




Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
This blog will discuss the growing need to detect machine-generated text, past detection methods, and a new approach: Binoculars.
Read the entire series
- OpenAI's ChatGPT
- Unlocking the Secrets of GPT-4.0 and Large Language Models
- Top LLMs of 2024: Only the Worthy
- Large Language Models and Search
- Introduction to the Falcon 180B Large Language Model (LLM)
- OpenAI Whisper: Transforming Speech-to-Text with Advanced AI
- Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
- What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
- LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
- Mastering Cohere's Reranker for Enhanced AI Performance
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
- Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
- RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
- Prover-Verifier Games Improve Legibility of LLM Outputs
- Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
- Unlocking the Power of Many-Shot In-Context Learning in LLMs
- Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
- Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
- Everything You Need to Know About LLM Guardrails
- Chain-of-Retrieval Augmented Generation
- Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
The advancement of large language models (LLMs) has made distinguishing between human-written and machine-generated text tricky. As these models produce more human-like outputs, traditional detection methods, once effective for earlier models, have become obsolete. Many approaches, particularly those tailored to ChatGPT, rely heavily on training data and struggle to generalize across different models and domains.
A new detection method called Binoculars was developed to address the limitations of existing methods. It introduces a novel approach using a ratio of perplexity to cross-perplexity to detect machine-generated text without any model-specific training. The approach can accurately detect text from multiple LLMs, not just ChatGPT.
Binoculars achieve state-of-the-art accuracy in zero-shot detection. They outperform existing open-source methods and compete with or surpass commercial APIs. They have high true positive rates (TPR) and very low false positive rates (FPR). Additionally, Binoculars overcome common challenges, such as prompt dependency. They also maintain robustness against stylistic variations and adversarial text modifications by using a ratio of perplexity to cross-perplexity.
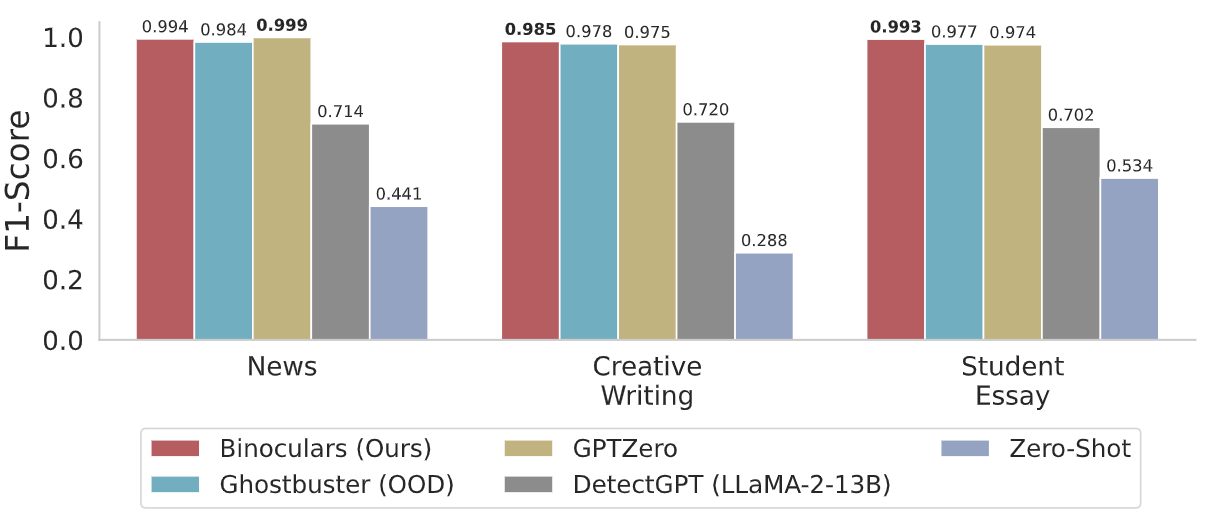 Figure: Detection of ChatGPT-generated text across several detectors
Figure: Detection of ChatGPT-generated text across several detectors
Figure: Detection of ChatGPT-generated text across several detectors | Source
This blog will discuss the growing need to detect machine-generated text, past detection methods, and a new approach: Binoculars. We will also discuss how Binoculars work and their robustness and reliability in diverse scenarios. For a comprehensive understanding, please refer to this binocular paper.
Why Detection Methods Are Critical
As large language models (LLMs) become more advanced and widely accessible, their potential benefits are accompanied by significant risks when misused. Reliable detection methods are crucial to address these challenges. For example:
Academic Integrity Challenges: The use of LLMs for plagiarism or unauthorized assistance in academic work has raised ethical concerns. Effective detection can protect the credibility of educational institutions.
Misinformation and Malicious Use: The widespread availability of LLMs has enabled malicious actors to create bots, generate fake reviews, and spread misinformation on social media. Such misuse can erode public trust and harm digital ecosystems without reliable detection.
Bias and Ethical Concerns: Detection methods help spot and reduce biased or harmful outputs from LLMs. This can contribute to more ethical AI deployments.
The Problem with Traditional LLM Detection
Traditional LLM detection methods have a primary issue. They rely on statistical signatures or training data specific to particular language models. This makes them ineffective in a zero-shot setting. Key challenges include:
Model-Specific Training: Many traditional detectors are trained on data from specific language models like ChatGPT. This means they struggle to identify text from other LLMs they haven't been trained on. This lack of adaptability is a significant limitation as the number of LLMs increases.
