




Large Language Models and Search
Explore the integration of Large Language Models (LLMs) and search technologies, featuring real-world applications and advancements facilitated by Zilliz and Milvus.
Read the entire series
- OpenAI's ChatGPT
- Unlocking the Secrets of GPT-4.0 and Large Language Models
- Top LLMs of 2024: Only the Worthy
- Large Language Models and Search
- Introduction to the Falcon 180B Large Language Model (LLM)
- OpenAI Whisper: Transforming Speech-to-Text with Advanced AI
- Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
- What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
- LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
- Mastering Cohere's Reranker for Enhanced AI Performance
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
- Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
- RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
- Prover-Verifier Games Improve Legibility of LLM Outputs
- Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
- Unlocking the Power of Many-Shot In-Context Learning in LLMs
- Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
- Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
- Everything You Need to Know About LLM Guardrails
- Chain-of-Retrieval Augmented Generation
- Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
Large language models (LLMs) have changed the field of artificial intelligence. They are trained on vast amounts of text data to generate human-like responses. LLMs have demonstrated remarkable versatility and power in various applications, from chatbots to language translation systems. However, one area where their impact is particularly pronounced is in improving search capabilities.
Advanced search technologies are essential in today's data-driven world, where the volume and complexity of information continue to grow exponentially. Zilliz and its flagship open-source product, Milvus, are crucial in advancing search technologies by enabling the fusion of generative AI models, such as OpenAI LLMs, with traditional search methods. Milvus offers optimal query performance for many vector search applications, efficiently indexing and searching large-scale, unstructured data. Its advanced indexing and search algorithms are tailored to handle the complexities of modern datasets, making Milvus an indispensable tool for organizations seeking to leverage the power of LLMs in their search applications. Let's jump into some actual examples of how LLM synergizes with search.
Retrieval-Augmented Generation (RAG) with Milvus
Although LLMs have powerful abilities for text generation as they are pre-trained on large amounts of publicly available data, they still have limitations, such as generating fabricated information in prompts that they don't have enough data to reference (also referred to as a hallucination) or lack knowledge of domain-specific, proprietary, or private information. Vector databases such as Milvus bring external data sources to the LLMs, aiming to mitigate these limitations. Such systems have been referred to as RAG. For example, by leveraging Milvus's vector search capabilities, users can integrate generative models to generate relevant content (e.g., images, text) and quickly find the most similar results in a large database.
Let's see how we can use Milvus, LlamaIndex and OpenAI to create a demo RAG system.
LlamaIndex is a data framework for LLM-based applications that allows easy ingest, structure, and access to private or domain-specific data to inject these safely and reliably into LLMs for more accurate text generation. OpenAI is an LLM trained to generate human-like text, and you already know what Milvus is: a reliable open-source vector database.
Implementation steps
Visit Zilliz Cloud and sign up for free with the Starter version. Then, copy the cluster setup arguments, which are the collection name, API keys, and URI. After that, fire up a Google Colab notebook and paste that info into a cell, as shown below.
# Zilliz Cloud Setup Arguments
COLLECTION_NAME = 'RAG' # Collection name of your choice
URI = 'https://in03-277eeacb6460f14.api.gcp-us-west1.zillizcloud.com' # Endpoint URI obtained from Zilliz Cloud
API_KEY = 'Your key' # Also obtained from Zilliz Cloud
A common way to interact with large language models currently involves a chat interface where you type out your prompt for the LLM to give your back an answer as illustrated in figure one.
 Fig 1. A flowchart of user interaction with an LLM
Fig 1. A flowchart of user interaction with an LLM
But from the challenges we highlighted earlier that LLM faces such as hallucination, limited domain knowledge etc., we implement a RAG system as illustrated on figure below to add external data for better performance. Let's break down the flow chart including a code example on a Colab notebook.
