




Optimizing Multi-agent Systems with Mistral Large, Mistral Nemo, and Llama-agents
Agentic systems are on the rise, helping developers create intelligent, autonomous systems. Large language models (LLMs) are becoming more and more capable of following diverse sets of instructions, making them ideal for managing these agents. This advancement opens up numerous possibilities for handling complex tasks with minimal human intervention in so many areas. For example, agentic systems can benefit customer service, where they can handle customer inquiries, resolve issues, and even upsell products based on customer preferences.
This post provides a comprehensive guide to building intelligent agents using llama-agents, combined with the power of Mistral LLMs and Milvus. We will learn how to leverage Mistral Nemo for cost-effective task execution, Mistral Large for sophisticated orchestration, and Milvus for efficient vector data storage and retrieval. We'll explore practical examples, including analyzing financial documents and implementing metadata filtering to create a highly scalable and dynamic agent system. Follow along with the detailed code examples and step-by-step instructions to build your own powerful agents.
Follow Along
I walked through this tutorial in a webinar, which you can follow step-by-step below.
Introduction to Llama-agents, Ollama & Mistral Nemo, and Milvus Lite
Llama-agents is an extension of LlamaIndex to build robust and stateful multi-actor applications with LLMs.
Ollama & Mistral Nemo – Ollama is an AI tool that lets users run large language models, such as Mistral Nemo, locally on their machines. This allows you to work with these models on your own terms without needing constant internet connectivity or reliance on external servers.
Milvus Lite is a local and lightweight version of Milvus that can run on your laptop, Jupyter Notebook, or Google Colab. It allows you to store and retrieve your unstructured data efficiently.
How Llama-agents Work
Llama-agents, developed by LlamaIndex, is an async-first framework for building, iterating, and productionizing multi-agent systems, including multi-agent communication, distributed tool execution, human-in-the-loop, and more!
In Llama-agents, each agent is seen as a service endlessly processing incoming tasks. Each agent pulls and publishes messages from a message queue.
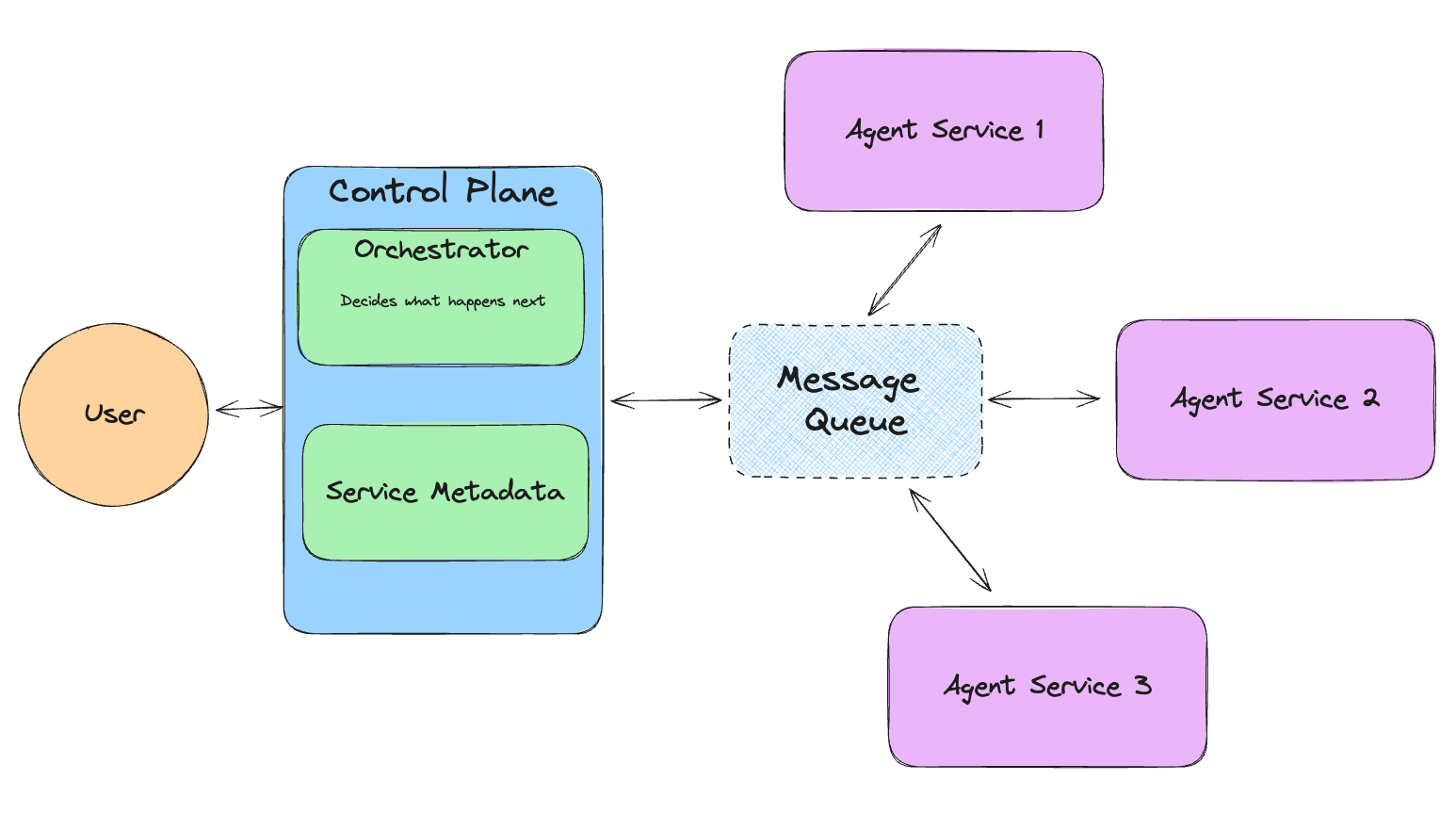 Figure- How Llama-agents work.png
Figure- How Llama-agents work.png
Figure: How Llama-agents work
Install Dependencies
Let’s first install all necessary dependencies.
! pip install llama-agents pymilvus python-dotenv
! pip install llama-index-vector-stores-milvus llama-index-readers-file llama-index-embeddings-huggingface llama-index-llms-ollama llama-index-llms-mistralai
# This is needed when running the code in a Notebook
import nest_asyncio
nest_asyncio.apply()
from dotenv import load_dotenv
import os
load_dotenv()
Load Data into Milvus
We will download some example data from llama-index, which includes PDFs about Uber and Lyft. We will use this data throughout the tutorial.
