




Building a Multimodal RAG with Gemini 1.5, BGE-M3, Milvus Lite, and LangChain
Multimodal RAG extends RAG by accepting data from different modalities as context. Learn how to build one with Gemini 1.5, BGE-M3, Milvus, and LangChain.
Read the entire series
- Effortless AI Workflows: A Beginner's Guide to Hugging Face and PyMilvus
- Building a RAG Pipeline with Milvus and Haystack 2.0
- How to Pick a Vector Index in Your Milvus Instance: A Visual Guide
- Semantic Search with Milvus and OpenAI
- Efficiently Deploying Milvus on GCP Kubernetes: A Guide to Open Source Database Management
- Building RAG with Snowflake Arctic and Transformers on Milvus
- Vectorizing JSON Data with Milvus for Similarity Search
- Building a Multimodal RAG with Gemini 1.5, BGE-M3, Milvus Lite, and LangChain
Large Language Models (LLMs) are highly versatile when it comes to performing various natural language tasks, such as text generation, language translation, text summarization, question answering, and more. However, a significant limitation of using LLMs in our applications is the risk of hallucination.
Hallucination refers to the phenomenon where the response generated by the LLM appears convincing and coherent but is completely inaccurate. This issue can be difficult to detect, especially if we are not experts in the area on which the LLM's response is based.
This article will discuss a powerful solution for mitigating LLM hallucination called Retrieval Augmented Generation (RAG). Specifically, we will implement a multimodal RAG combining data with different modalities, such as text and images, to reduce LLM hallucination. So, without further ado, let’s start with a general understanding of RAG.
What is Retrieval Augmented Generation (RAG)?
Hallucination often occurs when we ask an LLM a question beyond its pre-trained knowledge. For example, if we ask an LLM about a highly specialized topic in medicine or law with numerous insider jargon, we risk obtaining a random, inaccurate response from our LLM.
One solution to mitigate this issue is fine-tuning our LLM with a dataset specific to our use case. Although LLM fine-tuning can be effective, it is highly expensive in terms of time and memory consumption.
RAG offers an alternative yet powerful approach to mitigate LLM hallucination. The concept is based on information retrieval methods, where we first take a user's query and then find the most relevant contexts in our database that can help our LLM answer the query accurately. By providing context alongside a user's query, we can significantly improve the accuracy of the LLM's response.