Lack of Generalization: Traditional approaches often fail to generalize across different text domains and languages. Detectors trained on a specific type of text, like essays, might perform poorly on other text types. For example, they may struggle with news articles or text in different languages.
False Positives: Traditional methods can result in high false positive rates. They often incorrectly label human text as machine-generated, especially when non-native English speakers write it. This mislabeling happens more frequently when the text comes from out-of-domain sources.
Inability to Adapt to New Models: Existing methods often fail to adapt to new models because they depend on model-specific training data.
The Binoculars method overcomes these limitations using a zero-shot approach that doesn't require training data from the target LLM. Let's explore how it works.
How Binoculars Works: A Two-Lens Approach
The Binoculars method uses a two-model mechanism to analyze text, contrasting an "observer" LLM and a "performer" LLM. It calculates a detection score by comparing perplexity (how surprising the text is to a model) and cross-perplexity (how surprising one model's predictions are to another). This mechanism helps Binoculars identify machine-generated content, even without specific training data from the source model.
Here's a step-by-step breakdown of how Binoculars works:
Tokenization
Tokenization is the process of breaking a string of characters into tokens. A given string of characters 𝑠 is first converted into tokens. These tokens are represented as a list of indices x, where each index xi corresponds to a specific entry in the language model's vocabulary 𝑉. The vocabulary 𝑉 is a predefined set of integers ranging from 1 to 𝑛, mapping tokens to numerical representations used by the model.
Perplexity Calculation
First, the method computes the log-perplexity (log-PPL) of the input string 𝑠 using an "observer" LLM, denoted as M1. It measures how "surprising" a given test is to a language model.
Higher perplexity indicates the text is less predictable or more surprising for the model, which is often a sign of human authorship.
Lower perplexity indicates the model is more confident about the text and associated with machine-generated content.
However, perplexity alone is insufficient due to the influence of prompts. Mathematically, log perplexity (log PPL) is defined as the average negative log-likelihood of all tokens in the given sequence:
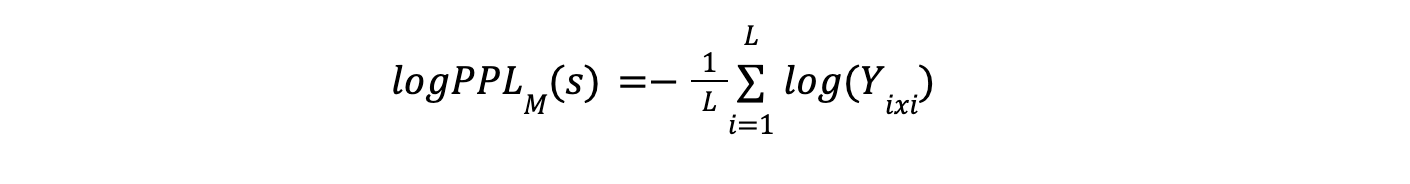
Where:
- L is the number of tokens in 𝑠.
- Y =M1(x)=M1(T(s)) is the probability distribution over the vocabulary predicted by the model M1for the token sequence.
Cross-Perplexity Calculation
Next, the method calculates the cross-perplexity (X-PPL), which includes using a "performer" LLM M2 to generate next-token predictions for the same text. Then, the perplexity of those predictions is computed according to the "observer" LLM M1. This is the average per-token cross-entropy between the outputs of M1and M2 when operating on the tokenization of s. The cross-perplexity is mathematically defined as:
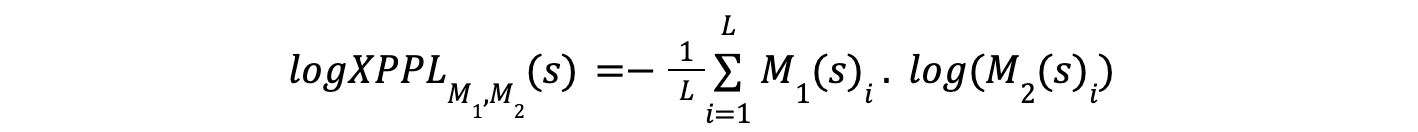
Binoculars Score
The core of the Binoculars method is the Binoculars score, which is the ratio of the log perplexity to the log cross-perplexity. This score is calculated as:
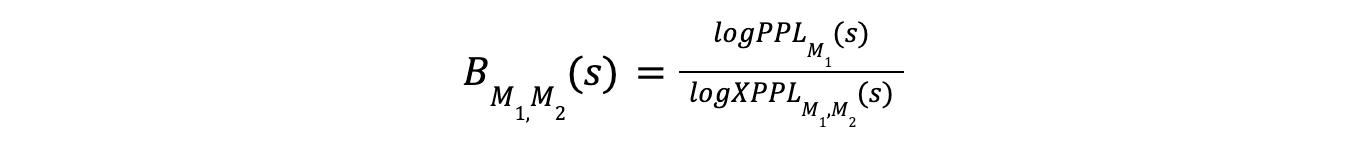
Where:
The numerator logPPLM(s) measures how surprising the string is to the observer model.
The denominator logXPPLM1,M2(s) measures how surprising the token predictions of the performer model M2 are when observed M1.
