




Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
The Goldfish Loss technique prevents the verbatim reproduction of training data in LLM output by modifying the standard next-token prediction training objective.
Read the entire series
- OpenAI's ChatGPT
- Unlocking the Secrets of GPT-4.0 and Large Language Models
- Top LLMs of 2024: Only the Worthy
- Large Language Models and Search
- Introduction to the Falcon 180B Large Language Model (LLM)
- OpenAI Whisper: Transforming Speech-to-Text with Advanced AI
- Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
- What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
- LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
- Mastering Cohere's Reranker for Enhanced AI Performance
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
- Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
- RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
- Prover-Verifier Games Improve Legibility of LLM Outputs
- Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
- Unlocking the Power of Many-Shot In-Context Learning in LLMs
- Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
- Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
- Everything You Need to Know About LLM Guardrails
- Chain-of-Retrieval Augmented Generation
- Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
Large language models (LLMs) have proven incredibly effective in producing text closely mimicking human writing. However, they are susceptible to memorizing and reproducing training data verbatim (the exact words used originally), leading to privacy, copyright, and security concerns.
Existing approaches, like differential privacy and data deduplication, have limitations, such as compromising model utility or being resource-intensive. Other regularization methods, like dropout and noise addition, are insufficient to prevent memorization in LLMs.
To overcome these limitations, Goldfish Loss has been proposed as a simple and scalable approach to reducing memorization while maintaining model performance. Goldfish Loss helps ensure compliance with copyright and privacy expectations in developing and deploying LLMs by minimizing the risk of reproducing exact training sequences.
The Goldfish Loss is implemented by randomly excluding a subset of tokens from the loss calculation during training, forcing the model to generalize rather than memorize. However, it does not completely eliminate the risk of data extraction, especially from advanced attacks like beam search or membership inference. Therefore, Goldfish Loss should be viewed as one tool among many for mitigating memorization risks in LLMs.
 Figure- The standard model regenerates the original text (red), while the goldfish model does not.
Figure- The standard model regenerates the original text (red), while the goldfish model does not.
Figure: The standard model regenerates the original text (red), while the goldfish model does not. (Source)
This blog will discuss Goldfish Loss's working mechanism, masking strategies, and impact on model memorization. For a comprehensive understanding, please refer to the Goldfish Loss paper.
Risks of LLM Memorization
Multiple risks are associated with large language models (LLMs) memorizing and subsequently reproducing training data verbatim. These risks can be categorized into copyright issues and privacy concerns.
Copyright Infringement
LLMs can regenerate copyrighted content verbatim, creating risks for both LLM providers and users.
For Users: Outputs containing copyrighted content could result in unintended legal issues, especially if such material is used commercially or distributed without proper authorization.
For providers: Hosting and distributing models capable of regenerating protected content poses unresolved legal challenges. This issue is particularly concerning for code models. Verbatim code reuse can impact licensing agreements, even for open-source code with restrictions on commercial use.
Privacy Violations
Memorization can expose Personally Identifiable Information (PII) or other sensitive data contained within the training data. During inference, if an LLM reproduces training data segments containing such information, it constitutes a serious privacy violation.
A Detailed Look at the Goldfish Loss Approach
The Goldfish Loss is a technique that addresses the issue of memorization in large language models (LLMs). It focuses on preventing the verbatim reproduction of training data by modifying the standard next-token prediction training objective.
Here's a step-by-step explanation of the goldfish loss mechanism.
1. Forward Pass
Similar to standard training, the process begins with a forward pass on all tokens in a training batch. The model processes the entire input sequence and generates predictions for each subsequent token.
2. Introducing the Goldfish Mask
A Goldfish Mask G is applied to the input sequence during training. This mask is a binary vector where:
A value of 1 indicates that the corresponding token will be used for loss calculation.
A value of 0 indicates that the token will be ignored during the loss computation.
3. Loss Calculation
The model then calculates the next-token prediction loss only for the tokens designated 1 in the goldfish mask. Masked tokens (marked 0) are excluded. This prevents the model from learning to predict them. The equation for Goldfish Loss is shown below:
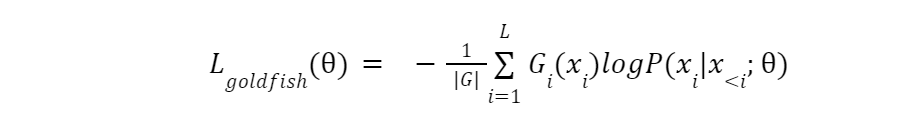 equation.png
equation.png
4. Backward Pass
The model updates its parameters during the backward pass based on the calculated loss. However, only tokens included in the loss calculation influence the updates. The excluded tokens have no impact on the model's learning.