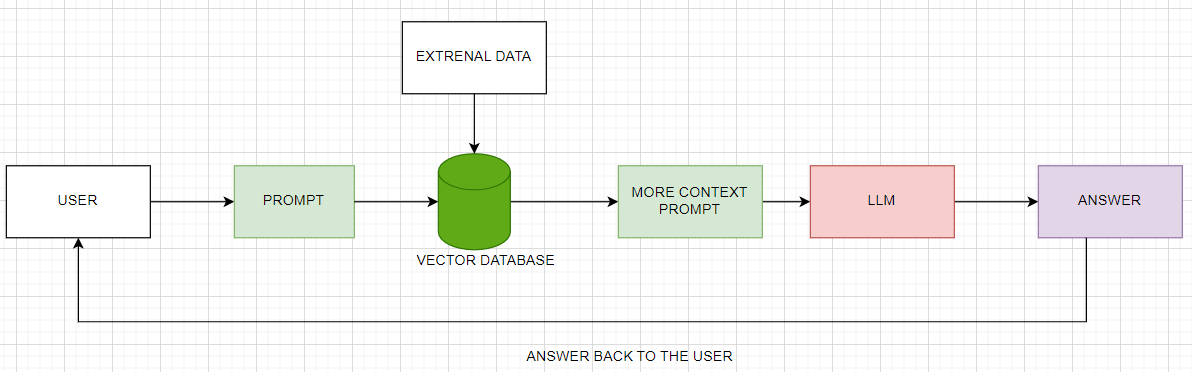 Fig 2. A flowchart of user interaction with an LLM in a RAG system.png
Fig 2. A flowchart of user interaction with an LLM in a RAG system.png
On figure 2, we see that a user comes up with a prompt. Then the prompt is passed to the vector database for a similarity search with existing external data. This is where indexing happens. Indexing is the process of organizing and structuring data in a way that makes it easier and faster to retrieve and search through. For example Milvus provides several index types to sort field values for efficient similarity searches. In Zilliz Cloud, the index is taken care of for you (autoindex). It also offers three metric types: Cosine Similarity (COSINE), Euclidean Distance (L2), and Inner Product (IP) to measure the distances between vector embeddings which you can configure on Zilliz cloud as shown in figure 3 or use your favorite programming language such as Python, NodeJS, Java, Go to do the configuration.
 Fig. 3 creating a schema from Zilliz Cloud.png
Fig. 3 creating a schema from Zilliz Cloud.png
Enhancing Query Understanding with Zilliz