The ratio provides a normalized measure. It is more effective at distinguishing between human-generated and machine-generated text than either perplexity or cross-perplexity alone.
Addressing the "Capybara Problem"
The use of cross-perplexity in the denominator of the Binoculars score acts as a normalizing factor to help address the "capybara problem." This problem refers to the fact that prompts can greatly influence perplexity. A prompt can cause a machine to generate text that is surprisingly complex, leading to a high perplexity score that might be mistaken for human-written text.
Detection
Binoculars determine whether the tokens in a string are surprising by looking at the ratio of perplexity to cross-perplexity. This determination is made relative to the expected baseline perplexity of an LLM acting on the same string.
The method is based on the idea that human-generated text is more likely to diverge from the observer model's expectations. In contrast, the performer model's predictions would be more aligned, considering that the two LLMs are more similar to each other than either is to a human. A lower Binoculars score indicates a higher likelihood of the text being machine-generated, while a higher score indicates it is likely human-written.
Experimental Setup: Data, Baselines, and Evaluation Metrics
We will examine the performance of Binoculars in various scenarios. First, let's review the key details regarding how the Binoculars were tested and evaluated. This includes the datasets used, the process for adjusting the detection threshold, and the selection of baseline methods for comparison.
Dataset Generation: To evaluate the Binoculars' ability to detect machine-generated text, datasets were created using human-written samples sourced from CC News, CNN, and PubMed.
The first 50 tokens of each human sample were used as a prompt. This prompt generated up to 512 tokens of machine-generated text using LLaMA-2-13B and Falcon-7B.
The original human prompts were then removed, and only the machine-generated text was used in the datasets.
Out-of-Domain Threshold Tuning: The detectors were evaluated based on their True Positive Rate (TPR) while maintaining an extremely low False Positive Rate (FPR), specifically at 0.01%.
A threshold was determined by combining training splits from several reference datasets. This threshold helps classify text as either machine-generated or human-written. All reference datasets were generated using ChatGPT.
The threshold was optimized using accuracy across all the chosen datasets. A fixed global threshold was used to separate machine and human text. Unless stated otherwise, each document was evaluated using a prefix of 512 tokens.
Baseline Details: The baseline methods were chosen based on their applicability in post-hoc, out-of-domain (zero-shot), and black-box detection scenarios.
The selected baselines include Ghostbuster, the commercially deployed GPTZero, DetectGPT, Fast-DetectGPT, and DNA-GPT.
The "out-of-domain" version of all baselines was used for a fair comparison with Binoculars.
For DetectGPT, the LLaMA-2-13B model was used for scoring, and the T5 model was used for mask filling, even if the dataset was generated using LLaMA-2-13B.
For Fast-DetectGPT, GPT-J-6B and GPT-Neo-2.7B were used as reference and scoring models.
For DNA-GPT, the gpt-3.5-turbo-instruct API was used for suffix prediction.
Primary Evaluation Metrics for Binoculars
The performance of the Binoculars method as a detector of machine-generated text is assessed using several key metrics:
True Positive Rate (TPR) at a low False Positive Rate (FPR): This metric is important because it measures how well the detector identifies machine-generated text. It also minimizes the chances of incorrectly labeling human text as machine-generated. The evaluation focuses explicitly on TPR at low FPR (e.g., 0.01%).
Precision and Recall: These metrics evaluate the detector's performance in multilingual settings, especially for low-resource languages. Precision refers to the proportion of correctly identified machine-generated texts out of all texts labeled as machine-generated, while recall measures the proportion of correctly identified machine-generated texts out of all actual machine-generated texts.
F1-Score: The F1-Score is used to assess the model's performance using an out-of-domain threshold. It provides a single value that balances identifying as many machine-generated texts as possible (recall) while ensuring those identified are mostly correct (precision).
Binoculars' Detection Performance Across Diverse Scenarios
The Binoculars method as a zero-shot LLM detector was evaluated across multiple domains and scenarios. The evaluation aims to show the accuracy and reliability of Binoculars, especially when compared to existing detection methods.
Binoculars Benchmark Performance on ChatGPT Detection
The Binoculars method is evaluated using datasets that include news articles, creative writing samples, and student essays. These datasets are balanced with an equal number of human-written and machine-generated samples created by ChatGPT. Binoculars show high accuracy in separating machine-generated and human-written text. They achieve a true positive rate (TPR) of over 90% and a false positive rate (FPR) of only 0.01%. This performance is achieved without any training on ChatGPT data, showing its zero-shot capability.
Binoculars outperform both commercial systems like GPTZero and open-source detectors, including Ghostbuster, DetectGPT, Fast-DetectGPT, and DNA-GPT. Some of these baseline detectors are even specifically tuned to detect ChatGPT outputs.
