




Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
Knowledge distillation is a machine learning technique in which the knowledge of a large, complex model (teacher) is transferred to a smaller, simpler model (student).
Read the entire series
- OpenAI's ChatGPT
- Unlocking the Secrets of GPT-4.0 and Large Language Models
- Top LLMs of 2024: Only the Worthy
- Large Language Models and Search
- Introduction to the Falcon 180B Large Language Model (LLM)
- OpenAI Whisper: Transforming Speech-to-Text with Advanced AI
- Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
- What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
- LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
- Mastering Cohere's Reranker for Enhanced AI Performance
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
- Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
- RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
- Prover-Verifier Games Improve Legibility of LLM Outputs
- Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
- Unlocking the Power of Many-Shot In-Context Learning in LLMs
- Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
- Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
- Everything You Need to Know About LLM Guardrails
- Chain-of-Retrieval Augmented Generation
- Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
Large language models (LLMs) like GPT-4, Gemini, and Claude have stood out as groundbreaking technologies in the rapidly evolving field of AI. They can generate human-like text and solve complex problems, showcasing emergent abilities beyond their original training objectives.
Despite their impressive abilities, proprietary LLMs like GPT-4 have limitations, including restricted accessibility, high costs, and data privacy and security concerns. Open-source models like LLaMA and Mistral give advantages over proprietary LLMs in accessibility and adaptability but can suffer from smaller model scales and lower performance.
Knowledge Distillation (KD) is an important technique for bridging this gap. Through distillation techniques, the gap between proprietary LLMs and open-source models is greatly reduced and even filled. Knowledge distillation is important for improving the capabilities of LLMs, model compression, and self-improvement. Additionally, it helps models act as their own teachers for self-improvement.
In this article, we will discuss the significance of knowledge distillation within the context of large language models (LLMs), the need for knowledge distillation, evolving knowledge distillation techniques, their detailed descriptions, and their applications.
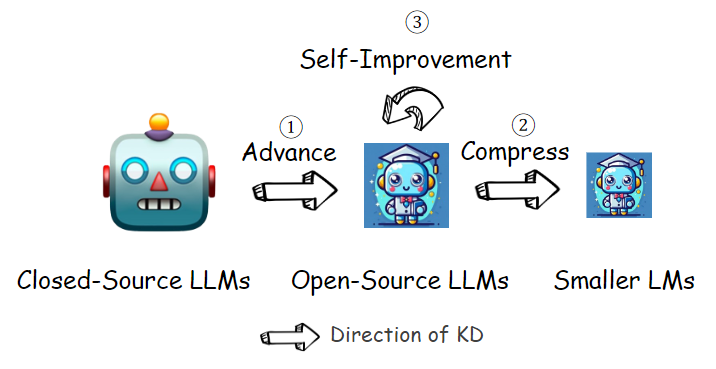 Self-improvement via Knowledge Distillation
Self-improvement via Knowledge Distillation
Figure: Self-improvement via Knowledge Distillation | Source
If you want to explore this topic further, here is the paper: A Survey on Knowledge Distillation of LLMs.
What is Knowledge Distillation (KD)?
Knowledge distillation is a technique where a smaller, simpler "student" model is trained to mimic the behavior of a larger, more complex "teacher" model. Teacher models are trained on a large amount of data and possess a deeper understanding of the task. The goal is to transfer this expertise to the student model, which is optimized to run faster and more efficiently on resource-constrained devices.
