




Everything You Need to Know about Llama 2

Everything You Need to Know about Llama 2
What Is Llama 2?
Llama 2, introduced by Meta AI in 2023, is a significant advancement in large language models (LLMs). These models, Llama 2 and Llama 2-CHAT, scale up to 70 billion parameters and are available for research and commercial purposes at no cost, representing a leap forward in natural language processing (NLP) capabilities, from text generation to programming code interpretation.
Building upon its predecessor, LLaMa 1, which was initially accessible only to research institutions under a noncommercial license, Llama 2 marks an important shift towards democratizing access to cutting-edge AI technologies. Unlike its predecessor, Llama 2 models are “open-source” and thus freely available for research and commercial applications, reflecting Meta's commitment to fostering a more inclusive and collaborative generative AI ecosystem.
The release of Llama 2 provides access to state-of-the-art LLMs and addresses the computational challenges associated with their development. By optimizing performance without exponentially increasing parameter count, Llama 2 offers models with varying parameter sizes, ranging from 7 billion to 70 billion. This strategic approach enables smaller organizations and research communities to harness the power of LLMs without exorbitant computing resources.
Moreover, Meta's dedication to transparency is evident in its decision to release both the code and model weights of Llama 2, facilitating greater understanding and collaboration within the AI research community. By lowering barriers to entry and promoting accessibility, Llama 2 paves the way for a more inclusive and innovative future in AI research and development.
Llama 2
Llama 2 is an updated version of Llama 1 trained on a new mix of public data. The pretrained data set was increased by 40%, the context length was doubled, and the Meta team adopted grouped-query attention when building Llama 2.
| Training Data | Parameters | Context Length | Group-query attention | Tokens | |
| Llama 1 | See Touvron et al.(2023) | 7B | 2K | - | 1.0T |
| 13B | 2K | - | 1.0T | ||
| 33B | 2K | - | 1.4T | ||
| 65B | 2K | - | 1.4T | ||
| Llama 2 | A new mix of publiclyavailable online data | 7B | 4K | - | 2.0T |
| 13B | 4K | - | 2.0T | ||
| 34B | 4K | ✓ | 2.0T | ||
| 70B | ✓ | 2.0T |
Llama 2-CHAT
Llama 2-CHAT is a fine-tuned version of Llama 2 that the Meta team optimized for natural language use cases. This model's variants are available with 7B, 13B, and 70B parameters. Llama 2-Chat is subject to the same well-recognized limitations of other LLMs, including a cessation of knowledge updates post-pretraining, potential for non-factual generation such as unqualified advice, and a propensity towards hallucinations.
Llama 2 open source
While Meta has generously provided access to the starting code and model weights for Llama 2 models for research and commercial purposes, discussions have arisen regarding the appropriateness of labeling it as "open source" due to certain restrictions outlined in its licensing agreement.
The debate surrounding the classification of Llama 2's licensing terms hinges on technical and semantic nuances. While "open source" is commonly used colloquially to denote any software with freely accessible source code, it carries a specific meaning as a formal designation overseen by the Open Source Initiative (OSI). To qualify as "Open Source Initiative approved," a software license must adhere to the ten criteria outlined in the official Open Source Definition (OSD).
As such, the applicability of the "open source" label to Llama 2 models depends on whether its licensing terms align with the stringent criteria set forth by the OSI. This distinction underscores the importance of clarity and precision in discussing the accessibility and distribution of software resources within the broader development community.
However, while Llama 2 isn't fully open-source, it offers developers a compelling model with way more flexibility than the closed models created by OpenAI, Google, and other major players in the generative AI field.