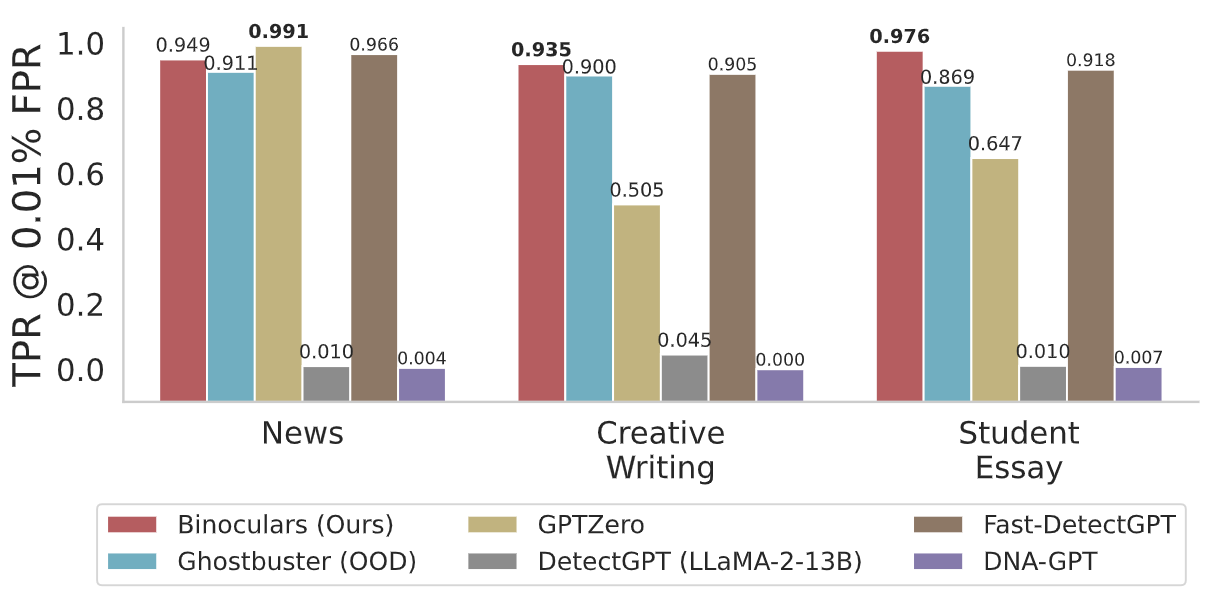 Figure: Detection of machine-generated text from ChatGPT
Figure: Detection of machine-generated text from ChatGPT
Figure: Detection of machine-generated text from ChatGPT | Source
Additionally, the detection performance of Binoculars improves with more information, demonstrating its capability to detect with a low number of tokens.
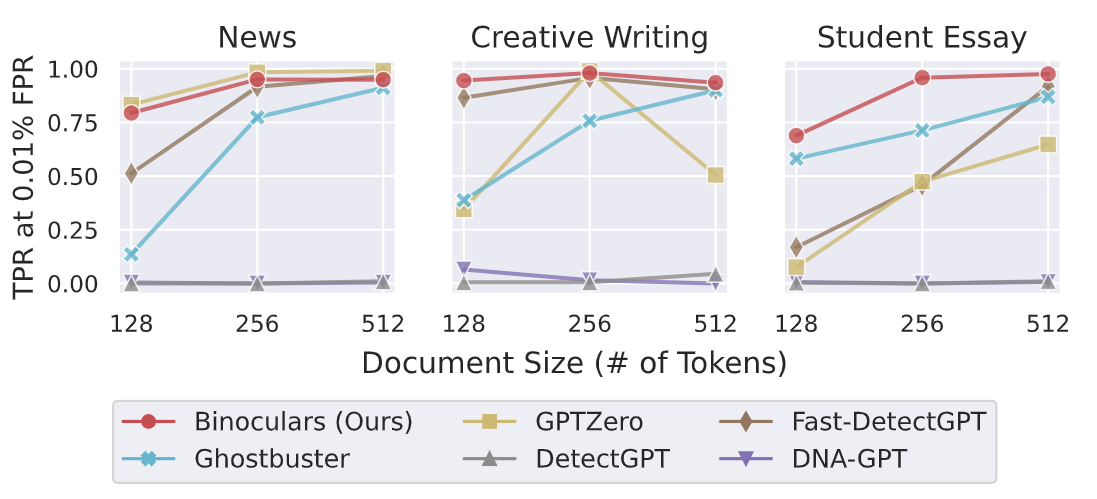 Figure: Impact of document size on detection performance
Figure: Impact of document size on detection performance
Figure: Impact of document size on detection performance | Source
Detection of Various LLMs (Beyond ChatGPT)
Binoculars extend their detection capabilities beyond ChatGPT to other LLMs, such as LLaMA-2 and Falcon. Binoculars maintain their accuracy in detecting text generated by these models without requiring model-specific modifications.
In contrast, other detectors, such as Ghostbuster, which is tuned for ChatGPT, struggle to reliably detect text from other LLMs like LLaMA-2. Binoculars achieve higher TPRs for low FPRs than other methods when detecting LLaMA-2 generations.
