but focusing on returning the word to its dictionary or canonical form, known as the lemma. Lemmatization takes into account the context and part of speech of a word to ensure that it is reduced to the correct form. Unlike stemming, which often chops off parts of a word, lemmatization aims to produce more meaningful and accurate base forms.
Example of Lemmatization:
"Running" would be reduced to "run."
"Better" would be reduced to "good" (based on context).
Stemming with NLTK
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
# Initialize the stemmer
stemmer = PorterStemmer()
# Sample text
text = "Playing plays played"
# Tokenize the text
tokens = word_tokenize(text)
# Apply stemming
stemmed_words = [stemmer.stem(token) for token in tokens]
print(stemmed_words)
Output: ['play', 'play', 'play']
Lemmatization with NLTK
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
import nltk
# Download necessary resources
nltk.download('wordnet')
nltk.download('omw-1.4')
# Initialize the lemmatizer
lemmatizer = WordNetLemmatizer()
# Sample text
text = "Running runs better"
# Tokenize the text
tokens = word_tokenize(text)
# Apply lemmatization
lemmatized_words = [lemmatizer.lemmatize(token, pos='v') for token in tokens]
print(lemmatized_words)
Output: ['Run', 'run', 'good']
Applications of Stemming and Lemmatization
Some interesting applications of stemming and lemmatization are:
Enhancing Text Normalization: Normalizing text by stemming or lemmatizing words can significantly improve model performance in tasks like text classification or sentiment analysis. This is because the model can better identify patterns and relationships between words when different word forms are treated as the same entity.
Improving Search Engines: In search engines, stemming and lemmatization help improve search results by ensuring that queries and documents with different forms of the same word are matched more effectively.
Reducing Dimensionality: By converting words to their base forms, stemming and lemmatization help reduce the dimensionality of the text data, making the processing faster and more efficient.
Part-of-Speech (POS) Tagging
Part-of-speech (POS) tagging involves assigning each word in a sentence to its appropriate part of speech. It is essential for understanding the grammatical structure of a sentence and plays an important role in many NLP tasks.
POS tagging is critical because it helps disambiguate words with multiple meanings or functions in different contexts. For example, the word "run" can be a noun ("a morning run") or a verb ("I run every day"). By correctly identifying the part of speech, NLP models can interpret the sentence more accurately and perform more advanced tasks such as entity recognition, sentiment analysis, or machine translation.
There are two main techniques for POS:
Rule-based Methods: Rule-based POS tagging relies on a set of hand-crafted rules to assign POS tags to words. These rules often take into account the word's suffix, prefix, and surrounding words to determine its part of speech. While rule-based methods can be effective, they often struggle with ambiguity and require extensive rule creation.
Statistical Methods: Statistical POS tagging uses machine learning algorithms to assign POS tags based on the probability of a word's part of speech given its context. This approach typically involves training a model on a large labeled dataset, where the model learns patterns and relationships between words and their parts of speech. Statistical methods, such as Hidden Markov Models (HMM) and Conditional Random Fields (CRF), tend to be more accurate and adaptable than rule-based methods.
POS Tagging with NLTK
import nltk
from nltk.tokenize import word_tokenize
from nltk import pos_tag
# Sample text
text = "The quick brown fox jumps over the lazy dog."
# Tokenize the text
tokens = word_tokenize(text)
# Perform POS tagging
pos_tags = pos_tag(tokens)
print(pos_tags)
Output: [('The', 'DT'), ('quick', 'JJ'), ('brown', 'JJ'), ('fox', 'NN'), ('jumps', 'VBZ'), ('over', 'IN'), ('the', 'DT'), ('lazy', 'JJ'), ('dog', 'NN')]
| Tag | Meaning | Example |
| DT | Determiner | "the," "a," "an" |
| JJ | Adjective | "quick," "lazy," "brown" |
| NN | Noun, singular or mass | "dog," "fox" |
| VBZ | Verb, 3rd person singular present | "jumps," "runs" |
| IN | Preposition or subordinating conjunction | "over," "in," "before" |
Applications of Part-of-Speech (POS) Tagging
Analyzing Sentence Structure: By identifying the parts of speech, NLP models can better understand the relationships between words and phrases, which are essential for tasks like parsing and syntax analysis.
