




Unlocking the Power of Many-Shot In-Context Learning in LLMs
Many-Shot In-Context Learning is an NLP technique where a model generates predictions by observing multiple examples within the input context.
Read the entire series
- OpenAI's ChatGPT
- Unlocking the Secrets of GPT-4.0 and Large Language Models
- Top LLMs of 2024: Only the Worthy
- Large Language Models and Search
- Introduction to the Falcon 180B Large Language Model (LLM)
- OpenAI Whisper: Transforming Speech-to-Text with Advanced AI
- Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
- What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
- LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
- Mastering Cohere's Reranker for Enhanced AI Performance
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
- Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
- RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
- Prover-Verifier Games Improve Legibility of LLM Outputs
- Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
- Unlocking the Power of Many-Shot In-Context Learning in LLMs
- Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
- Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
- Everything You Need to Know About LLM Guardrails
- Chain-of-Retrieval Augmented Generation
- Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
Few-shot In-Context Learning vs Many-shot In-Context Learning
Large Language Models (LLMs) have shown impressive abilities in few-shot In-Context Learning (ICL). They perform tasks by learning from a limited set of input-output examples provided during inference without requiring any parameter modifications. Few-shot learning has previously been the standard in the field of In-Context Learning (ICL). However, it often faces limitations due to the restricted context windows of earlier LLMs, such as GPT-3 and Llama 2.
Recent advancements in the LLM domain have led to expanded context windows, allowing the exploration of many-shot in-context learning (ICL). Many-shot learning provides the model with a much larger set of examples, which helps it to understand and generalize more effectively.
Although a few-shot ICL can be effective for simpler tasks, it often fails with complex reasoning and high-dimensional problems. This is due to the limited capacity to specify the task within small context windows. Researchers investigate the impact of scaling the number of in-context examples (shots) on performance across various tasks to overcome these challenges and explore the potential of many-shot ICL.
Many-shot ICL consistently outperforms few-shot ICL, particularly for tasks requiring complex reasoning, problem-solving, and algorithmic computations. Optimal performance is attained when the number of tokens in the context window reaches hundreds of thousands. This signifies the scalability and effectiveness of many-shot in-context learning (ICL).