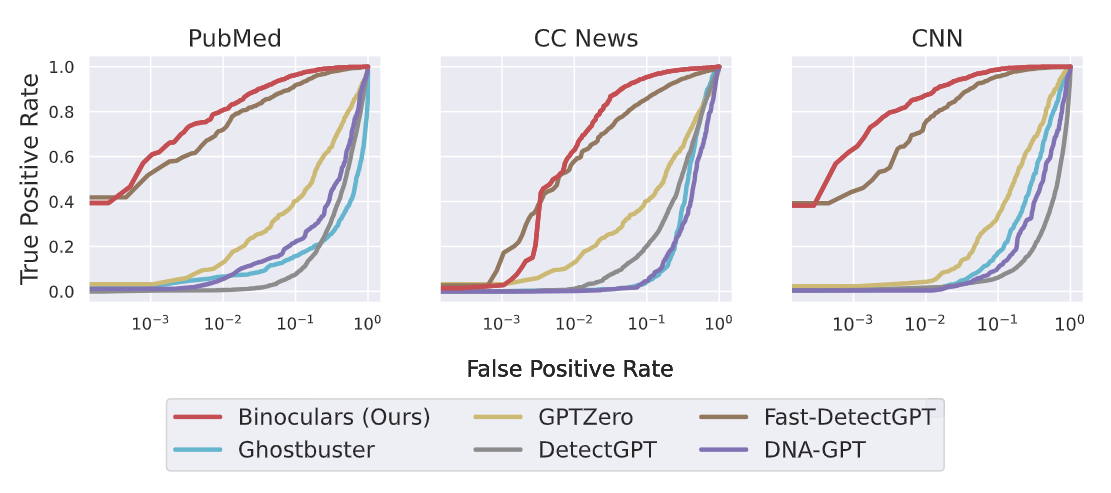 Figure: Detecting LLaMA-2-13B generations
Figure: Detecting LLaMA-2-13B generations
Figure: Detecting LLaMA-2-13B generations | Source
Binoculars in the Wild: Reliability and Robustness
The reliability of Binoculars was evaluated across diverse text sources, including different languages and domains. Binoculars can effectively generalize across domains using the Multi-generator, Multi-domain, and Multi-lingual (M4) datasets. These domains include Arxiv, Reddit, Wikihow, and Wikipedia. They also perform well in various languages, including Urdu, Russian, Bulgarian, and Arabic.
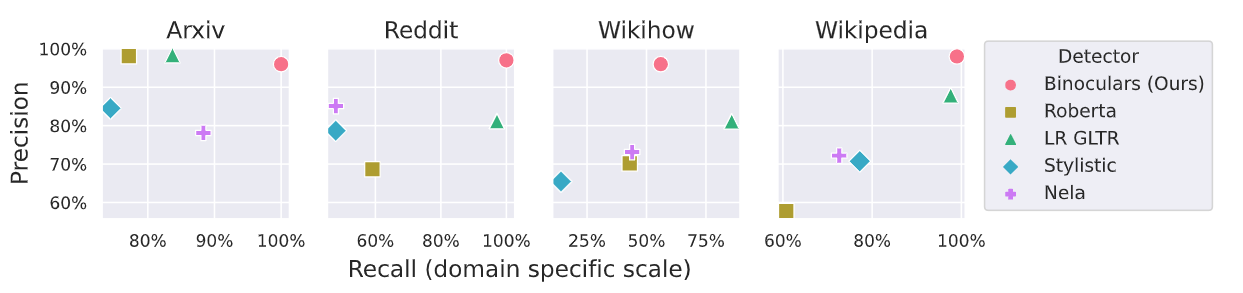 Figure: Detection of ChatGPT generated text in various domains from M4 Dataset
Figure: Detection of ChatGPT generated text in various domains from M4 Dataset
Figure: Detection of ChatGPT generated text in various domains from M4 Dataset | Source
Binoculars are highly precise in these domains and languages and less likely to incorrectly identify human-written text as machine-generated.
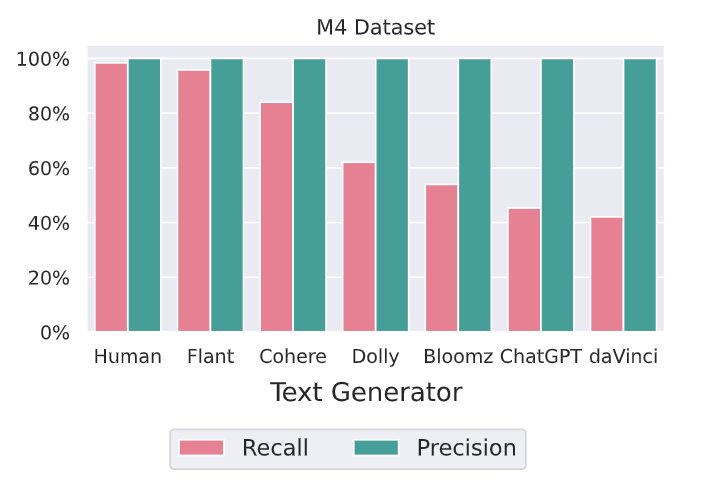 Figure: Performance of Binoculars on samples from various generative models
Figure: Performance of Binoculars on samples from various generative models
Figure: Performance of Binoculars on samples from various generative models | Source
However, they show lower recall in low-resource languages, which means they may fail to detect machine-generated text in those languages.