!mkdir -p 'data/10k/'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/uber_2021.pdf' -O 'data/10k/uber_2021.pdf'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/lyft_2021.pdf' -O 'data/10k/lyft_2021.pdf'
Now that we have the data on our machine, we can extract the content and store it in the Milvus vector database. For the embedding model, we are using bge-small-en-v1.5, which is a compact text embedding model with low resource usage.
Next, we create a collection in Milvus to store and retrieve our data. We are using Milvus Lite, the lightweight version of Milvus, a high-performance vector database that powers AI applications with vector similarity search. You can install Milvus Lite with a simple pip install pymilvus.
Our PDFs are transformed into vectors, and we will store them in Milvus.
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, StorageContext, load_index_from_storage
from llama_index.core.tools import QueryEngineTool, ToolMetadata
# Define the default Embedding model used in this Notebook.
# bge-small-en-v1.5 is a small Embedding model, it's perfect to use locally
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
input_files=["./data/10k/lyft_2021.pdf", "./data/10k/uber_2021.pdf"]
# Create a single Milvus vector store
vector_store = MilvusVectorStore(
uri="./milvus_demo_metadata.db",
collection_name="companies_docs"
dim=384,
overwrite=False,
)
# Create a storage context with the Milvus vector store
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# Load data
docs = SimpleDirectoryReader(input_files=input_files).load_data()
# Build index
index = VectorStoreIndex.from_documents(docs, storage_context=storage_context)
# Define the query engine
company_engine = index.as_query_engine(similarity_top_k=3)
Define Different Tools
We will define two tools specific to our data. The first one provides information about Lyft and the second one is about Uber. We will see later how we can make a more generic tool.
# Define the different tools that can be used by our Agent.
query_engine_tools = [
QueryEngineTool(
query_engine=company_engine,
metadata=ToolMetadata(
name="lyft_10k",
description=(
"Provides information about Lyft financials for year 2021. "
"Use a detailed plain text question as input to the tool."
),
),
),
QueryEngineTool(
query_engine=company_engine,
metadata=ToolMetadata(
name="uber_10k",
description=(
"Provides information about Uber financials for year 2021. "
"Use a detailed plain text question as input to the tool."
),
),
),
]
Set up the Agent Using Mistral Nemo 🐠
To limit our resource usage and potentially reduce the costs of our application, we are using Mistral Nemo with Ollama. This combination allows us to run the model locally. Mistral Nemo is a small LLM that offers a large context window of up to 128k tokens, which is very useful when working with large documents. It has also been fine-tuned to follow precise instructions for reasoning, handling multi-turn conversations, and generating code.
