




LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
LLM-Eval is an approach to simplifying and automating the evaluation of LLM conversation quality.
Read the entire series
- OpenAI's ChatGPT
- Unlocking the Secrets of GPT-4.0 and Large Language Models
- Top LLMs of 2024: Only the Worthy
- Large Language Models and Search
- Introduction to the Falcon 180B Large Language Model (LLM)
- OpenAI Whisper: Transforming Speech-to-Text with Advanced AI
- Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
- What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
- LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
- Mastering Cohere's Reranker for Enhanced AI Performance
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
- Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
- RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
- Prover-Verifier Games Improve Legibility of LLM Outputs
- Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
- Unlocking the Power of Many-Shot In-Context Learning in LLMs
- Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
- Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
- Everything You Need to Know About LLM Guardrails
- Chain-of-Retrieval Augmented Generation
- Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
Introduction
The rapid growth of Large Language Models (LLMs) over the past few years necessitates a robust method to evaluate their generation quality. As you may already know, LLMs, at their core, have been pre-trained to predict the most probable next token given previous tokens. This means that these LLMs could hallucinate when generating a response to users' queries.
Hallucination is a phenomenon where the response of an LLM looks coherent and convincing, but its truthfulness is entirely off. This issue can occur when the model's internal knowledge gained during the pre-training process can't answer our question. For example, hallucination might occur if we ask LLM a question that is too specific to our use case, such as inquiries related to proprietary data.
The problem is that hallucination is hard to spot unless we are subject matter experts in the domain on which the LLM's responses are based. Therefore, there must be a method to evaluate the quality of the responses generated by these LLMs, and that's what we will discuss in this article.
In this piece, we'll talk about a method called LLM-Eval, which is used to evaluate the response quality of an LLM.
What is LLM-Eval?
LLM-Eval is an approach designed to simplify and automate the evaluation of the quality of LLM conversations. Instead of separately assessing each aspect of a conversation (like its relevance or grammatical correctness), LLM-Eval combines all these assessments into one streamlined process. The key feature of LLM-Eval is that it allows for evaluating a generated dialogue response across multiple dimensions (such as appropriateness, content, grammar, and relevance) using a single prompt.
LLM-Eval Evaluation Metrics
ROUGE and BLEU are two of the most popular metrics for evaluating the quality of responses generated by an LLM before the inception of more sophisticated methods. In a nutshell, here is what these two metrics do:
BLEU score calculates the precision of n-grams between the text generated by our LLM and a reference text. The "n" in n-grams can be any integer that you choose in advance.
ROUGE score calculates the similarity between the text generated by our LLM and a reference text using overlapping n-grams and word sequences.
The problem with these two metrics is that they’re unable to capture the semantic meaning of the text. Semantic meaning is crucial in assessing an LLM’s performance, as we need to capture the nuance and essence of the LLM’s response to the user’s query. Additionally, many advanced methods rely on human annotation and multiple prompts, which can be time-consuming and error-prone.
 High-level workflow of LLM-Eval
High-level workflow of LLM-Eval
Figure 1: High-level workflow of LLM-Eval. Source.
LLM-Eval aims to solve these problems and offer a simple evaluation process with the help of the LLM itself. With LLM-Eval, we can get the evaluation result of an LLM’s response quality in several different metrics, hence the name "multi-dimensional" in the title. The core metrics evaluated by LLM-Eval in the paper include content, grammar, relevance, and appropriateness.
Content: This metric measures qualities such as the accuracy of the information provided, completeness of responses, depth of knowledge demonstrated, and coherence and logical flow of ideas.
Grammar: This metric measures qualities such as sentence structure, correct use of tenses, cohesiveness between subjects and verbs, appropriate use of punctuation, and consistency in spelling.
Relevance: This metric measures how well the response aligns with the given context or query, i.e., whether it stays on-topic, addresses specific points raised in the query, and provides responses that match the level of detail requested.
Appropriateness: This metric measures the suitability of the response in various aspects, such as tone and formality of the language, cultural sensitivity, and awareness.