Extracting Meaningful Insights: POS tags help identify and categorize entities, such as names, dates, and locations. For example, in Named Entity Recognition (NER), POS tags help determine whether a word is likely to be a proper noun or an entity.
Text Summarization: POS tagging identifies key phrases and important information in a text, making it useful in text summarization tasks where the goal is to capture the essence of a document.
Sentiment Analysis: It helps models understand the context of words. For instance, adjectives like "happy" or "sad" are often key indicators of sentiment, and correctly tagging them improves the accuracy of the analysis.
Machine Translation: It ensures that words are translated with the correct grammatical context. For example, correctly identifying whether a word is a noun or a verb can significantly impact the quality of the translation.
Named Entity Recognition (NER)
Named Entity Recognition (NER) identifies and classifies named entities within text into predefined categories, such as names of people, organizations, locations, dates, and more. The goal of NER is to extract valuable information from unstructured text data, enabling machines to understand and work with specific entities. NER is crucial in information retrieval, content categorization, and question-answering systems.
NER is significant because it allows NLP systems to automatically detect and classify important information within large volumes of text. For example, in a news article, NER can identify the key figures, locations, and dates involved in the story, providing a clearer understanding of the content.
There are three main techniques for NER:
Rule-based Approaches: This approach uses established patterns and linguistic rules to recognize named entities. These rules may include regular expressions, gazetteers (lists of known entities), and part-of-speech tags to detect specific entities in the text. While rule-based methods can be effective for certain domains, they are often rigid and require extensive manual rule creation, making them less adaptable to new contexts.
Machine Learning Approaches: Machine learning-based NER systems use labeled training data to learn patterns and relationships between words and entities. These systems typically employ algorithms like Conditional Random Fields (CRF) or Hidden Markov Models (HMM) to classify entities based on their context in the sentence. Machine learning approaches are more flexible than rule-based methods and can generalize better across different domains.
Deep Learning Approaches: Deep learning-based NER systems leverage neural networks, particularly Recurrent Neural Networks (RNNs) and Transformers, to automatically learn complex patterns and representations of entities from text data. These models, such as BERT (Bidirectional Encoder Representations from Transformers), have achieved state-of-the-art performance in NER tasks due to their ability to capture long-range dependencies and contextual information.
NER using NLTK
import nltk
from nltk import ne_chunk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
# Download necessary resources
nltk.download('maxent_ne_chunker')
nltk.download('words')
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
# Sample text
text = "Apple is looking at buying U.K. startup for $1 billion."
# Tokenize the text
tokens = word_tokenize(text)
# POS tagging
pos_tags = pos_tag(tokens)
# Perform NER
named_entities = ne_chunk(pos_tags)
print(named_entities)
- Output: Tree('S', [('Apple', 'NNP'), ('is', 'VBZ'), ('looking', 'VBG'), ('at', 'IN'), ('buying', 'VBG'), ('U.K.', 'NNP'), ('startup', 'NN'), ('for', 'IN'), (''), ('1', 'CD'), ('billion', 'CD'), ('.', '.')])
| Tag | Meaning | Example |
| NNP | Proper Noun, Singular | "Apple," "U.K." |
| VBZ | Verb, 3rd person singular present | "is" |
| VBG | Verb, Gerund or Present Participle | "looking," "buying" |
| IN | Preposition or Subordinating Conjunction | "at," "for" |
| NN | Noun, Singular | "startup" |
| $ | Symbol for Currency | "$" |
| CD | Cardinal Number | "1," "billion" |
| . | Punctuation Mark (Period) | "." |
In this example, the NER system recognizes "Apple" and “UK” as named entities and tags them accordingly.
Applications of NER
Information Extraction: NER is widely used in extracting key information from unstructured text, such as identifying people, organizations, and locations in news articles or research papers. This helps structure data and makes it more accessible for analysis.
