




Mastering Cohere's Reranker for Enhanced AI Performance
Unlock the full potential of AI applications by diving into the fine-tuning process of Cohere's Reranker, a powerful tool for optimizing search results and recommendation systems.
Read the entire series
- OpenAI's ChatGPT
- Unlocking the Secrets of GPT-4.0 and Large Language Models
- Top LLMs of 2024: Only the Worthy
- Large Language Models and Search
- Introduction to the Falcon 180B Large Language Model (LLM)
- OpenAI Whisper: Transforming Speech-to-Text with Advanced AI
- Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
- What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
- LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
- Mastering Cohere's Reranker for Enhanced AI Performance
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
- Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
- RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
- Prover-Verifier Games Improve Legibility of LLM Outputs
- Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
- Unlocking the Power of Many-Shot In-Context Learning in LLMs
- Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
- Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
- Everything You Need to Know About LLM Guardrails
- Chain-of-Retrieval Augmented Generation
- Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
Introduction
Re-ranking is a fundamental concept employed in search engines and recommendation systems to prioritize the final list of candidates less relevant documents or items based on specific criteria. It plays a crucial role in modern systems, significantly enhancing the quality of information shared with users and improving the overall user experience. By refining the order in which results are presented, re-ranking helps ensure that the most relevant and useful information is surfaced first, making it easier for users to find what they are looking for.
Traditional re-ranking methods often rely on criteria such as item recency, popularity within the application, and other data object sometimes even user preferences or behavioral data. These criteria are essential for filtering and sorting large volumes of data, but they can be limited in their ability to capture the true relevance of an item to a specific query or user need.
Last year, Cohere introduced its innovative rerank model, Rerank endpoint, which harnesses the power of artificial intelligence and advanced semantic understanding to re-rank retrieved passages and candidate documents based on their relevance to a given query. This sophisticated rerank model not only facilitates re-ranking but also introduces robust semantic search capabilities to search engines and recommendation systems, addressing the complex challenge of accurately defining queries to yield the most relevant results. By leveraging AI to understand the deeper meanings behind queries and the documents retrieved, Cohere's Rerank endpoint enables systems to deliver more precise and contextually appropriate results, thereby further enhancing the user experience and satisfaction.
Cohere Rerank Endpoint
According to Cohere's blog post, "the Rerank system is a sophisticated semantic relevance scoring and ranking system that optimizes search results by evaluating the contextual relationship between queries and passages." This approach goes beyond simple keyword matching by understanding the nuances and deeper meanings in both the queries and the context length the passages, allowing for a more accurate and contextually relevant ranking of search results.
Cohere's re-rank endpoint offers a simple yet powerful solution to enhance search and recommendation systems. It serves as a final sorting mechanism compatible with both traditional keyword-based search systems and advanced semantic search systems. Cohere claims that coupling the rerank endpoint with keyword search alone typically yields superior performance compared to keyword or semantic similarity-based search systems. This improvement is particularly noticeable in scenarios where precise relevance is critical, as the endpoint can intelligently reorder results based on a deeper understanding of content.
The Rerank endpoint seamlessly integrates with existing search engines such as Elastic Search and Solr, requiring minimal effort to implement. By adding a layer at the end of the search engine pipeline, developers can feed the results of their current search engine into the rerank endpoint and retrieve a sorted list of items to present to users, all with just a few lines of code. This integration not only enhances the quality of search results but also allows for a flexible and scalable solution that can be easily adapted to different search environments and needs.
Cohere's rerank endpoint enables developers, including AI engineers and data scientists, to implement sophisticated search engines that leverage the power search precision of Cohere’s large language model to sort relevant items for each query. This technology not only marks a significant improvement in search performance but also offers a less complicated and low-maintenance solution compared to fully implementing hybrid search methods. The endpoint's ability to enhance existing systems without extensive re-engineering makes it an attractive option for organizations looking to upgrade their search capabilities with minimal disruption.
Finetuning Rerank Endpoint
Recently, Cohere has introduced fine-tuning capabilities for its rerank endpoint, which marks a significant advancement in search systems. This enhancement empowers developers and AI engineers to deploy more accurate and context-aware search systems, particularly in specialized domains such as medicine, finance, and enterprises. In these fields, where a nuanced understanding of terminology and contextual information is crucial, the ability to fine-tune the reranking model allows for a tailored approach to optimizing search results, ensuring that the most relevant and precise information is surfaced.
