




DistilBERT: A Distilled Version of BERT
DistilBERT maintains 97% of BERT's language understanding capabilities while being 40% small and 60% faster.
Read the entire series
- Exploring BGE-M3 and Splade: Two Machine Learning Models for Generating Sparse Embeddings
- Comparing SPLADE Sparse Vectors with BM25
- Exploring ColBERT: A Token-Level Embedding and Ranking Model for Efficient Similarity Search
- Vectorizing and Querying EPUB Content with the Unstructured and Milvus
- What Are Binary Embeddings?
- A Beginner's Guide to Website Chunking and Embedding for Your RAG Applications
- An Introduction to Vector Embeddings: What They Are and How to Use Them
- Image Embeddings for Enhanced Image Search: An In-depth Explainer
- A Beginner’s Guide to Using OpenAI Text Embedding Models
- DistilBERT: A Distilled Version of BERT
- Unlocking the Power of Vector Quantization: Techniques for Efficient Data Compression and Retrieval
Advancements in transformer-based language models have significantly changed natural language processing (NLP). BERT, or Bidirectional Encoder Representations Transformers, is one of the most influential language models, introduced in 2018. Its bidirectional nature reads text in both directions, which makes it different from earlier models that processed text in only one direction. Because of this, BERT achieves state-of-the-art results in various NLP tasks.
However, one major disadvantage of BERT is its resource-intensive nature. Its base model has 110 million parameters, while the larger version has 340 million. Training and deploying BERT on edge devices require a lot of memory and computational resources.
To overcome these problems, DistilBERT was introduced as a smaller, faster, and distilled version of BERT. It maintains 97% of BERT's language understanding capabilities while being 40% small and 60% faster. This article will discuss the methodologies used in DistilBERT development, including the training approach and its results. We will also see how to implement DistilBERT with Hugging Face.
What is DistilBERT?
DistilBERT pre-trains a smaller and faster general-purpose language representation model, which can be fine-tuned with good performance on many downstream tasks.
The primary motivation behind DistilBERT is the need for compact and more efficient models for NLP applications that operate in real-time on edge devices. Language models like BERT often require substantial computational resources, limiting deployment in resource-constrained environments.
To address these challenges, DistilBERT focuses on the following key objectives:
Computational Efficiency: While BERT requires more computational resources to operate due to its large number of parameters, ****DistilBERT reduces the size of a BERT model by 40%. It requires less computation and time, which is especially useful when working with large datasets.
Faster Inference Speed: BERT's complexity leads to slow inference times. DistilBERT addresses this problem by being smaller and optimized for speed and giving 60% faster inference times compared to BERT. On-device applications, such as mobile question-answering apps, DistilBERT is 71% faster than BERT.
Comparable Performance: Although DistilBERT is much smaller, it retains 97% of BERT’s accuracy on popular NLP benchmarks. This balance between size reduction and minimal performance degradation makes it a solid alternative to BERT.
How Does DistilBERT Work?
Understanding the underlying methodologies that enable the DistilBERT model to deliver significant efficiency gains without sacrificing performance is important.
DistilBERT's key methodologies are the following:
Knowledge Distillation
Triple Loss Function
Architecture Modification
Knowledge Distillation
Knowledge distillation, introduced by Hinton et al. in 2015, is the compression and core technique behind DistilBERT. This technique trains a smaller, simpler model (the student) by replicating knowledge from a larger, pre-trained model (the teacher). Here, BERT serves as the teacher, and DistilBERT is the student. Generally, the distillation procedure is applied during the pertaining but can also be used during the fine-tuning.
Consider an example to understand knowledge distillation. Suppose a large, state-of-the-art image classification model, like ResNet-50, which has been trained on a large dataset. We can use this model as the teacher network. Now, we want to deploy a smaller model on resource-constrained devices like smartphones without sacrificing accuracy. We can train a smaller student network like MobileNet via knowledge distillation.
The student network learns from the teacher network soft probabilities and minimizes the cross-entropy between the student's predicted distribution. Soft probabilities refer to a model's output probabilities before converting them into hard, discrete class predictions. This improves performance and reduces memory and computation needs.