Content Categorization: In content management systems, NER can automatically categorize documents based on the entities they contain, such as tagging articles about specific companies or events.
Question Answering Systems: NER enhances question-answering systems by allowing them to identify the relevant entities in a query and match them with the correct answers. For example, a system can identify that a question about "Tesla" relates to the company, not the scientist, and retrieve the appropriate information.
Search Optimization: Search engines and databases use NER to improve search results by recognizing and prioritizing named entities in queries, leading to more relevant and targeted information retrieval.
Bag of Words (BoW)
The BoW model converts a text into a bag (or set) of its words, where each word is treated independently. The text is represented as a fixed-size vector, with each element corresponding to a word in the vocabulary. The value of each element indicates the frequency of that word in the text. For example, in a text corpus containing the words "cat," "dog," and "bird," the sentence "The cat and the dog are friends" would be represented as a vector with the frequency counts of "cat," "dog," and "bird." While BoW is a simple method, it is a powerful foundation for tasks like text classification and information retrieval.
To create a BoW model, follow these steps:
Tokenize the Text: Break the text into individual words (tokens).
Build a Vocabulary: Create a list of unique words (vocabulary) from the text corpus.
Vectorize the Text: Convert each text into a vector of word frequencies based on the vocabulary.
BoW Model with NLTK
import nltk
from nltk.tokenize import word_tokenize
from collections import Counter
# Sample text corpus
text_corpus = [
"The cat sat on the mat",
"The dog sat on the log",
"The bird flew over the mat"
]
# Tokenize the text and build the vocabulary
tokens = [word_tokenize(text.lower()) for text in text_corpus]
vocabulary = sorted(set(word for sentence in tokens for word in sentence))
# Create the BoW model
bow_model = []
for sentence in tokens:
word_count = Counter(sentence)
bow_vector = [word_count[word] for word in vocabulary]
bow_model.append(bow_vector)
print("Vocabulary:", vocabulary)
print("Bag of Words Model:", bow_model)
Output:`Vocabulary: ['bird', 'cat', 'dog', 'flew', 'log', 'mat', 'on', 'over', 'sat', 'the']
Bag of Words Model: [[0, 1, 0, 0, 0, 1, 1, 0, 1, 2], [0, 0, 1, 0, 1, 0, 1, 0, 1, 2], [1, 0, 0, 1, 0, 1, 1, 1, 0, 2]]
Applications OF BoW
Text Classification: The BoW model is widely used in spam detection and sentiment analysis. By representing text as a fixed-length vector, machine learning algorithms can easily process the data and learn patterns to classify new text.
Information Retrieval: The BoW model matches queries with relevant documents in information retrieval systems. By comparing the BoW vectors of the query and documents, the system can identify the most similar documents and rank them accordingly.
Document Similarity: BoW can measure document similarity by comparing their word frequency vectors. This is useful in tasks like clustering similar documents or finding duplicate content.
Keyword Extraction: The BoW model can help in extracting important keywords from a document by identifying the most frequent words. This is often used in content summarization and search engine optimization (SEO).
Language Modeling: Although BoW ignores word order and context, it serves as a simple baseline for language modeling tasks, where more sophisticated models can be built upon it.
TF-IDF (Term Frequency-Inverse Document Frequency)
Unlike the Bag of Words (BoW) model, which counts word occurrences, TF-IDF assigns weights to words based on their frequency in a single document and their rarity across the entire corpus. Words that appear frequently in a document but are rare across the corpus receive higher TF-IDF scores, making them more significant for tasks like text search and relevance ranking.
Calculation
- Term Frequency (TF):
Compute TF by dividing the number of times a word appears in a document by the total number of words in that document.
TF(t, d) =Number of times term t appears in document dTotal number of terms in document d
- Inverse Document Frequency (IDF):
Calculate IDF by taking the logarithm of the total number of documents divided by the number of documents containing the word.