Aside from the four core metrics above, LLM-Eval can also be used to evaluate dataset-specific metrics. For example, the ConvAI2 dataset evaluates the relevancy and engagement of responses. In this case, we can adjust the prompt of LLM-Eval to evaluate these two metrics on ConvAI2 dataset. We’ll see the detailed prompt of LLM-Eval to evaluate metrics in the next section.
Now that we know the metrics we can evaluate using LLM-Eval, let’s discuss how it actually works.
How LLM-Eval Works
As briefly mentioned in the previous section, LLM-Eval uses the LLM itself to evaluate its response quality. This means that we provide the LLM with a predefined prompt that contains everything it needs to give us an evaluation result of its response quality.
LLM-Eval uses a single prompt to obtain a final score of the metrics we want to investigate. The prompt consists of several components, such as a schema, a context, a human reference text, and a text response from the LLM.
A schema is a natural language instruction that defines the task and evaluation criteria. Here, you can specify any metrics that you’d like the LLM to evaluate. Additionally, you can define the range of evaluation scores. LLM-Eval uses two different ranges of evaluation scores: one from 0 to 5, and another from 0 to 100. Below is the schema template used by LLM-Eval to evaluate the four metrics (appropriateness, content, grammar, and relevance):
Human: The output should be formatted as a
JSON instance that conforms to the JSON
schema below.
As an example, for the schema {"properties":
{"foo": {"title": "Foo", "description": "a
list of strings", "type": "array", "items":
{"type": "string"}}}, "required": ["foo"]}}
the object {"foo": ["bar", "baz"]} is a
well-formatted instance of the schema.
The object {"properties": {"foo": ["bar",
"baz"]}} is not well-formatted.
Here is the output schema:
{"properties": {"content": {"title":
"Content", "description": "content score
in the range of 0 to 5", "type":
"integer"}, "grammar": {"title": "Grammar",
"description": "grammar score in the range
of 0 to 5", "type": "integer"}, "relevance":
{"title": "Relevance", "description":
"relevance score in the range of 0 to 100",
"type": "integer"}, "appropriateness":
{"title": "Appropriateness", "description":
"appropriateness score in the range of 0 to
5", "type": "integer"}}, "required":
["content", "grammar", "relevance",
"appropriateness"]}
Once we have a schema described above, we can build the other prompt components: context, reference, and response.
Context: Contains previous chat dialogues that can be used by the LLM to generate a response.
Reference: Contains the preferred response to a context created by a human.
Response: Contains the response generated by the LLM to a context.
If a dataset contains a human reference, the complete prompt would look like this:
{evaluation_schema}
Score the following dialogue response
generated on a continuous scale from
{score_min} to {score_max}.
Context: {context}
Reference: {reference}
Dialogue response: {response}
Meanwhile, for datasets without human reference, the complete prompt would only consist of the context and the response from an LLM, as you can see below:
{evaluation_schema}
Score the following dialogue response
generated on a continuous scale from
{score_min} to {score_max}.
Context: {context}
Dialogue response: {response}
The two prompts mentioned above only take a single response of an LLM into account. If we want to evaluate the LLM’s response quality in a whole dialogue, then LLM-Eval use the following prompt:
{evaluation_schema}
Score the following dialogue generated
on a continuous scale from {score_min}
to {score_max}.
Dialogue: {dialog}
Once we have created a prompt similar to the template above, the only thing left to do is to feed this prompt into an LLM of our choice (such as Llama, GPT, Claude, Mistral, etc.). The LLM will then score each metric based on the defined schema.
An LLM-Eval Demo
In this section, we'll implement LLM-Eval to evaluate the response quality of an LLM on a user query. While there are numerous LLMs to choose from, we'll be using Llama 3.1 from Meta in this article, as it's an open-source model and free to use. Llama 3.1 comes in three variants: 8B, 70B, and 405B parameters, but we'll use the 8B version to ensure we can load it on our local machine.