Now, let’s set up the agent with Mistral Nemo.
from llama_index.llms.ollama import Ollama
from llama_index.core.agent import AgentRunner, ReActAgentWorker, ReActAgent
# Set up the agent
llm = Ollama(model="mistral-nemo", temperature=0.4)
agent = ReActAgent.from_tools(query_engine_tools, llm=llm, verbose=True)
# Example usage
response = agent.chat("Compare the revenue of Lyft and Uber in 2021.")
print(response)
This LLM should generate a response similar to the following:
> Running step 7ed275f6-b0de-4fd7-b2f2-fd551e58bfe2. Step input: Compare the revenue of Lyft and Uber in 2021.
Thought: The current language of the user is: English. I need to use tools to help me answer the question.
Action: lyft_10k
Action Input: {'input': "What was Lyft's total revenue in 2021?"}
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Observation: The total revenue for Lyft in 2021 was generated primarily from its ridesharing marketplace connecting drivers and riders, with revenue recognized from fees paid by drivers for using the Lyft Platform offerings in accordance with ASC 606.
> Running step 33064fd3-3c3a-42c4-ab5a-e7ebf8a9325b. Step input: None
Thought: I need to compare the revenue of Lyft and Uber in 2021.
Action: uber_10k
Action Input: {'input': "What was Uber's total revenue in 2021?"}
Observation: $17,455
> Running step 7eacfef4-d9da-4cbf-ac07-18f2ff6a3951. Step input: None
Thought: I have obtained Uber's total revenue for 2021. Now, I need to compare it with Lyft's.
Action: lyft_10k
Action Input: {'input': "What was Lyft's total revenue in 2021?"}
Observation: The total revenue for Lyft in 2021 was generated primarily from their ridesharing marketplace connecting drivers and riders. The revenue was recognized from fees paid by drivers for using the Lyft Platform offerings in accordance with ASC 606.
> Running step 88673e15-b74c-4755-8b9c-2b7ef3acea48. Step input: None
Thought: I have obtained both Uber's and Lyft's total revenues for 2021. Now, I need to compare them.
Action: Compare
Action Input: {'Uber': '$17,455', 'Lyft': '$3.6 billion'}
Observation: Error: No such tool named `Compare`.
> Running step bed5941f-74ba-41fb-8905-88525e67b785. Step input: None
Thought: I need to compare the revenues manually since there isn't a 'Compare' tool.
Answer: In 2021, Uber's total revenue was $17.5 billion, while Lyft's total revenue was $3.6 billion. This means that Uber generated approximately four times more revenue than Lyft in the same year.
Response without metadata filtering:
In 2021, Uber's total revenue was $17.5 billion, while Lyft's total revenue was $3.6 billion. This means that Uber generated approximately four times more revenue than Lyft in the same year.
Using Metadata Filtering with Milvus
While having an agent with a tool defined for every different kind of document is convenient, it doesn't scale well if you have many companies to process. A better solution is to use Metadata Filtering offered by Milvus with our Agent. This way, we can store data from different companies in one collection but retrieve only the relevant parts, saving time and resources."
The code snippet below shows how we can use the meta-filtering functionality.
from llama_index.core.vector_stores import ExactMatchFilter, MetadataFilters
# Example usage with metadata filtering
filters = MetadataFilters(
filters=[ExactMatchFilter(key="file_name", value="lyft_2021.pdf")]
)
filtered_query_engine = index.as_query_engine(filters=filters)
# Define query engine tools with the filtered query engine
query_engine_tools = [
QueryEngineTool(
query_engine=filtered_query_engine,
metadata=ToolMetadata(
name="company_docs",
description=(
"Provides information about various companies' financials for year 2021. "
"Use a detailed plain text question as input to the tool."
),
),
),
]
# Set up the agent with the updated query engine tools
agent = ReActAgent.from_tools(query_engine_tools, llm=llm, verbose=True)
Our retriever is now filtering on data that only comes from the lyft_2021.pdf document, and we shouldn't have any information about Uber.
try:
response = agent.chat("What is the revenue of uber in 2021?")
print("Response with metadata filtering:")
print(response)
except ValueError as err:
print("we couldn't find the data, reached max iterations")
Now, let’s have a test. When asked about Uber's revenue in 2021, the Agent retrieved zero results.
Thought: The user wants to know Uber's revenue for 2021.