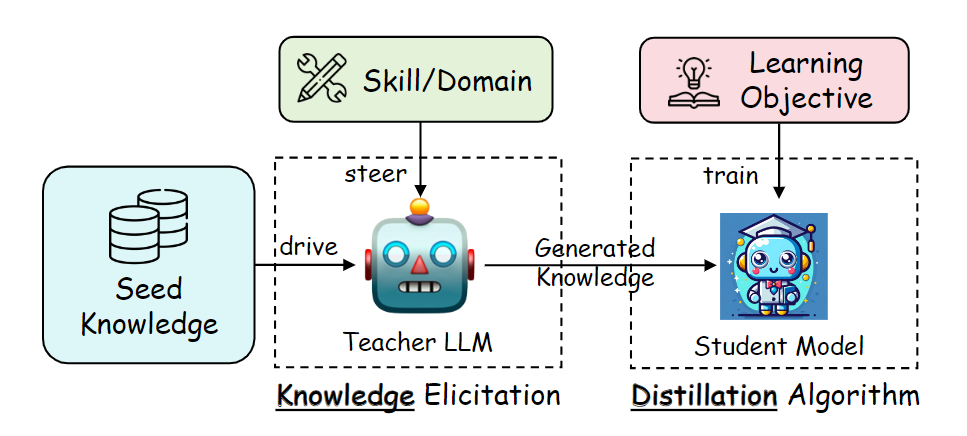 Knowledge distillation from a large teacher model to a student model
Knowledge distillation from a large teacher model to a student model
Figure: Knowledge distillation from a large teacher model to a student model | Source
Data Augmentation (DA) in Knowledge Distillation
Data Augmentation (DA) is essential in improving the effectiveness of Knowledge Distillation. It uses the teacher LLM’s ability to generate new data, expanding the training dataset for the student model. This is important when dealing with specialized domains or skills with limited labeled data. Here’s how data augmentation works in knowledge distillation:
Seed Knowledge: The teacher LLM is provided with a small set of initial data, such as instructions, demonstrations, or specific domain knowledge.
Prompt Engineering: Carefully designed prompts guide the teacher LLM in generating new data relevant to the target skill or domain.
Data Generation: The teacher LLM generates new data samples, such as question-answer pairs, explanations, or code, based on the seed knowledge and prompts.
Data Filtering and Evaluation: The generated data is then reviewed and filtered to ensure it is high-quality and relevant before training the student model.
KD enables smaller models to acquire advanced capabilities that would otherwise require significantly more training data and computational resources by generating large-scale, high-quality datasets.
Methodologies Driving Knowledge Distillation for LLMs
Knowledge Distillation (KD) for Large Language Models (LLMs) is multifaceted, emphasizing the interplay between algorithms, skill enhancement, and domain specialization. Let's break down each aspect and methodologies involved:
KD Algorithms
Skill Distillation
Verticalization Distillation
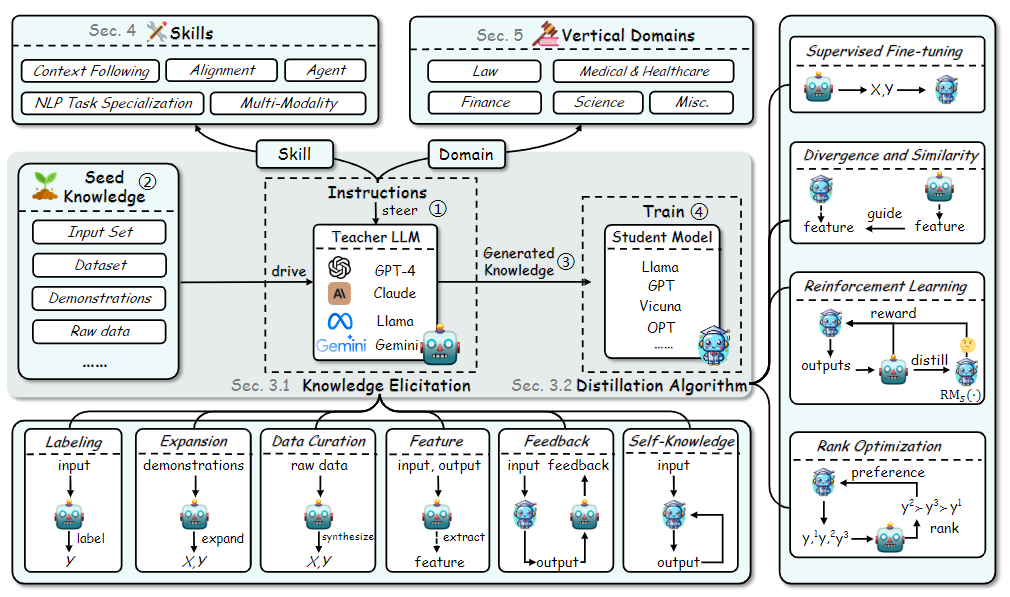 A multifaceted overview of knowledge distillation of LLMs
A multifaceted overview of knowledge distillation of LLMs
Figure: A multifaceted overview of knowledge distillation of LLMs | Source
KD Algorithms: The Foundation for Knowledge Transfer
Knowledge distillation algorithms provide the technical mechanisms for transferring knowledge. The objective is to improve the student's capabilities without requiring the same extensive training data and computational resources as the teacher. This process is categorized into two primary steps:
Knowledge Elicitation
Distillation Algorithms
 Taxonomy of KD algorithms.png
Taxonomy of KD algorithms.png
Figure: Taxonomy of KD algorithms | Source
Knowledge elicitation
Knowledge elicitation in the context of LLMs is extracting valuable knowledge from the teacher, often a proprietary LLM like the GPT-4 model. Unlike traditional knowledge distillation, in which model architectures compress to reduce the size and computational load, this process focuses on the selective transfer of rich and diverse knowledge.