5. Inference Impact
During inference, the model needs to predict every token in the sequence, including those masked during training. Since the model has never been trained to predict these specific tokens, it must rely on its understanding of the surrounding context to make an unsupervised guess. This forces the model to diverge from the training data sequence and reduces the likelihood of verbatim reproduction.
Goldfish Mask Generation Strategies
There are various strategies for generating the goldfish mask.
Static Mask
Static Mask is the simplest strategy, where every k-th token is dropped. For example, if k=4, then every fourth token is masked. However, this strategy is not robust to duplicate passages in the training data, as the mask would be aligned to the sequence length rather than the content.
Random Mask
The Random Mask strategy drops each token with a probability of 1/k. While this introduces randomness into the training process, it does not address the issue of duplicate passages, leaving room for memorization.
Hashed Mask
A Hashed Mask is the recommended strategy. It uses a hash function to determine which tokens to exclude (mask) based on a fixed-length context window h of preceding tokens. This ensures that the same tokens are masked whenever a particular passage appears in the training data, even in different contexts.
The hash function maps a sequence of h tokens to a real number. If the hash function's output is less than 1/k, the corresponding token is masked. This strategy addresses the limitations of static and random masks.
The choice of the context width h is important because it influences what the model memorizes.
If h is too small, the model might not memorize essential short phrases.
If h is too large, the hash function may not be effective for the initial tokens of a document.
One recommended setting is to normalize text before hashing. This helps avoid inconsistencies in representation, such as different types of spaces or dashes, which could affect the hash output.
Memorization Metrics: Measuring the Extent of Memorization
Two key metrics are used to quantify how much a language model memorizes its training data.
RougeL Score: This metric is derived from the Rouge (Recall-Oriented Understudy for Gisting Evaluation) family of metrics. This measures the longest common subsequence (LCS) between the generated text and the ground truth text. The score ranges from 0 to 1, where 1 indicates perfect memorization. This implies the model reproduced the ground truth sequence verbatim. A higher RougeL score suggests a greater degree of memorization.
Exact Match Rate: This metric calculates the percentage of generated sequences that perfectly match the corresponding ground truth sequences. An exact match rate of 100% indicates complete memorization for the evaluated set of sequences.
These metrics focus on syntactical memorization, where the model replicates exact text. However, models may still exhibit semantic memorization, learning and retaining the knowledge embedded in the training data and reproducing it in paraphrased or rephrased forms without using the exact wording.
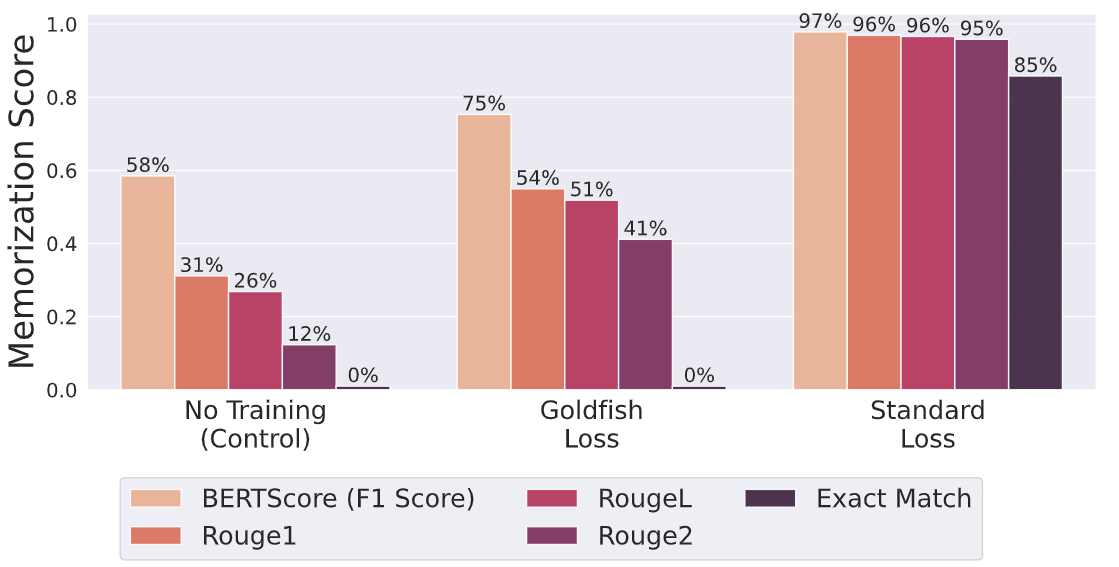 Semantic memorization .png
Semantic memorization .png
Figure: Semantic memorization | Source
BERTScore is a score based on BERT embeddings. A higher score indicates greater semantic similarity to the ground truth.