Llama 2 Architecture
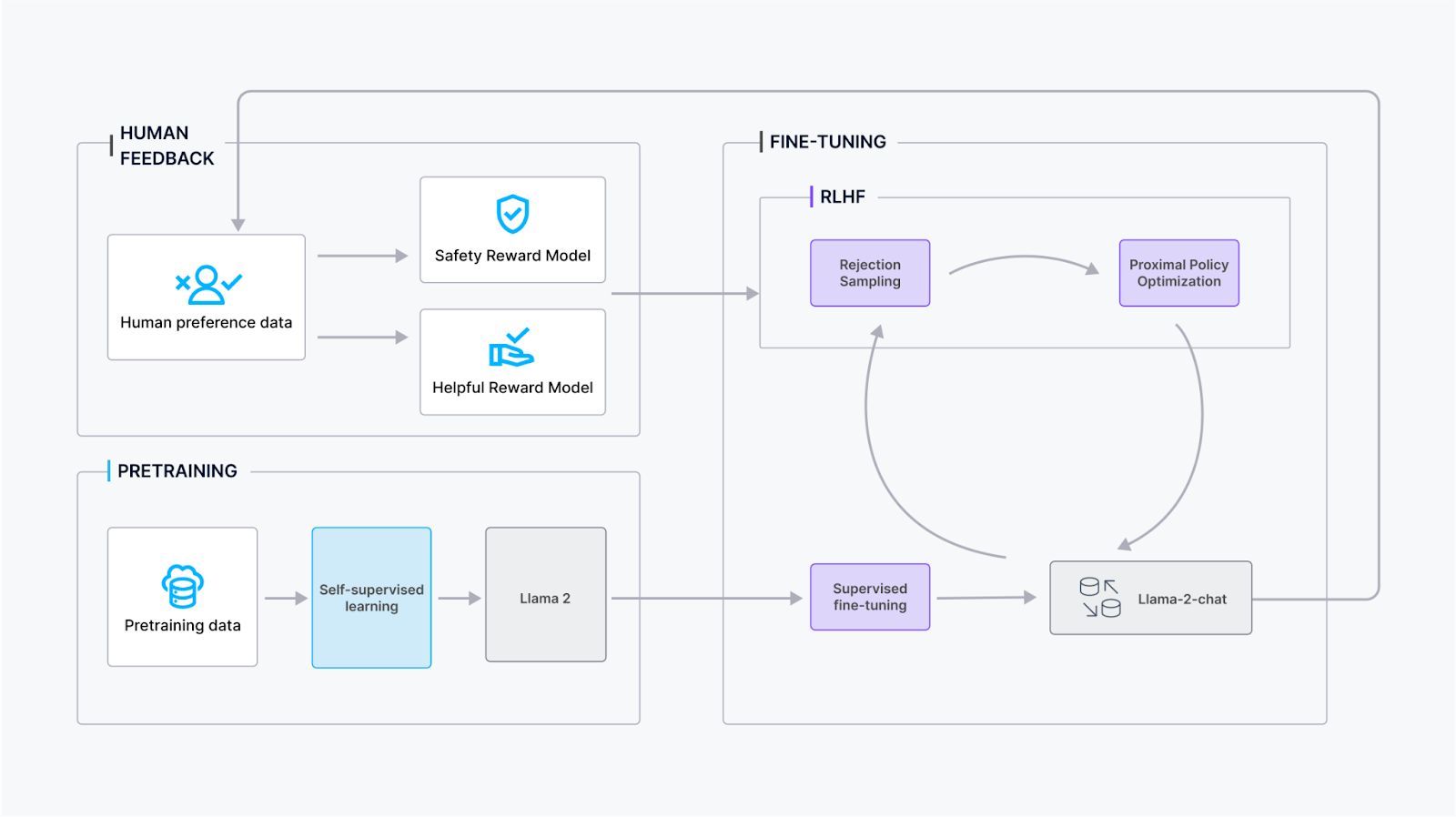
The training process for Llama 2-Chat involves several stages to ensure optimal performance and refinement:
Pretraining: Llama 2 undergoes pretraining using publicly available online sources to establish foundational knowledge and language understanding.
Supervised Fine-Tuning: The Meta team created an initial version of Llama 2-Chat through supervised fine-tuning, where the model learns from labeled data to improve its conversational capabilities.
Reinforcement Learning with Human Feedback (RLHF): The model undergoes iterative refinement using RLHF methodologies, mainly through rejection sampling and Proximal Policy Optimization (PPO). This stage involves continuous interaction with human feedback to improve conversational quality.
Iterative Reward Modeling: Throughout the RLHF stage, iterative reward modeling data accumulation occurs in parallel with model enhancements. Iterative reward modeling ensures that reward models remain within distribution, contributing to consistently improving the model's conversational abilities.
By incorporating these steps, Llama 2-Chat's training aims to achieve robust conversational performance while adapting to user feedback and maintaining alignment with reward models.
What is an Embedding in Machine Learning?
In machine learning, an embedding refers to a learned representation of objects in a continuous vector space, such as words, images, or entities. These embeddings capture semantic relationships and similarities between objects, making them more suitable for computational tasks. In natural language processing (NLP), word embeddings, for example, map words from a vocabulary to dense vectors in a high-dimensional space, where similar words are close to each other.
In Llama 2, embeddings play a crucial role in understanding and generating natural language. Llama 2 uses embeddings to represent words, phrases, or entire sentences in a continuous vector space. Llama 2 can effectively process and generate text by embedding language inputs and outputs while capturing semantic relationships and nuances.
For instance, Llama 2 learns embeddings for words and phrases from the vast corpus of text it is trained on during the training process. These embeddings encode semantic information about the language, enabling Llama 2 to understand and generate coherent responses to queries or prompts.
Embeddings in machine learning, including those used in Llama 2, facilitate the representation of language and other data in a structured and semantically meaningful way, enabling effective processing, understanding, and generation of natural language.
How to Use Llama 2?