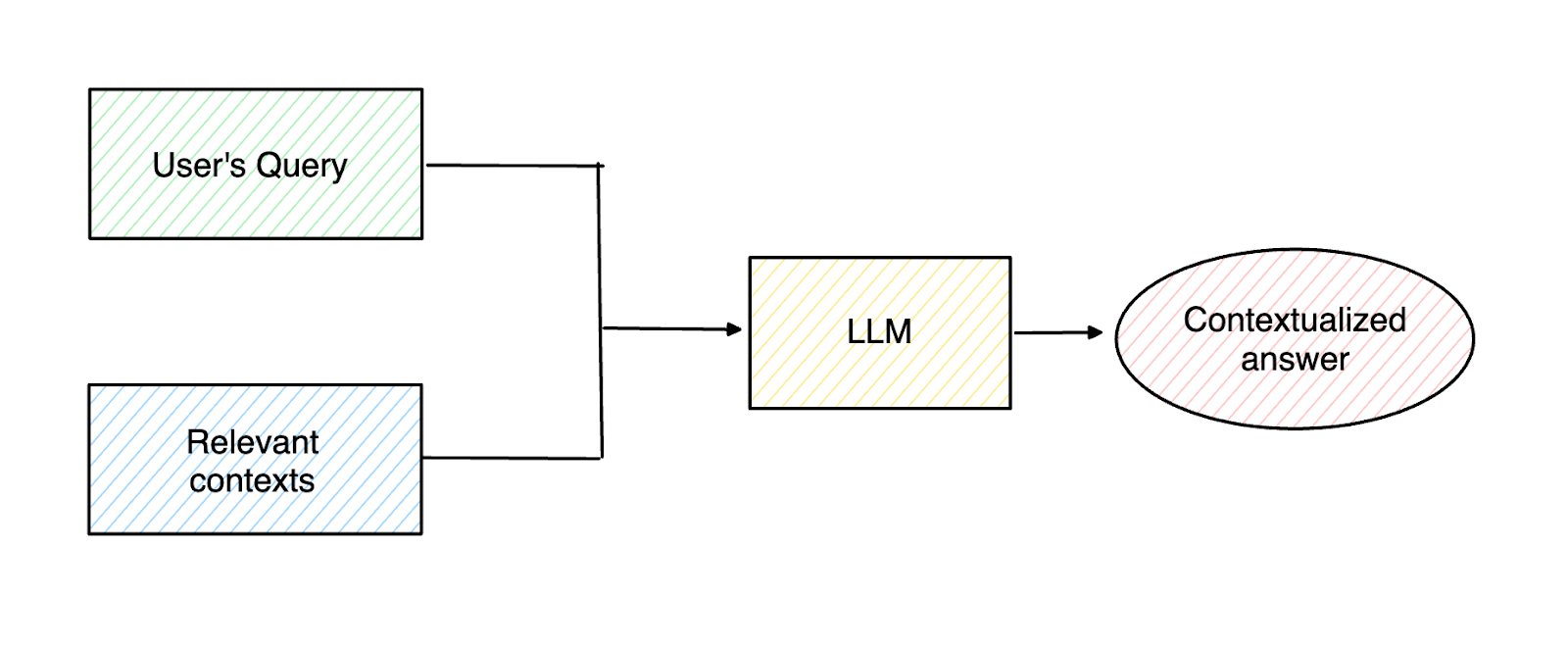 Figure 1- High-level concept of RAG
Figure 1- High-level concept of RAG
RAG itself consists of three components: retrieval, augmentation, and generation.
In the retrieval component, RAG fetches relevant contexts that can help the LLM generate a contextualized answer. To fetch the context, we must first transform all contextual information into vector embeddings using embedding models such as those from Sentence Transformers, OpenAI, VoyageAI, etc. Next, we store these embeddings inside a vector database like Milvus and Zilliz Cloud (the fully managed Milvus).
When a user query is present, we transform it into a vector embedding using the same model we used to encode the contexts. A vector database like Milvus will then perform a vector search (also known as vector similarity search or semantic similarity search) to compute the similarity between the query embedding and the context embeddings inside the vector database. Finally, the top-k results with the highest similarity to the user’s query will be retrieved as relevant contexts.
In the augmentation component, the relevant contexts fetched from the retrieval component are merged and composed together with the original user’s query to form a coherent prompt to be passed to our LLM. Finally, our LLM generates a contextualized response based on the provided prompt in the generation component.
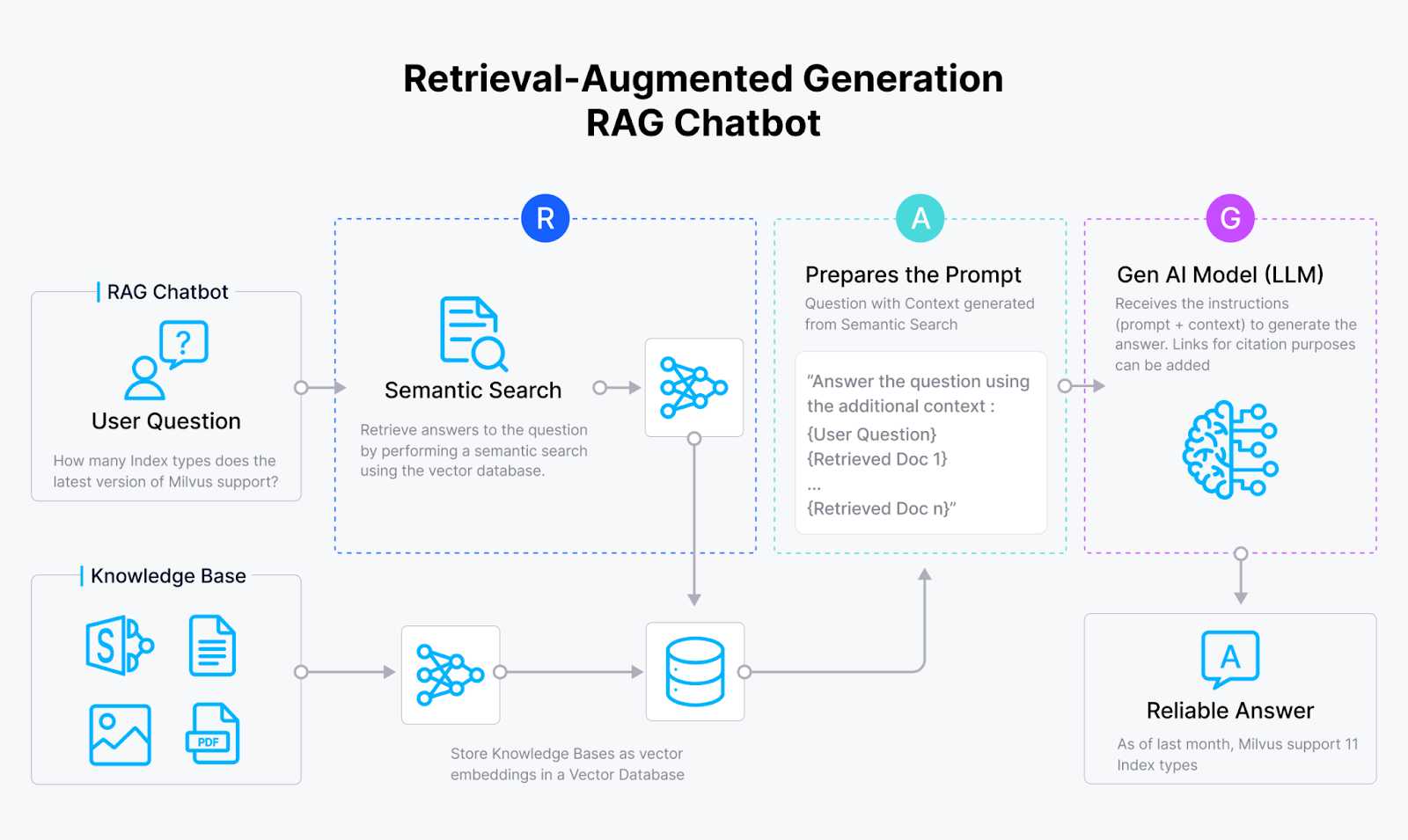 Figure 2- RAG workflow
Figure 2- RAG workflow
What is Multimodal RAG?
The concept of RAG, which provides relevant context alongside the user's query, has proven to be very powerful in improving the quality of LLM responses. However, not all relevant contexts are provided as text in real-world applications.
There may be cases where the most relevant context is provided as an image or a table in a document. The problem is that most LLMs and embedding models, due to their nature, can't infer the content inside an image. They also tend to struggle with inferring the content of tables or tabular data. As you might already know, LLMs are pre-trained to predict the next most probable token given previous tokens. This means that LLMs naturally try to make sense of text content sequentially, which doesn't hold for tabular data.