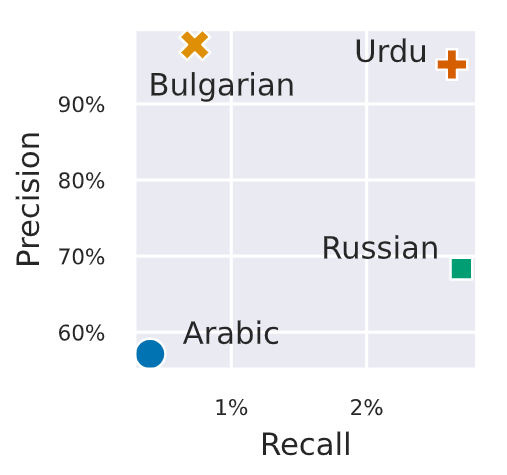 Figure: Binoculars low recall
Figure: Binoculars low recall
Figure: Binoculars low recall | Source
Importantly, Binoculars can handle variations in text written by non-native English speakers. Unlike many commercial detectors that frequently misclassify non-native English writing as machine-generated, Binoculars demonstrate consistent accuracy. They perform equally well on original essays and grammar-corrected versions written by non-native speakers.
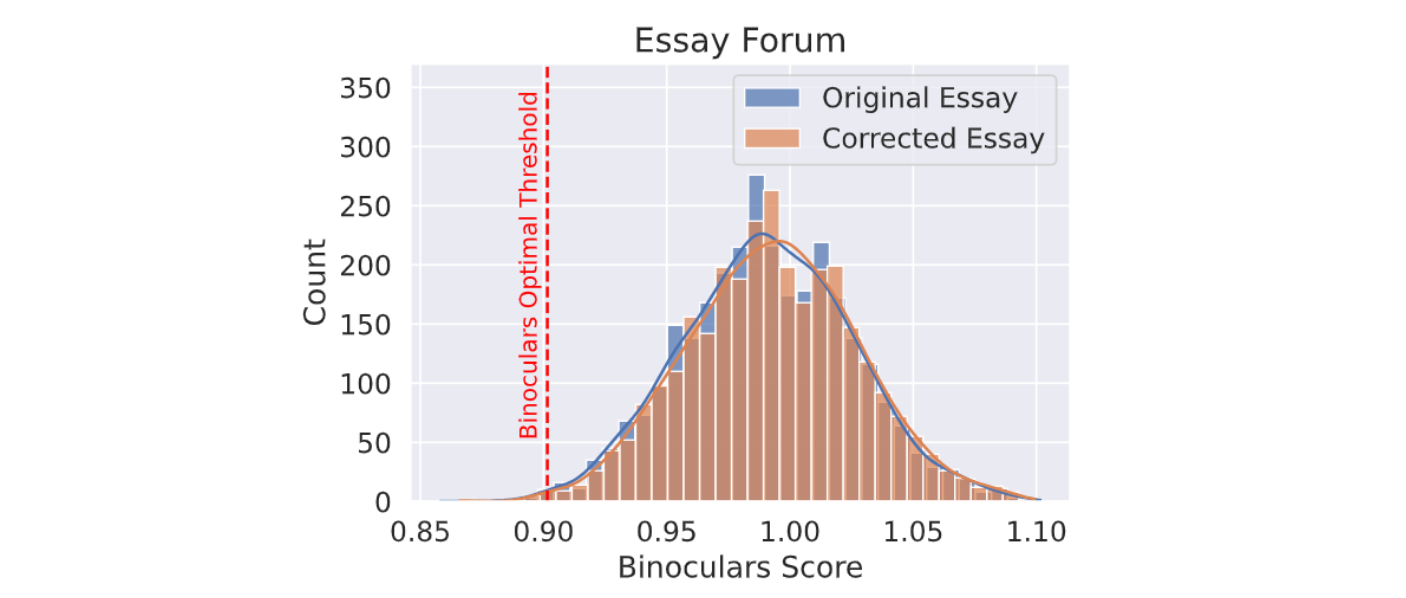 Figure: Distribution of Binoculars scores
Figure: Distribution of Binoculars scores
Figure: Distribution of Binoculars scores | Source
Performance on Memorized Text
Binoculars' behavior is also evaluated when encountering memorized text, such as famous quotes. While perplexity-based detectors might classify memorized examples as machine-generated, Binoculars perform well on this type of data.
For instance, the US Constitution receives a score within the machine-generated range, but other famous texts are correctly identified as human-written. Two songs by Bob Dylan, "Blowin’ In The Wind" and "To Fall In Love With You," are accurately labeled as human, irrespective of their popularity. This shows that Binoculars does not solely rely on perplexity and have a more robust approach to detection.
