




Chain-of-Retrieval Augmented Generation
Explore CoRAG, a novel retrieval-augmented generation method that refines queries iteratively to improve multi-hop reasoning and factual answers.
Read the entire series
- OpenAI's ChatGPT
- Unlocking the Secrets of GPT-4.0 and Large Language Models
- Top LLMs of 2024: Only the Worthy
- Large Language Models and Search
- Introduction to the Falcon 180B Large Language Model (LLM)
- OpenAI Whisper: Transforming Speech-to-Text with Advanced AI
- Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
- What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
- LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
- Mastering Cohere's Reranker for Enhanced AI Performance
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
- Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
- RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
- Prover-Verifier Games Improve Legibility of LLM Outputs
- Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
- Unlocking the Power of Many-Shot In-Context Learning in LLMs
- Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
- Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
- Everything You Need to Know About LLM Guardrails
- Chain-of-Retrieval Augmented Generation
- Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
Retrieval-augmented generation (RAG) is essential in enterprise AI, enabling large language models (LLMs) to incorporate external knowledge for more accurate and factual responses. However, traditional RAG depends on a single retrieval step before generation, which often falls short for complex queries. This limitation is especially problematic for tasks that require connecting multiple pieces of information to produce a well-grounded answer.
Chain-of-Retrieval Augmented Generation (CoRAG) overcomes this limitation by refining queries iteratively. It samples multiple sub-queries from the original query and retrieves information in a chained form. Each query is refined based on previous sub-queries and their answers, improving context. Rejection sampling is applied to generate intermediate retrieval chains, augmenting RAG datasets. This method improves factual accuracy and helps the model handle uncertain or incomplete information.
Additionally, CoRAG uses adaptive decoding strategies and test-time scaling. This enables it to modify retrieval depth according to query complexity, explore various reasoning paths, and enhance response quality.

CoRAG surpasses a strong baseline, particularly in long-context and complex reasoning tasks like multi-hop questions requiring multiple reasoning steps. It improves exact match (EM) scores by over 10 points and achieves state-of-the-art results on the KILT benchmark. Key findings include its ability to generalize across different retrievers and an adaptive stopping mechanism that minimizes computation without compromising accuracy.