Multimodal RAG is a new approach that accepts data from different modalities as context to be passed into the LLM. We need to use LLMs with multimodal capabilities to perform multimodal RAG, such as LLAVA, GPT4-V, Gemini 1.5, Claude 3.5 Sonnet, etc. However, we can still use text-based embedding models, although multimodal embedding models such as CLIP are also a good option.
There are a couple of ways we can implement multimodal RAG:
Use a multimodal embedding model like CLIP to transform texts and images into embeddings. Next, retrieve relevant context by performing a similarity search between the query and text/image embeddings. Finally, pass the most relevant context's raw text and/or image to our multimodal LLM.
Use a multimodal LLM to produce text summarizations of images or tables. Next, transform those text summarizations into embeddings with a text-based embedding model. Then, perform a text similarity search between the query and summarization embeddings. Finally, pass the raw image of the most relevant summary to our LLM for response generation.
In the following sections, we'll implement the multimodal RAG based on the second approach. Specifically, we'll use the Gemini 1.5 model to produce text summarizations of images and tables and generate the final response.
Introduction to Milvus Lite, Gemini 1.5, BGE M3, and LangChain
We'll build a multimodal RAG system using four different technologies: Milvus as the vector database, Gemini 1.5 as the LLM, BGE M3 as the embedding model, and LangChain as the framework to build the overall RAG system. Let's discuss each of these technologies first.
Milvus Lite
Milvus is an open-source vector database that enables us to efficiently store billion-scale embeddings and perform fast vector searches during the retrieval stage of RAG. There are different options for installing Milvus, but the easiest way is with Milvus Lite. If you're a beginner and just want to start with Milvus, then Milvus Lite is the recommended approach. With just a simple pip install command, you can start utilizing Milvus to store up to a million embeddings. Here's the command to install Milvus Lite:
pip install pymilvus
However, as you scale your application and eventually deploy it into production, it's best to run Milvus in a Docker container or Kubernetes. To install and run Milvus via Docker container or Kubernetes, refer to the official Milvus installation page.