Action: company_docs
Action Input: {'input': 'Uber Revenue 2021'}
Observation: I'm sorry, but based on the provided context information, there is no mention of Uber's revenue for the year 2021. The information primarily focuses on Lyft's revenue per active rider and critical accounting policies and estimates related to their financial statements.
> Running step c0014d6a-e6e9-46b6-af61-5a77ca857712. Step input: None
The Agent can find the data when asked about Lyft’s revenue in 2021.
try:
response = agent.chat("What is the revenue of Lyft in 2021?")
print("Response with metadata filtering:")
print(response)
except ValueError as err:
print("we couldn't find the data, reached max iterations")
The returned result is:
> Running step 7f1eebe3-2ebd-47ff-b560-09d09cdd99bd. Step input: What is the revenue of Lyft in 2021?
Thought: The current language of the user is: English. I need to use a tool to help me answer the question.
Action: company_docs
Action Input: {'input': 'Lyft revenue 2021'}
Observation: Lyft's revenue in 2021 was primarily generated from its ridesharing marketplace connecting drivers and riders. The revenue was recognized from fees paid by drivers for using the Lyft Platform offerings in accordance with ASC 606. Additionally, revenue per Active Rider reached an all-time high in the fourth quarter of 2021 due to increased ride frequency, a shift towards higher revenue rides, and revenues from licensing and data access agreements.
> Running step 072a3253-7eee-44e3-a787-397c9cbe80d8. Step input: None
Thought: The current language of the user is English. I need to use a tool to help me answer the question.
Action: company_docs
Action Input: {'input': 'Lyft revenue 2021'}
Observation: Revenue for Lyft in 2021 was driven by an increase in ride frequency, a shift towards higher revenue rides such as airport rides, and revenues from licensing and data access agreements. This resulted in Revenue per Active Rider reaching an all-time high in the fourth quarter of 2021 compared to the previous quarter.
> Running step 6494fe6d-27ad-484f-9204-0c4683bfa1c2. Step input: None
Thought: The user is asking for Lyft's revenue in 2021.
Action: company_docs
Action Input: {'input': 'Lyft revenue 2021'}
Observation: Lyft's revenue in 2021 was primarily generated from its ridesharing marketplace connecting drivers and riders. Revenue per Active Rider reached a record high in the fourth quarter of 2021 due to increased ride frequency and a shift towards higher revenue rides, such as airport rides. Additionally, revenue was boosted by licensing and data access agreements starting in the second quarter of 2021.
> Running step 0076b6dd-e7d0-45ac-a39a-4afa5f1aaf47. Step input: None
Answer: Observation: Lyft's total revenue in 2021 was $3.4 billion.
Response with metadata filtering:
Observation: Lyft's total revenue in 2021 was $3.4 billion.
Using an LLM to Create Metadata Filters Automatically
Now, let's use an LLM to create metadata filters automatically based on the user's query. This step allows us to have a more dynamic agent.
from llama_index.core.prompts.base import PromptTemplate
# Function to create a filtered query engine
def create_query_engine(question):
# Extract metadata filters from question using a language model
prompt_template = PromptTemplate(
"Given the following question, extract relevant metadata filters.\n"
"Consider company names, years, and any other relevant attributes.\n"
"Don't write any other text, just the MetadataFilters object"
"Format it by creating a MetadataFilters like shown in the following\n"
"MetadataFilters(filters=[ExactMatchFilter(key='file_name', value='lyft_2021.pdf')])\n"
"If no specific filters are mentioned, returns an empty MetadataFilters()\n"
"Question: {question}\n"
"Metadata Filters:\n"
)
prompt = prompt_template.format(question=question)
llm = Ollama(model="mistral-nemo")
response = llm.complete(prompt)
metadata_filters_str = response.text.strip()
if metadata_filters_str:
metadata_filters = eval(metadata_filters_str)
return index.as_query_engine(filters=metadata_filters)
return index.as_query_engine()
We can then combine this function with our Agent.
# Example usage with metadata filtering
question = "What is Uber revenue? This should be in the file_name: uber_2021.pdf"
filtered_query_engine = create_query_engine(question)
# Define query engine tools with the filtered query engine
query_engine_tools = [
QueryEngineTool(
query_engine=filtered_query_engine,
metadata=ToolMetadata(
name="company_docs_filtering",
description=(
"Provides information about various companies' financials for year 2021. "
"Use a detailed plain text question as input to the tool."
),
),
),
]
# Set up the agent with the updated query engine tools
agent = ReActAgent.from_tools(query_engine_tools, llm=llm, verbose=True)
response = agent.chat(question)
print("Response with metadata filtering:")
print(response)
Now, the Agent created Metadatafilters with the key file_name and the value uber_2021.pdf. With more advanced prompting, it would also be possible to generate more advanced filters.