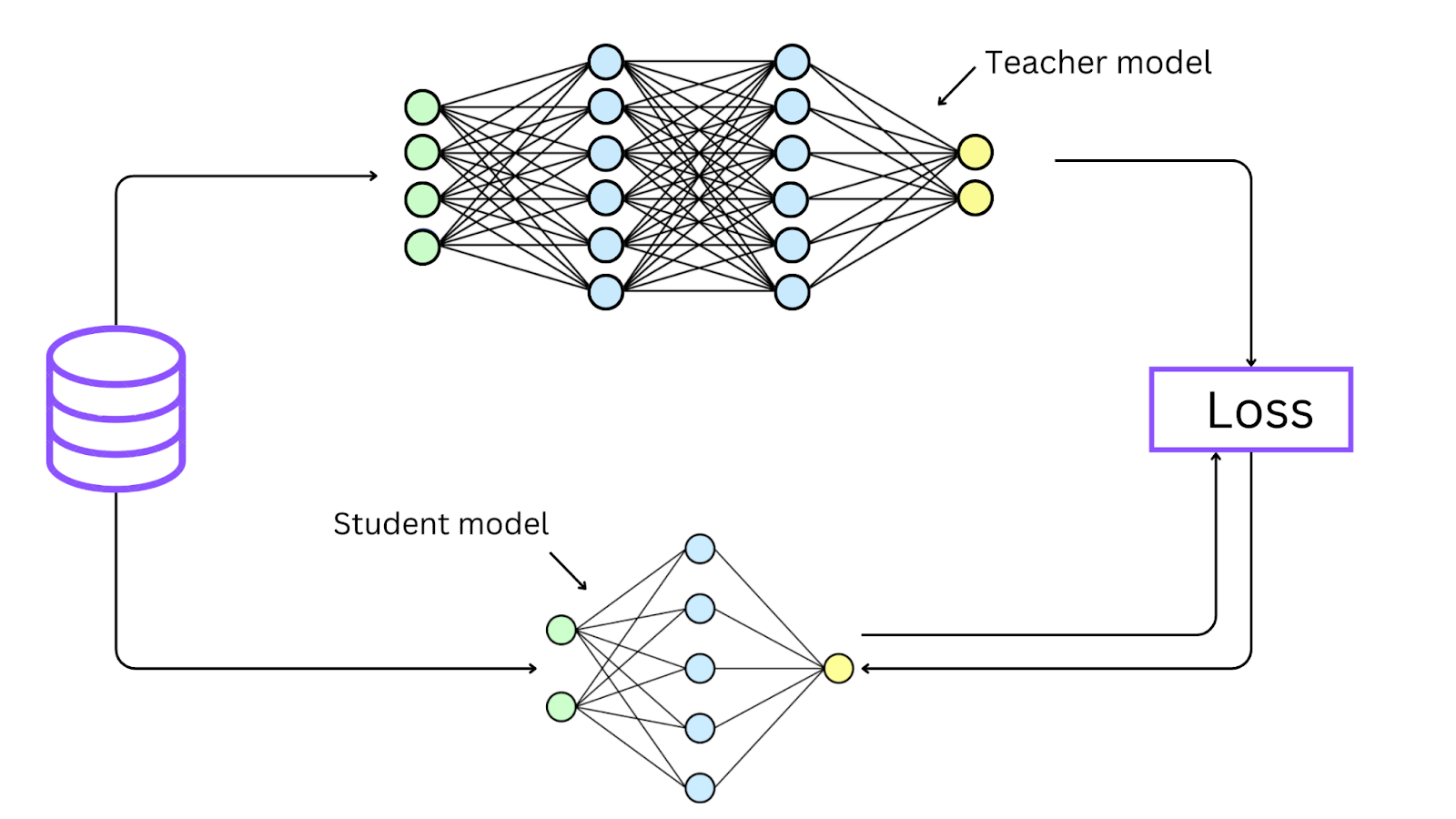 Figure: Teacher-student model knowledge distillation
Figure: Teacher-student model knowledge distillation
In this illustration, the teacher network trains the student network by giving it soft probabilities. This helps the student network learn well and replicate the teacher network's behavior.
Triple Loss Function in Knowledge Distillation
The knowledge distillation process in DistilBERT uses the triple loss function. This loss function helps the student model (DistilBERT) learn from the knowledge and patterns of the teacher model (BERT). But before discussing loss functions in detail, it's necessary to understand the concept of softmax temperature (temperature in softmax function). This hyperparameter controls the smoothness of the output probabilities of the teacher model.
We usually use a softmax function in standard neural networks to convert the model output scores into probabilities. The softmax function is defined as:
Softmax(z)=f(zi)= exp(z) / sum(exp(z))
However, Softmax Temperature introduces a small variation to the standard softmax function, where the model outputs are divided by 𝑇 (temperature) before applying the softmax function. This is done to reduce the difficulty level for the student model, as the probability distribution learned by the teacher is often very close to 0 or 1, making it harder for the student to learn. The formula for Softmax temperature is:
Softmax(zi, T)=f(zi, T)= exp(z/T) / sum(exp(z/T))
The temperature 𝑇 controls the smoothness of the probability distribution:
When 𝑇 = 1, this is equivalent to the standard softmax.