To effectively use Llama 2, access the model via the provided interface or API, ensuring permissions are in place. Prepare your input data, whether text, images, or compatible formats, and preprocess it as needed. Specify the task for Llama 2, such as text generation or summarization. Feed preprocessed data into Llama 2, retrieve the output, and evaluate its quality. Experiment with different formats and configurations to optimize results. Monitor performance metrics like accuracy and speed, adjusting strategies based on feedback. Stay updated on enhancements to maximize effectiveness, unlocking new possibilities for projects and applications. You can also use Llama 2 with tools like LangChain, LlamaIndex, and Semantic Kernel when building RAG applications.
Llama 2 Performance
The overall performance can be viewed by looking at some popular aggregated benchmarks. Here is a table of results on the performance compared to open-source based models as noted in the LLama 2 paper:
| Model | Size | Code | Commonsense Reasoning | World Knowledge | Reading Comprehension | Math | MMLU | BBH | AGI Eval |
| MPT | 7B | 20.5 | 57.4 | 41.0 | 57.5 | 4.9 | 26.8 | 31.0 | 23.5 |
| 30B | 28.9 | 64.9 | 50.0 | 64.7 | 9.1 | 46.9 | 38.0 | 33.8 | |
| Falcon | 7B | 5.6 | 56.1 | 42.8 | 36.0 | 4.6 | 26.2 | 28.0 | 21.2 |
| 40B | 15.2 | 69.2 | 56.7 | 65.7 | 12.6 | 55.4 | 37.1 | 37.0 | |
| Llama 1 | 7B | 14.1 | 60.8 | 46.2 | 58.5 | 6.95 | 35.1 | 30.3 | 23.9 |
| 13B | 18.9 | 66.1 | 52.6 | 62.3 | 10.9 | 46.9 | 37.0 | 33.9 | |
| 33B | 26.0 | 70.0 | 58.4 | 67.6 | 21.4 | 57.8 | 39.8 | 41.7 | |
| 65B | 30.7 | 70.7 | 60.5 | 68.6 | 30.8 | 63.4 | 43.5 | 47.6 | |
| Llama 2 | 7B | 16.8 | 63.9 | 48.9 | 61.3 | 14.6 | 45.3 | 32.6 | 29.3 |
| 13B | 24.5 | 66.9 | 55.4 | 65.8 | 28.7 | 54.8 | 39.4 | 39.1 | |
| 33B | 27.8 | 69.9 | 58.7 | 68.0 | 24.2 | 62.6 | 44.1 | 43.4 | |
| 65B | 37.5 | 71.9 | 63.6 | 69.4 | 35.2 | 68.9 | 51.2 | 54.2 |
You can see that Llama 2 outperforms Llama 1 in a number of categories like MMLU and BBH, and even does a good job against the Falcon model.
Llama 2 vs GPT 4
The Llama 2 paper also covers some comparisons with Llama 2 and GPT 4 and a few others, as shown below:
| Benchmark (shots) | GPT-3.5 | GPT-4 | PaLM | PaLM-2-L | Llama 2 |
| MMLU (5 shot) | 70.0 | 86.4 | 69.3 | 78.3 | 68.9 |
| TriviaQA (1-shot) | — | — | 81.4 | 86.1 | 85.3 |
| Natural Questions (1-shot) | — | — | 29.3 | 37.5 | 33.0 |
| GSM8K (8-shot) | 57.1 | 92.0 | 56.5 | 80.7 | 56.8 |
| HumanEval (0-shot) | 48.1 | 67.0 | 26.2 | — | 29.9 |
| BIG-Bench Hard (3-shot) | — | — | 52.3 | 65.7 | 51.2 |
- MMLU (5-shot): The model is given 5 passages or examples to generate a response.
- TriviaQA (1-shot): A dataset where the model is provided with a single context or question before generating an answer.
- Natural Questions (1-shot): Another dataset where the model is given one question as input.
- GSM8K (8-shot): A dataset where the model is given 8 passages or examples to answer questions or perform tasks.
- HumanEval (0-shot): A dataset or evaluation setting where the model is evaluated on tasks or questions it hasn't been explicitly trained on, hence "0-shot."
Does Zilliz Work with Llama 2?
The most common use case for Zilliz Cloud in conjunction with Llama 2 is the development of Retrieval Augmented Generation (RAG) applications. RAG applications leverage the capabilities of large language models (LLMs) like Llama 2, which are trained on vast datasets but inherently operate within the bounds of finite data. On its own, Llama 2 has the propensity to "hallucinate" responses, generating answers even when there might not be sufficient context or accurate information. RAG is one way to address this hallucination.
The combination of Zilliz Cloud and Llama 2 allows users to integrate advanced language understanding and generation capabilities seamlessly with efficient and scalable vector-based retrieval systems provided by Zilliz Cloud. By harnessing the strengths of both platforms, developers can create sophisticated applications that excel in tasks requiring comprehensive language processing, information retrieval, and generation functionalities.
Key Resources
- What Is Llama 2?
- Llama 2 Architecture
- What is an Embedding in Machine Learning?
- How to Use Llama 2?
- Llama 2 Performance
- Llama 2 vs GPT 4
- Does Zilliz Work with Llama 2?
- Key Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free