Gemini 1.5
Gemini 1.5 is a multimodal LLM developed by Google DeepMind as an improvement over the previous Gemini 1.0 model. This model is far superior to its predecessor in math, coding, multilingual capabilities, and understanding images, audio, and videos. Two distinct features set this model apart from its previous version: the model architecture and the context length.
Gemini 1.5's architecture combines the Transformer architecture with Mixture of Experts (MoE). This improves the model's efficiency as MoE models learn to selectively activate only the most relevant expert pathways in their neural network, depending on the user's input or prompt. This version also has a far longer context length than the previous version. Gemini 1.5 can handle up to 1 million tokens of context, compared to "only" 32,000 tokens in Gemini 1.0.
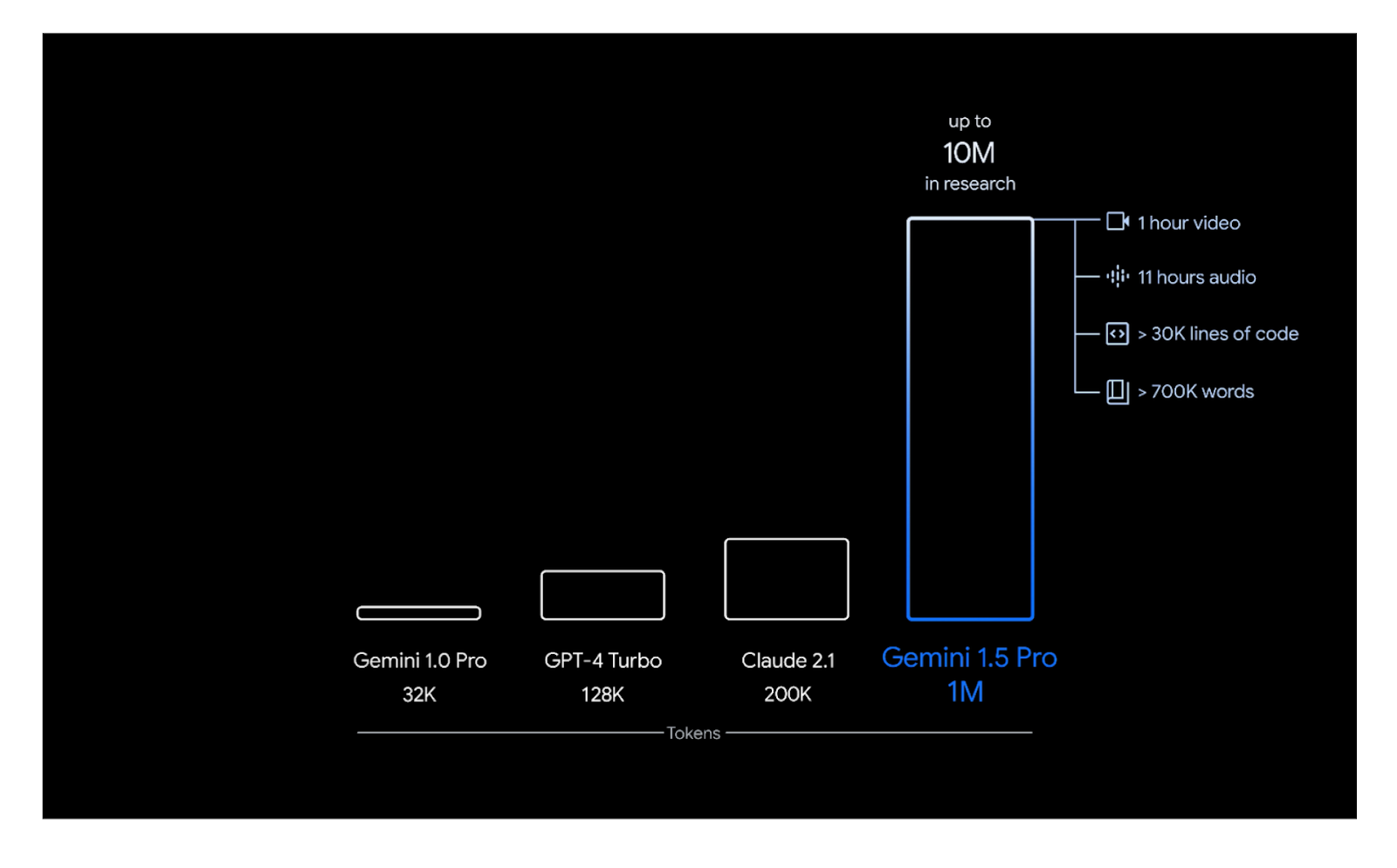 Figure 3- Gemini 1.5 Pro’s context length
Figure 3- Gemini 1.5 Pro’s context length
Figure 3: Gemini 1.5 Pro’s context length. Source
There are two variants of the Gemini 1.5 model to date: Flash and Pro. Flash is the lightweight version of Gemini 1.5, making it faster and more efficient in generating responses. Meanwhile, Pro is the most performant version of the Gemini 1.5 model, performing at a similar level to Gemini 1.0 Ultra, their largest model to date.