When 𝑇 > 1, the output probabilities are smoother.
When 𝑇 < 1, the output probability distribution becomes more rough.
In other words, the Higher the temperature, the smoother the probability distribution.
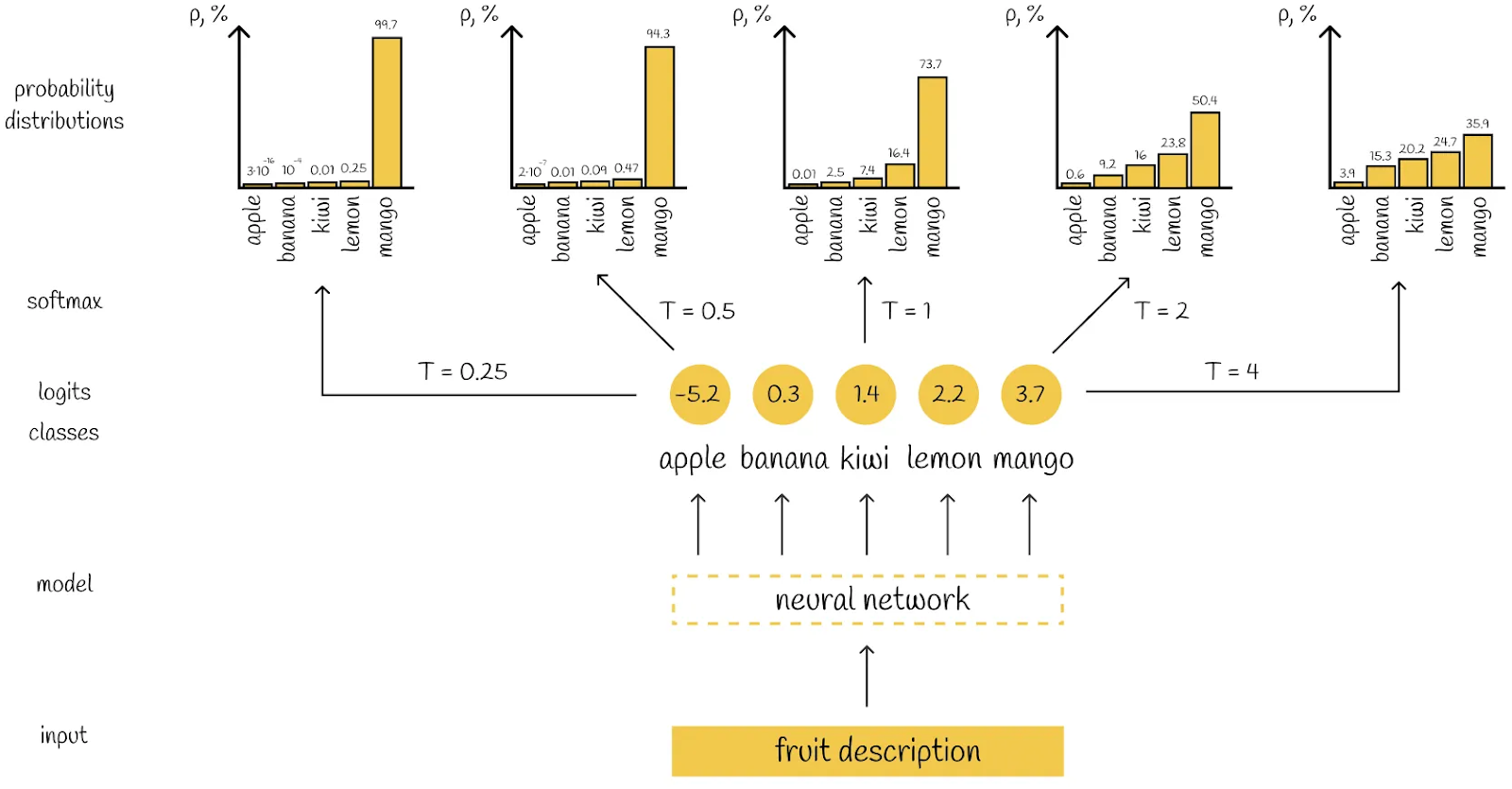 Figure: Illustration of a neural network producing different probability distributions based on the temperature 𝑇
Figure: Illustration of a neural network producing different probability distributions based on the temperature 𝑇
Now, let's look at the loss functions used in DistilBERT one by one. These functions help DistilBERT learn from BERT and update its weights.
Masked language modeling loss Lmlm
Distillation loss Lce
Cosine embedding loss Lcos
Masked language modeling loss (MLM)
Like BERT, DistilBERT learns language patterns by using a technique called masked language modeling (MLM). In MLM, certain words in a sentence are randomly replaced with a special token, and the model learns to predict these masked words based on the surrounding context.