This blog explores how CoRAG improves upon RAG. It covers its core mechanisms, training methods, and experiment results. The goal is to move closer to AI models that retrieve, reason, and generate like humans.
For more details, check the following paper on CoRAG.
CoRAG Framework
The CoRAG framework builds on RAG. It introduces iterative retrieval chains for better information retrieval. Instead of retrieving once and generating an answer, CoRAG refines queries step by step. Each query builds on previous retrievals, mimicking human reasoning, and improves response accuracy.
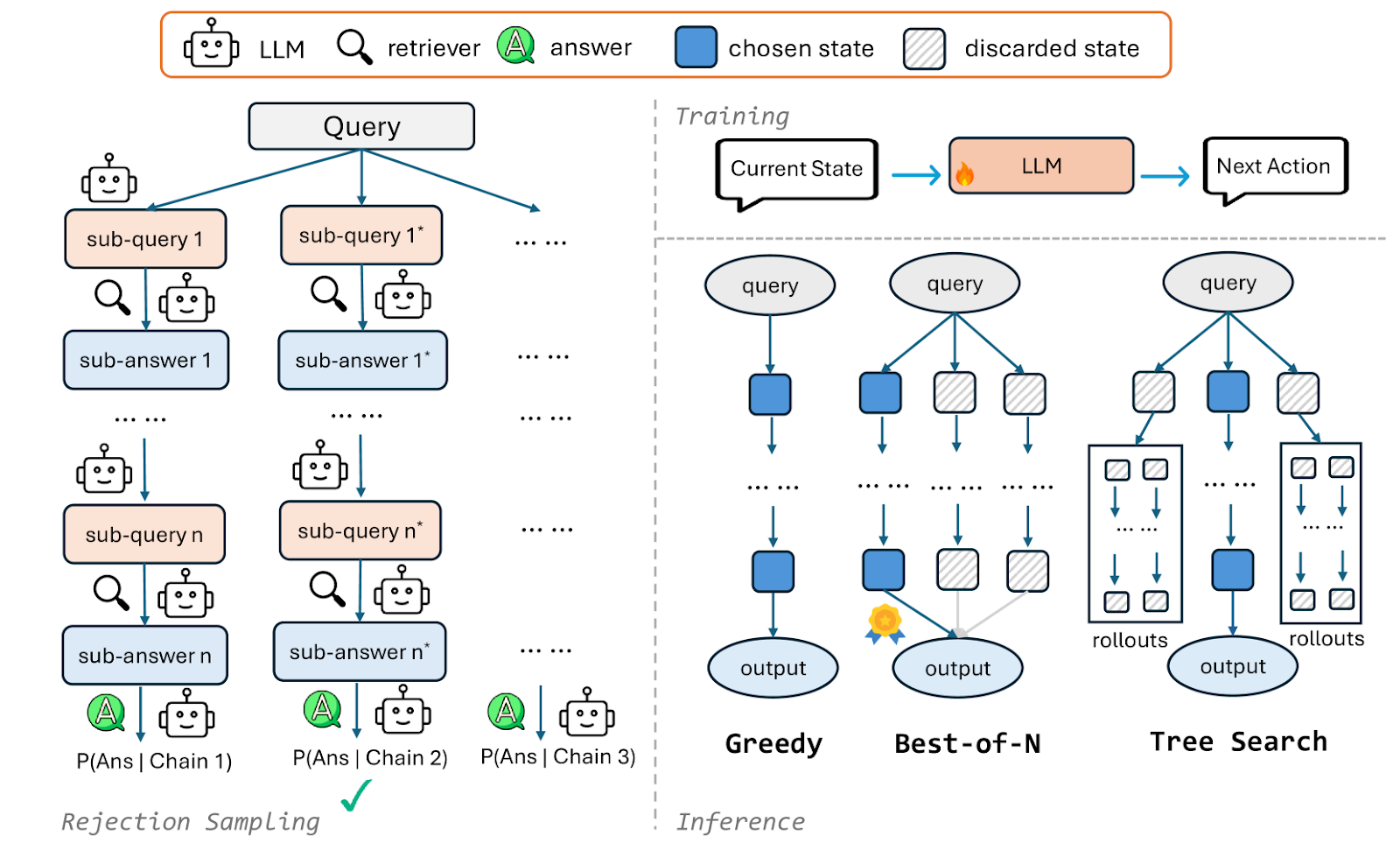
Overview of CoRAG: Rejection Sampling and Inference | Source
Now, we will discuss the key components of CoRAG, including retrieval chain generation through rejection sampling, model training with augmented datasets, and strategies for scaling test-time computing.
Retrieval Chain Generation
Most RAG datasets include only the final answer and lack intermediate reasoning steps. CoRAG solves this by automatically generating retrieval chains through rejection sampling and adding intermediate reasoning steps to augment existing question answering (QA) datasets.
Here’s how it works:
Generate sub-queries: Instead of using the original query Q directly, CoRAG samples a sequence of sub-queries {Q1 ,Q2 , ... ,QL} and corresponding sub-answers using an LLM: Qi=LLM(Q<i,A<i,Q)
This allows the model to adjust the query based on previous questions and answers, mimicking human reasoning.
Retrieve relevant information: Each sub-query Qi is used to search for the top k most relevant documents D1:k(i) using a retriever to generate the sub-answer: D1:k(i)=Retriever(Qi)
This ensures that the search results are context-aware and updated at each step.
Generate sub-answers: An LLM is prompted to generate the intermediate answer Ai based on the sub-query Qi and the retrieved documents D1:k(i): Ai=LLM(Qi,D1:k(i))
This allows the model to refine its understanding gradually before arriving at the final response.
Building a chain: The chain continues until one of two conditions is met: either the maximum chain length L (1, 6, or 10) is reached or the sub-answer matches the final answer(Ai=A). This ensures that the process remains efficient, preventing unnecessary steps while maintaining accuracy in deriving the final response.
Select the best retrieval chain: CoRAG evaluates each retrieval chain by computing the log-likelihood of the correct answer, a measure of how probable the answer is given the retrieval chain. The retrieval chain with the highest log-likelihood score is selected to augment the original QA-only dataset. : logP(A|Q1:L,A1:L)
Training
The augmented dataset is used in the training phase. Each training example consists of the original question Q , the final answer A, the retrieval chain A1:L , and the top relevant documents for each retrieval step D1:k(i).
The model is trained on three tasks: next sub-query prediction, sub-answer prediction, and final answer prediction using a multi-task learning framework. CoRAG uses cross-entropy loss to train the model on these tasks.