Furthermore, many-shot ICL can overcome pre-training biases, enabling adaptation to unseen tasks. It can learn high-dimensional functions with numerical inputs, expanding its application beyond natural language processing (NLP). It also performs comparably to supervised fine-tuning, potentially reducing the need for task-specific training.
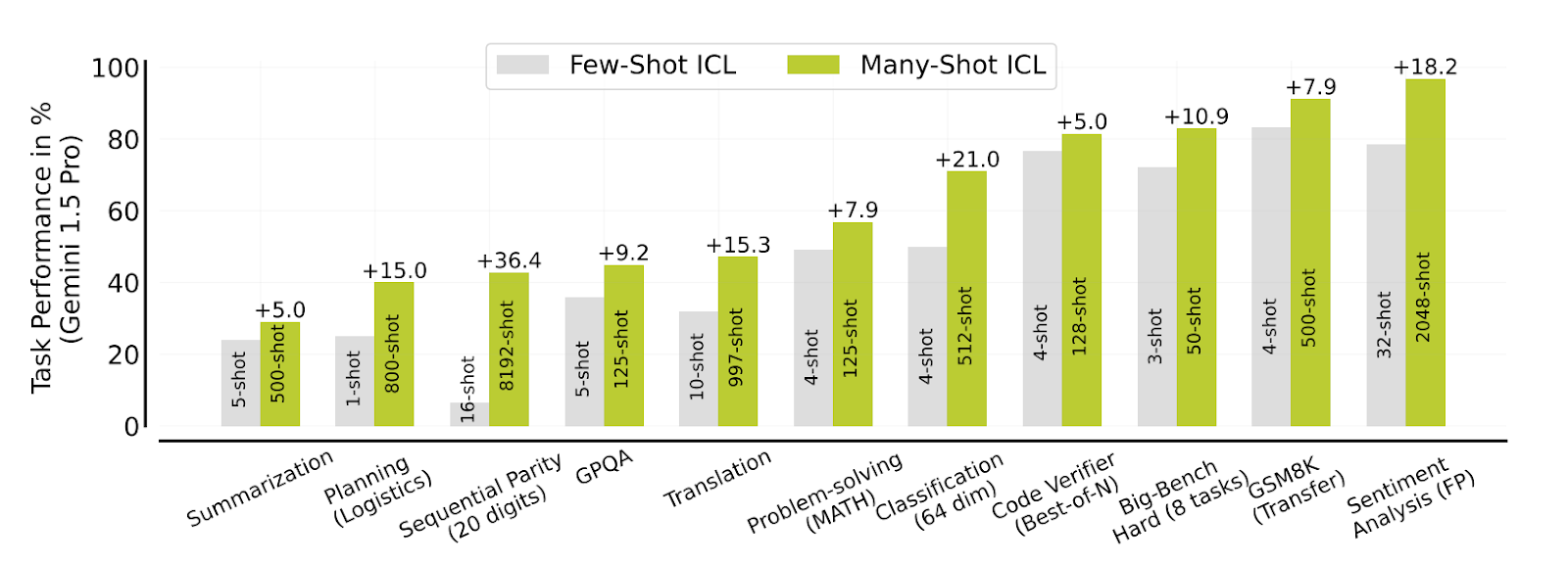 Figure- Many-shot vs few-shot in-context learning (ICL) across several tasks
Figure- Many-shot vs few-shot in-context learning (ICL) across several tasks
Figure: Many-shot vs few-shot in-context learning (ICL) across several tasks | Source
This blog will discuss the contributions of many-shot ICL across a wide range of tasks, as exemplified by Gemini 1.5 Pro. For a comprehensive understanding, please refer to the Many-Shot ICL paper.
Scaling In-Context Learning with Expanded Context Windows
Scaling In-Context Learning (ICL) refers to the ability of LLMs to improve their performance on a task by processing an increasing number of examples (many-shot) within their context window. Instead of adjusting the model's weights through traditional training, the model learns dynamically from examples (shots) provided directly in the prompt.
Recent advanced LLMs with expanded context windows have made scaling ICL an effective approach. Models like Gemini 1.5 Pro, which can process up to 1 million tokens in a single context, show the benefits of moving from few-shot learning (limited examples) to many-shot learning (substantial examples).
How Does Scaling In-Context Learning Work?
The process of scaling ICL is straightforward:
Prompt Construction: A prompt is created containing many input-output pairs (examples or "shots") that present the desired task.
Input for Prediction: A new input for which a prediction is needed is appended to the end of this many-shot prompt.
Model Prediction: The LLM processes the entire prompt, including the new input, without any weight updates and generates a prediction based on the patterns and relationships it identifies from the many-shot examples.
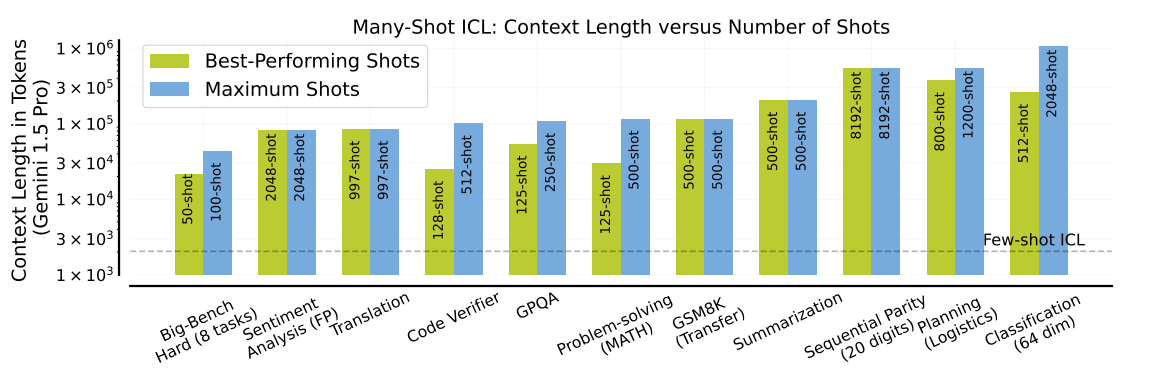 Figure- Context length for best-performing and the maximum number of shots tested for each task
Figure- Context length for best-performing and the maximum number of shots tested for each task
Figure: Context length for best-performing and the maximum number of shots tested for each task | Source
Overcoming the Data Bottleneck: Reinforced and Unsupervised ICL
While many-shot in-context learning shows great potential, it can be challenged by the need for high-quality, human-generated outputs. This limitation stems from the need for numerous examples to demonstrate the desired task effectively to the model. Obtaining such a large amount of human-annotated data can be resource-intensive and time-consuming.
