




Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
We’ll explore the limitations of binary relevance labels, how fine-grained relevance scoring works, and why it’s a game-changer for zero-shot text rankers
Read the entire series
- OpenAI's ChatGPT
- Unlocking the Secrets of GPT-4.0 and Large Language Models
- Top LLMs of 2024: Only the Worthy
- Large Language Models and Search
- Introduction to the Falcon 180B Large Language Model (LLM)
- OpenAI Whisper: Transforming Speech-to-Text with Advanced AI
- Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
- What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
- LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
- Mastering Cohere's Reranker for Enhanced AI Performance
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
- Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
- RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
- Prover-Verifier Games Improve Legibility of LLM Outputs
- Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
- Unlocking the Power of Many-Shot In-Context Learning in LLMs
- Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
- Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
- Everything You Need to Know About LLM Guardrails
- Chain-of-Retrieval Augmented Generation
- Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
The way we search for information has evolved drastically. Whether you’re looking for the best product reviews, technical documentation, or answers to complex questions, ranking systems are at the core of how search engines and AI systems prioritize results. But have you ever wondered why some results feel more useful than others? It’s all about relevance and how systems decide what’s relevant.
Zero-shot text rankers powered by large language models (LLMs) are reshaping this process. These rankers don’t rely on task-specific training but instead use natural language prompts to evaluate whether a document matches a query. However, most of these systems use binary relevance labels, which classify documents as either relevant or not relevant. While this approach is simple, it struggles to differentiate between documents that fully address a query and those that are only partially relevant.
To tackle this challenge, researchers from Google introduced fine-grained relevance labels into zero-shot rankers. This method allows systems to evaluate documents on a spectrum, assessing their relevance rather than making a binary decision. Their findings, published in the paper Improving Zero-Shot LLM Rankers via Scoring Fine-Grained Relevance Labels, show that incorporating fine-grained labels improves ranking performance significantly across multiple datasets.
In this blog, we’ll explore the limitations of binary relevance labels, how fine-grained relevance scoring works, and why it’s a game-changer for zero-shot text rankers. We’ll also look at how combining this approach with vector databases can create smarter, more intuitive search systems. Let’s start with a quick overview of zero-shot text rankers.
What Makes Zero-Shot Text Rankers Unique?
Unlike traditional ranking systems that require extensive training on labeled datasets, zero-shot rankers powered by LLMs can evaluate relevance without domain-specific training. They achieve this through prompting, where the model is guided by natural language instructions to assess documents.
For example, given the query “best practices in machine learning deployment”, a zero-shot ranker might evaluate a document using a prompt like:
Does this document provide relevant information about the query ‘best practices in machine learning deployment’? Yes or No.
This ability to rank documents without additional training makes zero-shot rankers flexible and adaptable to new tasks. However, their reliance on binary relevance prompts limits their effectiveness in scenarios where relevance isn’t black and white.
Why Binary Relevance Labels Aren’t Enough
Binary relevance labels ask a simple question: Is this document relevant to the query? While this works for straightforward queries, it often falls short in real-world scenarios.
Imagine you’re searching for machine learning frameworks. A binary ranker might classify both an in-depth guide to TensorFlow and a brief overview of Python libraries as relevant. But clearly, the detailed guide deserves to rank higher. Binary relevance doesn’t have the nuance to make this distinction.
Another issue arises with partially relevant documents, which address some aspects of a query but not others. For instance, an article that discusses only the advantages of PyTorch might still offer valuable insights but won’t fully answer a query about a comparison of machine learning frameworks. Binary rankers either overvalue or undervalue such documents, leading to inconsistent rankings that don’t meet user expectations.
Fine-Grained Relevance Labels: A Smarter Approach
Fine-grained relevance labels introduce multiple levels of relevance, enabling rankers to evaluate documents on a spectrum. Instead of asking whether a document is simply relevant, fine-grained rankers ask: How relevant is this document to the query?
This approach allows the ranker to assess documents more comprehensively, categorizing them as follows:
Highly Relevant: Directly addresses the query with depth and detail.
Moderately Relevant: Partially answers the query or provides useful supporting information.