Sub-query prediction: Learning to generate refined queries based on prior retrievals: Lsub query= -logP(Qi|Q,Q<i,A<i), i[1,L]
Sub-answer prediction: Extracting relevant information from retrieved documents. Lsub answer= -logP(Ai|Qi,D1:k(i)), i[1,L]
Final answer prediction: Synthesizing retrieved evidence into a complete response. Lfinal answer= -logP(A|Q,Q1:L,D1:k)
Test-time Scaling
Several decoding strategies are used to manage the trade-off between model performance and computational cost during inference. The test-time compute is measured by the total number of token consumptions, including both prompt and generated tokens.
CoRAG offers 3 strategies:
Greedy decoding (the fastest way): The model generates L sub-queries and their corresponding sub-answers sequentially. It follows a fixed, step-by-step search without exploring multiple retrieval paths. It is the fastest method but may miss better answers if the initial retrieval is weak.
Best-of-N sampling (balanced approach): The model samples N different retrieval chains with a temperature of 0.7 and picks the best one. It penalizes chains that retrieve irrelevant information to decide the best chain.
Tree search (the most accurate strategy): This strategy implements a breadth-first search (BFS) variant with retrieval chain rollouts. At each step, the current state is expanded by sampling several sub-queries. For each expanded state, multiple rollouts are performed, and the average penalty score of these rollouts is computed. The state with the lowest average penalty score is retained for further expansion. While potentially the most accurate, tree search is also the most computationally expensive.
CoRAG also uses iterative training with rejection sampling for self-improvement, generating up to 16 retrieval chains with a maximum length randomly selected from the interval. The sampling temperature is set to 0.7 for sub-query generation and 0 for sub-answer generation. Chain generation stops if the sub-answer matches the correct answer or if the average conditional log-likelihood exceeds -0.05.
Experimental Setup
Here is the setup for the experiment, including the dataset used, the model training, and other key components such as baselines and evaluation methods.
Dataset
CoRAG’s capabilities are evaluated across two benchmark categories. The first assessment focuses on step-by-step reasoning using multi-hop QA datasets: 2WikiMultihopQA, HotpotQA, Bamboogle, and MuSiQue. These datasets test the model’s ability to perform step-by-step reasoning across multiple pieces of information. The second evaluation measures generalization performance using the KILT benchmark, which includes a diverse set of knowledge-intensive tasks.
For retrieval chain generation, the Llama-3.1-8B-Instruct model is used with rejection sampling. E5-large serves as the text retriever, handling intermediate retrieval steps. The retrieval corpus consists of 36 million passages from the KILT Wikipedia dataset, providing a comprehensive knowledge base for training.
Model Training
Llama-3.1-8B-Instruct is fine-tuned on the augmented datasets, with separate models trained for multi-hop QA and the KILT benchmark. The model uses distinct learning rates—510-6 for multi-hop QA and 10-5 for KILT benchmark—to ensure effective adaptation. The multi-hop QA dataset includes 125k training examples, while the KILT benchmark consists of 660k examples after sub-sampling. To enhance stability during early training, 100 warmup steps are applied. Each model retrieves 20 passages per query and processes sequences up to 3072 tokens in length.

Hyperparameters for training CoRAG | Source
All training jobs are conducted using 8 A100 GPUs. The multi-hop QA model requires under 6 hours of training, whereas the KILT benchmark training takes approximately 30 hours due to its larger dataset size.
To improve retrieval effectiveness, an E5-Mistral retriever is fine-tuned, and a RankLLaMA re-ranker is incorporated. Both are trained on their respective datasets to enhance ranking quality.
Benchmarking and Evaluation
Performance is measured using EM scores, which check if the model’s answers match the ground truth, and F1 scores, which evaluate partial correctness based on token overlap. For the KILT benchmark, predictions are submitted to the official evaluation server, which assesses performance on a hidden test set.
Ablation studies are also conducted using the public validation set to comply with leaderboard submission policies. This setup thoroughly evaluates CoRAG’s ability to handle complex multi-hop reasoning and diverse knowledge retrieval, demonstrating its effectiveness across different tasks.
Experiment Results
We evaluate CoRAG-8B on multi-hop QA datasets and the KILT benchmark. Its performance is compared against strong baseline models. The results analyze different retrieval strategies and decoding configurations.