Knowledge elicitation can be done in various ways, including Labeling, Expansion, Data Curation, Feature, Feedback, and Self-knowledge.
Labeling
The teacher LLM generates labels or outputs y for a given input x. This labeled data serves as the training data for the student model. For example, the teacher LLM could be prompted to categorize text for a natural language understanding task or generate summaries for a text summarization task. The labeling process can be defined as follows:
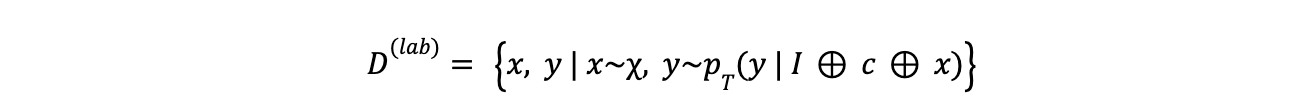 equation - labeling
equation - labeling
Here,
x Is the input data point
y represents output or label
represents the probability distribution of the teacher model
Expansion
The Expansion technique uses LLMs' in-context learning abilities to generate new input-output pairs (x, y) similar to a provided set of demonstrations (c) or instructions. The expansion process can be described as:
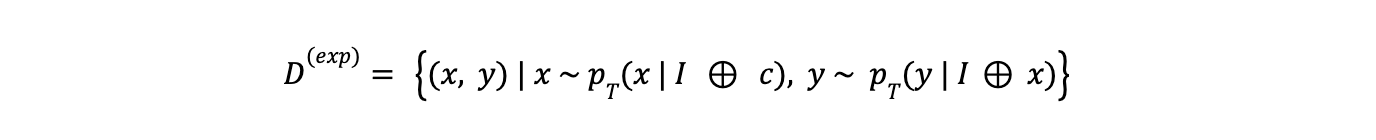 equation - expansion
equation - expansion
Data Curation
Data curation addresses the quality and quantity constraints of Labeling and Expansion by using extensive meta-information as seed knowledge to curate high-quality and large-scale data. For example, in developing the "phi-1" model, random topics or function names were used as meta-information to assist the teacher LLM in creating a dataset of Python textbooks and exercises. The process of data curation can be represented as:
 equation - data curation.png
equation - data curation.png
Feature
Feature knowledge elicitation uses the internal representations of teacher LLMs, such as output distributions, intermediate features, or activations. This gives the student model an understanding of the teacher's decision-making process. The technique for eliciting feature knowledge can be outlined as follows:
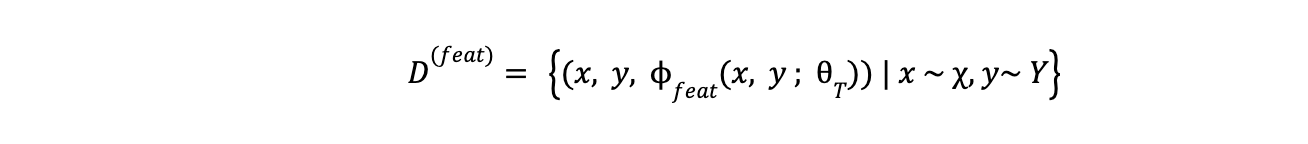 equation - feature
equation - feature
Feedback
The teacher LLM gives feedback on the student model's outputs, guiding its learning process. This feedback can take various forms, such as corrections, preferences, or assessments. A generalized formulation for eliciting feedback knowledge is as follows:
 equation - feedback
equation - feedback
Self-Knowledge
Self-knowledge elicitation is a method where the student model takes on both the roles of teacher and student. It generates outputs and then evaluates them, filtering for high-quality responses. The model learns and improves over time by distilling and refining its own previously generated outputs. The process of eliciting self-knowledge can be defined as:
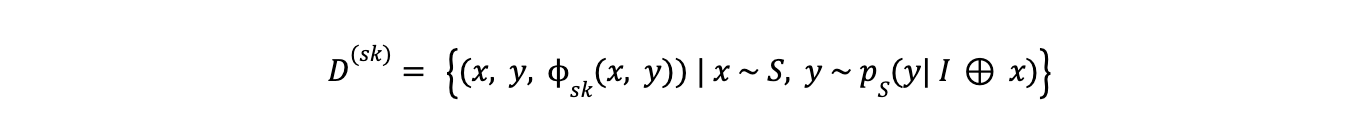 equation - self-knowledge
equation - self-knowledge
 Different knowledge elicitation methods from teacher LLMs.png
Different knowledge elicitation methods from teacher LLMs.png
Figure: Different knowledge elicitation methods from teacher LLMs | Source
Distillation Algorithms
Once knowledge is extracted from the teacher's LLM, various distillation algorithms are used to transfer this knowledge to the student's LLM. The choice of algorithm depends on factors such as the type of knowledge being distilled, the architecture of the student model, and the available resources.