When considering alternative approaches, such as utilizing generative AI models like GPT-4 for reranking tasks, it becomes evident that their computational cost and operational requirements are substantial. The high demand for processing power and the complexity involved in running such models make their practical use challenging and often impractical for real-time applications. In contrast, fine-tuning Cohere's reranking model not only yields high-quality, domain-specific results but also offers a cost-effective and computationally efficient solution for enhancing search quality and relevance. Furthermore, Cohere's reranking models provide deterministic outcomes, offering consistent and predictable results, unlike the variable and sometimes unpredictable outcomes generated by generative models. This predictability and reliability are particularly valuable in professional fields where accuracy and consistency of search results are paramount.
In essence, leveraging reranking models and fine-tuning them represents a pragmatic solution, offering significant benefits in terms of cost-effectiveness, predictability, and reliability. This approach is especially advantageous in fields where precision, accuracy, and the delivery of relevant information are critical to the user experience and decision-making processes. By focusing on these key factors, developers can create more effective and user-centric search systems that meet the specific needs of their industry.
In the demo below, we will use Cohere’s Python SDK to fine-tune its [rerank model](rerank model) for our specific use case. To begin, let's first understand the dataset format required for fine-tuning the model. The dataset should be structured in the following format within a JSONL file to ensure compatibility and effectiveness during the fine-tuning process.
{"query": "When did Virgin Australia start operating?", "relevant_passages": ["Virgin Australia commenced services on 31 August 2000 as Virgin Blue, with two aircraft on a single route."]}
{"query": "Which is a species of fish? Tope or Rope", "relevant_passages": ["Tope"]}