Multihop QA performance
CoRAG-8B outperforms most baselines despite using a smaller LLM than Search-o1-32B and IterDRAG. Increasing the retrieval chain length (L) boosts performance, with L=10 (best-of-8) achieving the highest scores. The tree search decoding strategy also delivers strong results.
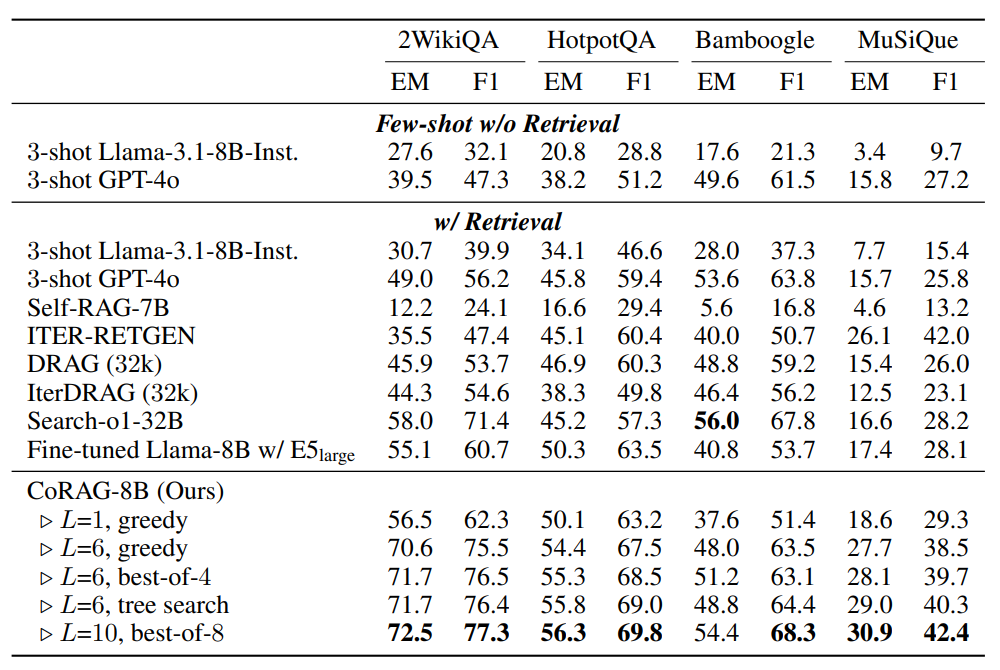
Results on multi-hop QA datasets | Source
However, CoRAG-8B performs slightly lower on Bamboogle, likely due to the dataset’s small size (125 instances), which causes high variance. Additionally, some Bamboogle questions also require more recent knowledge than the Wikipedia dump used for retrieval, giving an advantage to commercial search engine-based models like Search-o1-32B.
KILT Benchmark Performance
CoRAG-8B sets new performance records across all KILT tasks, except for FEVER, where it falls slightly behind an 11B-parameter model. It surpasses previous best scores in entity linking, slot filling, open QA, and fact-checking tasks.
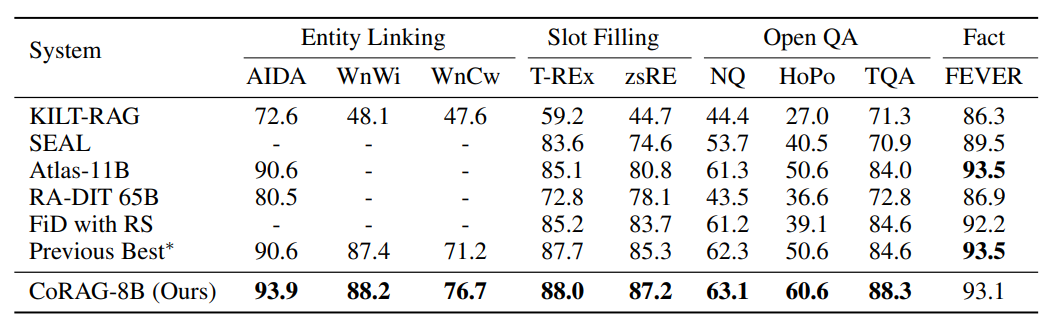
Results on the hidden test set of the KILT benchmark | Source
Scaling Test-Time Compute
CoRAG-8B allows test-time compute scaling to boost performance without changing model weights, similar to OpenAI o1. Two key factors influence this process:
Retrieval chain length (L): Increasing L improves performance significantly initially, but the benefits decrease beyond a certain point. This aligns with the intuition that longer chains support more reasoning steps and enable trial-and-error query refinements.