Two approaches were introduced to address this data bottleneck: Reinforced ICL and Unsupervised ICL.
Reinforced In-Context Learning: Leveraging Model-Generated Rationales
Reinforced ICL uses model-generated rationales instead of human-written ones for in-context learning. The process involves:
Rationale Generation: A zero-shot or few-shot chain-of-thought (CoT) prompt generates multiple reasoning chains (rationales) for each training problem.
Rationale Filtering: The generated rationales are filtered based on the correctness of their final answers. This ensures that only rationales leading to the right solution are used for ICL.
Prompt Construction: The selected model-generated rationales and their corresponding problems are arranged as in-context examples.
Reinforced ICL, using model-generated rationales, achieves task performance similar to human-annotated examples while reducing the amount of data needed.
Unsupervised In-Context Learning: Learning from Inputs Alone
Unsupervised ICL takes a step further in minimizing data dependency. It proposes removing rationales entirely from the many-shot prompt and prompting the model solely with inputs. The prompt structure is as follows:
Preamble: A brief introduction, such as "You will be provided questions similar to the ones below:, "sets the context.
Unsolved Inputs: A list of problems or inputs for which solutions are desired is presented.
Output Format Specification: A zero-shot instruction or a few-shot prompt with outputs is included to guide the model toward the desired output format.
The hypothesis behind Unsupervised ICL is that if the LLM possesses the necessary knowledge, the sheer volume of problem inputs can trigger the activation of relevant concepts acquired during pre-training. This approach is considered broadly applicable due to its minimal data requirements. However, unsupervised ICL may not be effective when output examples are crucial for defining the task.
Evaluation and Insights of Many-Shot In-Context Learning
Experiments have been conducted across various tasks to evaluate the effectiveness of many-shot in-context learning (ICL) compared to few-shot ICL.
Machine Translation
Many-shot ICL significantly improves translation performance for low-resource languages. On the FLORES-200 benchmark, particularly for English to Bemba translation, many-shot ICL shows a 15.3% improvement relative to the 1-shot Gemini prompt. There is a 4.5% improvement with many-shot ICL for English to Kurdish translation.
Many-shot ICL achieves state-of-the-art chrF2++ scores for both Bemba and Kurdish, exceeding scores from NLLB and Google Translate. This shows that many-shot ICL can enhance translation quality, especially when dealing with languages that have limited training data.
 Figure- Machine Translation (MT) test performance
Figure- Machine Translation (MT) test performance
Figure: Machine Translation (MT) test performance | Source
Summarization
Many-shot ICL achieves near-optimal performance on XSum. It approaches the results of specialized models like PEGASUS and mT5 fine-tuned for summarization. Performance on XLSum generally improves with more shots. This demonstrates a positive transfer from many-shot learning on XSum. Using the XSum dataset, performance deteriorates with more than 50 in-context examples. This is possibly due to prompt saturation or interference effects. Surprisingly, the model exhibits hallucinations. It generates summaries containing fabricated dates and times, even though such information is absent from the training examples.