After ingesting the prompt and relevant data into Milvus, the next step is to enhance query understanding by leveraging natural language processing (NLP) capabilities. For example, Milvus is equipped with advanced indexing techniques that allow for a search for semantic similarity. When a user asks a question about a document, Milvus retrieves similar documents based on semantic similarities encoded in vector representations. This ensures that relevant documents are considered during query processing. Here is an illustration of Zilliz Cloud. Figure 4 shows an example of embedding a part of the data we ingested in Milvus on the collab notebook we shared earlier. Suppose we wanted to query the most relevant part of the document in reference to what we have in Figure 4. Milvus allows for vector search.
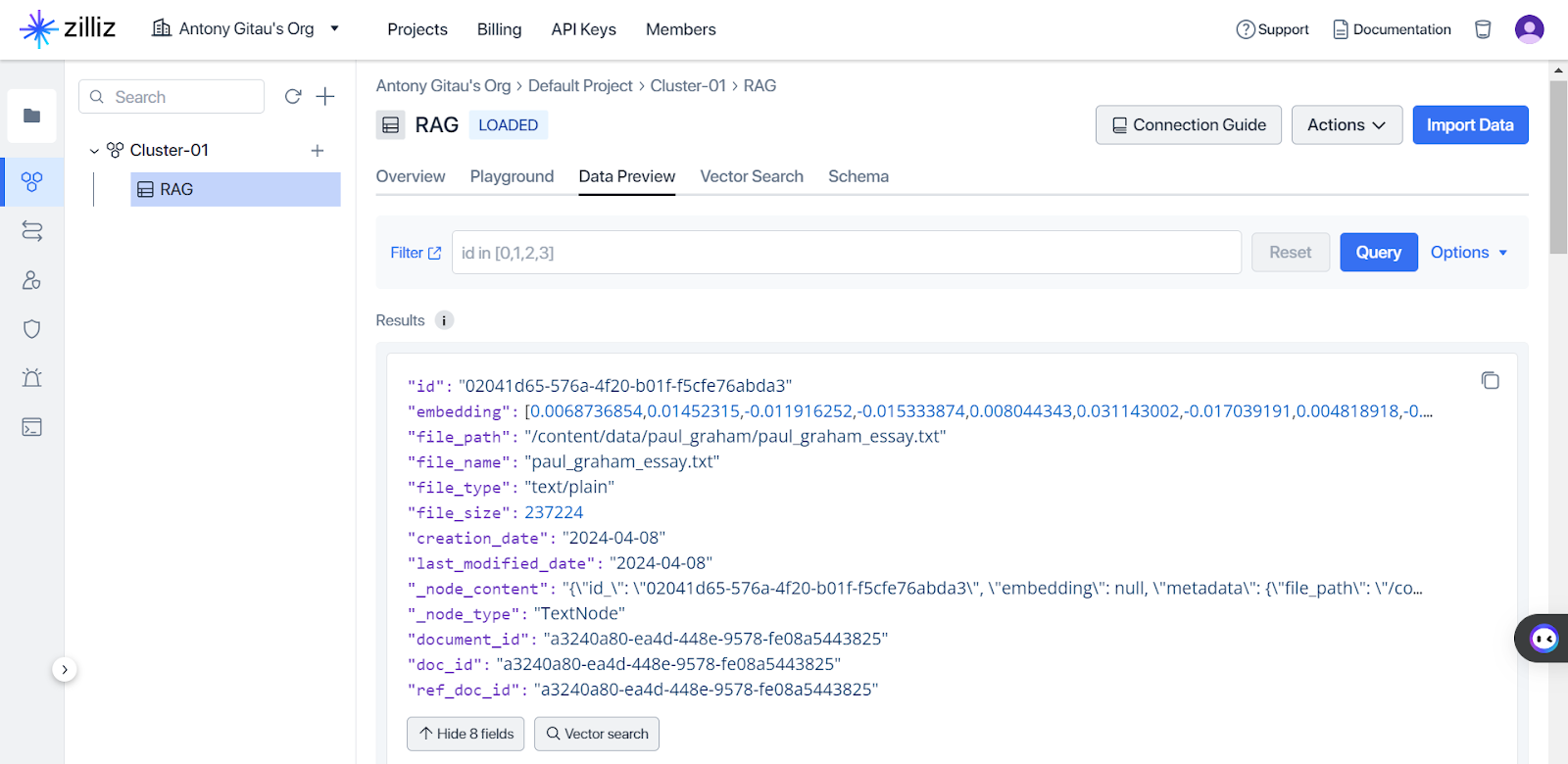 Fig 4. Vector similarity search on Zilliz Cloud.png
Fig 4. Vector similarity search on Zilliz Cloud.png
Clicking vector search, Milvus allows us to perform a vector query search as illustrated in Figure five, by selecting the top-K relevant document based on the semantic similarities encoded in the vector representations retrieved by Milvus, thereby enhancing query understanding and facilitating more accurate information retrieval.