In this article, we'll be using Gemini 1.5 Pro. You need to set up an API key to access this model for our multimodal RAG application. Refer to this Google page for step-by-step instructions on generating the API key. In the next section, we'll use this API key in the multimodal RAG implementation.
BGE-M3
BGE-M3 is a highly versatile embedding model capable of processing texts in multiple languages at different granularity levels. For example, you can have text inputs in different languages ranging from short sentences to long documents up to 8192 tokens. This embedding model also outputs two different embeddings: one dense embedding and one sparse embedding.
Dense embedding has a more compact dimension than sparse embedding and holds the semantic representation of the original input. Meanwhile, as the name suggests, a sparse embedding is usually sparse, meaning it has high dimensionality, but most of the elements are zero. Therefore, a sparse embedding can be stored and processed more efficiently using specialized data structures and algorithms.
In the RAG implementation below, we'll use BGE-M3 as our embedding model to transform our text input into an embedding. We can implement BGE-M3 with Milvus using the following code:
!pip install "pymilvus[model]"
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
bge_m3_ef = BGEM3EmbeddingFunction(
model_name='BAAI/bge-m3', # Specify the model name
device='cpu', # Specify the device to use, e.g., 'cpu' or 'cuda:0'
use_fp16=False # Specify whether to use fp16. Set to `False` if `device` is `cpu`.
)
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
docs_embeddings = bge_m3_ef.encode_documents(docs)
# Print embeddings
print("Embeddings:", docs_embeddings)
"""
Output:
Embeddings: {'dense': [array([-0.02505937, -0.00142193, 0.04015467, ..., -0.02094924,
0.02623661, 0.00324098], dtype=float32), array([ 0.00118463, 0.00649292, -0.00735763, ..., -0.01446293,
0.04243685, -0.01794822], dtype=float32), array([ 0.00415287, -0.0101492 , 0.0009811 , ..., -0.02559666,
0.08084674, 0.00141647], dtype=float32)], 'sparse': <3x250002 sparse array of type '<class 'numpy.float32'>'
with 43 stored elements in Compressed Sparse Row format>}
"""
As you can see, we get two different types of vector embedding from one input: dense and sparse embedding. We can leverage these two embeddings during vector search as Milvus supports a hybrid search to enhance the accuracy and quality of the context retrieved in our RAG system.
LangChain
LangChain is a framework that helps us build LLM-powered applications in minutes. It is an orchestration tool connecting components, such as vector databases, embedding models, and LLMs, to build a fully functioning RAG system. This is achievable thanks to its easy integration with popular LLM providers like OpenAI, Anthropic, and Google, as well as vector database providers like Zilliz.
LangChain also handles the end-to-end workflow of a RAG system, starting from data preprocessing steps such as data parsing, cleaning, and chunking to the LLM response generation back to the user. We’ll see the detailed implementation of this framework in the next section.
Building a Multimodal RAG Application
In this section, we’ll build a multimodal RAG application. As mentioned, most LLMs struggle to process contexts in images or tables due to their pretraining nature. By implementing a multimodal RAG, we can take the contexts in an image into account, thereby improving the overall response quality of our LLM.
The use case for our multimodal RAG is as follows: we’ll build a RAG system that enables us to ask for any information related to a research paper saved in PDF format. The research paper we’ll be working with is "Attention is All You Need," which introduced the famous Transformer architecture.
First, we’ll download the PDF file and extract all the figures and tables. Next, we’ll use Gemini 1.5 Pro to generate summaries for each extracted figure and table for context retrieval. Then, we’ll use the BGE-M3 model to transform these summaries into embeddings and store them inside the Milvus vector database.
During the RAG implementation, we’ll transform a user query into an embedding and perform a vector search to find the most relevant summary. The raw figure or table of the most relevant summary according to the user query will then be fetched and passed to Gemini 1.5 for response generation.
If you’d like to follow along, you can access all of the code implementations in this article in this Notebook.
