




Understanding Deep Reinforcement Learning (DRL): A Comprehensive Guide
Short answer: Deep Reinforcement Learning (DRL) is a field of AI where an agent learns how to make decisions by interacting with an environment and improving over time based on feedback or "rewards." DRL combines reinforcement learning (RL), a learning method through trial and error, with deep learning, which enables the agent to handle complex data like images or sensor readings. DRL can use deep neural networks to teach agents to navigate complicated tasks with high-dimensional inputs. It’s widely used in applications like robotics and game playing, where traditional learning methods struggle due to the complexity and variability of the environment.
Understanding Deep Reinforcement Learning (DRL): A Comprehensive Guide
In 2016, when AlphaGo defeated world champion Lee Sedol at Go—a game with more possible moves than atoms in the universe—it marked a watershed moment in business technology. The secret behind this win? Deep Reinforcement Learning—a method that trains computers to improve through practice, just like a tennis player who perfects their serve after years on the court. Where traditional computer programs struggle with unexpected changes, this technology shines in situations that shift constantly—from directing robots in busy warehouses to making rapid decisions in stock trading. This new approach to machine learning opens doors for businesses, tackling problems that were once too complex for regular software to solve.
This guide provides an in-depth exploration of deep reinforcement learning, highlighting key concepts, its various applications, its advantages, and the challenges that may arise in its implementation.
What is Deep Reinforcement Learning?
Deep Reinforcement Learning (DRL) combines two effective AI techniques, Reinforcement Learning (RL) and Deep Learning, enabling AI agents to learn optimal actions through trial and error in complex environments. In RL, an agent interacts with its environment and adjusts its behavior based on rewards and learning strategies to maximize long-term rewards. Deep learning adds the ability to handle detailed state representations using neural networks.
For example, a robot navigating a maze moves randomly initially, but over time, it learns to reach the goal efficiently through feedback. DRL helps agents adapt to dynamic environments and solve complex problems without detailed instructions. It's useful in video games, self-driving cars, and personal recommendations. By combining Reinforcement Learning and Deep Learning, DRL agents can effectively handle complicated real-world tasks.
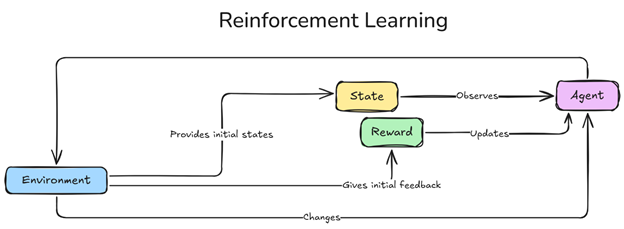 Figure 1 Reinforcement Learning Framework.png
Figure 1 Reinforcement Learning Framework.png
How Deep Reinforcement Learning Works
To understand how DRL works, it's important to know its key components:
Agent
Environment
State
Actions and Rewards
Policy
Agent
The agent is the decision-maker tasked with navigating the environment and making choices to maximize cumulative rewards over time. Through repeated interactions (learning episodes), the agent refines its strategy based on feedback, adjusting its behavior to achieve long-term success. Much like a player in a game, the agent's actions are guided by a policy—a set of rules learned over time to improve performance and reach optimal outcomes.
Environment
The environment is the structured space within which the agent operates, defining possible states, actions, and rewards. It reacts to each agent's action, delivering feedback that influences the agent’s future decisions and shapes its learning process.
State
The state represents a snapshot of the environment at a particular moment, containing information important for the agent’s decision-making. For instance, a state might include an agent's position and obstacles in a maze or a vehicle’s speed and proximity to other cars. Each state helps the agent assess its situation and select the most advantageous action.
Actions and Rewards
Actions represent an agent's choices in each state, directing its path through the environment. Actions can be:
Discrete Actions: Limited options, such as moving up, down, left, or right, in grid environments make it easier for agents to explore and develop policies.
Continuous Actions: These include a range of values, like adjusting speed or angle, which require advanced models to handle the increased complexity.
The agent aims to make optimal actions over time and maximize rewards.
Rewards provide feedback to guide the agent's learning. Positive rewards signal successful actions, while negative rewards penalize mistakes. Rewards may include:
Immediate Rewards: These are given directly after an action, like scoring points for capturing an opponent's piece in chess.
Delayed Rewards: Earned after completing a sequence of actions, such as navigating a maze.
It is important to design the reward structure, known as reward shaping. For instance, intermediate rewards along a complex path can accelerate learning, motivating the agent to take specific steps toward the final goal.