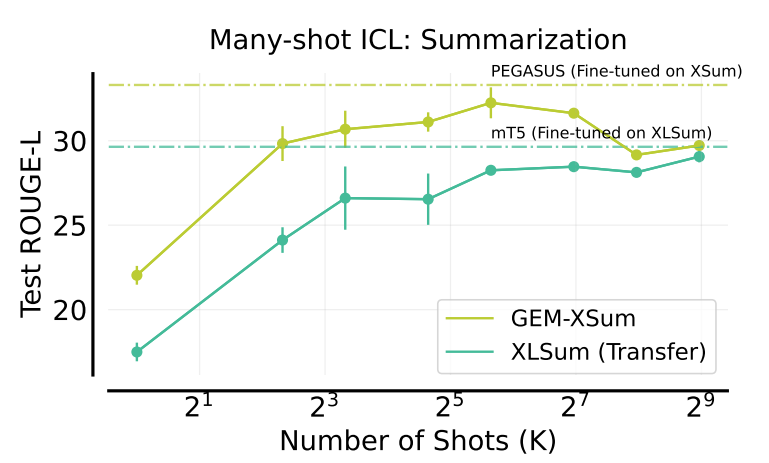 Figure- Summarization- XSum dev set, XSum test performance
Figure- Summarization- XSum dev set, XSum test performance
Figure: Summarization: XSum dev set, XSum test performance | Source
Planning in the Logistics Domain
Many-shot ICL substantially improves the planning abilities of LLMs in the Logistics domain. The goal of logistics is to efficiently transport packages between cities using trucks and airplanes. The success rate significantly improves with increasing numbers of shots, reaching up to 62% with many-shot prompting. While not reaching the level of specialized planners like Fast-Downward, many-shot ICL shows promise for improving LLMs' commonsense planning capabilities.
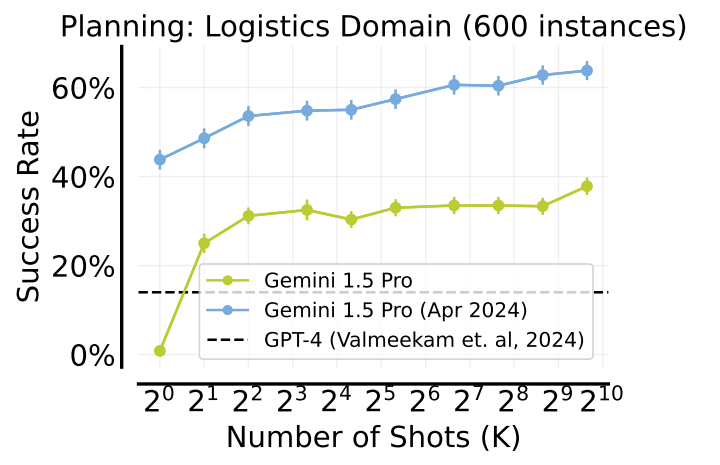 Figure- In-context planning
Figure- In-context planning
Figure: In-context planning | Source
Reward Modeling
Many-shot ICL also proves beneficial in learning reward models in-context, specifically for code verification tasks. As the number of in-context examples increases, the model becomes increasingly capable of accurately verifying the correctness of code solutions. This is evidenced by improved best-of-4 accuracy. With just 16 in-context examples, the best-of-4 accuracy of the verifier using few-shot prompting surpasses the Pass@1 accuracy. The Pass@1 accuracy refers to the accuracy of selecting the correct solution without a verifier.
Furthermore, using 128-shot ICL with the Gemini 1.0 Pro model effectively closes the performance gap between Pass@1 accuracy of 77.25% and Pass@4 accuracy of 90%. Beyond the improvement in accuracy, the model's confidence in differentiating between correct and incorrect solutions also increases with many-shot ICL.
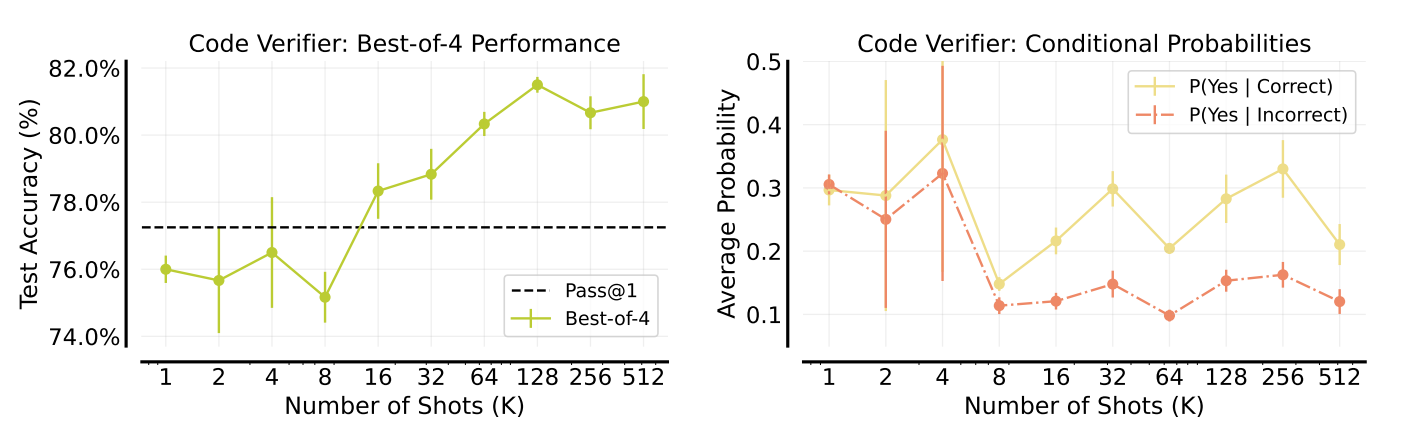 Figure- Learning Verifiers for checking GSM8K code solutions
Figure- Learning Verifiers for checking GSM8K code solutions
Figure: Learning Verifiers for checking GSM8K code solutions | Source
Problem-Solving
Both reinforced and unsupervised ICL demonstrate strong performance on Hendrycks MATH and GSM8K problem-solving benchmarks, often exceeding ICL with ground truth solutions.