Best-of-N sampling: The impact of N depends on the dataset. A larger N enhances performance for complex datasets like MuSiQue, while a smaller N is sufficient for simpler datasets like 2WikiMultihopQA.
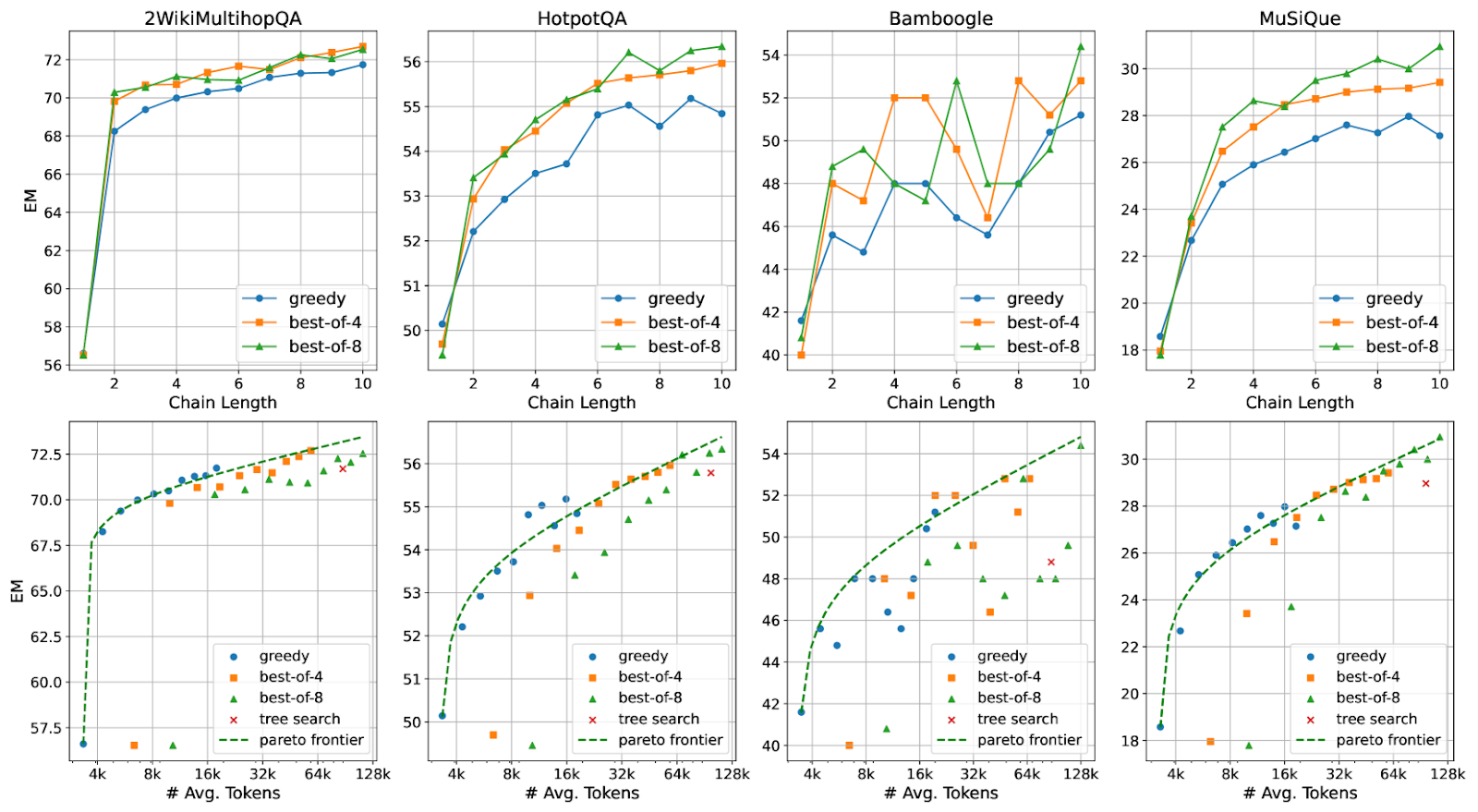
Scaling test-time compute on multi-hop QA datasets | Source
The Pareto frontier represents the set of optimal trade-offs where improving one factor, like accuracy, comes at the cost of another, such as token consumption. In the context of CoRAG-8B, it helps analyze how test-time compute scaling balances performance and efficiency. The observed log-linear pattern up to 128k tokens shows how increasing retrieval steps or sampling improves accuracy but with diminishing returns. Understanding this trade-off allows practitioners to optimize computational costs while maintaining high-quality responses, adapting strategies based on dataset complexity.