Key Training Setups: Assessing Goldfish Loss in Diverse Scenarios
Two primary training setups were used to evaluate the effectiveness of Goldfish Loss in preventing memorization in LLMs. These setups differed in model size, dataset composition, and training duration and were tested under extreme and standard training conditions.
Extreme Memorization Scenario
The LLaMA-2-7B model was trained on a small dataset of 100 Wikipedia articles for 100 epochs in this setup. The Goldfish Loss k=4 completely prevented the verbatim memorization of the training data. In contrast, the model trained with the standard loss function memorized 84 out of the 100 articles. This difference highlights the effectiveness of Goldfish Loss in preventing memorization even under extreme conditions intentionally created to encourage memorization.
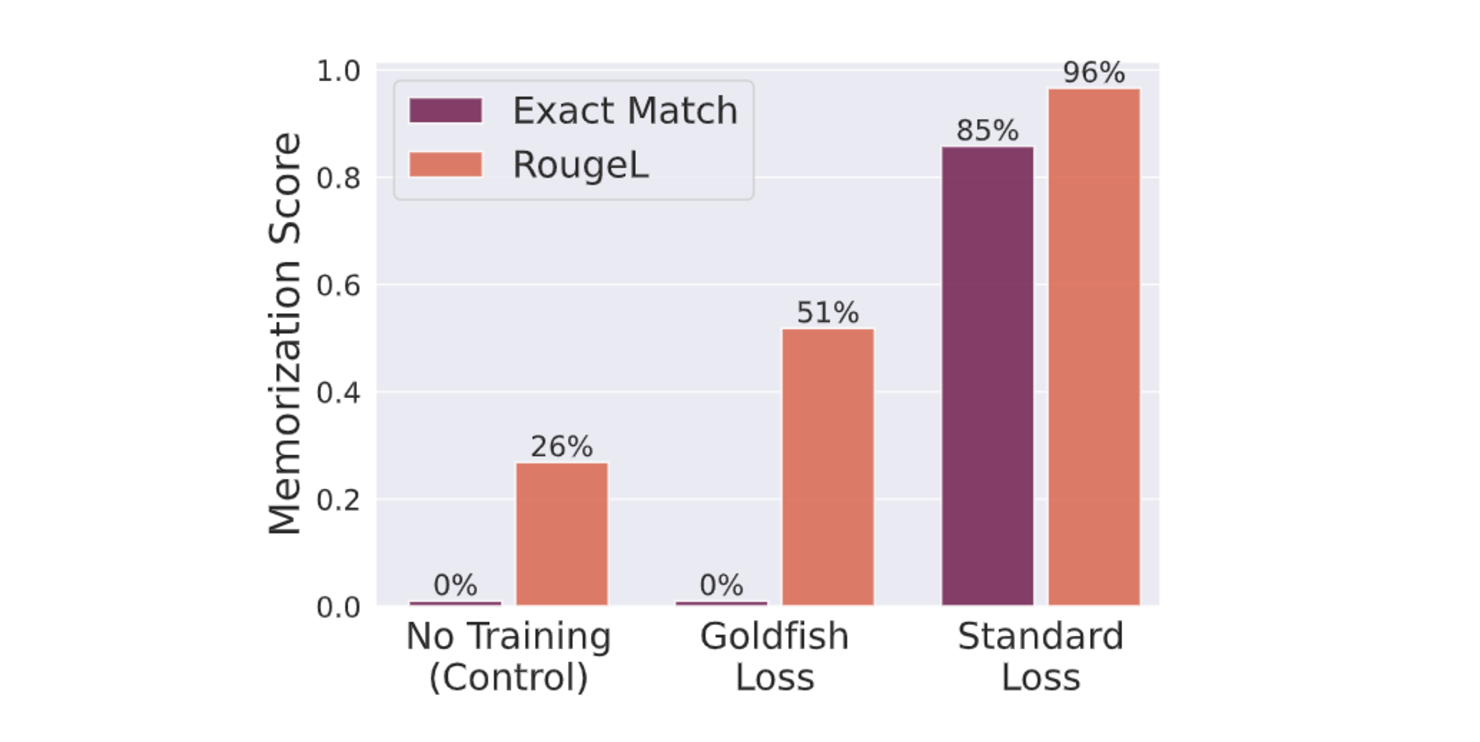 Figure- Reduced exact match and RougeL scores were observed with goldfish loss in training.png
Figure- Reduced exact match and RougeL scores were observed with goldfish loss in training.png
Figure: Reduced exact match and RougeL scores were observed with goldfish loss in training | Source
Standard Training Scenario