Slightly Relevant: Loosely related but lacking focus.
Not Relevant: Has little or no connection to the query.
Consider the query strategies for reducing software development time. A highly relevant document might outline specific techniques like Agile workflows, automated testing, and continuous integration pipelines, providing detailed explanations and examples. A moderately relevant document might touch on Agile methodologies without going into depth or suggest broad productivity tips applicable to many industries, not just software development. Slightly relevant documents could include high-level discussions on productivity without focusing on software, while not-relevant ones might discuss completely unrelated topics like hardware performance optimization.
This ability to distinguish between degrees of relevance ensures that the ranker prioritizes documents that align more closely with what the user is looking for, enhancing the overall search experience.
How Fine-Grained Relevance Works
The first step in implementing fine-grained relevance is to redesign the prompts given to the ranker. Traditional binary prompts simply ask: Is this document relevant? Yes or No. Fine-grained prompts, on the other hand, encourage the model to evaluate documents more thoughtfully. For instance: Rate this document as Highly Relevant, Moderately Relevant, Slightly Relevant, or Not Relevant. Some prompts take this further by using numerical scales, such as: On a scale of 0 to 4, how relevant is this document to the query?
These refined prompts allow the ranker to make more nuanced judgments, resulting in rankings that feel more accurate and meaningful. Let's see how these strategies work:
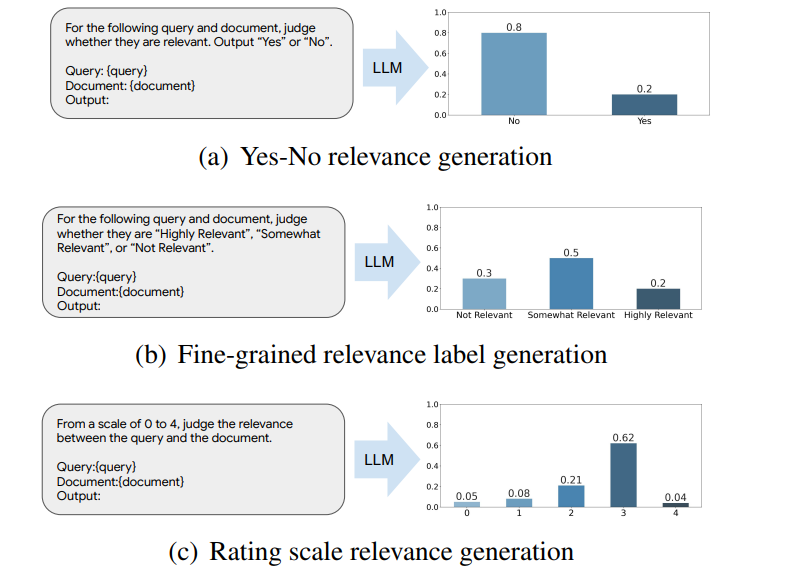
Figure 1: Illustration of different prompting strategies for relevance generation LLM rankers.
The binary approach offers a simple yes or no decision but lacks nuance. Fine-grained labels introduce intermediate categories like somewhat relevant, distributing probabilities across multiple relevance levels. The rating scale method assigns probabilities to a numerical range (e.g., 0 to 4), enabling more detailed evaluations.
Scoring Relevance: ERV and PRL
Once fine-grained relevance labels are integrated into the ranking process, the next step is to translate these nuanced judgments into actionable scores. Two methods are used for this: Expected Relevance Value (ERV) and Peak Relevance Likelihood (PRL). Each method serves a specific purpose, with ERV focusing on proportional contributions from all relevance levels and PRL emphasizing the single most likely level.
These scoring techniques help the ranker calculate relevance scores that prioritize results effectively, ensuring that the most useful documents are ranked higher. Let’s take a closer look at each method and how it works.
Expected Relevance Value (ERV)
ERV calculates a weighted average of relevance levels based on the probabilities assigned to each level. This ensures that all relevance levels contribute to the final score, capturing the model's overall judgment about a document's relevance.