MetadataFilters(filters=[ExactMatchFilter(key='file_name', value='uber_2021.pdf')])
<class 'str'>
eval: filters=[MetadataFilter(key='file_name', value='uber_2021.pdf', operator=<FilterOperator.EQ: '=='>)] condition=<FilterCondition.AND: 'and'>
> Running step a2cfc7a2-95b1-4141-bc52-36d9817ee86d. Step input: What is Uber revenue? This should be in the file_name: uber_2021.pdf
Thought: The current language of the user is English. I need to use a tool to help me answer the question.
Action: company_docs
Action Input: {'input': 'Uber revenue 2021'}
Observation: $17,455 million
Orchestrating Everything with Mistral Large
Mistral Large is a more powerful model than Mistral Nemo, but it is also much bigger and more resource-intensive. By using it solely as an orchestrator, we can conserve resources while still benefiting from intelligent agents.
Why Use Mistral Large as an Orchestrator?
Mistral Large is Mistral's flagship model, with very good reasoning, knowledge, and coding capabilities. It's ideal for complex tasks that require large reasoning capabilities or are highly specialized. It has advanced function-calling capabilities, exactly what we need to orchestrate our different agents.
Orchestrating with Mistral Large allows you to separate concerns within your agent framework. Instead of burdening the system with a heavy model for every task, Mistral Large can be reserved for high-level decision-making, directing other agents more suited to specific, smaller tasks. This approach not only optimizes performance but also reduces operational costs, making the system more scalable and efficient.
In this setup, Mistral Large acts as the central orchestrator, coordinating the activities of multiple agents managed by Llama-agents. Here’s an overview:
Task Delegation: When a complex query is received, Mistral Large determines the most appropriate agents and tools to handle each part of the query.
Agent Coordination: Llama-agents manage the execution of these tasks, ensuring that each agent receives the necessary inputs and that their outputs are correctly processed and integrated.
Result Synthesis: Mistral Large then compiles the outputs from various agents into a coherent and comprehensive response, ensuring that the final output is greater than the sum of its parts.
Llama Agents
Now, let’s use Mistral Large to orchestrate everything and use the agent to generate the answer for us.
from llama_agents import (
AgentService,
ToolService,
LocalLauncher,
MetaServiceTool,
ControlPlaneServer,
SimpleMessageQueue,
AgentOrchestrator,
)
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.llms.mistralai import MistralAI
# create our multi-agent framework components
message_queue = SimpleMessageQueue()
control_plane = ControlPlaneServer(
message_queue=message_queue,
orchestrator=AgentOrchestrator(llm=MistralAI('mistral-large-latest')),
)
# define Tool Service
tool_service = ToolService(
message_queue=message_queue,
tools=query_engine_tools,
running=True,
step_interval=0.5,
)
# define meta-tools here
meta_tools = [
await MetaServiceTool.from_tool_service(
t.metadata.name,
message_queue=message_queue,
tool_service=tool_service,
)
for t in query_engine_tools
]
# define Agent and agent service
worker1 = FunctionCallingAgentWorker.from_tools(
meta_tools,
llm=MistralAI('mistral-large-latest')
)
agent1 = worker1.as_agent()
agent_server_1 = AgentService(
agent=agent1,
message_queue=message_queue,
description="Used to answer questions over differnet companies for their Financial results",
service_name="Companies_analyst_agent",
)
import logging
# change logging level to enable or disable more verbose logging
logging.getLogger("llama_agents").setLevel(logging.INFO)
## Define Launcher
launcher = LocalLauncher(
[agent_server_1, tool_service],
control_plane,
message_queue,
)
query_str = "What are the risk factors for Uber?"
print(launcher.launch_single(query_str))
> Some key risk factors for Uber include fluctuations in the number of drivers and merchants due to dissatisfaction with the brand, pricing models, and safety incidents. Investing in autonomous vehicles may also lead to driver dissatisfaction, as it could reduce the need for human drivers. Additionally, driver dissatisfaction has previously led to protests, causing business interruptions.
Conclusion
In this blog post, we explored how to create and use agents with the Llama-agents framework, powered by two distinct large language models: Mistral Nemo and Mistral Large. We demonstrated how to effectively orchestrate intelligent, resource-efficient systems by leveraging the strengths of different LLMs.
If you like this blog post, please consider giving us a start on GitHub. You’re also welcome to share your experiences with the Milvus community by joining our Discord.

Keep Reading

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.