To load Llama 3.1 8B, we'll use Ollama, a tool that enables us to utilize LLMs on our own local machines. For installation instructions, please refer to Ollama's latest installation page.
Once you've installed Ollama, you can pull any desired LLM with a single command. To pull Llama 3.1, use this command:
ollama pull llama3.1
Before we use the Llama 3.1 8B model, we need to adjust its parameters.
An important aspect of LLM-Eval implementation is greedy decoding. This means that the parameters are set such that the LLM will always pick the token with the highest probability as the next token. To mimic this greedy decoding behavior, we need to adjust the following parameters:
Temperature: This parameter has a range of values between 0 and 1 and controls the creativity of the LLM in generating responses. A higher value means our LLM will be more creative in generating responses. If we set the value to 0, we force our LLM to output a deterministic result.
Top p: This parameter samples from the set of tokens with the highest probability such that the sum of probabilities is higher than p. It has a range of values between 0 and 1. Lower values focus on the most probable tokens, while higher values sample more low-probability tokens. We'll set this parameter to 0.
Top k: This parameter samples from the best k (number of) tokens. The range of values can be anywhere from 1 to the total number of tokens in the LLM's vocabulary. We'll set this parameter to 1 as we want our LLM to pick the token with the highest probability.
To set these parameters to the desired values, we must create a Modelfile first. Here's what the Modelfile looks like:
FROM llama3.1
# sets the temperature
PARAMETER temperature 0
# sets top k
PARAMETER top_k 1
# sets top p
PARAMETER top_p 0
Next, we can use this Modelfile to adjust our Llama3.1’s parameter by executing this command:
ollama create <name_of_your_choice> -f ./Modelfile
ollama run <name_of_your_choice>
For a more detailed explanation of Modelfile, refer to this document.
Now we can construct our prompt and use this model for metrics evaluation. We’ll use the template provided in the previous section as our schema and use an example from the TopicalChat dataset as a demo. The TopicalChat dataset is one of several benchmark datasets used to compare the performance of LLM-Eval with other evaluation methods. You can download the TopicalChat dataset from this website.
In general, one example from the TopicalChat dataset consists of a context, a response, a reference, and an annotation. The annotation refers to human-annotated scores for appropriateness, content, grammar, and relevance of the LLM’s response.
Here is the prompt template that we’ll use to generate scores for appropriateness, content, grammar, and relevance, as well as the response:
import ollama
prompt = """The output should be formatted as a
JSON instance that conforms to the JSON
schema below.
As an example, for the schema {"properties":
{"foo": {"title": "Foo", "description": "a
list of strings", "type": "array", "items":
{"type": "string"}}}, "required": ["foo"]}}
the object {"foo": ["bar", "baz"]} is a
well-formatted instance of the schema.
The object {"properties": {"foo": ["bar",
"baz"]}} is not well-formatted.
Here is the output schema:
{"properties": {"content": {"title":
"Content", "description": "content score
in the range of 0 to 5", "type":
"integer"}, "grammar": {"title": "Grammar",
"description": "grammar score in the range
of 0 to 5", "type": "integer"}, "relevance":
{"title": "Relevance", "description":
"relevance score in the range of 0 to 5",
"type": "integer"}, "appropriateness":
{"title": "Appropriateness", "description":
"appropriateness score in the range of 0 to
5", "type": "integer"}}, "required":
["content", "grammar", "relevance",
"appropriateness"]}
Score the following dialogue response
generated on a continuous scale from
0 to 5.
Context: "Hello! Do you like Football?nI do. Do you?nOf course! What's your favorite team. Mine is the New England Patriots, the Lannisters of the NFL!”
Reference: "I like the Broncos. Have you read the Indentured by Ben Strauss and Joe Nocera?”
Dialogue response: "I love the New England Patriots. They are the best team in the NFL!”"""
stream = ollama.chat(
model='llama3.1',
messages=[{'role': 'user', 'content': prompt}],
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
"""
Output:
"content": 2,
"grammar": 4,
"relevance": 1,
"appropriateness": 3
Here's a breakdown of the scores:
* Content: 2 (The response is relevant to the topic, but doesn't provide much new or interesting information.)