 Figure- Reinforcement Learning architecture.png
Figure- Reinforcement Learning architecture.png
Figure: Reinforcement Learning architecture
The Learning Process
The deep reinforcement learning's learning or training process is an iterative cycle of interaction, feedback, and improvement that involves:
Exploration
Exploitation
Deep Neural Networks
Backpropagation
Exploration
Initially, the agent does not know the environment. It starts by exploring randomly, trying different actions, and observing the consequences. This exploration phase is important for gathering environmental information and discovering rewarding actions.
Exploitation
As the agent explores and gathers experience, it starts to identify actions that lead to positive rewards. It then exploits this knowledge, choosing those actions more frequently to maximize its rewards.
Deep Neural Networks
The agent uses deep neural networks to approximate the agent's policy and value function.
Policy Network: This network takes the current state as input and outputs the probability of taking different actions.
Value Network: This network estimates the long-term value of being in a particular state, helping the agent make decisions that lead to higher cumulative rewards. These neural networks allow the agent to learn complex environmental patterns and relationships, helping to make more intelligent decisions.
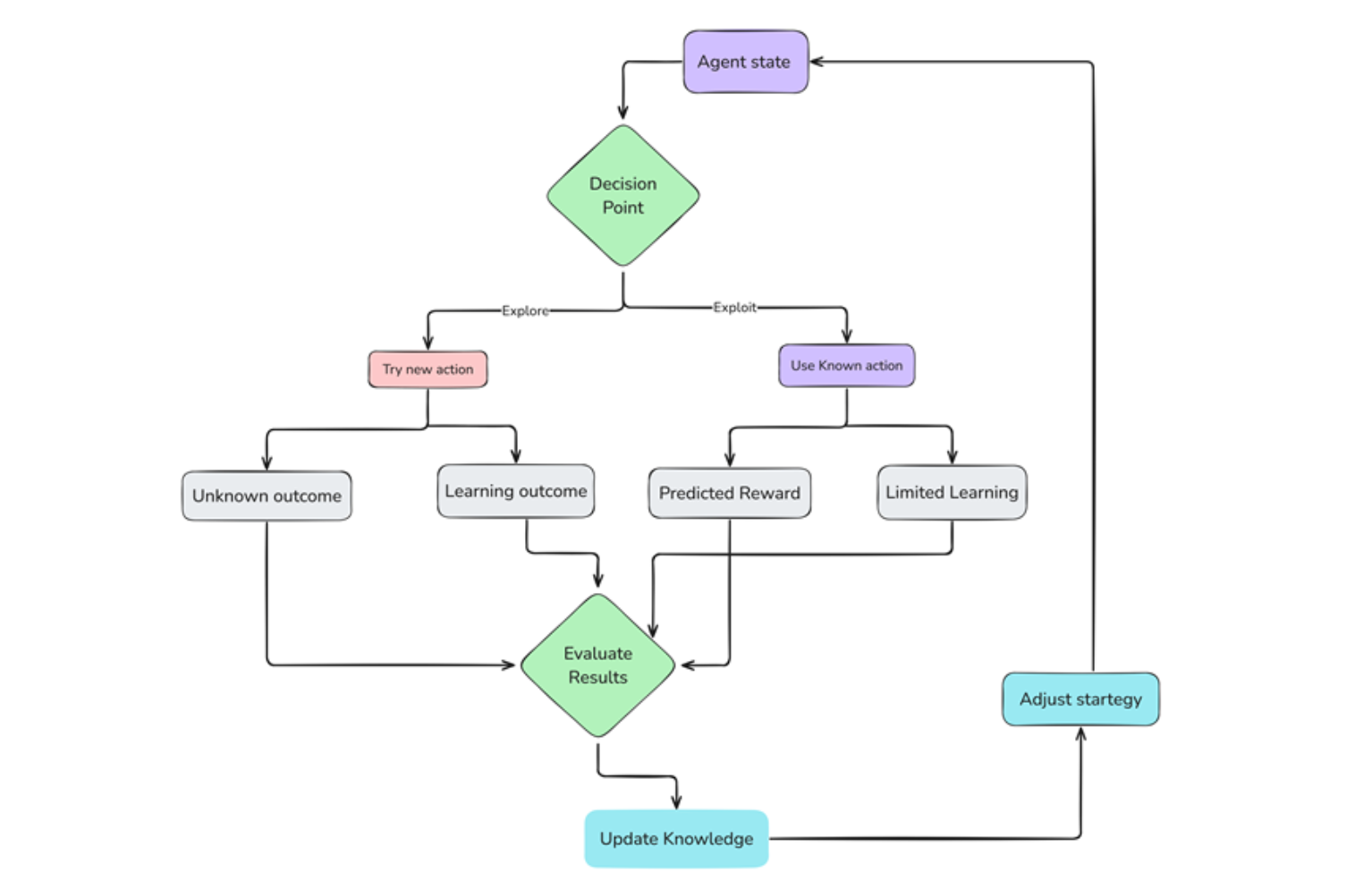 Exploration vs Exploitation Process .png
Exploration vs Exploitation Process .png
Figure 3 Exploration vs Exploitation Process
Backpropagation
Backpropagation, short for "backward propagation of errors," is a key algorithm in training neural networks. It adjusts the weights in a neural network to minimize the error in predictions.