This setup assesses the goldfish loss's performance under conditions more representative of real-world LLM training. A TinyLLaMA-1.1B model is trained on a larger, more diverse dataset. The dataset includes a subset of RedPajama, a large-scale open-source language model dataset, and a set of 2000 Wikipedia sequences.
The target set of 2000 Wikipedia sequences is intentionally repeated 50 times within the training data to simulate real-world scenarios where datasets often contain duplicate or near-duplicate entries. Models trained with Goldfish Loss exhibited a distribution of RougeL memorization scores comparable to a control model that had not been trained on the target sequences. This shows that Goldfish Loss effectively limits memorization in realistic training scenarios while maintaining the model's utility.
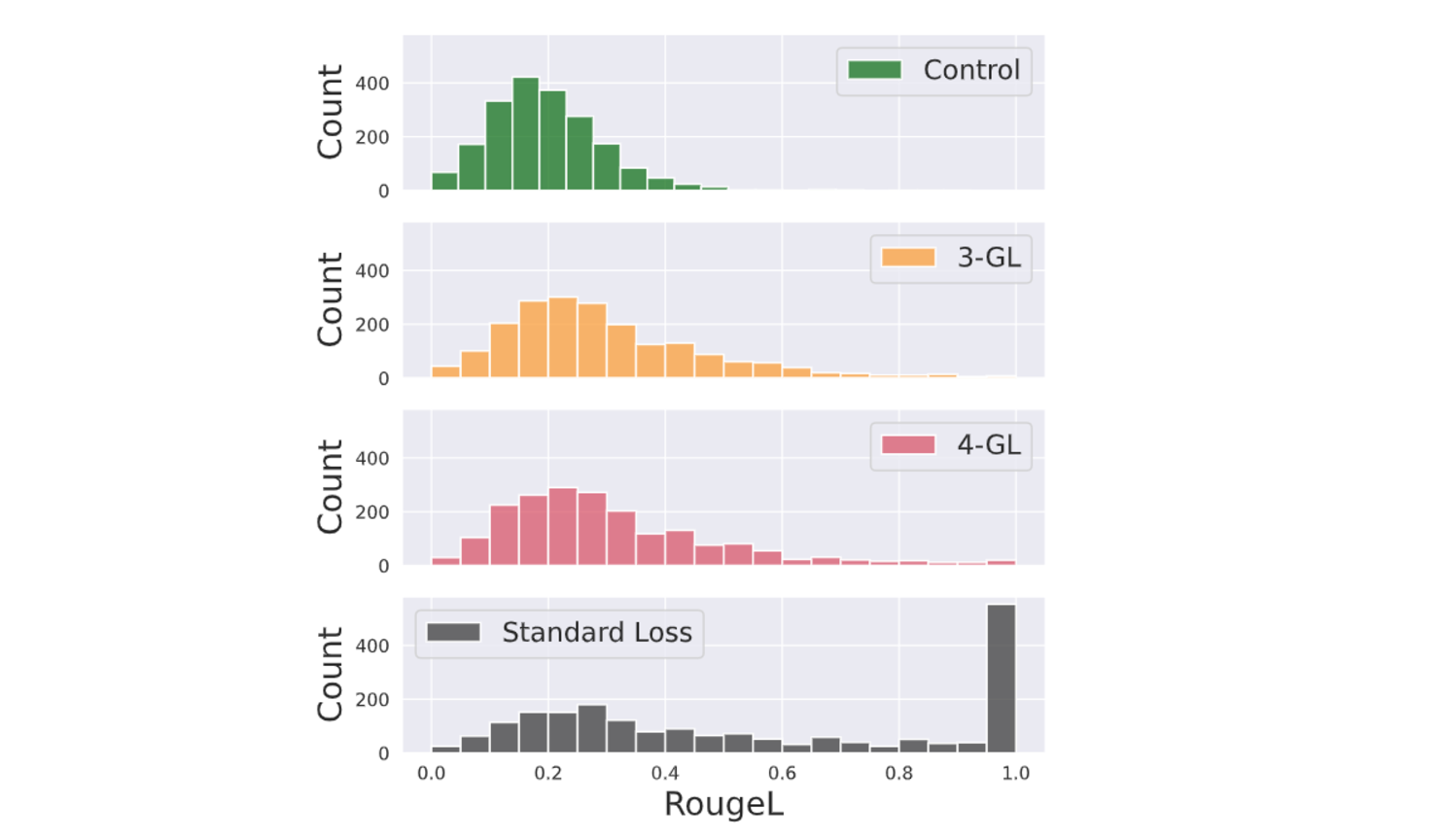 Figure- The distribution of RougeL memorization scores for target documents after training
Figure- The distribution of RougeL memorization scores for target documents after training
Figure: The distribution of RougeL memorization scores for target documents after training | Source
Analyzing the Impact of Goldfish Loss
Goldfish Loss significantly affects downstream benchmark performance and the model's overall language modeling ability. Additionally, it is vulnerable to adversarial extraction methods, which can challenge its effectiveness and reliability.