* Grammar: 4 (The grammar and spelling are mostly correct, with only minor issues such as using an exclamation mark instead of a question mark.)
* Relevance: 1 (The response is somewhat off-topic, as it starts talking about a different team and book.)
* Appropriateness: 3 (The tone of the response is enthusiastic and friendly, but also slightly sarcastic. It's not entirely suitable for all audiences.)
"""
We’ll see the result on benchmark datasets in the next section.
As you can see, our LLM will output the score for each metric specified in our schema. However, it’s important to note that in the above demo, we’re using the 8B model that has been quantized to 4 bits. Therefore, we lose some performance compared to the original model, and the results above are less reliable. The original LLM-Eval implementation used proprietary, more powerful LLMs such as OpenAI's ChatGPT and Anthropic's Claude to generate these scores. We’ll see the results of the original LLM-Eval on benchmark datasets in the next section.
LLM-Eval Results and Performance
To measure the effectiveness of LLM-Eval, this method has been evaluated and compared with several other LLM evaluation methods, such as:
Deep-AM-FM: Utilizes BERT embeddings to measure the quality of dialogue by calculating the Adequacy Metric (AM) and Fluency Metric (FM). AM measures how well the meaning of the source text is preserved in the generated text, while FM measures how natural, smooth, and grammatically correct the output text is.
MME-CRS: Measures response quality across five metrics: fluency, relevance, engagement, specificity, and coherence.
BERTScore: Measures the F1 score of dialogue quality by matching BERT token embeddings in human references and generated responses.
GPTScore: Evaluates generated responses using a GPT model, typically trained on human-rated examples to align with human judgments.
In addition to the four methods mentioned above, LLM-Eval's performance has also been compared with methods like DSTC10 Team 1, DEB, USR, USL-H, DynaEval, FlowScore, and traditional metrics like BLEU and ROUGE scores.
LLM-Eval showed very competitive results compared to the above-mentioned metrics in several benchmark datasets, both with and without human reference texts. Below is a table showing how LLM-Eval performs compared to other methods on datasets like TopicalChat and PersonaChat, evaluating metrics such as appropriateness, content, grammar, and relevance:
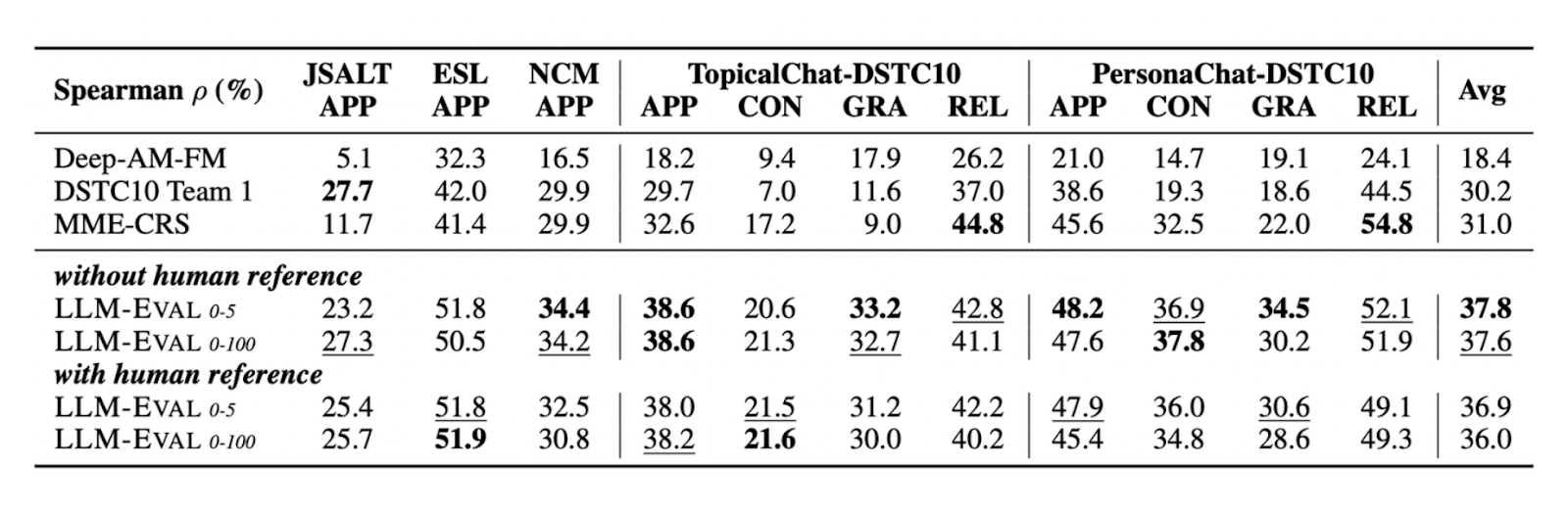 Comparison of LLM-Eval’s performance with other evaluation methods on four different metrics
Comparison of LLM-Eval’s performance with other evaluation methods on four different metrics
Figure 2: Comparison of LLM-Eval’s performance with other evaluation methods on four different metrics. Source.