The cross-entropy loss between the predicted and actual distributions is calculated, and the weights of the student’s model are updated through backpropagation.
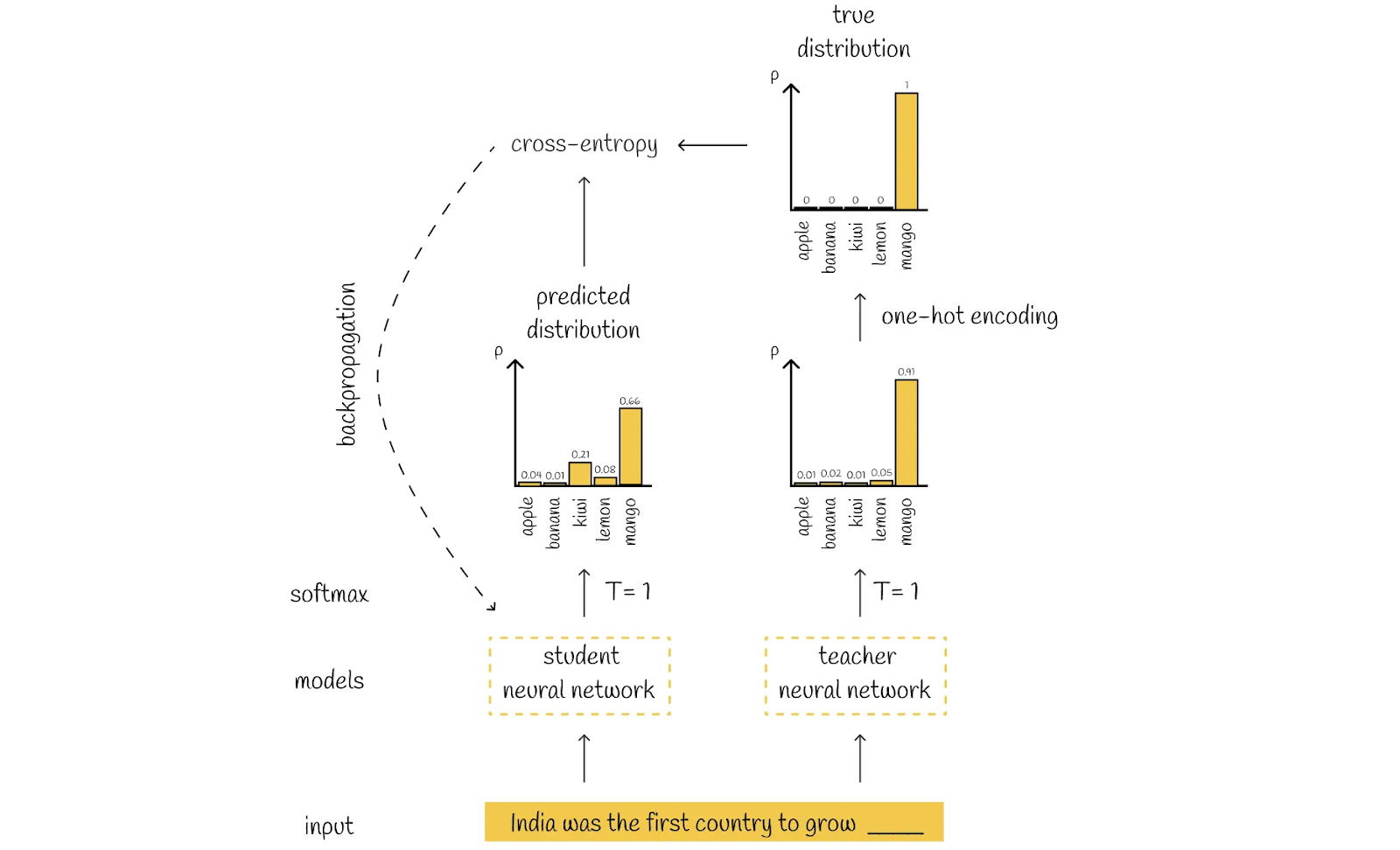 Figure: Illustration of Masked language modeling loss calculation
Figure: Illustration of Masked language modeling loss calculation
Distillation loss
Distillation loss is essential in training the student model during knowledge distillation. It's calculated by comparing the student's prediction probability to the soft probabilities provided by the teacher model.
Lce= iti*log(si)
Where ti the probability is estimated by the teacher and si the probability is estimated by the student.