Supervised Fine-Tuning (SFT)
Supervised Fine-Tuning (SFT) is the simplest and most widely used distillation method. In this method, the student model is trained on the labeled data generated by the teacher LLM. The objective is to replicate the output behavior directly. This method is usually used with the "Labeling" or "Expansion" knowledge elicitation methods. The process of SFT can be mathematically formulated as follows:
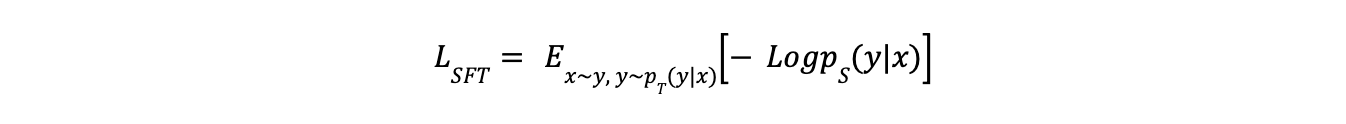 Equation - Supervised Fine-Tuning (SFT)
Equation - Supervised Fine-Tuning (SFT)
Here,
- Is the negative log-likelihood of the student model generating the output (y) given the input (x)
Divergence and Similarity
Divergence and Similarity methods aim to minimize the difference (divergence) between the probability distributions of the teacher and student model outputs or maximize the similarity of their internal representations (hidden states). Divergence-based methods, such as minimizing the Kullback-Leibler divergence, encourage the student model to cover all the modes of the teacher's distribution.
 Various divergence types
Various divergence types
Figure: Various divergence types | Source
Similarity-based algorithms align the internal representations or hidden states of the teacher and student models. This approach trains the student model to mirror the teacher model's internal structures, ensuring a closer resemblance in how both models process information.
 Similarity functions in knowledge distillation
Similarity functions in knowledge distillation
Figure: Similarity functions in knowledge distillation | Source
Reinforcement Learning (RL)
Reinforcement Learning (RL) algorithm works based on feedback from the teacher LLM to train the student model through a reward-based system.
- A reward model is first trained using the feedback provided by the teacher LLM. This reward model learns to assess the quality of the student's outputs based on the teacher's preferences. The loss function for the reward model is defined as:
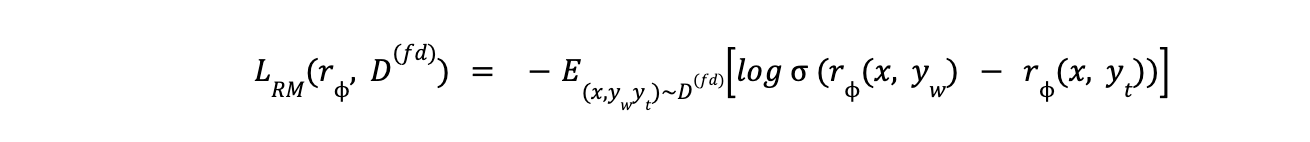 equation - Reinforcement Learning (RL)
equation - Reinforcement Learning (RL)
- The student model is then trained using reinforcement learning algorithms to maximize the reward it receives from the reward model. The student model learns to generate outputs that the teacher LLM will likely find favorable. The RL objective is given by:
 equation - Reinforcement Learning (RL) 2
equation - Reinforcement Learning (RL) 2
Rank Optimization
The student model learns to rank outputs in the same order the teacher LLM would rank them. For example, in text generation tasks, the teacher LLM could rank different possible outputs, and the student model would be trained to predict this ranking, learning the teacher's subjective preferences. The ranking process is defined as follows:
![]() equation - Rank Optimization
equation - Rank Optimization
Skill Distillation: Targeting Specific Capabilities
Knowledge Distillation is not limited to simply replicating the teacher LLM's overall behavior. It goes beyond examining how these algorithms can be applied to enhance specific skills or competencies in student LLMs. Skill Distillation (SD)has numerous examples across different skill categories.