IDF(t,D) = log Total number of documents DNumber of documents containing term t
- TF-IDF:
Multiply TF by IDF to get the TF-IDF score for each word.
TF-IDF(t,d,D)=TF(t,d)×IDF(t,D)
Calculating TF-IDF using Sci-kit learn in Python
from sklearn.feature_extraction.text import TfidfVectorizer
# Sample text corpus
corpus = [
"The cat sat on the mat",
"The dog sat on the log",
"The bird flew over the mat"
]
# Initialize the TfidfVectorizer
vectorizer = TfidfVectorizer()
# Transform the corpus into a TF-IDF matrix by fitting it.
tfidf_matrix = vectorizer.fit_transform(corpus)
# Convert the TF-IDF matrix to a dense array
tfidf_array = tfidf_matrix.toarray()
# Get the feature names (words)
feature_names = vectorizer.get_feature_names_out()
# Print the TF-IDF values
print("Feature Names:", feature_names)
print("TF-IDF Matrix:n", tfidf_array)
Output: Feature Names: ['bird' 'cat' 'dog' 'flew' 'log' 'mat' 'on' 'over' 'sat' 'the']
TF-IDF Matrix:
[[0. 0.49203758 0. 0. 0. 0.37420726
0.37420726 0. 0.37420726 0.58121064]
[0. 0. 0.46869865 0. 0.46869865 0.
0.3564574 0. 0.3564574 0.55364194]
[0.44839402 0. 0. 0.44839402 0. 0.34101521
0.44839402 0. 0.52965746]]
Applications of TF-IDF
Enhancing Text Search: TF-IDF is widely used in search engines to rank documents based on their relevance to a search query. By prioritizing documents that contain important terms with high TF-IDF scores, search engines can return more accurate and relevant results.
Document Classification: In text classification tasks, TF-IDF helps distinguish between different categories of documents by identifying the most significant terms. This improves the accuracy of machine learning models trained on text data.
Keyword Extraction: TF-IDF extracts keywords from a document by identifying words with the highest TF-IDF scores. This is useful for summarization, SEO, and content analysis.
Information Retrieval: TF-IDF plays a key role in information retrieval systems by enabling them to rank documents based on their relevance to a query. This is particularly useful in legal and academic research, where retrieving the most relevant documents is critical.
Relevance Ranking: In recommendation systems, TF-IDF ranks items (e.g., products, articles) based on their relevance to a user's preferences or search history. This helps improve user engagement by delivering more relevant content.
Word Embeddings
In a word embedding model, each word in the vocabulary is represented as a vector of real numbers, typically in a space of 100-300 dimensions. These vectors are learned from a large corpora of text data, and they capture the semantic meaning of words based on their context. For example, the words "king" and "queen" might have similar embeddings because they share similar contexts, whereas "king" and "cat" would be farther apart in the vector space.
Unlike traditional methods like Bag of Words (BoW) or TF-IDF, which represent words as discrete and sparse vectors, word embeddings map words into a low-dimensional space where words with similar meanings are closer. This approach allows NLP models to better understand the semantic relationships between words, making word embeddings a powerful tool for improving the performance of NLP models.
There are three main types of word embeddings
Word2Vec: Developed by Google, Word2Vec is a popular word embedding technique that uses neural networks to learn word representations. It is available in two variants: Continuous Bag of Words (CBOW) and Skip-gram. CBOW predicts a target word from its surrounding context, while Skip-gram predicts the context from a target word. Word2Vec embeddings capture both syntactic and semantic relationships between words.
GloVe (Global Vectors for Word Representation): Developed by Stanford, GloVe generates word vectors by capturing global statistical information about a corpus. Unlike Word2Vec, which focuses on local context, GloVe models the relationships between words using co-occurrence statistics across the entire corpus.
FastText: Developed by Facebook, where each word as a single vector, FastText breaks words into character n-grams, making it more effective for handling out-of-vocabulary words and morphologically rich languages.