While it is technically possible to use only the student loss to train the student model, relying only on student loss is not optimal because of the softmax transformation when the temperature 𝑇 is set to 1. When 𝑇 = 1, the resulting probability distribution is likely to be very skewed, with one label having a very high probability close to 1, while the probabilities for all other labels approach 0. This behavior becomes challenging when many classification labels may be valid for the same input.
To address this issue, DistilBERT uses a distillation loss, where the softmax probabilities are calculated with a temperature 𝑇 > 1. This change makes the output probabilities more evenly distributed, which helps the student model to consider multiple possible answers.
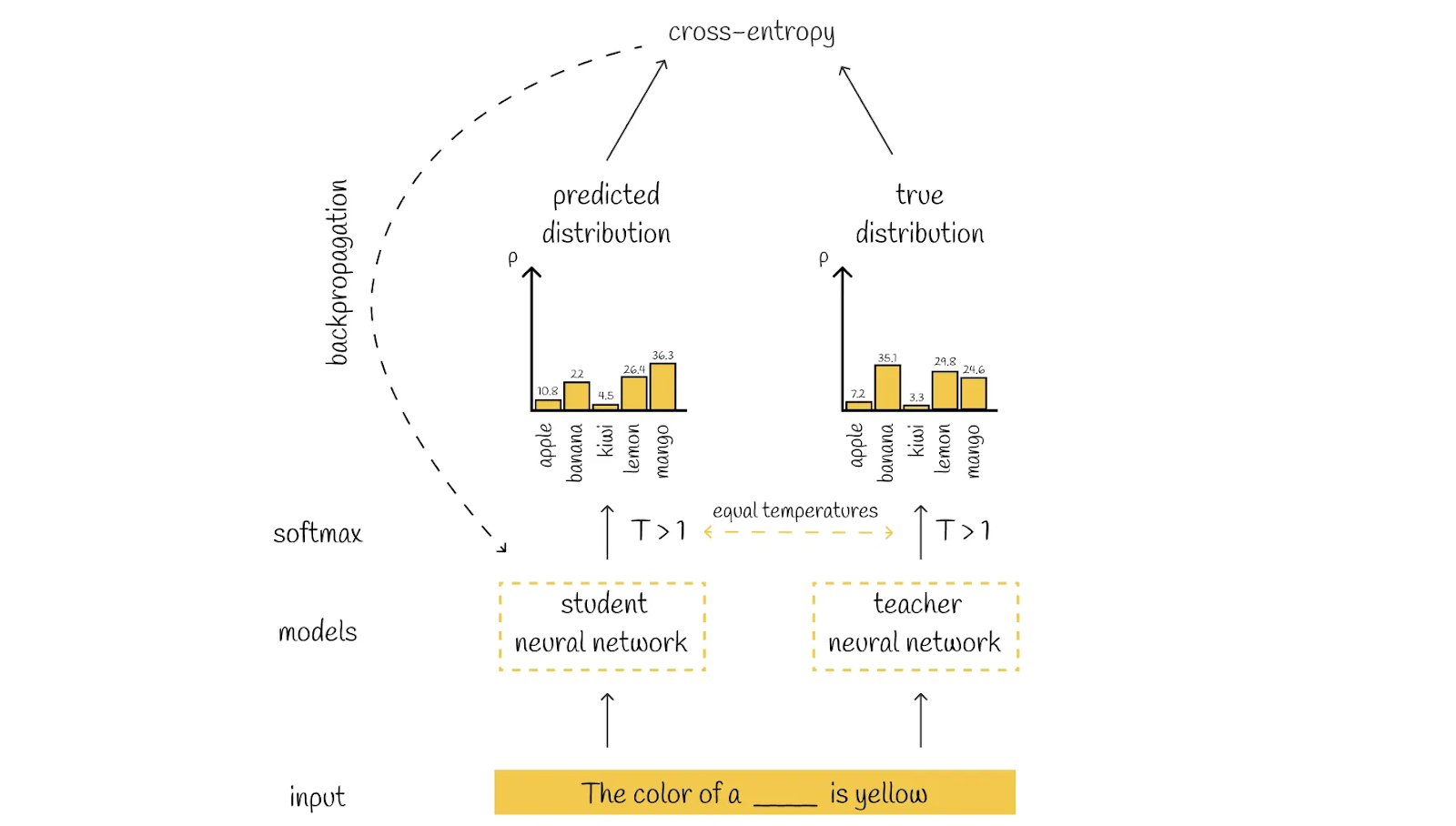 Figure: Illustration of Distillation loss calculation
Figure: Illustration of Distillation loss calculation
Cosine embedding loss
Cosine embedding loss is another important component used in the DistilBERT training process. Its primary purpose is to ensure that the student model learns to replicate the teacher model's internal knowledge representations (embeddings) by minimizing the cosine distance between the embeddings generated by the student and teacher models.