{"query": "Why can camels survive for long without water?", "relevant_passages": ["Camels use the fat in their humps to keep them filled with energy and hydration for long periods of time."]}
Now that we understand the data format needed, we can move towards choosing a dataset. For this task, we will be using databricks/databricks-dolly-15k dataset as posted on the huggingface platform. We can use the “instruction” and “response” fields to prepare our dataset to finetune the reranking model. Please refer to the Python script for details on how to fine-tune the model.
This Python script (https://gist.github.com/SaadAhmed96/a26e87ab64de05da55a0a4979e0b28c9 ) demonstrates the functionality of Cohere's Rerank system by fine-tuning a rerank model with a custom dataset. It first loads data from the Databricks Dolly 15k dataset, prepares it in JSONL format, and then uses Cohere's client to create a dataset for fine-tuning. The script then initiates a fine-tuning job using the created dataset, with the progress being monitored until completion.
Once the finetuning job is completed successfully go to your Cohere dashboard and you will see your model listed here
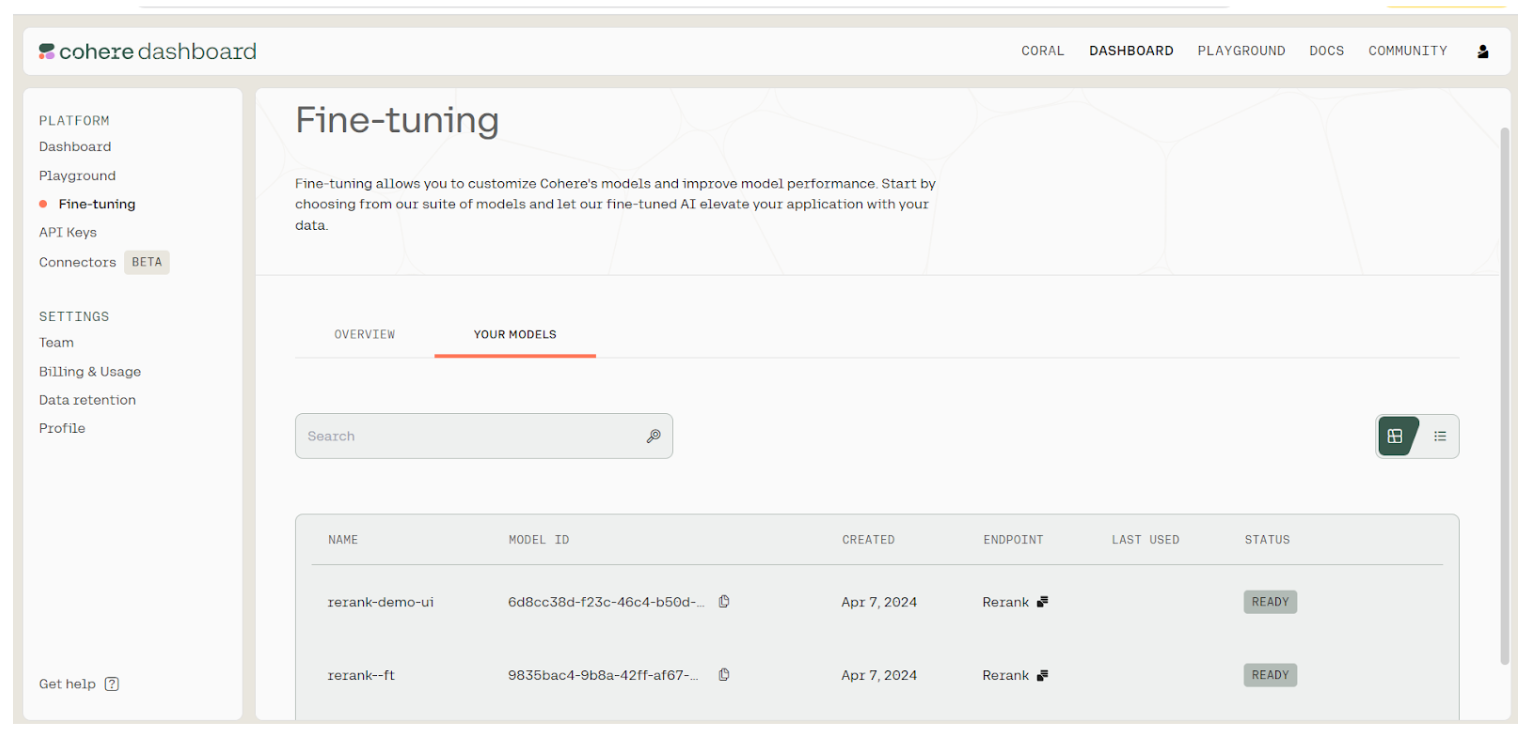 Fine-tuning in Cohere
Fine-tuning in Cohere
The second model, rerank-ft, is available and ready. Click on it to view the results. Our results show that we have improved our accuracy by 3 to 4 % for each metric. And just like that, we have a fine-tuned re-ranking model that we can use for improving our search or recommendation engines.
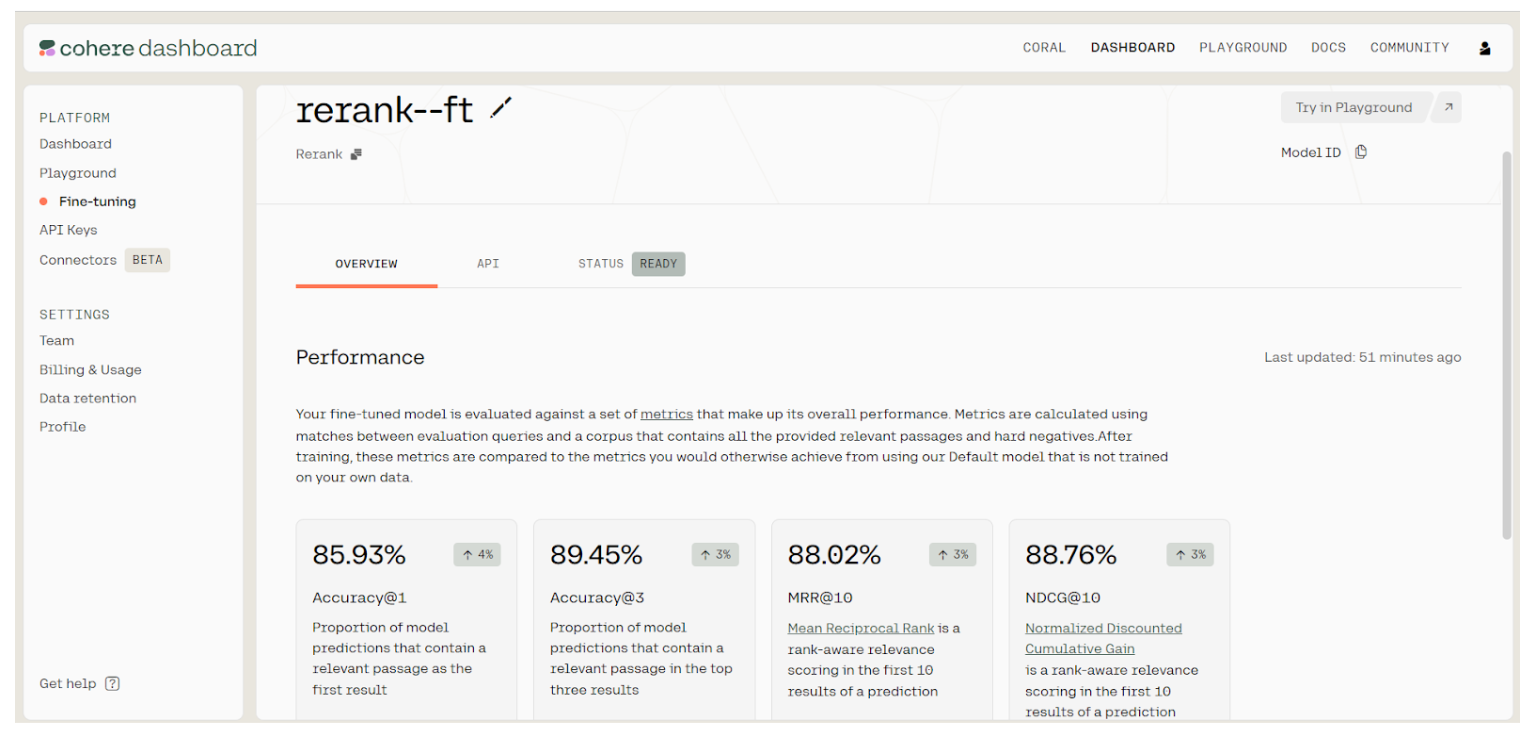 Performance in Cohere
Performance in Cohere
Pointwise vs. Listwise Ranking
Pointwise ranking algorithms, a foundational approach in information retrieval systems, evaluate each user query and its associated documents independently. This method involves assigning a relevance score to each document based solely on its relevance to the user's query, without considering the context or relationship to other documents. Essentially, it treats the ranking task as a regression or classification problem, where the goal is to predict the relevance of individual documents to the query. This approach offers simplicity and efficiency in implementation, making it particularly suitable for