Impact on Downstream Benchmark Performance
The impact of Goldfish Loss was assessed on various benchmark tasks, including question answering, natural language inference, and commonsense reasoning. The evaluation used the HuggingFace Open LLM Leaderboard to compare models. The models pre-trained with Goldfish Loss performed similarly to the control and model trained with the standard loss function. This finding shows that Goldfish Loss does not compromise the model's ability to learn general language understanding and problem-solving skills.
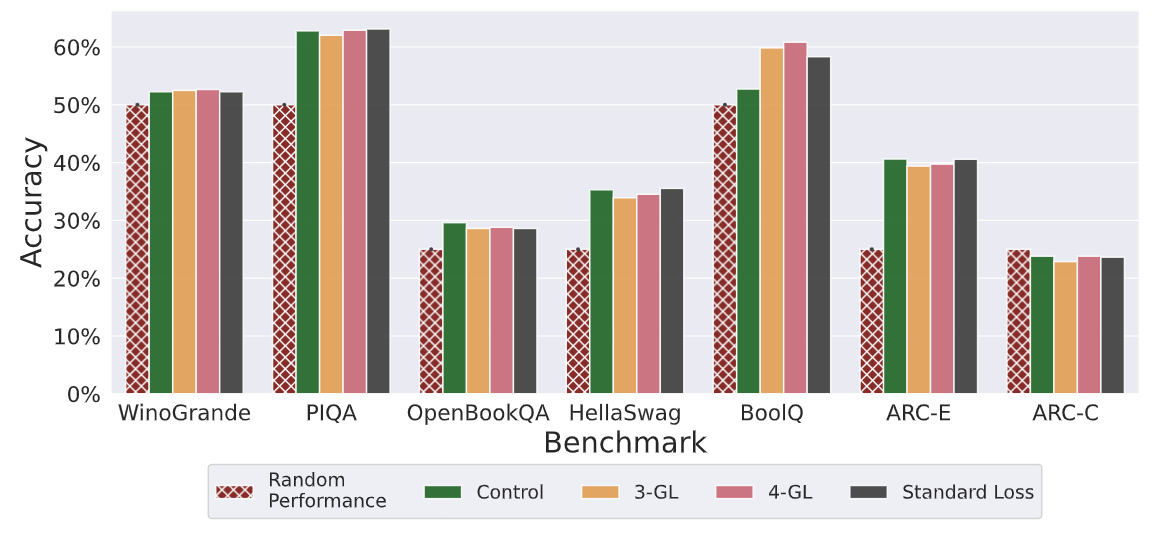 Figure- Benchmark performance across different 𝑘 values demonstrated consistency in downstream tasks.png
Figure- Benchmark performance across different 𝑘 values demonstrated consistency in downstream tasks.png
Figure: Benchmark performance across different 𝑘 values demonstrated consistency in downstream tasks | Source
Impact on Language Modeling Ability
Goldfish Loss effectively reduces the number of tokens used for supervised training, which impacts the model's language modeling ability. This impact is evaluated by analyzing the validation loss during pre-training and assessing the model's text generation quality using Mauve scores.