When the language model evaluates a document, it provides confidence scores for each relevance level. These scores are then converted into probabilities (like percentages) that tell us how confident the model is about each level of relevance. We combine these probabilities with preset values for each relevance level to get a final score that represents the document's overall relevance.
The formula for ERV is: f(q, di) = Σ pi,k · yk
where pi,k = exp(si,k) / Σk' exp(si,k')
si,k represents the model's raw confidence score for each relevance level, which we convert into probabilities (pi,k). We then multiply these probabilities by the value we've assigned to each relevance level (yk) and add them all up to get the final score. This way, we capture both how confident the model is about each relevance level and how important we consider each level to be.
Let’s say a document is evaluated as:
70% likely to be Highly Relevant (Score: 4),
20% likely to be Moderately Relevant (Score: 3),
10% likely to be Slightly Relevant (Score: 2).
The ERV is calculated as:
ERV = (0.7 × 4) + (0.2 × 3) + (0.1 × 2) ERV = 2.8 + 0.6 + 0.2 = 3.5
This score, 3.5, reflects the document’s overall relevance, considering all assigned probabilities. ERV is mostly useful for cases where the model’s confidence is distributed across multiple relevance levels, as it ensures that partial relevance is taken into account.
Peak Relevance Likelihood (PRL)
PRL simplifies the scoring process by focusing only on the direct log-likelihood score from the LLM for the highest relevance level. Instead of working with probabilities, it uses the raw log-likelihood score provided by the model.
The formula for PRL is: PRL = si,k*
si,k* is the log-likelihood score directly obtained from the LLM for the highest relevance level k*. For example, if a document receives these log-likelihood scores: Highly Relevant: -0.357 Moderately Relevant: -1.609 Slightly Relevant: -2.303
The PRL would simply be -0.357 (the score for Highly Relevant). This approach is particularly efficient as it only requires obtaining one log-likelihood score rather than computing probabilities across all relevance levels.
Comparing ERV and PRL
Both methods are effective but serve different purposes. ERV captures the full range of the model's confidence distribution, making it ideal for scenarios where partial relevance plays a significant role. PRL is computationally simpler and more direct, using raw log-likelihood scores that work particularly well with larger language models.
For instance, when ranking academic papers in response to a research query, ERV is preferable as papers often contain varying degrees of relevance to different aspects of the query. However, for a product search where the goal is to find exact matches to specific customer requirements, PRL could be more appropriate due to its emphasis on high-confidence matches.
Real-World Performance of Fine-Grained Relevance Scoring
The effectiveness of fine-grained relevance scoring was tested on eight datasets from the BEIR benchmark, a trusted suite for evaluating information retrieval systems. The results showed clear improvements in ranking performance, even under challenging conditions. These were the findings:
Higher NDCG ScoresFine-grained prompts consistently outperformed binary ones in Normalized Discounted Cumulative Gain (NDCG), a metric that emphasizes ranking the most relevant documents higher. On the TREC-COVID dataset, which focuses on medical research, fine-grained scoring increased NDCG scores by up to 2%. Similar gains were observed across datasets like SciFact (scientific claims) and FiQA (financial queries).
Effective on Binary-Labeled DataThe method also performed well on datasets designed for binary relevance, such as Quora and HotpotQA. This shows that fine-grained relevance works even in cases where the data lacks nuanced ground truth labels, proving its adaptability.
Better Handling of Partial RelevanceFine-grained scoring introduced intermediate levels of relevance, allowing the system to better rank partially relevant documents. Instead of undervaluing or overvaluing documents with supporting or tangential information, the system appropriately placed them in the rankings, leading to cleaner and more accurate results.
Enhancing Search with Fine-Grained Relevance and Vector Databases
The performance gains by fine-grained relevance scoring highlight its ability to deliver nuanced rankings that align closely with user needs. However, relevance scoring doesn’t operate in isolation. To unlock its full potential, it must be paired with powerful retrieval systems capable of identifying the right candidates for ranking.
This is where vector databases come in, bridging the gap between semantic retrieval and precise ranking. Vector databases, such as Milvus, store documents as high-dimensional embeddings, which capture the semantic meaning of text rather than relying solely on keyword matches. While fine-grained relevance scoring ensures nuanced ranking of results, vector databases ensure that the right set of candidates is retrieved in the first place, providing a strong foundation for ranking systems.