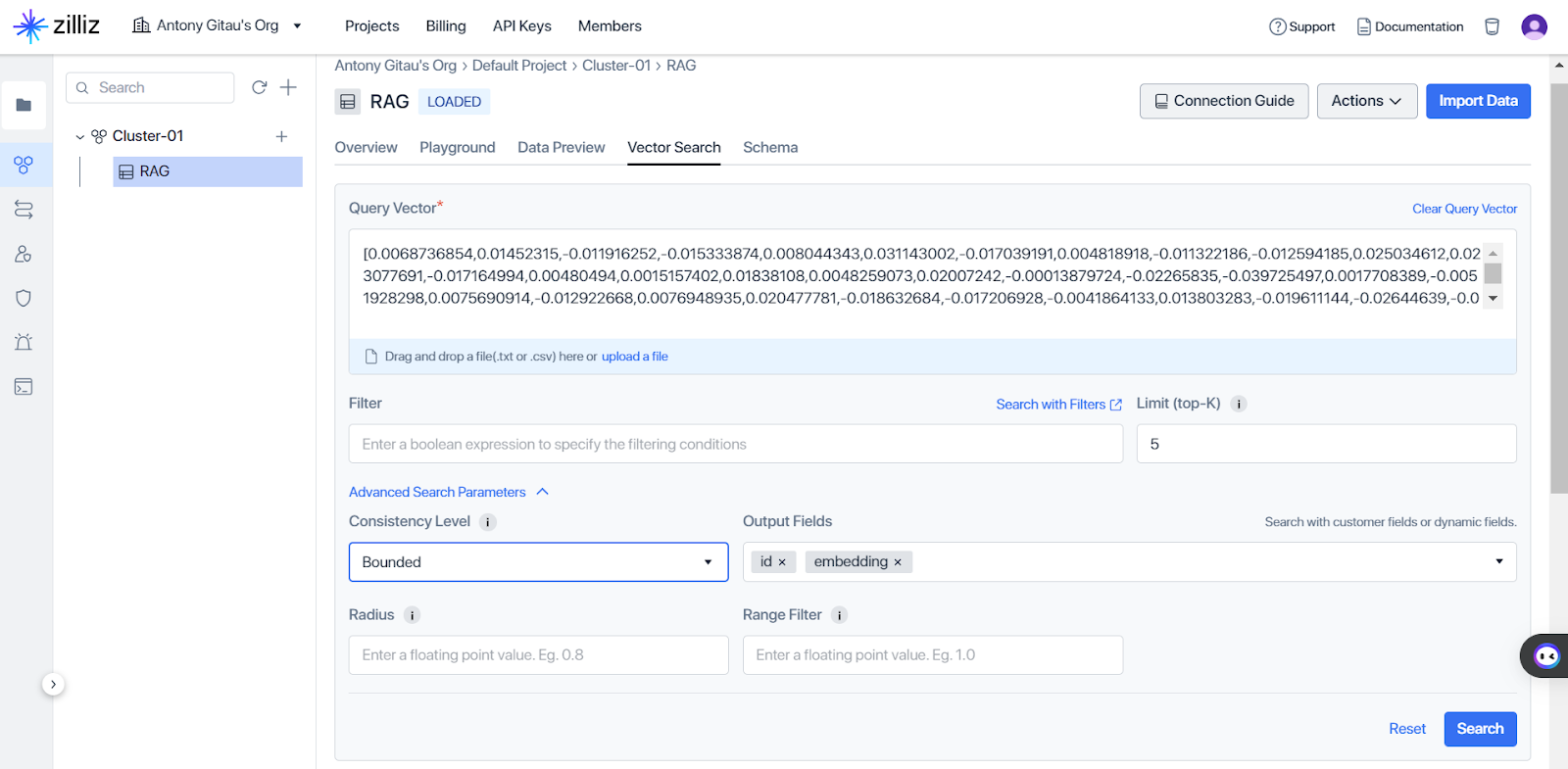 Fig. 5 Configurations for vector similarity search.png
Fig. 5 Configurations for vector similarity search.png
After performing the search, Milvus can retrieve the top 5 most relevant documents, as shown in Figure 6. As we saw in Figure 2, the results of vector similarity happening in the vector database enhance the query by augmenting the user's query with more context. This makes a lot more difference compared to the Figure 1 setup, which lacks a vector database. It's important to note that this vector search operation can be performed using one of the programming languages supported by Zilliz Cloud, such as Python, Node.js, GO, and Java, as documented in Milvus's search and query documentation.
 Fig. 6 Results of the vector search.png
Fig. 6 Results of the vector search.png
Re-Ranking Search Results with Zilliz Technologies
In the code example we saw earlier, we used a single document for retrieval. However, in many real-world cases, we could augment many documents to contextualize a prompt for better answers from the LLM. A challenge arises when we have multiple documents; which documents should we use to help the model contextualize the best? This is where the idea of ranking comes in. A reranker evaluates and reorders search results to enhance their relevance to a specific query. So, a reranker will select a list of the most relevant documents and use them to make a contextualized query, as illustrated in Figure seven.