 Skill distillation
Skill distillation
Figure: Skill distillation | Source
Context Following
This process trains student LLMs to understand and respond to a variety of contexts, including:
Instructions: This focuses on training the model to follow specific commands or guidelines provided in the input and perform tasks in a more controlled manner.
Multi-turn Dialogue: This extends the context to ongoing conversations, helping the student model to maintain coherence and relevance across multiple turns in a dialogue.
Retrieval-Augmented Generation (RAG): This integrates external information sources and model access and incorporates relevant data from databases or documents to improve its responses.
Alignment
Alignment refines the student LLM's outputs better to match human preferences, values, and intentions. Its element, thinking patterns, emphasizes training students to adopt the teacher's reasoning processes, such as generating step-by-step explanations or evaluating multiple perspectives before concluding.
Another important element is Persona and Preference Modeling. The student learns to mirror the teacher's persona or style differences to ensure consistent responses that meet a specific personality or brand voice.
Agent
SD helps develop LLM agents capable of interacting with the external world and completing more complex tasks. LLM agents can use external tools like calculators, calendars, or databases to enhance their functionality and problem-solving capabilities.
NLP Task Specialization
Student models can be adapted to excel in specific natural language processing tasks, including:
Natural Language Understanding (NLU): KD can improve the student model's ability to accurately understand and interpret human language, which can be used in tasks such as text classification, sentiment analysis, and information extraction.
Natural Language Generation (NLG): NLG includes text summarization, machine translation, and dialogue generation tasks. KD can help student models generate more fluent, coherent, and informative text.
Recommendation Systems: KD can help student models learn to make more accurate and relevant recommendations.
Code Generation: This involves generating computer code from natural language descriptions. KD trains student models to generate correct, efficient, and readable code.
Using the distilled knowledge from large language models (LLMs), student models can more effectively navigate diverse NLP challenges, enhancing their performance and addressing data limitations.
Multi-Modality
Extending KD techniques to multi-modal LLMs that handle not just text but also process and generate content in multiple modalities, such as images. KD transfers image-text knowledge from teacher LLMs to student models in the vision-language domain. These student models can understand and generate both text and translate images into textual descriptions.
Verticalization: Domain-Specific Distillation
 Taxonomy of verticalization distillation.png
Taxonomy of verticalization distillation.png
Figure: Taxonomy of verticalization distillation | Source
Knowledge Distillation (KD) is crucial in customizing the LLMs for particular domains to perform specialized tasks with greater accuracy and efficiency. Key domains include.
Law
KD is used to develop LLMs who can understand legal documents, reason about legal issues, and provide legal assistance. These models were trained on extensive legal corpora and were fine-tuned for specific legal tasks, such as contract analysis or legal research. Here are some examples of LLMs used in the law domain:
LawyerLLaMA: This Chinese legal language model was built upon the LLaMA framework. It was first pre-trained on a large legal corpus and then fine-tuned using objective questions from the Chinese National Judicial Examination dataset and responses to legal consultations generated by ChatGPT.
LawGPT: This model, based on OpenLLaMA, was trained using a dataset composed of real-world legal text, regulations, judicial interpretations, and legal consultation data. ChatGPT was used to generate additional data for training.
Medical & Healthcare
KD is applied to create LLMs that can process medical records, answer health-related questions, and generate personalized treatment plans. Some LLMs examples included:
HuatuoGPT: This model, designed for medical consultations, uses data distilled from ChatGPT and real-world data from doctors during the supervised fine-tuning stage.
DoctorGLM: This Chinese medical dialogue model was trained on a dataset constructed with assistance from ChatGPT and uses a variety of techniques for diagnoses, drug recommendations, and medical advice.