Backpropagation helps agents improve their decision-making models through learning from feedback. When an agent takes an action, it receives feedback on how good or bad that action was (in the form of a reward). Backpropagation then adjusts the neural network’s weights, reducing the error between predicted outcomes and actual rewards. By applying backpropagation repeatedly, the neural network learns to better approximate the value or policy functions, leading to more accurate decisions. This process enables the agent to gradually improve its understanding of the environment and make increasingly optimal decisions over time, which is essential for mastering complex tasks in dynamic, high-dimensional environments.
Popular Algorithms in Deep Reinforcement Learning
DRL employs a variety of algorithms, each designed to tackle different challenges in the learning process. Here are some of the most widely used methods:
Q-Learning: Q-Learning is one of the foundational reinforcement learning algorithms. It estimates the value of state-action pairs, referred to as Q-values, helping the agent determine which actions are preferable in particular states. The algorithm updates these Q-values based on immediate rewards and anticipated future rewards, gradually refining the agent's choices to favor actions with higher long-term value.
Deep Q-Networks (DQN): DQN enhances Q-learning by utilizing neural networks to approximate Q-values. This approach makes DQNs effective in complex environments such as game AI, robotic navigation, and autonomous driving.
Policy Gradients: Unlike value-based methods, policy gradient algorithms directly optimize an agent's policy by adjusting the weights of a neural network based on the rewards received. This approach enables the agent to enhance performance by increasing the likelihood of successful actions, which is especially important in control tasks that require precise adjustments, such as robotic arm manipulation.
Actor-Critic Methods: Hybrid approaches combine the strengths of policy-based methods, which aim to estimate the value of each action in a given state, and value-based methods, which focus on directly learning the optimal policy. In this framework, the actor is responsible for selecting actions, while the critic evaluates these actions and provides feedback. This feedback enables continuous improvements to the policy.
Comparison of Deep Reinforcement Learning with Other Concepts
Deep Reinforcement Learning (DRL) is often compared with other AI approaches. To clarify differences and similarities, let's break down the key aspects:
| Aspect | Deep Reinforcement Learning (DRL) | Regular Reinforcement Learning (RL) | Supervised Learning | Unsupervised Learning | |
| Core Concept & Data Handling | Combines RL with deep neural networks; processes high-dimensional, complex data | Focuses on RL with simpler models; works well in low-dimensional environments | Learns from labeled data with predefined outputs; relies on labeled datasets | Finds patterns in unlabeled data; works with unlabeled datasets | |
| Learning Process | Trial and error via interaction with the environment. | Trial and error through feedback from the environment. | Learn patterns from labeled input-output pairs. | Identifies clusters or structures in data. | |
| Goal | Maximize cumulative rewards over time. | Maximize cumulative rewards over time. | Predict outputs based on input data. | Discover hidden patterns or groupings in data. | |
| Applications | Complex tasks: game AI, robotics, autonomous vehicles. | Basic control systems and simple decision-making tasks. | Classification, regression, predictive modeling. | Clustering, dimensionality reduction, anomaly detection. |
Benefits and Challenges of Deep Reinforcement Learning
Deep reinforcement learning has a lot of possibilities, but it's important to know what it's good at and where it might fall short. Let's look at some of the main benefits and challenges of DRL.
Benefits:
Adaptability: One key benefit of DRL is its adaptability. DRL agents can handle new and unexpected situations without requiring additional programming. For example, a DRL-powered autonomous vehicle can respond to sudden road changes, such as obstacles or adverse weather, adjusting its behavior to navigate safely.