 Fig 7. Optimizing RAG with Rerankers.png
Fig 7. Optimizing RAG with Rerankers.png
Optimizing Search Results with LLMs and Milvus
Beyond reranking, Milvus has more techniques to optimize search results. Since LLMs often generate large volumes of data, which can pose challenges in storage and retrieval, Milvus supports compression techniques such as quantization and pruning to reduce the storage footprint of vectors without significantly sacrificing search accuracy. Quantization reduces the precision of vector components, while pruning eliminates less relevant components, optimizing storage and search efficiency.
Frameworks and the Road Ahead for Zilliz and Milvus
Significant technological advancements and growing industry demands mark the future of vector databases such as Milvus and LLM-based applications. According to a 2024 strategy blog on exploring vector databases published on Zilliz, continued research and development efforts are expected to enhance algorithmic efficiency, storage optimization, and query processing capabilities within vector databases, potentially aided by specialized hardware accelerators. Concurrently, the increasing adoption of AI across various sectors will drive the demand for scalable solutions, positioning vector databases as pivotal tools for data analysis and insight derivation. The convergence of vector databases with emerging technologies like graph-based databases and federated learning frameworks holds promise for more holistic AI-driven decision-making. Moreover, advancements in machine learning techniques such as deep learning and reinforcement learning are likely to augment vector databases' capabilities further, fostering innovation and discovery in AI applications.
The evolution of search technologies powered by Zilliz and Milvus is not just a passive process. It's a journey that you, as technology professionals and researchers, are a part of. This journey will drive significant industry transformations, allowing for highly personalized, multimodal, and intelligent search experiences. By leveraging advanced LLMs and scalable vector indexing capabilities, search engines will become indispensable tools for navigating and accessing information in an increasingly complex and interconnected world. To actively participate in this journey and stay updated on the latest developments, join the Milvus Discord channel to engage directly with engineers and the community.
Conclusion
In this blog, we have explored the capabilities of Zilliz and Milvus in enhancing search technologies through the integration of Large Language Models (LLMs). By leveraging Zilliz's abilities in NLP and Milvus efficient indexing and search algorithms, we have seen how to optimize search results, and improve query understanding. Through the concept of RAG, we have demonstrated how combining generative AI models with traditional search methods can yield superior outcomes, enabling users to access relevant content quickly and accurately. We have highlighted the role of Milvus in facilitating the ingestion, storage, and retrieval of vector representations, while Zilliz enriches query understanding through semantic analysis, entity recognition, and intent classification.
Resources
- What Is Milvus Vector Database? - The New Stack
- Retrieval-Augmented Generation (RAG) with Milvus and LlamaIndex
- Optimizing RAG with Rerankers: The Role and Trade-offs - Zilliz blog
- Effective RAG: Generate and Evaluate High-Quality Content for Your LLMs
- Building Open Source Chatbots with LangChain and Milvus in 5m - Zilliz blog
- Grounding LLMs - Microsoft Community Hub
- ReadtheDocs Retrieval Augmented Generation (RAG) using Zilliz Free Tier
- VectorDBBench: Open-Source Vector Database Benchmark Tool - Zilliz blog
- Using LangChain to Self-Query a Vector Database - Zilliz blog
- OpenAI's ChatGPT - Zilliz blog
- Vector Index Milvus v2.0.x documentation

- Retrieval-Augmented Generation (RAG) with Milvus
- Let's see how we can use Milvus, LlamaIndex and OpenAI to create a demo RAG system.
- Enhancing Query Understanding with Zilliz
- Re-Ranking Search Results with Zilliz Technologies
- Optimizing Search Results with LLMs and Milvus
- Frameworks and the Road Ahead for Zilliz and Milvus
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Mastering Cohere's Reranker for Enhanced AI Performance
Unlock the full potential of AI applications by diving into the fine-tuning process of Cohere's Reranker, a powerful tool for optimizing search results and recommendation systems.

Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
The Goldfish Loss technique prevents the verbatim reproduction of training data in LLM output by modifying the standard next-token prediction training objective.

Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
This blog will discuss the growing need to detect machine-generated text, past detection methods, and a new approach: Binoculars.