As you can see, LLM-Eval’s results showed the highest Pearson correlation with human-annotated scores across all datasets compared to other evaluation methods.
In addition to assessing these four metrics, LLM-Eval can also evaluate dataset-specific metrics. For example, the ConvAI2 dataset evaluates the relevancy and engagement of responses, DailyDialog evaluates response quality in everyday conversational contexts, and EmpatheticDialogue investigates the empathetic level of responses. Below is a comparison of LLM-Eval with other methods on these datasets:
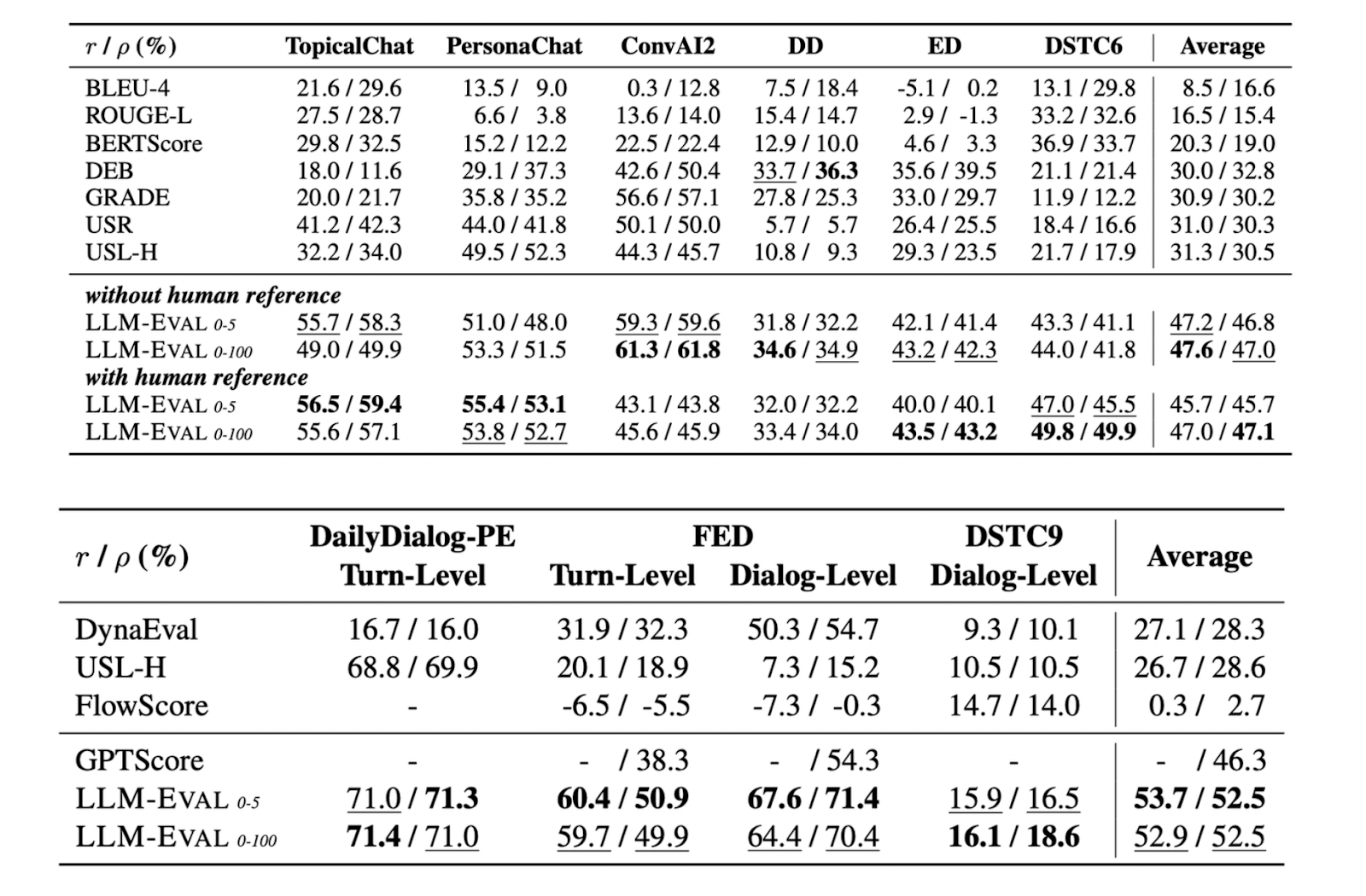 Comparison of LLM-Eval’s performance with other evaluation methods on several benchmark datasets
Comparison of LLM-Eval’s performance with other evaluation methods on several benchmark datasets
Figure 3: Comparison of LLM-Eval’s performance with other evaluation methods on several benchmark datasets. Source.
Once again, the tables show that LLM-Eval's performance is superior to other evaluation methods in Spearman and Pearson correlations across all benchmark datasets.