Let’s start from the very beginning: downloading the research paper of our choice. We can use the Arxiv API to do this, and here’s the code to download any research paper you want:
import arxiv
import os
import getpass
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_milvus.vectorstores import Milvus
from langchain.schema import Document
from langchain.embeddings.base import Embeddings
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
from langchain_core.messages import HumanMessage
from langchain_google_genai import ChatGoogleGenerativeAI
from IPython.display import HTML, display
from PIL import Image
import base64
from pdf2image import convert_from_path
import layoutparser as lp
import cv2
import numpy as np
file_path = "./Dataset/pdf/"
arxiv_client = arxiv.Client()
paper = next(arxiv.Client().results(arxiv.Search(id_list=["1706.03762"])))
# Download the PDF to a specified directory with a custom filename.
paper.download_pdf(dirpath=file_path, filename="attention.pdf")
You can download any research paper you want by providing the corresponding ID, which you can find in the URL when you view a research paper on Arxiv. For example, the ID of the "Attention is All You Need" paper is 1706.03762.
Next, let’s extract the figures and tables from our PDF file. Based on my observations, the Mask-RCNN model trained on the PubLayNet dataset is the most accurate for this task. LayoutParser is the perfect library to utilize this model and perform the extraction.
image_path = "./Dataset/img/"
def extract_image_and_table(pdf_path, output_dir):
images = convert_from_path(pdf_path)
model = lp.Detectron2LayoutModel('lp://PubLayNet/mask_rcnn_X_101_32x8d_FPN_3x/config',
extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.75],
label_map={0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"})
for i, image in enumerate(images):
image_np = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
layout_result = model.detect(image_np)
blocks = lp.Layout([b for b in layout_result if b.type=='Table' or b.type=='Figure'])
for j, block in enumerate(blocks._blocks):
x1 = int(block.block.x_1)
y1 = int(block.block.y_1)
x2 = int(block.block.x_2)
y2 = int(block.block.y_2)
cropped_image = Image.fromarray(image_np).crop((x1, y1, x2, y2))
cropped_image.save(f'{output_dir}/{i}_{j}.png', 'PNG')
extract_image_and_table(f"{file_path}attention.pdf", image_path)
Now that we have extracted all figures and tables from our research paper, it's time to generate a summary of each figure and table using Gemini 1.5 Pro. You'll need to use your API key to access this LLM.
The figures and tables we extracted from the PDF file are stored as PNG files. However, we can't use these raw image files as input to our multimodal LLM, as most APIs expect all inputs, including images, to be in text format. Therefore, we need to encode these image files into base64 format. This encoding scheme allows images to be sent as text strings in API requests.
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def image_summarize(img_base64, prompt):
msg = llm_model.invoke(
[
HumanMessage(
content=[
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{img_base64}"},
}
]
)
]
)
return msg.content
def generate_img_summaries(path):
# Store base64 encoded images
img_base64_list = []
# Store image summaries
image_summaries = []
# Prompt
prompt = """You are an assistant tasked with summarizing images for retrieval.
These summaries will be embedded and used to retrieve the raw image.
Give a concise summary of the image that is well optimized for retrieval."""
# Apply to images
for i, img_file in enumerate(sorted(os.listdir(path))):
if img_file.endswith(".png"):
img_path = os.path.join(path, img_file)
base64_image = encode_image(img_path)
img_base64_list.append(base64_image)
image_summaries.append(image_summarize(base64_image, prompt))
return img_base64_list, image_summaries
img_base64_list, image_summaries = generate_img_summaries(image_path)
documents = [Document(page_content=image_summaries[i], metadata={"source": img_base64_list[i]}) for i in range (len(image_summaries))]
Now let’s do a sanity check by looking at one example of a figure and its corresponding summarization generated by Gemini 1.5 Pro. You can do so by implementing the following code:
def plt_img_base64(img_base64):
# Create an HTML img tag with the base64 string as the source
image_html = f'<img src="data:image/jpeg;base64,{img_base64}" />'
# Display the image by rendering the HTML
display(HTML(image_html))
plt_img_base64(img_base64_list[0])
print(image summaries[0])
 Figure 5- Example of a table and its corresponding summarization
Figure 5- Example of a table and its corresponding summarization
The summarization generated by our Gemini 1.5 Pro model captures the overall essence and information provided in the figure. Next, we need to store these summaries alongside the encoded images in our Milvus vector database.
First, we need to transform the summaries into embeddings. As mentioned, we'll use the BGE-M3 model to perform this task. Later, we'll only use the dense embeddings generated from BGE-M3 for context retrieval.