Finance
LLMs are trained with KD using financial news, market data, and company filings to analyze financial information, assess risks, and make informed financial decisions. These models assist with tasks like investment analysis and risk management. Here are examples of knowledge distillation (KD) in building large language models (LLMs):
- XuanYuan: This finance-focused LLM uses self-instruct techniques applied to seed data and self-QA methods on structured and unstructured data to generate instruction data for training.
Science
KD plays a transformative role in scientific research, enabling the creation of LLMs that can:
Read and understand vast amounts of scientific literature, identifying key findings and trends.
Generate new hypotheses based on existing scientific knowledge.
Assist with writing, generating initial drafts, and suggesting improvements to scientific papers.
Science domain LLMs included:
SciGLM: This scientific LLM prompts a teacher LLM to generate detailed answers for unlabeled scientific questions and employs a self-reflective critic-and-revise process to improve data quality.
AstroLLaMA-Chat: Built upon the 7B-parameter LLaMA-2 model and focuses on astronomy. It uses continual pre-training on a curated astronomy corpus to improve its performance in question-answering tasks related to astronomy.
Knowledge distillation (KD) extends beyond traditional domains into education, aiding teaching, learning, and assessment. It's also used in creating language models that automate IT tasks and support IT professionals. KD methods enhance the transfer of complex skills and knowledge, leading to more versatile AI solutions. However, challenges like data selection, catastrophic forgetting, and ensuring the reliability of distilled knowledge still need to be addressed.
Impact and Implications of Knowledge Distillation for LLMs
Transferring knowledge from large models to smaller models is vital for bridging the gap and making state-of-the-art AI capabilities more accessible. This process not only improves accessibility but also enhances efficiency and sustainability in AI development.
Sustainability: KD contributes to AI's environmental sustainability by enabling smaller, more efficient models that require less computational power.
Model Compression and Efficiency: KD enables the development of smaller, efficient LLMs with minimal performance loss, essential for AI deployment in resource-limited environments like mobile devices.
Data Efficiency and Quality: New data selection and augmentation methods like Superfiltering and self-instruct improve distillation, reducing data needs while improving model performance.
Broader Task Coverage: KD enhances generalizability across tasks by using diverse instruction data. Models like WaveCoder and MFTCoder show how KD improves multi-task learning, excelling in specialized areas like code generation.
Advancements in Multi-Modality: Innovative LLMs like LLaVA and MIMIC-IT showcase knowledge distillation's role in linking language, vision, and audio, enhancing applications like image-based instruction tuning and multimodal conversational agents.
Conclusions and Future Work
Knowledge distillation is a technique that helps smaller language models adopt the strengths of larger ones. AI solutions become more accessible, efficient, and reliable by using methods like data augmentation, knowledge elicitation, and efficient distillation algorithms. As AI technology advances, there will be a growing need for more advanced KD methods. Future research could explore several areas, including:
Advancing Data Selection and Filtering Techniques: As the volume of LLM training data grows, efficient data selection for knowledge distillation (KD) is essential. Research should focus on automatically identifying valuable data for distillation into smaller models.
Mitigating Catastrophic Forgetting: Continued fine-tuning of LLMs on specific tasks or domains can lead to catastrophic forgetting of previously learned knowledge. Future research needs to explore methods to overcome this challenge.
Exploiting Richer Knowledge from Teacher LLMs: Existing KD methods use teacher LLM outputs as labels for training smaller models. Future research should explore ways to use richer knowledge from teachers.
Advancing Weak-to-Strong Distillation: Explore techniques to enable the distillation of knowledge from weaker or less accurate teacher models to stronger student models.
Further Resources
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- What is Knowledge Distillation (KD)?
- Data Augmentation (DA) in Knowledge Distillation
- Methodologies Driving Knowledge Distillation for LLMs
- Impact and Implications of Knowledge Distillation for LLMs
- Conclusions and Future Work
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Large Language Models and Search
Explore the integration of Large Language Models (LLMs) and search technologies, featuring real-world applications and advancements facilitated by Zilliz and Milvus.
Efficient Memory Management for Large Language Model Serving with PagedAttention
PagedAttention and vLLM solve important challenges in serving LLMs, particularly the high costs and inefficiencies in GPU memory usage when using it for inference.

Chain-of-Retrieval Augmented Generation
Explore CoRAG, a novel retrieval-augmented generation method that refines queries iteratively to improve multi-hop reasoning and factual answers.