The cosine similarity can be computed as the negative of the cosine similarity between the teacher’s and student’s generated embeddings(h).
Lcos= 1 - hteacher . hstudenthteacher hstudent
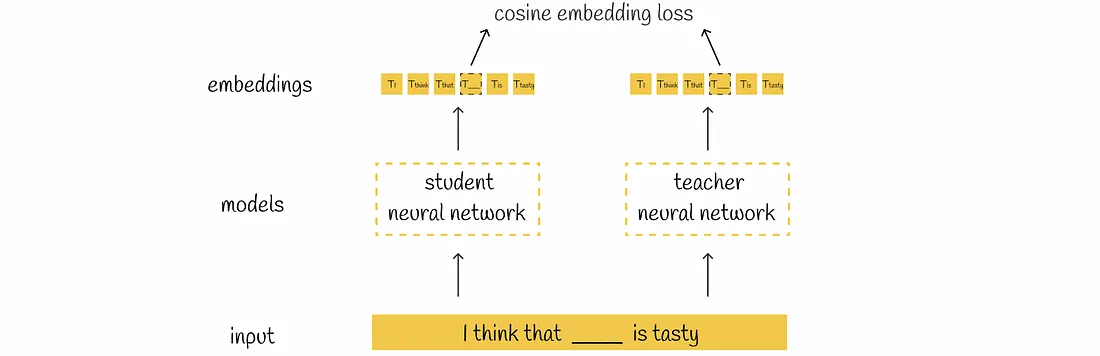 Figure: Cosine embedding loss calculation
Figure: Cosine embedding loss calculation
Triple loss
Finally, the loss function in DistilBERT is determined by adding the linear combinations of the three loss functions. Based on the loss value, the student model undergoes backpropagation to update its weights.
Loss = Lmlm+ Lce+ Lcos
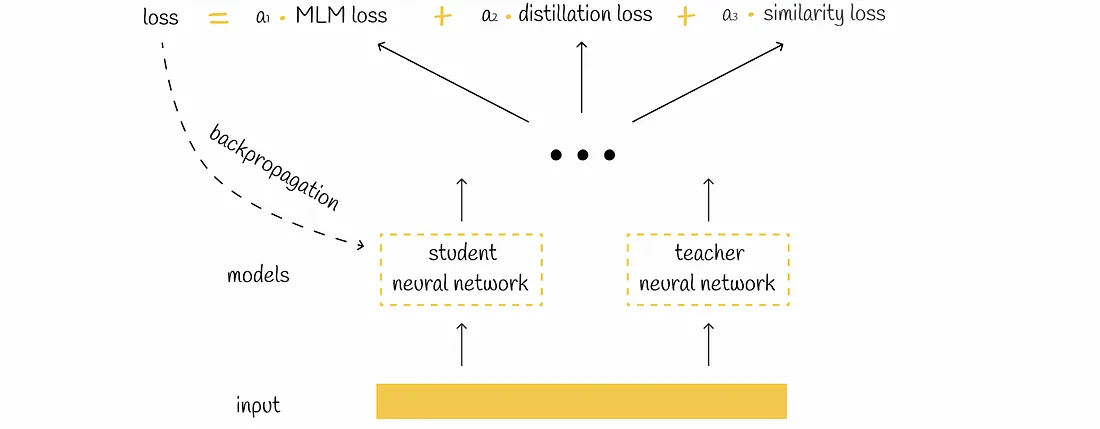 Figure: DistilBERT loss function
Figure: DistilBERT loss function
DistilBERT Architecture
The student model, DistilBERT, has the same general architecture as BERT but with some modifications. The token-type embeddings and the pooler are removed, and the number of layers is reduced by a factor of 2. BERT Base has 12 layers, while DistilBERT has only 6. These architectural changes make DistilBERT more efficient, and further improvements were made during training, as explained next.
Student Initialization: A critical part of training DistilBERT is determining how to initialize the student model so it learns well. Since both BERT (the teacher) and DistilBERT (the student) share the same dimensionality, the student is initialized by taking one layer out of two from the teacher model.
Distillation: DistilBERT was distilled in very large batches (up to 4K examples per batch) using dynamic masking. The next sentence prediction (NSP) objective was removed so the model could focus more on understanding the masked words in each sentence. This concept was taken from RoBERTa to provide a more robust performance.
Data and Compute Power: DistilBERT was trained on the same dataset as the original BERT model, a concatenation of English Wikipedia (2500M words) and Toronto Book Corpus (800M words), and on 8 16GB V100 GPUs for approximately 90 hours.