To use this embedding model in LangChain, we need to create a custom class with two different methods: embed_documents and embed_query . LangChain will call these two functions by default when transforming our input into embeddings and storing them inside a vector database.
class BGEMilvusEmbeddings(Embeddings):
def __init__(self):
self.model = BGEM3EmbeddingFunction(
model_name='BAAI/bge-m3', # Specify the model name
device='cpu', # Specify the device to use, e.g., 'cpu' or 'cuda:0'
use_fp16=False # Specify whether to use fp16. Set to `False` if `device` is `cpu`.
)
def embed_documents(self, texts):
embeddings = self.model.encode_documents(texts)
return [i.tolist() for i in embeddings["dense"]]
def embed_query(self, text):
embedding = self.model.encode_queries([text])
return embedding["dense"][0].tolist()
# Instantiate embedding model and LLM
embedding_model = BGEMilvusEmbeddings()
os.environ['GOOGLE_API_KEY'] = getpass.getpass('Gemini API Key:')
llm_model = ChatGoogleGenerativeAI(model="gemini-1.5-pro",
temperature=0.7, top_p=0.85)
URI = "./milvus_demo.db"
# Create Milvus vector store and store the embeddings inside it
vectorstore = Milvus.from_documents(
documents,
embedding_model,
connection_args={"uri": URI},
collection_name="multimodal_rag_demo"
)
# Create a retriever from the vector store
retriever = vectorstore.as_retriever()
And that’s it! Now we’re ready to perform RAG.
Let’s say we submit a query: “What's the BLEU score of the base model on English to German translation task?”. We can examine the most relevant image retrieved by our RAG system with the following code:
# Use the retriever
query = "What's the BLEU score of the base model on English to German translation task?"
retrieved_docs = retriever.invoke(query, limit= 1)
plt_img_base64(retrieved_docs[0].metadata["source"])
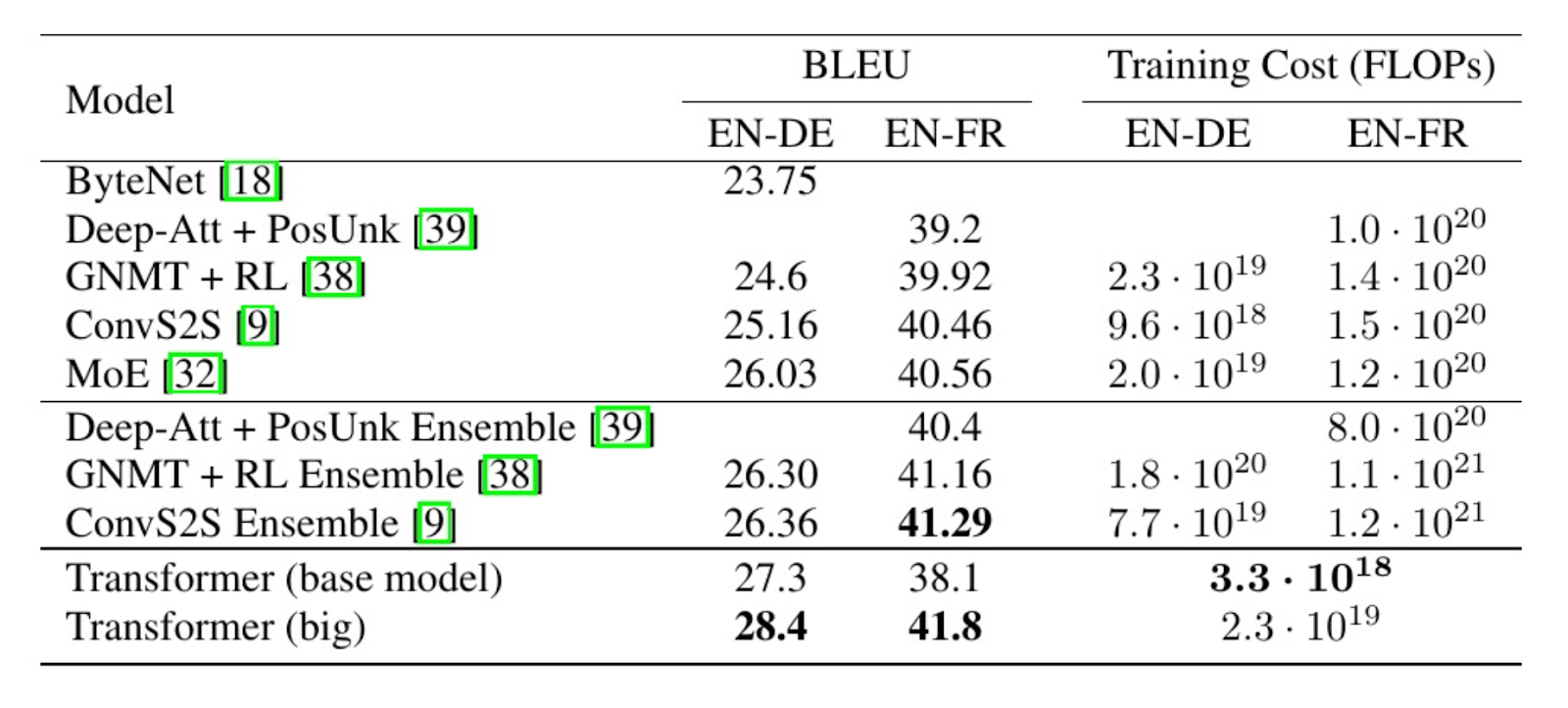 Figure 6- Example of the retrieved context for a given query
Figure 6- Example of the retrieved context for a given query
As you can see, our RAG system can fetch the most relevant image according to our query. In the RAG pipeline, this image will be used as context for our Gemini 1.5 Pro to generate a contextualized answer.