Generating Word Embeddings with Gensim Word2Vec
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Sample text corpus
corpus = [
"The cat sat on the mat",
"The dog sat on the log",
"The bird flew over the mat"
]
# Tokenize the text
tokenized_corpus = [word_tokenize(doc.lower()) for doc in corpus]
# Train Word2Vec model
model = Word2Vec(sentences=tokenized_corpus, vector_size=100, window=5, min_count=1, workers=4)
# Get the vector for a word
vector = model.wv['cat']
print("Word Vector for 'cat':", vector)
# Find similar words
similar_words = model.wv.most_similar('cat')
print("Words similar to 'cat':", similar_words)
Output: Word Vector for 'cat': [0.1324516, -0.2402345, ..., 0.0112534]
Words similar to 'cat': [('dog', 0.89), ('bird', 0.85), ...]
Applications of Word Embeddings
Improving NLP Models with Semantic Understanding: Word embeddings are widely used in NLP models to capture semantic relationships between words. This improves the model's ability to understand the context and meaning of words, leading to better performance in tasks like text classification, sentiment analysis, and machine translation.
Text Similarity and Clustering: Word embeddings allow models to measure text similarity by comparing their word vectors. This is useful in document clustering, information retrieval, and plagiarism detection tasks.
Named Entity Recognition (NER): Word embeddings enhance NER models by helping them recognize entities based on their semantic context. For example, a model can identify that "Paris" refers to a location when it appears near words like "France" or "city."
Machine Translation: In machine translation, word embeddings help map words from one language to another by capturing their meanings and relationships in a shared vector space. This improves the accuracy and fluency of translations.
Question-Answering Systems: Word embeddings are used in question-answering systems to match questions with relevant answers by understanding the semantic relationships between words. For example, a system can understand that "capital of France" refers to "Paris" based on its embeddings.
Sentiment Analysis: Word embeddings improve sentiment analysis models by capturing the subtle nuances of language. For example, the word "great" might have a positive sentiment, and its embedding would be close to other positive words like "excellent" and "fantastic."
Topic Modeling
Topic modeling is an unsupervised machine-learning technique that automatically identifies hidden topics within a collection of documents. In this context, a "topic" is a group of words that frequently appear together, indicating a common theme or subject. Topic modeling helps summarize and organize large text datasets by discovering the underlying structure of the data, allowing for a better understanding of the content without manually reading through each document.
Topic modeling is useful for tasks such as text mining, document classification, and information retrieval, where understanding the main subjects discussed in a corpus is essential. By grouping similar documents based on their topics, topic modeling helps users navigate and analyze large datasets more effectively.
There are two main techniques for topic modeling:
Latent Dirichlet Allocation (LDA): LDA is a popular generative probabilistic model that assumes each document is a mixture of topics, and each topic is a mixture of words. It assigns probabilities to words in a document based on the associated topics. LDA is commonly used for discovering topics in large text corpora, where the number of topics is unknown in advance.
Non-Negative Matrix Factorization (NMF): NMF is a linear algebraic technique that decomposes a document-term matrix into two non-negative matrices representing topics and their associated words. Unlike LDA, which is a probabilistic model, NMF focuses on factorizing the original data into parts that are easy to interpret. NMF is useful for discovering topics in datasets with well-separated topics or when interpretability is a priority.
Topic Modeling with LDA using Scikit-learn:
from sklearn.decomposition import LatentDirichletAllocation
from sklearn.feature_extraction.text import CountVectorizer
# Sample text corpus
corpus = [
"The cat sat on the mat",
"The dog sat on the log",
"The bird flew over the mat",
"The cat chased the bird",
"The dog barked at the cat"
]
# Transform text data into a document-term matrix
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
# Define and fit the LDA model
lda = LatentDirichletAllocation(n_components=2, random_state=42)
lda.fit(X)
# Display the topics and their associated words
words = vectorizer.get_feature_names_out()
for index, topic in enumerate(lda.components_):
print(f"Topic {index}:")
print([words[i] for i in topic.argsort()[-5:]])
Output:
Topic 0: ['mat', 'on', 'sat', 'cat', 'the']
Topic 1: ['the', 'flew', 'over', 'bird', 'chased']
Applications of Topic Modeling
Discovering Hidden Themes in Text Data: Topic modeling is widely used in discovering underlying themes or topics within large collections of documents. For instance, in news articles, topic modeling can help categorize articles into topics such as politics, sports, or technology.