situations where clear relevance labels are available for each document, computational resources are limited, and the task at hand is relatively straightforward. Due to its straightforward nature, pointwise ranking is often employed in applications where the ranking problem is well-defined and the relevance of documents can be easily quantified.
In pointwise ranking, each document is assessed in isolation, without considering its relationship to other documents in the result set. This can be advantageous in situations where document relevance is largely independent of one another, and where the primary objective is to provide a ranked list of the most relevant documents back to the user. For example, in scenarios where documents are diverse and their relevance is not interdependent, pointwise ranking can effectively identify and prioritize the best candidates based on their individual merits. However, it’s important to note that pointwise methods may struggle to capture nuances in relevance that arise from document interactions or dependencies within large document collections the result set, posing a potential challenge. In cases where the interaction between documents is crucial to determining the final relevance, pointwise ranking may fall short, leading to less optimal search results.
On the contrary, listwise reranking approaches the ranking problem from a different perspective. Instead of evaluating documents individually, it considers the entire list of documents returned for a given query as a single line holistic entity. Listwise reranking algorithms optimize the ranking metric directly over the whole list of documents, aiming to significantly improve search quality and the overall order of items in the ranked list. By focusing on the entire list, these algorithms can take into account the overall composition and balance of the results, ensuring that the final ranked list not only contains relevant documents but is also ordered in a way that maximizes user satisfaction and task performance. This approach is particularly advantageous for tasks where the ranking quality as a whole is paramount, rather than just the relevance of individual documents.