Whether we use a scoring range between 0 and 5 or 0 to 100 or datasets with or without human references, LLM-Eval consistently outperforms other methods across all datasets. This demonstrates that LLM-Eval is highly versatile for evaluating open-domain dialogues.
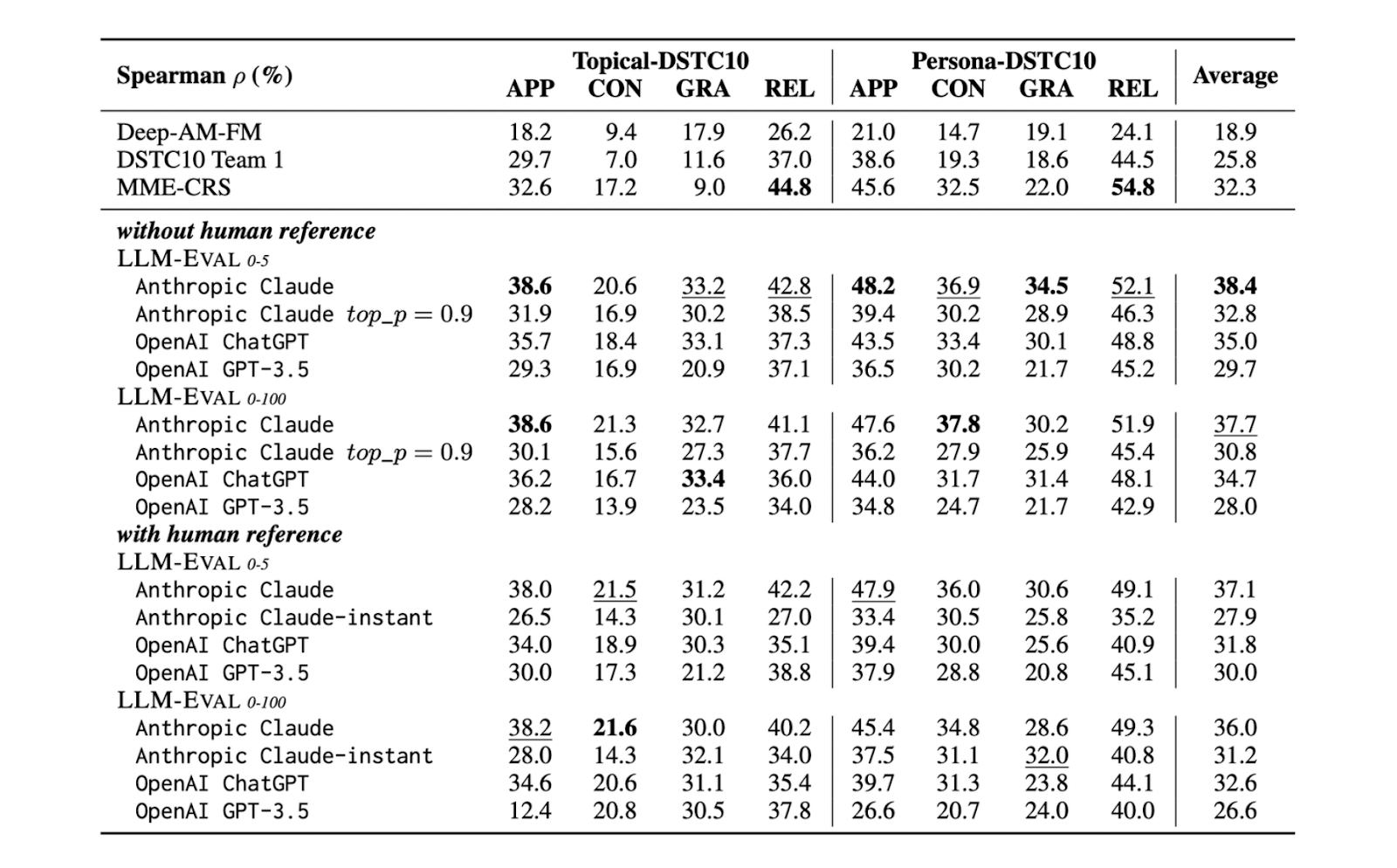 LLM-Eval’s performance on benchmark datasets using different LLMs
LLM-Eval’s performance on benchmark datasets using different LLMs
Figure 4: LLM-Eval’s performance on benchmark datasets using different LLMs. Source.
LLM-Eval can be implemented with any LLM. However, as you can see from the table above, its performance is best across all metrics when using LLMs that have been optimized for chat, i.e., ChatGPT performs better than the base GPT model. Moreover, the table also shows that Claude generally slightly outperforms ChatGPT, indicating that our choice of LLM will impact the overall performance of LLM-Eval.
Conclusion
In this article, we have discussed LLM-Eval, a versatile method for evaluating an LLM's response quality. LLM-Eval's practicality lies in its single-prompt evaluation procedure, which reduces the reliance on human annotation when assessing LLM performance.
We can choose any LLM to perform LLM-Eval. However, as demonstrated in this article, the choice of LLM will directly impact the overall evaluation quality. Therefore, it’s best to use a performant LLM optimized for chat to achieve high-quality evaluations across different metrics.
Further Resources
The LLM-Eval Paper: https://arxiv.org/pdf/2305.13711
The LLM-Eval GitHub: https://github.com/MiuLab/LLM-Eval

- Introduction
- What is LLM-Eval?
- LLM-Eval Evaluation Metrics
- How LLM-Eval Works
- An LLM-Eval Demo
- LLM-Eval Results and Performance
- Conclusion
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Top LLMs of 2024: Only the Worthy
This blog introduces the six most influential large language models in 2024.

Prover-Verifier Games Improve Legibility of LLM Outputs
We discussed the checkability training approach to help LLMs generate accurate answers that humans can easily understand and verify.
Unlocking the Power of Many-Shot In-Context Learning in LLMs
Many-Shot In-Context Learning is an NLP technique where a model generates predictions by observing multiple examples within the input context.