Optimal Decision Making: DRL also enables smarter, often more effective decision-making. Unlike traditional rule-based systems, DRL models can discover strategies that even human designers might overlook. In finance, for instance, DRL has been successfully applied to create trading bots that frequently make more profitable decisions than conventional systems.
Automation Potential: DRL enables the automation of tasks in fields like moving goods, medical care, and helping customers. In these often complicated and always shifting areas, DRL helps make things easier by automating them.
Challenges:
Sample Efficiency: One of the biggest challenges with DRL is its demand for vast amounts of training data. DRL models typically require extensive data to perform well, which can be costly and time-intensive to gather. Techniques like experience replay help by allowing models to learn from past data, but improvements in data efficiency are still needed to make DRL more practical.
Reward Design: Another challenge lies in designing effective reward functions. Setting the right rewards is crucial because poorly designed rewards can lead to unintended and sometimes problematic agent behaviors. As a result, reward design in DRL requires careful planning to ensure that agents act in ways that align with their intended goals.
Stability and Convergence: Lastly, DRL training can be unstable. Sometimes, models get stuck in less-than-ideal strategies or fail to reach a stable solution. Improving training stability is essential to making DRL models more reliable, especially for high-stakes applications where consistency is key.
Real-World Applications of Deep Reinforcement Learning
Now that we've explored the workings of deep reinforcement learning (DRL) let's shift our focus to its practical applications. DRL is being used to solve real-world problems across various domains. Including:
Game Playing: DRL has enabled the creation of advanced AI agents that excel in games like Chess, Go, and Dota 2. For those interested in hands-on exploration, Unity ML-Agents provides an accessible toolkit for experimenting with game-based learning.
Robotics: In robotics, DRL teaches machine skills such as navigating and handling objects. DRL proves highly effective in warehouses, allowing robots to adapt to new layouts and changing tasks, boosting operations' efficiency.
Autonomous Vehicles: In self-driving cars, DRL plays a crucial role in making split-second decisions for lane changes, avoiding obstacles, or adjusting speed. Waymo, for instance, uses DRL to help its vehicles make safe choices in complex traffic situations.
Financial Trading: DRL is also widely used in finance to develop trading bots that respond to market shifts. Using approaches like Deep Q-Learning, DRL-powered trading bots analyze historical trends and live data to make informed buy, hold, or sell decisions, often achieving better results than manual trading strategies.
Personalized Recommendations: DRL powers increasingly advanced recommendation systems. To provide tailored recommendations, DRL algorithms analyze user behavior and preferences on streaming services, online stores, and social media platforms. By observing user actions, DRL can recommend content or products that align more closely with individual preferences.
FAQs About Deep Reinforcement Learning
- How does an agent learn in deep reinforcement learning?
In DRL, an agent learns by taking actions in an environment and receiving feedback in the form of rewards. The agent uses exploration (trying new actions) to discover effective strategies and exploitation (using known actions) to maximize rewards. Deep neural networks help the agent generalize from its experiences and adapt to complex scenarios.
- How do deep reinforcement learning models balance exploration and exploitation?
DRL models balance exploration (trying new actions to discover better strategies) and exploitation (using known actions to maximize rewards) through algorithms like epsilon-greedy or Thompson Sampling. These techniques help maintain a balance, ensuring the agent discovers new strategies while maximizing known rewards.
- How do value functions work in deep reinforcement learning?
Value functions estimate the expected reward of being in a certain state (state-value function) or taking a specific action in a given state (action-value function). They help the agent prioritize states and actions that lead to higher rewards, guiding decision-making.
- How can DRL be used with Milvus for AI applications?
Milvus can store and manage the high-dimensional state representations generated by DRL agents. It can serve as a replay buffer for past experiences or assist in state representation storage, enhancing the efficiency of policy optimization and value estimation.
- What are the ethical concerns of using deep reinforcement learning?
Ethical concerns include potential biases in training data, unintended behaviors arising from poorly designed reward functions, and fairness issues in sensitive applications. To mitigate these risks, it is crucial to implement robust testing, transparency, and explainable AI.
Related Resources
For further exploration, consider these resources:
- What is Deep Reinforcement Learning?
- How Deep Reinforcement Learning Works
- Popular Algorithms in Deep Reinforcement Learning
- Comparison of Deep Reinforcement Learning with Other Concepts
- Benefits and Challenges of Deep Reinforcement Learning
- Real-World Applications of Deep Reinforcement Learning
- FAQs About Deep Reinforcement Learning
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free