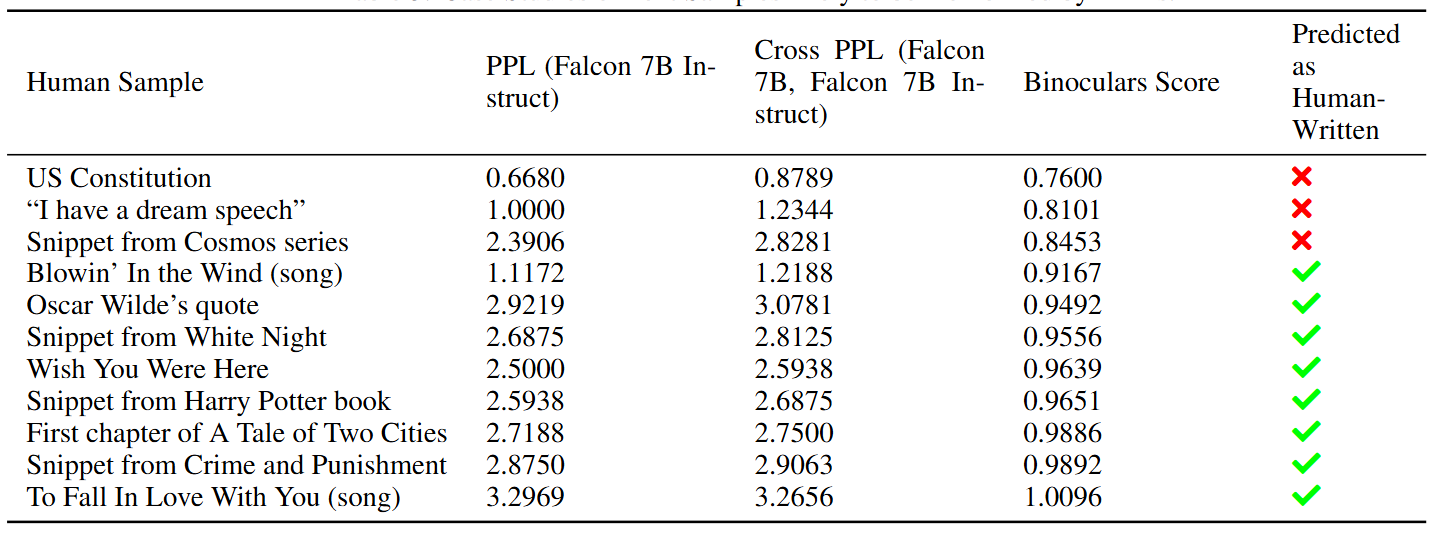 Figure: Text samples likely to be memorized by LLMs
Figure: Text samples likely to be memorized by LLMs
Figure: Text samples likely to be memorized by LLMs | Source
Impact of Modified Prompting Strategies
Binoculars stay effective when different prompting strategies are used. Using the Open Orca dataset, Binoculars can detect 92% of GPT-3 and 89.57% of GPT-4 generated samples. The method maintains its accuracy even when prompts are stylized, such as writing in the style of Carl Sagan, avoiding robotic phrasing, or even adopting a pirate-like tone.
 Figure: Open-Orca sample prompt with modifications
Figure: Open-Orca sample prompt with modifications
Figure: Open-Orca sample prompt with modifications | Source
While pirate-sounding output has the biggest impact, it only slightly decreases the detector's sensitivity. This shows Binoculars' resilience to stylistic variations in the generated text.
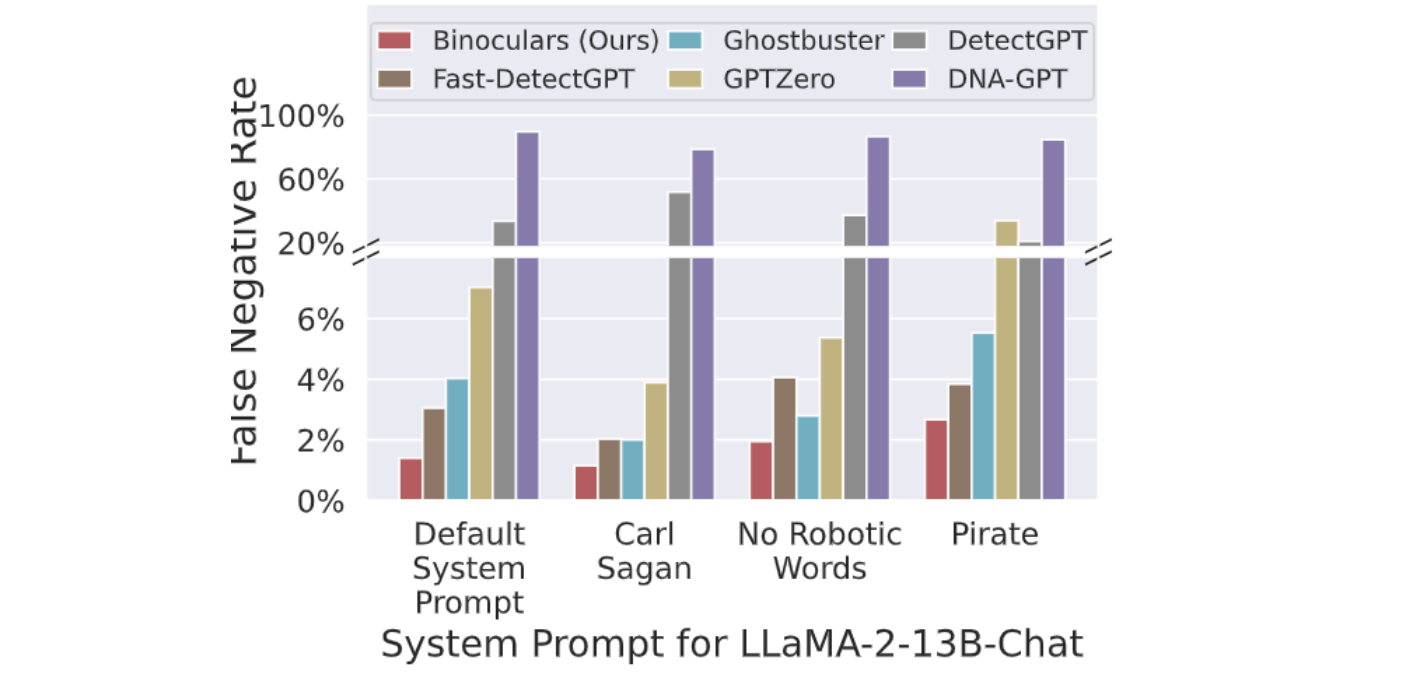 Figure: Detection with modified system prompts
Figure: Detection with modified system prompts
Figure: Detection with modified system prompts | Source
Handling Randomness
The impact of random tokens on Binoculars was also assessed. Binoculars confidently score random sequences of tokens as human-written. This is because trained LLMs are highly unlikely to generate such random sequences.