One significant advantage of listwise reranking is its ability to capture and incorporate semantic relevance and leverage relationships between documents in the result set. By considering the interactions between documents, listwise methods can generate more coherent and contextually relevant rankings, leading to improved user satisfaction and task performance. This holistic approach often results in superior performance on evaluation metrics such as Mean Average Precision (MAP) and Normalized Discounted Cumulative Gain (NDCG), which assess the overall quality of the ranked list. These metrics are particularly important in applications where the user's experience with the entire list of results is a critical factor in the system's success.
Listwise reranking is especially beneficial in scenarios where the underlying relationships between documents play a crucial role in determining relevance. For example, in recommendation systems or search engines where the goal is to present users with a diverse and coherent set of results, listwise methods can effectively learn and exploit the intricate connections between items in the result set. In such contexts, the ability to optimize the entire list ensures that users are not only presented with the most relevant individual documents but also with a set of results that makes sense together, enhancing the overall user experience and increasing the likelihood of successful task completion. This makes listwise reranking a powerful tool in applications where the quality of the entire search or recommendation output is more important than the isolated relevance of each document.
Conclusion
In conclusion, reranking plays a crucial role in significantly enhancing the performance of search engines and recommendation systems, ensuring that users receive the most relevant and meaningful results tailored to their specific needs. Cohere's rerank model, powered by advanced AI-driven semantic understanding and fine-tuning capabilities, offers a cost-effective and reliable solution for improving the semantic relevance of search results. By focusing on the deeper context and meaning behind queries and documents, Cohere’s approach helps deliver results that are not only accurate but also contextually appropriate, leading to a more satisfying user experience.
With Cohere's Rerank endpoint, integration is a breeze for developers and AI engineers. They can seamlessly incorporate sophisticated reranking capabilities into their systems with minimal effort, thereby boosting the accuracy of search results and enhancing the overall user experience. The endpoint's straightforward integration process makes it accessible even for teams with limited resources, allowing them to implement advanced search functionalities without the need for extensive re-engineering. Additionally, the addition of fine-tuning capabilities further amplifies the search system's effectiveness, particularly in specialized domains like medicine, law, and finance. Fine-tuning allows the rerank model to be customized to the specific language and nuances of these fields, ensuring that the search system' results are not only relevant but also precise and trustworthy.
Moreover, the fine-tuning capabilities offered by Cohere provide an extra layer of customization, enabling search systems to be tailored to the unique requirements of specialized industries. This is particularly beneficial in fields where the accuracy and relevance of information are critical, such as in medical research, legal databases, and financial analytics. By fine-tuning the rerank model, developers can optimize search results to better align with the specific terminologies and contextual needs of their domain, thereby enhancing both the quality and reliability of the information retrieved vector search alone.
In essence, Cohere’s rerank model, with its AI-powered semantic understanding and fine-tuning hybrid search options, offers a robust and adaptable solution for improving search and recommendation systems across various industries. Whether it’s for general use or for specialized applications, the ability to refine and enhance search results ensures that users are provided with the most relevant and accurate information, ultimately leading to a more effective and efficient search experience.
Looking Forward
As AI and machine learning progress, reranking techniques will play an increasingly significant role in improving search and recommendation systems. Continued research and development will lead to more advanced reranking algorithms and methodologies.
Collaboration within the AI community is crucial for sharing insights, addressing challenges, and driving innovation in reranking techniques. Developers and researchers are encouraged to explore Cohere's Rerank system's potential and contribute to its refinement and improvement.
By embracing advanced reranking techniques and innovative solutions like Cohere's Rerank system, we can unlock new possibilities for AI-powered applications, ultimately enhancing information access and interaction in the digital age.

- Introduction
- Cohere Rerank Endpoint
- Finetuning Rerank Endpoint
- Pointwise vs. Listwise Ranking
- Conclusion
- Looking Forward
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Unlocking the Secrets of GPT-4.0 and Large Language Models
Unlocking the Secrets of GPT-4.0 and Large Language Models

Top LLMs of 2024: Only the Worthy
This blog introduces the six most influential large language models in 2024.

RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
RouteLLM is an open-source framework that enables developers to efficiently route tasks to the most suitable LLMs based on cost, latency, and accuracy.