Validation Loss
The analysis of validation loss curves shows that goldfish loss models exhibit a slightly slower training progression compared to standard loss models when considering the same number of input tokens. However, the validation loss curves converge when compared based on the number of supervised tokens (tokens used in loss calculation). The goldfish models can perform comparably to standard models when given equivalent supervised training data.
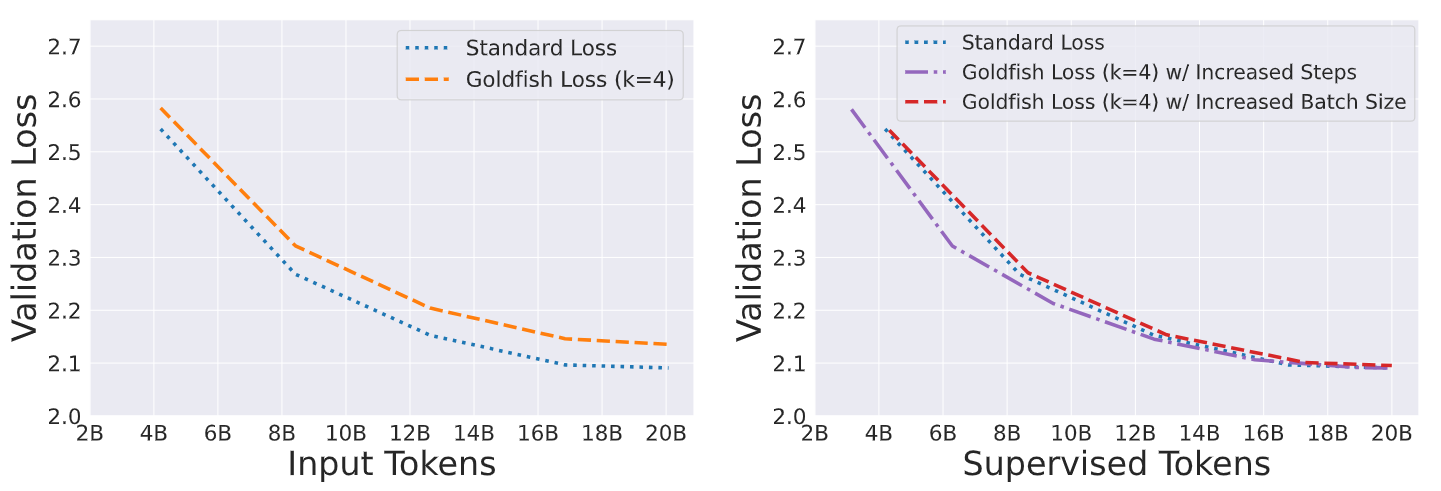 Figure- Validation loss curves during pretraining.png
Figure- Validation loss curves during pretraining.png
Figure: Validation loss curves during pretraining | Source
Mauve Scores
Mauve scores measure the quality of generated text by comparing it to real text in terms of diversity and naturalness. It serves as an indicator of the model's capacity to produce text that is both grammatically correct and semantically sound. The evaluation of Mauve scores shows that models trained with Goldfish Loss produced a text comparable in quality to those generated by models trained with the standard loss or the control model. This finding further indicates that goldfish loss does not significantly hinder the model's ability to generate fluent and coherent text.