The Binoculars score for random token sequences falls on the human side of the threshold. This shows that such sequences are even less likely to be produced by a language model than by a human.
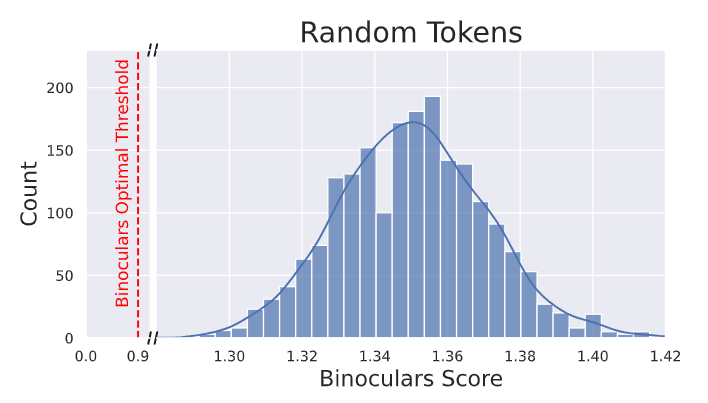 Figure: Random token sequence result
Figure: Random token sequence result
Figure: Random token sequence result | Source
Key Implications of Binoculars
The Binoculars method presents significant implications and provides a robust approach that overcomes many limitations of previous methods.
Zero-Shot Detection: Binoculars can detect machine-generated text without needing specific training data from the LLM being tested. This is a significant advantage, as it allows the method to be applied to new or unseen language models without additional training.
Robustness Across Domains: The Binoculars method is effective across different text sources and languages, showing a generalizable approach to detection. This is important because the method isn't limited to a narrow scope but applies to various text types.
Model Agnostic: The method is not limited to detecting a single LLM. It can identify text from a range of modern LLMs without model-specific modifications. It can be applied to various applications where the source of the machine-generated text may be unknown or varied.
Addressing the Capybara Problem: Binoculars overcome the challenge of detecting machine-generated text when prompts are involved by comparing perplexity to cross-perplexity. This addresses the problem of naive perplexity-based detection failing when prompts strongly influence text generation.
Conclusion and Future Research Directions
The Binoculars method introduces a novel approach to detecting machine-generated text by using zero-shot detection. It calculates a Binoculars score based on the ratio of perplexity to cross-perplexity. The method is model-agnostic and capable of detecting text from various LLMs without needing specific modifications. Therefore, it can be an adaptable tool for real-world scenarios.
Binoculars achieve a low false positive rate, which is important for minimizing the risk of misclassifying human-written text as AI-generated. While effective, it's a "black box" method that does not explain its predictions and may not be completely effective when there is a motivated attempt (adversarial attacks) to bypass it.
Future Research Directions for Binoculars
There are several future research directions to improve the Binoculars method and address its limitations:
Low-Resource Languages: One area for further exploration is improving detection performance in low-resource languages. The current method has lower recall in these languages. Using stronger multilingual models could improve the detection of machine-generated text in this context.
Non-Conversational Text Domains: Further research is needed to evaluate the method's performance in non-conversational text domains, such as source code, which were not examined.
Adversarial Attacks: Binoculars show limitations in adversarial settings. This shows the need for additional research on defending against adversarial attacks.
Model combinations: Future research could explore different model combinations. This may help identify the most effective observer and performer models to improve binocular performance.
Related Resources
Binoculars paper: Spotting LLMs With Binoculars: Zero-Shot Detection of
DetectGPT paper: Zero-Shot Machine-Generated Text Detection using Probability Curvature
Ghostbuster paper: Detecting Text Ghostwritten by Large Language Models
LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
Efficient Memory Management for Large Language Model Serving with PagedAttention
Maximizing GPT 4.x's Potential Through Fine-Tuning Techniques
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- Why Detection Methods Are Critical
- The Problem with Traditional LLM Detection
- How Binoculars Works: A Two-Lens Approach
- Experimental Setup: Data, Baselines, and Evaluation Metrics
- Binoculars' Detection Performance Across Diverse Scenarios
- Key Implications of Binoculars
- Conclusion and Future Research Directions
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
Multimodal AI learning can get input and understand information from various modalities like text, images, and audio together, leading to a deeper understanding of the world. Learn more about OpenAI's CLIP (Contrastive Language-Image Pre-training), a popular multimodal model for text and image data.

What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
As we move into new AI territories, staying committed to innovations, protecting our rights, and building trust is crucial. Making AI that preserves privacy isn't just a tech challenge; it's essential for ensuring AI grows in a way that's good for everyone.

Everything You Need to Know About LLM Guardrails
In this blog, we'll examine LLM guardrails, technical systems, and processes designed to ensure LLMs' safe and reliable operation.