Key Findings
Iterative rejection sampling: CoRAG-8B benefits from self-improvement through iterative training, but results vary by dataset. While 2WikiMultihopQA sees gains, other datasets show slight declines, indicating that instruction-tuned LLMs already generate strong retrieval chains.
Robustness to different retrievers: CoRAG-8B performs well even with weaker retrievers like E5-base and BM25, though stronger retrievers still improve results. Investing in better retrievers enhances performance further.
Weak-to-strong generalization: Using smaller LLMs (Llama-3B, Llama-1B) for retrieval chain generation lowers compute costs. However, Llama-1B struggles with instructions, producing weaker retrieval chains. This trade-off suggests that weaker LLMs can enable more extensive search strategies, which may help in mathematical reasoning tasks.
Effectiveness of chain-of-retrieval: Multi-hop QA tasks benefit significantly from chain-of-retrieval, but single-hop tasks (e.g., NQ, TriviaQA) see limited advantages. This highlights the need for adaptive decoding based on query complexity.
Learning to stop at test time: Instead of retrieving a fixed number of steps, CoRAG-8B can decide when to stop dynamically. Early stopping saves tokens but may reduce accuracy. The optimal balance depends on dataset complexity and accuracy requirements.
CoRAG and Vector Databases
CoRAG builds upon RAG by iteratively refining queries and retrieving information step by step. It uses vector databases to find relevant information, improving reasoning over complex queries.
The Role of Vector Databases in CoRAG
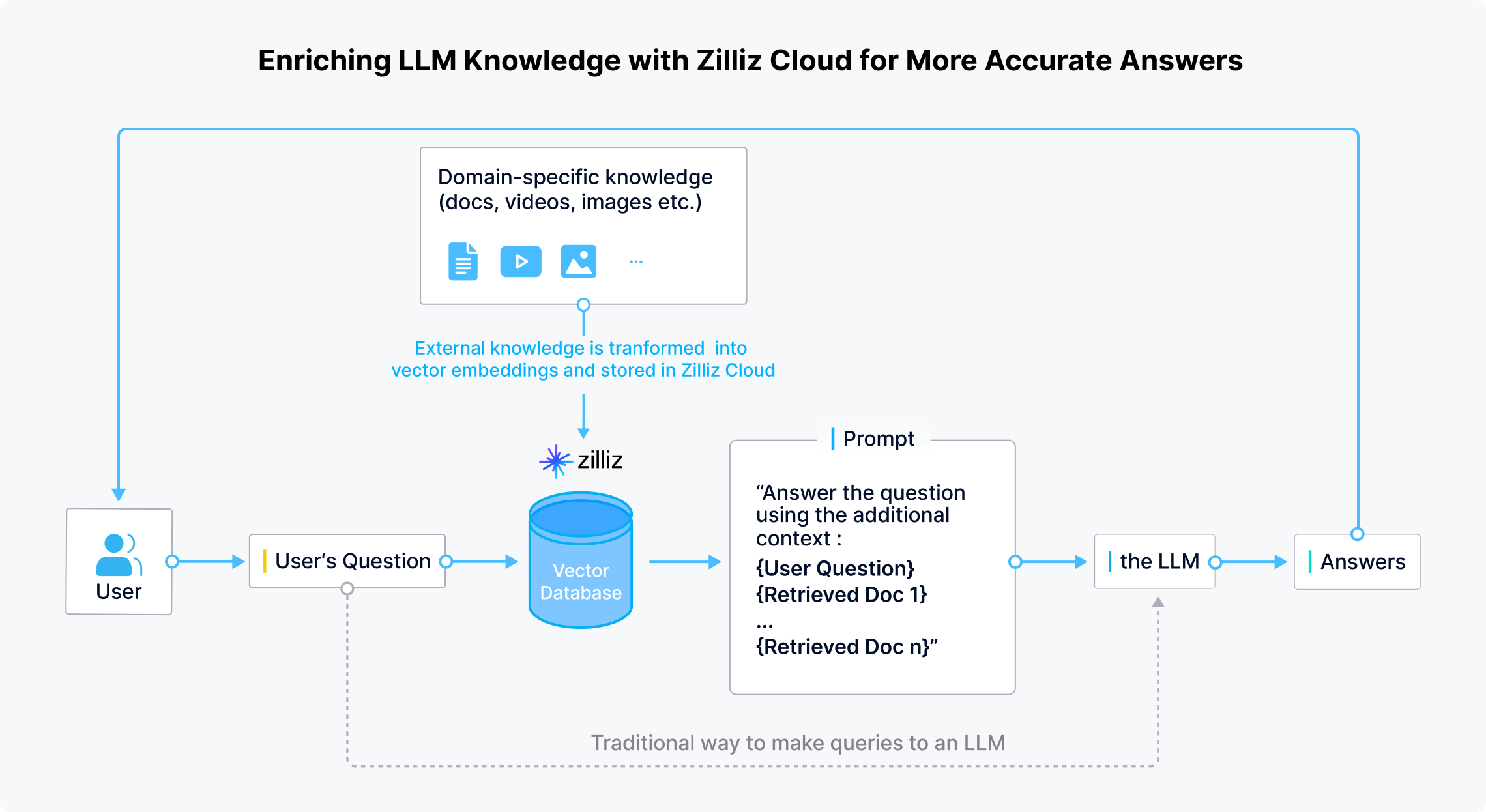