Text Summarization: By identifying the main topics within a document, topic modeling can aid in summarizing long documents by focusing on the key themes and removing irrelevant information.
Document Classification: Topic modeling can classify documents based on the topics they contain. This is useful in content management systems, where documents need to be organized by subject matter.
Recommender Systems: In recommendation systems, topic modeling can help match users with content that aligns with their interests by analyzing the topics of the content they engage with.
Information Retrieval: Topic modeling improves information retrieval systems by grouping documents based on their topics, making it easier to retrieve relevant documents when searching for specific themes or subjects.
Social Media Analysis: Topic modeling analyzes social media data and identifies trends, discussions, and emerging topics. This helps businesses and researchers understand public opinion and sentiment on various issues.
Sentiment Analysis
Sentiment analysis, also known as opinion mining, identifies and categorizes the emotional tone expressed in a text. This technique is commonly used in various fields, such as marketing, customer service, and social media analysis, to gauge public opinion, customer satisfaction, and brand perception.
Sentiment analysis is crucial for businesses and organizations as it provides insights into how people feel about their products, services, or content. Businesses can make data-driven decisions to improve their offerings, enhance customer experiences, and manage their brand reputation by analyzing sentiments in customer feedback, social media posts, and reviews.
There are three main techniques for sentiment analysis:
Rule-based Approaches: Rule-based sentiment analysis relies on a predefined set of rules and lexicons (dictionaries of positive and negative words) to classify text. For example, if a text contains more positive words like "great" or "excellent" than negative words like "bad" or "terrible," the sentiment is classified as positive. While simple and interpretable, rule-based methods can be limited in handling complex language and contextual nuances.
Machine Learning Approaches: To classify text, machine learning-based sentiment analysis uses algorithms like Naive Bayes, Support Vector Machines (SVM), or Logistic Regression. These models are trained on labeled datasets where each text is annotated with its corresponding sentiment. The model learns patterns in the data and can classify new, unseen text. Machine learning approaches offer more flexibility than rule-based methods and can handle a wider range of text, but they require labeled data for training.
Deep Learning Approaches: Deep learning-based sentiment analysis leverages neural networks, such as Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and Transformers, to capture complex patterns and contextual information in text. Without manual feature engineering, these models can automatically learn features from raw text data. Deep learning approaches are particularly effective in handling long and complex texts, making them suitable for sentiment analysis in social media, reviews, and customer feedback.
Sentiment Analysis with TextBlob
from textblob import TextBlob
# Sample text
text = "I love the new features in this product, but the battery life could be better."
# Create a TextBlob object
blob = TextBlob(text)
# Perform sentiment analysis
sentiment = blob.sentiment
print(f"Sentiment: {sentiment}")
Output: Sentiment: Sentiment(polarity=0.35, subjectivity=0.65)
Output: Sentiment: Sentiment(polarity=0.35, subjectivity=0.65)
Here, the polarity score indicates a mildly positive sentiment, while the subjectivity score suggests that the statement is somewhat opinion-based.
Applications of Sentiment Analysis
Analyzing Customer Feedback: Sentiment analysis is widely used to analyze customer feedback, such as reviews, surveys, and support tickets. By identifying positive and negative sentiments, businesses can address customer concerns, improve their products, and enhance customer satisfaction.
Social Media Sentiment: Social media platforms are rich sources of public opinion. Sentiment analysis helps organizations monitor social media sentiment to understand how their brand, products, or services are perceived by the public. This allows companies to engage with their audience and respond to trends in real time.
Market Research: Sentiment analysis is valuable in market research, where it is used to analyze consumer opinions, preferences, and attitudes toward different products, services, or brands. This helps businesses identify opportunities, optimize marketing strategies, and make informed decisions.