For example, for the query best frameworks for deep learning. A vector database retrieves a broad set of documents discussing TensorFlow, PyTorch, and Keras based on their semantic similarity to the query. Fine-grained relevance scoring then evaluates these documents on a spectrum, prioritizing detailed guides or comparative analyses over general overviews. For example, a tutorial that explores TensorFlow’s deployment capabilities and PyTorch’s flexibility for research would rank higher than a blog post that briefly mentions all three frameworks.
Applications in Retrieval-Augmented Generation (RAG)
This integration becomes particularly impactful in retrieval-augmented generation (RAG) workflows. In RAG, LLMs retrieve relevant documents to inform responses. Fine-grained scoring ensures that only the most contextually appropriate documents are selected, enhancing the quality of generated answers.
For instance, in a technical support scenario, a query like How can I optimize my PyTorch model? would result in prioritized documents detailing optimization techniques such as learning rate schedules and batch normalization. By retrieving and ranking the most relevant information, the system ensures precise and helpful responses.
This combination of semantic retrieval capabilities of vector databases with fine-grained relevance scoring makes search systems not only retrieve documents that match the query’s intent but also rank them by depth, specificity, and usefulness.
Future Directions for Fine-Grained Relevance Scoring
While fine-grained relevance scoring marks a significant advancement in ranking systems, there is still ample room for innovation and exploration. Future research could focus on several key areas to further enhance its applicability and efficiency.
Personalized Relevance Judgments
One exciting avenue is incorporating user preferences and context into fine-grained scoring. A system could learn from individual user behavior to refine its relevance assessments, delivering rankings tailored to specific needs. For instance, a researcher looking for technical explanations might prioritize detailed papers, while a casual user might prefer summaries.
Multimodal Extensions
As content increasingly spans multiple formats of text, images, and videos future models could extend fine-grained relevance scoring to multimodal data. For example, a search for climate change visualizations could rank results by combining the relevance of accompanying visuals with the explanatory power of the text.
Dynamic Context Awareness
Queries often depend on context, such as time, location, or evolving trends. Enhancing fine-grained scoring with dynamic context awareness could allow systems to adapt relevance judgments based on these factors. For example, a search for data privacy regulations could prioritize recent documents over older ones, reflecting changes in laws or practices.
Conclusion
Fine-grained relevance scoring addresses the limitations of binary judgments in zero-shot text rankers by evaluating documents on a nuanced spectrum, delivering results that align more closely with user expectations. Combined with vector databases, it enhances semantic search by retrieving and ranking results based on meaning and depth, proving especially effective in technical fields, academic research, and retrieval-augmented generation workflows. Integrating this approach with personalization, multimodal capabilities, and context-aware systems offers the potential to bridge the gap between machine processing and human understanding, paving the way for smarter, more intuitive search systems.
Further Resources
 Denis Kuria
Denis KuriaDenis is a machine learning engineer who enjoys writing guides to help other developers. He has a bachelor's in computer science and loves hiking and exploring the world.
- What Makes Zero-Shot Text Rankers Unique?
- Why Binary Relevance Labels Aren’t Enough
- Fine-Grained Relevance Labels: A Smarter Approach
- How Fine-Grained Relevance Works
- Real-World Performance of Fine-Grained Relevance Scoring
- Enhancing Search with Fine-Grained Relevance and Vector Databases
- Future Directions for Fine-Grained Relevance Scoring
- Conclusion
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Large Language Models and Search
Explore the integration of Large Language Models (LLMs) and search technologies, featuring real-world applications and advancements facilitated by Zilliz and Milvus.

Mastering Cohere's Reranker for Enhanced AI Performance
Unlock the full potential of AI applications by diving into the fine-tuning process of Cohere's Reranker, a powerful tool for optimizing search results and recommendation systems.

RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
RouteLLM is an open-source framework that enables developers to efficiently route tasks to the most suitable LLMs based on cost, latency, and accuracy.