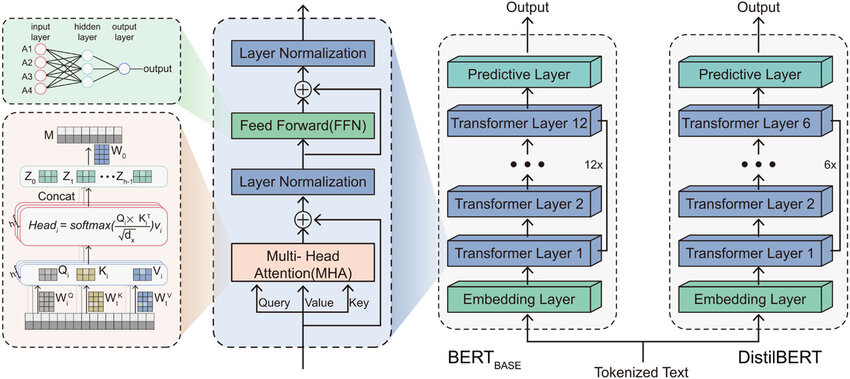 Diagram of BERT BASE and DistilBERT model architecture
Diagram of BERT BASE and DistilBERT model architecture
Experimental Results
DistilBERT's language understanding and generalization capabilities were evaluated on the General Language Understanding Evaluation (GLUE) benchmark, a collection of 9 datasets for evaluating natural language understanding systems. DistilBERT's performances were also evaluated on downstream tasks, such as sentiment classification (IMDb) ****and question-answering tasks (SQuAD v1.1 - Stanford Question Answering Dataset).
GLUE
 Figure: Comparison of the dev sets of the GLUE benchmark
Figure: Comparison of the dev sets of the GLUE benchmark
DistilBERT achieves a score of 77.0 on the GLUE benchmark and is always on par with or improving over the ELMo baseline provided by the GLUE authors (up to 19 points of accuracy on the STS-B - Semantic Textual Similarity Benchmark). DistilBERT also compares to BERT, retaining 97% of the performance with 40% fewer parameters.
IMDb & SQuAD
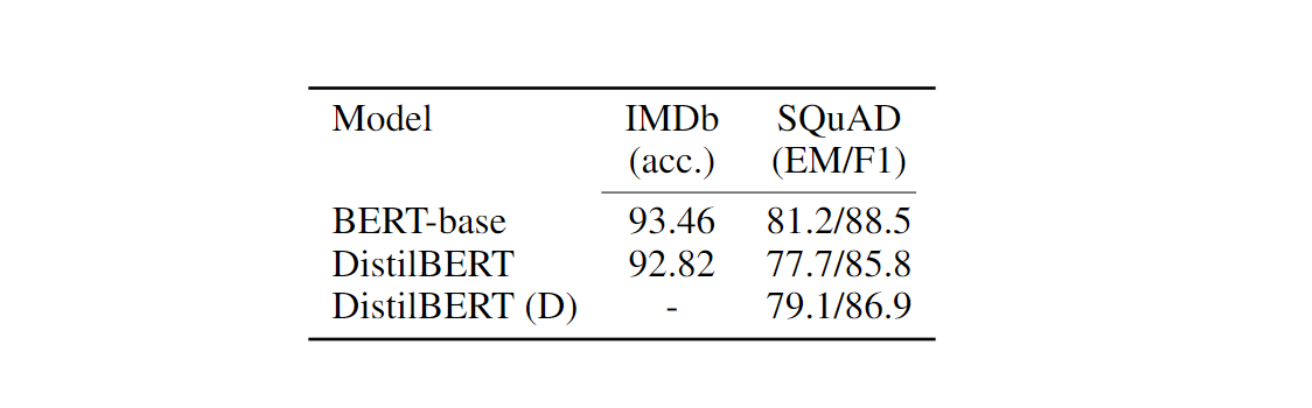 Figure: DistilBERT yields comparable performance on downstream tasks
Figure: DistilBERT yields comparable performance on downstream tasks
DistilBERT achieved results comparable to those of BERT on downstream tasks. It is only 0.6% behind BERT in test accuracy on the IMDb benchmark, while it is 40% smaller. On SQuAD, DistilBERT is within 3.9 points of the full BERT.