Political Analysis: In politics, sentiment analysis gauges public opinion on political candidates, policies, and events. Analysts can predict election outcomes and understand voter behavior by analyzing sentiments expressed in news articles, speeches, and social media posts.
Product Development: Sentiment analysis provides insights into how users feel about specific features or aspects of a product. This feedback can guide product development teams in prioritizing features, fixing issues, and delivering a better user experience.
Customer Service Automation: Sentiment analysis can be integrated into customer service chatbots and automated systems to detect negative sentiments in real time and escalate issues to human agents for faster resolution.
How Vector Databases Help with Natural Language Processing
Vector databases like Milvus and Zilliz Cloud (fully managed Milvus) can play a significant role in many natural language processing tasks. They are designed to efficiently store, index and search large volumes of high-dimensional data, particularly vector embeddings—numerical representations of words, sentences, or entire documents easier for machines to learn and understand.
Efficient Similarity Search
One of the key benefits of using vector databases in NLP is their ability to perform similarity searches. When dealing with tasks like finding similar documents, answering questions, or making recommendations, it’s important to retrieve results based on conceptual similarity rather than just exact keyword matches. Vector databases excel at this task by comparing the stored embeddings to find the closest matches, using distance metrics like cosine similarity. This capability is particularly valuable in semantic search applications, where understanding the context and meaning of a query is more important than simply matching words.
Capability to Handle Large-scale Vector Data
In addition to search capabilities, vector databases are designed to handle large-scale, high-dimensional data efficiently. For example, Milvus, a high-performance open-source vector database can even manage billion-scale vectors of tens of thousands of dimensionalities with just millisecond-level latencies. Modern NLP models like BERT or GPT generate embeddings that can have hundreds or even thousands of dimensions. Storing and querying these embeddings requires specialized systems that can manage such complexity. Vector databases not only store these embeddings but also provide tools for optimizing their storage through techniques like dimensionality reduction. This approach ensures that the meaningful relationships between different pieces of text are preserved while keeping the system scalable and responsive.
Seamless Integration with Machine Learning Models
Vector databases can also integrate with machine learning models (also called embedding models) used in NLP. They store the embeddings generated by these models and allow for quick retrieval during inference, which is the process of making predictions or decisions based on new data. This integration is essential for building NLP systems that can operate at scale, providing fast and accurate results in real-world applications. Milvus and Zilliz Cloud have integrated various machine learning models such as OpenAI’s text embedding models and Microsoft’s multilingual models, making vector embedding and similarity search much easier within the same system.
Retrieval Augmented Generation (RAG)
Vector databases are ideal for retrieval augmented generation (RAG) which is an advanced AI technique for mitigating hallucinations in large language models (LLMs) like ChatGPT. Vector databases serve as a long-term memory and additional knowledge base that stores and retrieves contextual information for the LLM to generate more accurate answers to user queries.