Vector databases are essential for CoRAG, enabling efficient retrieval of high-dimensional embeddings. Unlike traditional retrieval, which depends on static queries, CoRAG dynamically updates queries at each step. Vector databases power this process by performing fast semantic searches, ensuring each retrieval step provides the most relevant information. This is critical for multi-hop QA, open-domain reasoning, and knowledge-intensive tasks.
These databases index textual or multimodal data as dense vector embeddings, allowing for fast and accurate similarity searches using approximate nearest neighbor (ANN) search. When a query is generated, the vector database retrieves the closest matching embeddings based on cosine similarity or other distance metrics. This ensures that only the most contextually relevant information is passed to the generation model, improving factual accuracy and reducing hallucinations.
Milvus/Zilliz as a Vector Database/Cloud Platform
Milvus, an open-source vector database developed by Zilliz, is a powerful solution for managing and querying high-dimensional embeddings in RAG systems. Retrieval chains rely on efficient similarity search to retrieve relevant knowledge before generating responses, and Milvus is optimized for large-scale, real-time retrieval tasks.
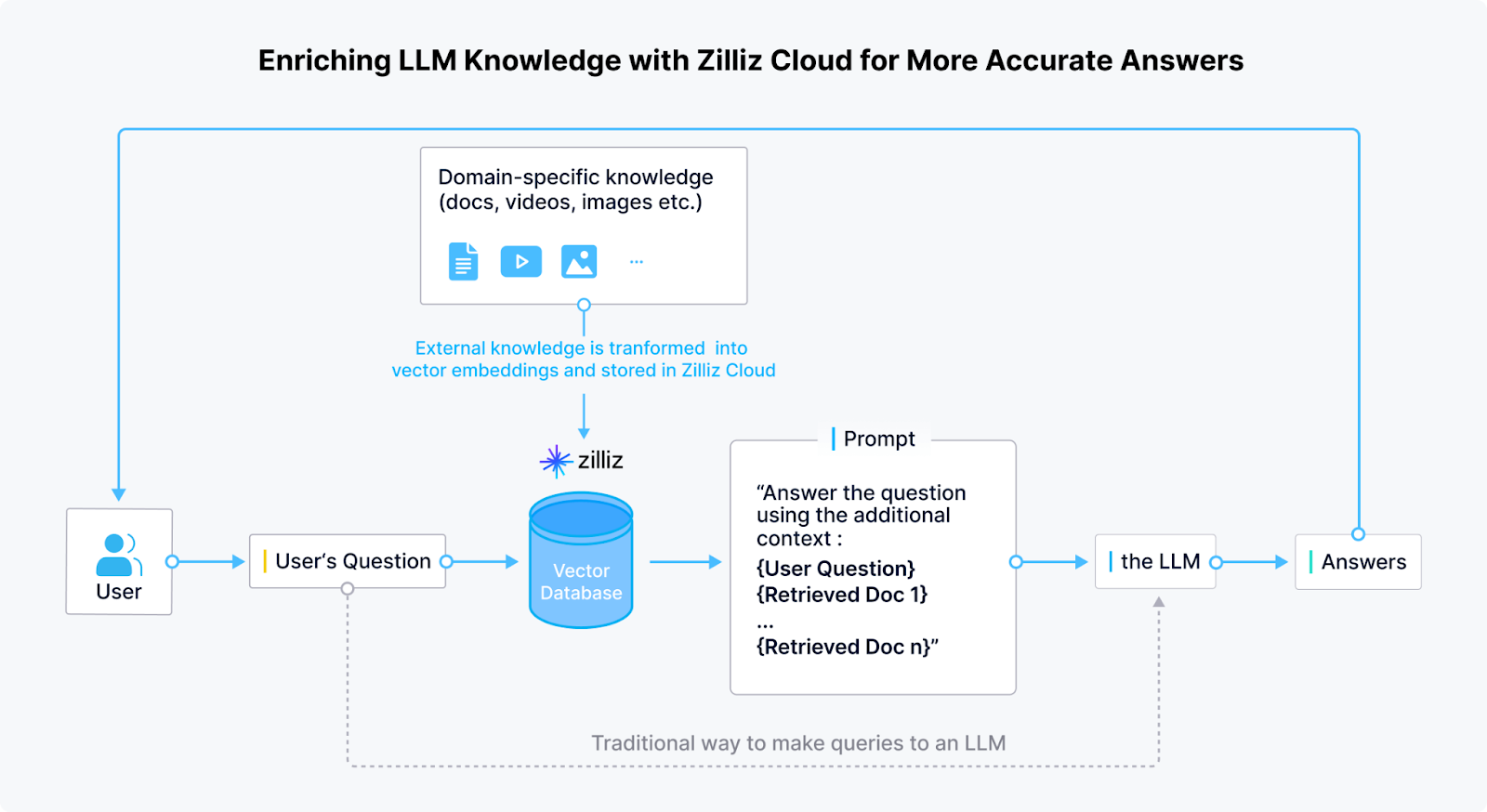
Enriching LLM knowledge with Zilliz cloud for more accurate answers | Source
{kind=link}
Milvus enables the storage and indexing of millions or even billions of vector embeddings, allowing RAG models to perform rapid semantic searches across vast knowledge bases. Moreover, it ensures low-latency retrieval by supporting multiple indexing algorithms. This is critical for applications where real-time information is essential, such as chatbots, search engines, and enterprise AI systems.
Zilliz extends Milvus with cloud-based solutions, making it easier for enterprises to deploy and scale vector search for RAG without managing infrastructure.
Conclusion and Potential Future Research Directions