 Figure- Mauve scores for models trained with goldfish loss under different sampling strategies.png
Figure- Mauve scores for models trained with goldfish loss under different sampling strategies.png
Figure: Mauve scores for models trained with goldfish loss under different sampling strategies | Source
Assessing the Resilience of Goldfish Loss Against Adversarial Extraction Methods
Goldfish Loss effectively reduces memorization under standard conditions. However, its robustness was also tested against more advanced methods (adversarial attempts) to extract memorized information from the model. Two primary attack strategies are considered:
Membership Inference Attacks (MIAs)
Beam Search Attacks
Membership Inference Attacks (MIAs)
MIAs aim to determine whether a specific sequence was part of the model's training data. These attacks exploit the observation that models behave differently when encountering training data versus unseen data. Attackers can use these differences, often observed in metrics such as:
Prediction Confidence (Loss): The model may assign higher confidence to tokens seen during training.
Compressibility (Zlib Entropy): Training data tends to produce more predictable and compressible outputs than unseen data.
Goldfish loss can reduce the effectiveness of MIAs compared to standard training. However, these attacks can still achieve significant accuracy in identifying training samples, especially when using the Zlib criterion. This shows that although goldfish loss resists verbatim memorization, it doesn't completely eliminate the traces of training data that MIAs can exploit.
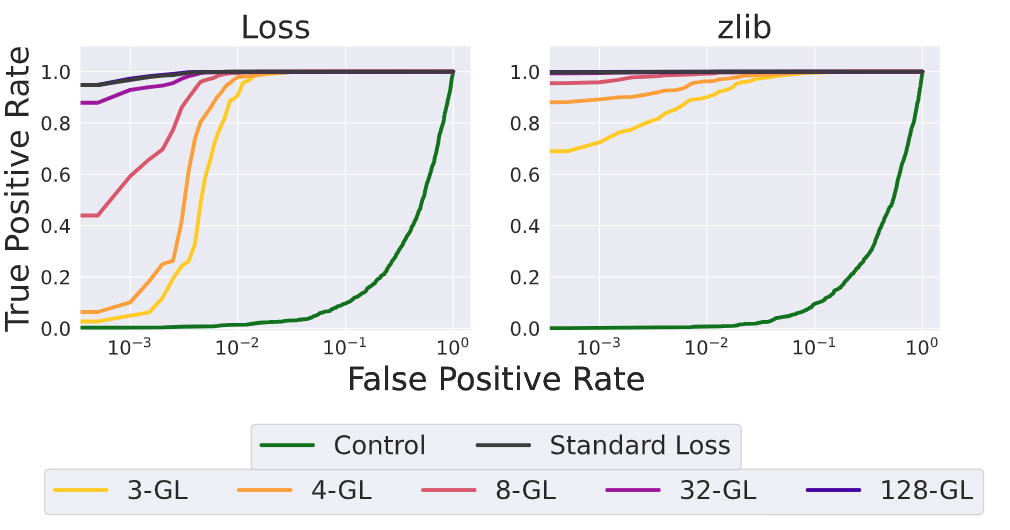 Figure- Membership inference attack.png
Figure- Membership inference attack.png
Figure: Membership inference attack | Source
Beam Search Attacks
This attack strategy includes using a beam search algorithm. It tries to reconstruct the original training samples by iteratively refining the generated sequence and selecting the most likely candidates based on the model's perplexity. Since goldfish loss only masks a subset of tokens during training, the attacker can use the unmasked tokens and the model's knowledge of the surrounding context to guide the beam search process.
By exploring different combinations for the masked tokens, the attacker tries to find a sequence that reduces the model's perplexity. This suggests a higher chance that it resembles the original training sample. As the masking ratio increases (higher 𝑘), the number of masked tokens grows, giving the attacker more freedom to manipulate the sequence during beam search. However, Goldfish Loss with a low masking ratio (k=3) resisted beam search attacks. This significantly affects the attacker’s ability to reconstruct training samples.