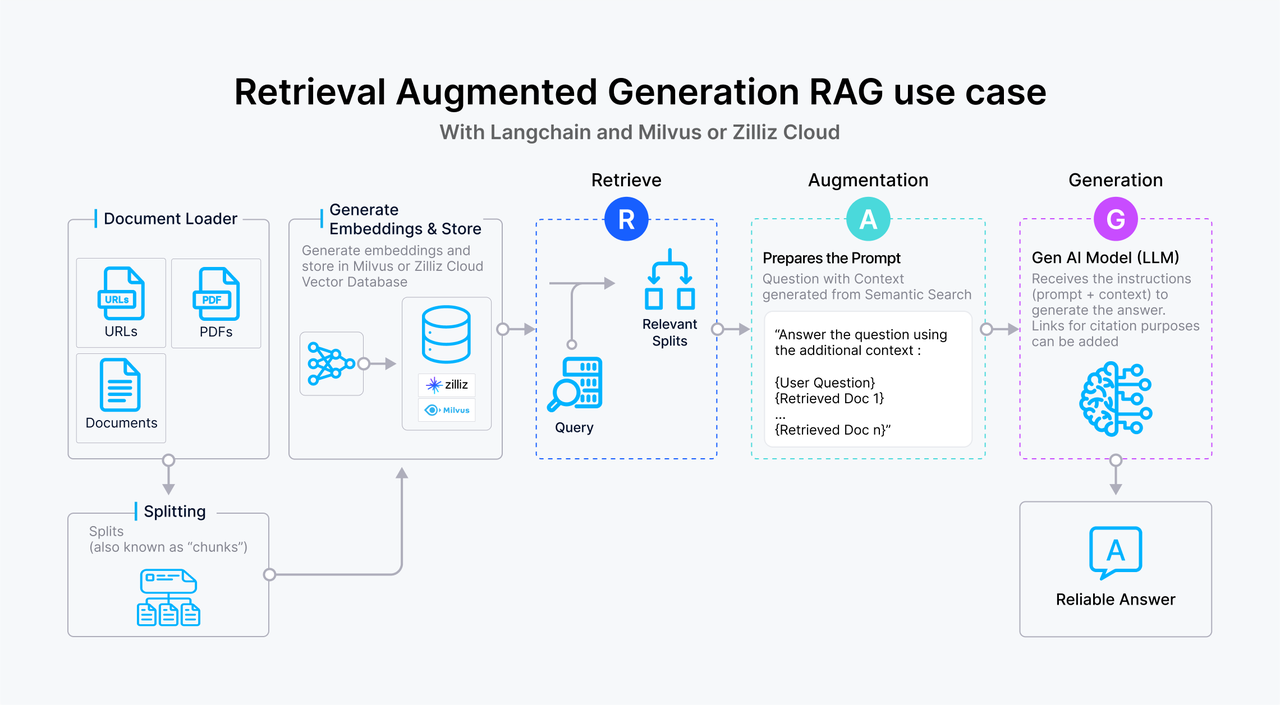 Figure 1- How RAG works
Figure 1- How RAG works
Check out this video to learn more about Milvus and vector databases.
Conclusion
In this article, we've covered the top 10 NLP techniques essential for working with text data. These methods are fundamental tools for any data scientist looking to analyze and understand language data effectively. As you continue to work with NLP, these techniques will help you extract meaningful insights and build more accurate models. We also covered how vector databases can help with various NLP tasks and building advanced RAG applications.
Don't stop here—there’s always more to learn and explore in the field of NLP. Discover top-10 NLP tools and platforms where built-in libraries in Python are used, and you can easily apply the techniques we have learned. We also recommend learning GenAI fundamentals and how to build GenAI Applications with various AI tools and vector databases.
Additional Resources
 Fariba Laiq
Fariba LaiqDescription: Fariba Laiq is a freelance content writer at Zilliz. She has studied Computer Science, been a coding instructor, and published research papers in the domain of AI and cyber-security. She is passionate about learning more about LLMs and vector databases in the ever evolving era of AI. Along with technical skills, she is also a self-taught artist.
- What is Natural Language Processing (NLP)?
- Overview of the Top 10 NLP Techniques
- Tokenization
- Stop Word Removal
- Stemming and Lemmatization
- Part-of-Speech (POS) Tagging
- Named Entity Recognition (NER)
- Bag of Words (BoW)
- TF-IDF (Term Frequency-Inverse Document Frequency)
- Word Embeddings
- Topic Modeling
- Sentiment Analysis
- How Vector Databases Help with Natural Language Processing
- Conclusion
- Additional Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

An Introduction to Natural Language Processing
Learn the intricacies of Natural Language Processing and how vector databases, like Zilliz Cloud, transform NLP with efficient embedding storage and retrieval.

Transforming Text: The Rise of Sentence Transformers in NLP
Everything you need to know about the Transformers model, exploring its architecture, implementation, and limitations

NLP and Vector Databases: Creating a Synergy for Advanced Processing
Finding photos, recommending products, or enabling facial recognition, the power of vector databases lies in their ability to make sense of the complexity of the world around us.