CoRAG introduces an iterative retrieval and reasoning framework that helps LLMs handle complex queries more effectively. By using rejection sampling, it automates intermediate retrieval chain generation, reducing the need for manual annotations. CoRAG supports multiple decoding strategies, balancing performance with computational cost. CoRAG-8B achieves state-of-the-art results on multi-hop QA datasets and the KILT benchmark, outperforming several larger LLM-based models.
Future Research Directions
Several key areas can further enhance CoRAG’s capabilities and extend its applicability:
Refined scaling analysis: The current approach simplifies certain factors, such as treating prompt and generated tokens the same and ignoring retrieval costs. A more detailed analysis could provide a better understanding of efficiency and performance trade-offs.
Real-time retrieval integration: Existing methods rely on static datasets. Incorporating real-time retrieval from sources like web search engines could improve CoRAG’s ability to handle time-sensitive and evolving queries.
Further Resources
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- CoRAG Framework
- Experimental Setup
- Experiment Results
- Key Findings
- CoRAG and Vector Databases
- Conclusion and Potential Future Research Directions
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
LLM-Eval is an approach to simplifying and automating the evaluation of LLM conversation quality.

Mastering Cohere's Reranker for Enhanced AI Performance
Unlock the full potential of AI applications by diving into the fine-tuning process of Cohere's Reranker, a powerful tool for optimizing search results and recommendation systems.
Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
We’ll explore the limitations of binary relevance labels, how fine-grained relevance scoring works, and why it’s a game-changer for zero-shot text rankers