The only thing left to do is build the end-to-end workflow for response generation. This process includes receiving a user query, fetching the most relevant context, incorporating that context and user query into one coherent prompt, passing the prompt to the LLM, and finally generating a response from the LLM back to the user. We can accomplish all of these steps in several lines of code with LangChain, as you can see below:
def prepare_image_context(docs):
b64_images = []
for doc in docs:
b64_images.append(doc.metadata["source"])
return {"images": b64_images}
def img_prompt(data_dict):
messages = []
if data_dict["context"]["images"]:
for image in data_dict["context"]["images"]:
image_message = {
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image}"},
}
messages.append(image_message)
text_message = {
"type": "text",
"text": (
"You will be given an image or a table.n"
"Use information contained in the image or table to provide contextualized answer related to the user question. n"
f"User-provided question: {data_dict['question']}nn"
),
}
messages.append(text_message)
return [HumanMessage(content=messages)]
def multi_modal_rag_chain(retriever):
# RAG pipeline
chain = (
{
"context": retriever | RunnableLambda(prepare_image_context),
"question": RunnablePassthrough(),
}
| RunnableLambda(img_prompt)
| llm_model
| StrOutputParser()
)
return chain
# Create RAG chain
chain_multimodal_rag = multi_modal_rag_chain(retriever)
And we can invoke our RAG pipeline according to a query with one line of code:
# Run RAG chain
chain_multimodal_rag.invoke(query)
"""
Output:
The BLEU score of the base Transformer model on English to German translation task is 27.3.
"""
Refer to this notebook for the full code of this demo.
Conclusion
Congratulations! You've successfully built a multimodal RAG system using Milvus, Gemini 1.5, BGE-M3, and LangChain. Multimodal RAG is a highly useful system for enhancing an LLM's response accuracy to specific user queries, especially when the relevant context is stored in formats other than text.
You can now adapt this RAG concept to inquire about other research papers or explore different use cases. We only stored around 15 contexts inside our vector database in the above demo. However, Milvus Lite allows you to store up to a million embeddings, and we encourage you to expand or try different use cases by storing more contexts in your vector database using Milvus Lite or Milvus on Docker/Kubernetes or Zilliz Cloud (the fully managed Milvus).

- What is Retrieval Augmented Generation (RAG)?
- What is Multimodal RAG?
- Introduction to Milvus Lite, Gemini 1.5, BGE M3, and LangChain
- Building a Multimodal RAG Application
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Building a RAG Pipeline with Milvus and Haystack 2.0
This guide will demonstrate the integration of Milvus and Haystack 2.0 to build a powerful RAG applications.

How to Pick a Vector Index in Your Milvus Instance: A Visual Guide
In this post, we'll explore several vector indexing strategies that can be used to efficiently perform similarity search, even in scenarios where we have large amounts of data and multiple constraints to consider.

Efficiently Deploying Milvus on GCP Kubernetes: A Guide to Open Source Database Management
Self-hosting Milvus on Kubernetes (K8s), especially in the Google Cloud Platform (GCP) environment, offers numerous benefits. Read about the benefits and how to set up the Kubernetes cluster on GCP in the blog.