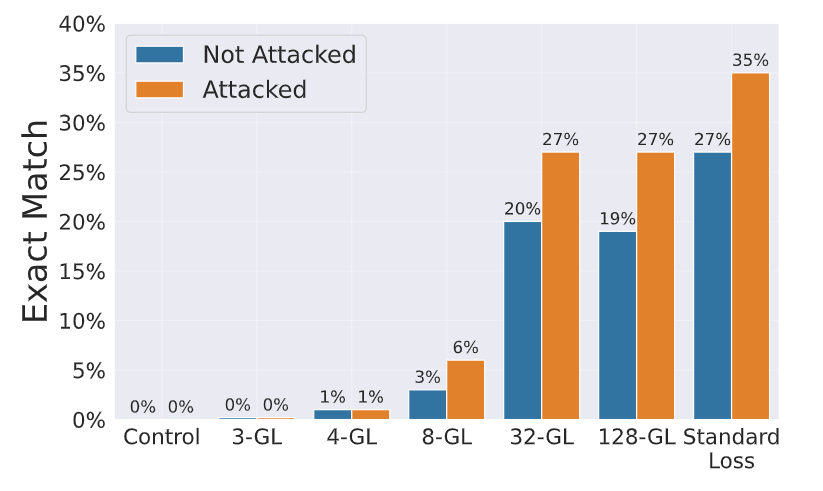 Figure- Beam search attacks .png
Figure- Beam search attacks .png
Figure: Beam search attacks | Source
Implications of Goldfish Loss
The goldfish loss technique extends beyond simply reducing the verbatim repetition of training data, affecting various aspects of model training, performance, and security.
Potential for Copyright and Privacy Protection: Goldfish Loss directly addresses the growing concerns surrounding copyright infringement and privacy violations associated with LLMs. This technique reduces the chances of verbatim reproduction of training data. It helps protect creators' intellectual property and prevents the leakage of sensitive personal information.
Impact on LLM Training Practices: The introduction of goldfish loss indicates a need for changes in LLM training practices. Developers may need to adapt their training procedure by adjusting the number of training steps or batch size. This adjustment is necessary to account for the reduced number of tokens used in loss computation.
Need for Comprehensive Security Assessments: Various potential attacks must be considered when evaluating the security of large language models (LLMs). While techniques like goldfish loss can help reduce the risk of verbatim memorization, they may not protect against more advanced threats, such as membership inference attacks and beam searches. This underscores the necessity for thorough security assessments beyond just checking for direct repetition.
Conclusions and Potential Future Research Directions
Goldfish loss is a simple yet effective technique for mitigating memorization in large language models. By selectively dropping tokens during training, goldfish loss helps minimize the risk of directly reproducing sensitive data. At the same time, it mostly preserves the model's performance on downstream tasks. Although not impervious to advanced attacks, there is a critical need to balance model capabilities with responsible data handling practices.
Future Research Directions for Goldfish Loss
There are several promising directions for future research on goldfish loss.
Scalability to Larger Models: As the size of language models increases, so does their tendency to memorize training data. Therefore, it's crucial to understand the benefits and limitations of the goldfish loss scale with model size. This necessitates research into adapting and refining goldfish loss for increasingly complex LLMs with tens or hundreds of billions of parameters.
Selective Application of Goldfish Loss: Exploring the selective application of goldfish loss to specific parts of the training data or during particular stages of training. This could optimize the balance between memorization mitigation and model performance.
Developing Robust Hashing Strategies: The effectiveness of goldfish loss, especially in scenarios with near-duplicated text segments, relies heavily on the robustness of the hashing mechanism. Research into developing and evaluating advanced hashing strategies that ensure consistent masking of repeated content is important.
Exploring Hybrid Approaches: Investigating the potential benefits of combining goldfish loss with other techniques, such as differential privacy or data sanitization methods. This could lead to more robust and comprehensive solutions for mitigating memorization risks in LLMs.
Related Resources
Goldfish loss paper: Be like a Goldfish, Don’t Memorize! Mitigating Memorization in Generative LLMs
MAUVE scores paper: MAUVE Scores for Generative Models: Theory and Practice
MIA's paper: Do Membership Inference Attacks Work on Large Language Models?
What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
Efficient Memory Management for Large Language Model Serving with PagedAttention
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- Risks of LLM Memorization
- A Detailed Look at the Goldfish Loss Approach
- Goldfish Mask Generation Strategies
- Memorization Metrics: Measuring the Extent of Memorization
- Key Training Setups: Assessing Goldfish Loss in Diverse Scenarios
- Analyzing the Impact of Goldfish Loss
- Implications of Goldfish Loss
- Conclusions and Potential Future Research Directions
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
LLM-Eval is an approach to simplifying and automating the evaluation of LLM conversation quality.
LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
LoRA (Low-Rank Adaptation) is a technique for efficiently fine-tuning LLMs by introducing low-rank trainable weight matrices into specific model layers.
Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
Knowledge distillation is a machine learning technique in which the knowledge of a large, complex model (teacher) is transferred to a smaller, simpler model (student).