Size and Inference Speed
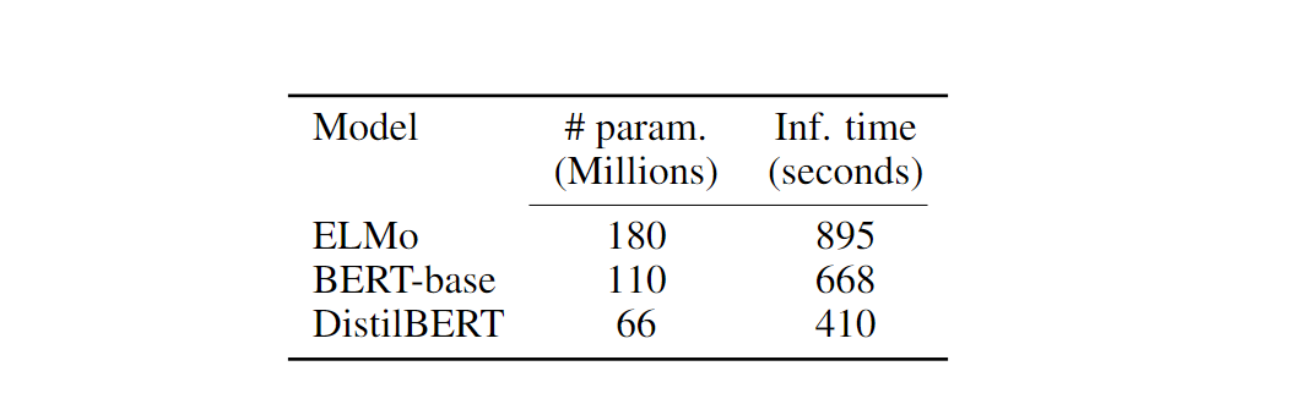 Figure: DistilBERT inference time and model parameters
Figure: DistilBERT inference time and model parameters
DistilBERT has 40% fewer parameters than BERT and is 60% faster than BERT. The number of parameters and inference time for both models were compared on the STS-B development set, using a batch size of 1 on a CPU.
DistillBERT Implementation with Hugging Face
DistilBERT can be implemented in Python using the Hugging Face Transformers library. Here are the steps for implementing DistilBERT. The code below is from HuggingFace.
Step 1: Install the Transformers library
You can install the Transformers library using pip. Open your terminal and enter the following command.
!pip install transformers
Step 2: Load the Pre-trained DistilBERT Model
You can load the pre-trained DistilBERT model using the DistilBertForSequenceClassification class.
# Import libraries
import torch
from transformers import AutoTokenizer,DistilBertForSequenceClassification
#Load tokenizer and pre-trained model
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
Step 3: Tokenize the Input Text
Tokenize the input text using tokenizer function.
Input_text = "Hello, my dog is cute"
# Tokenize the input text
inputs = tokenizer(Input_text, return_tensors="pt")
Step 4: Inference using the pre-trained model on the Input Text
Finally, we get the predicted label by taking the argmax of the model's output logits.
with torch.no_grad():
logits = model(**inputs).logits
# Get predicted class ID
predicted_class_id = logits.argmax().item()
To train DistilBERT on a specific task, you need to set the number of output classes and provide appropriate training data. The following code demonstrates how to do this:
# Set the number of output classes
num_labels = len(model.config.id2label)
# Create a new model with the desired number of labels
model = DistilBertForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=num_labels
)
# Calculate loss
labels = torch.tensor([1])
loss = model(**inputs, labels=labels).loss
The code demonstrates the steps for using DistilBERT for a SequenceClassification with Hugging Face, where the model predicts labels based on the input text. While the current example focuses on classification, DistilBERT, like BERT, is a general-purpose pre-trained language model that can be used to generate contextual embeddings for text.
These embeddings can be stored in vector databases such as Milvus or Zilliz Cloud, designed for efficient vector retrieval and semantic search. Vector databases are optimized for handling high-dimensional vectors and are perfect for many modern AI applications, such as retrieval-augmented generation (RAG) systems, AI chatbots, recommendation engines, and natural language processing apps.
Conclusions
DistilBERT made a huge step in advancing BERT by significantly compressing the model while maintaining comparable performance across various NLP tasks. Additionally, at just 207 MB, it becomes much easier to integrate on devices with limited resources. While knowledge distillation is the primary technique, DistilBERT can be further compressed through methods like quantization or pruning algorithms for even greater efficiency.
Further resources
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- What is DistilBERT?
- How Does DistilBERT Work?
- Experimental Results
- DistillBERT Implementation with Hugging Face
- Conclusions
- Further resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading
A Beginner's Guide to Website Chunking and Embedding for Your RAG Applications
This post explains how to extract content from a website and use it as context for LLMs in a RAG application. However, before doing so, we need to understand website fundamentals.

An Introduction to Vector Embeddings: What They Are and How to Use Them
In this blog post, we will understand the concept of vector embeddings and explore its applications, best practices, and tools for working with embeddings.
Image Embeddings for Enhanced Image Search: An In-depth Explainer
Image Embeddings are the core of modern computer vision algorithms. Understand their implementation and use cases and explore different image embedding models.