Reinforced ICL, using model-generated solutions, consistently outperforms ICL with human-generated solutions. It reaches a plateau at around 25 examples and maintains performance even with a large number of examples.
Unsupervised ICL, which uses only problem inputs, also surpasses ICL with ground truth solutions.
Reinforced ICL with MATH prompts shows strong transfer performance on the GSM8K dataset. In the many-shot setting, it outperforms ICL with ground-truth MATH solutions and Unsupervised ICL.
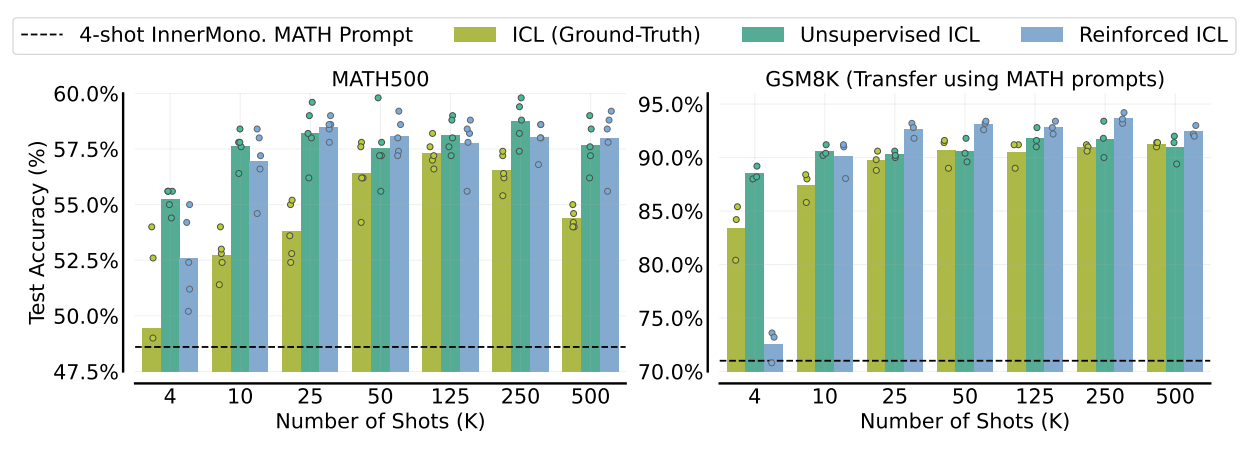 Figure- Many-shot Reinforced and Unsupervised ICL for problem-solving
Figure- Many-shot Reinforced and Unsupervised ICL for problem-solving
Figure: Many-shot Reinforced and Unsupervised ICL for problem-solving | Source
Question Answering
Many-shot ICL with ground truth rationales considerably improves accuracy on Google-Proof QA (GPQA) challenging question-answering benchmark. Performance increases from 5 shots to 125 shots, approaching the accuracy of state-of-the-art models like Claude-3 Opus.
Reinforced ICL, using model-generated rationales, matches or exceeds the performance of ICL with ground truth rationales, particularly up to 25 shots.
Unsupervised ICL shows inconsistent trends. It sometimes performs better than ICL with ground-truth rationales but generally underperforms compared to reinforced ICL.
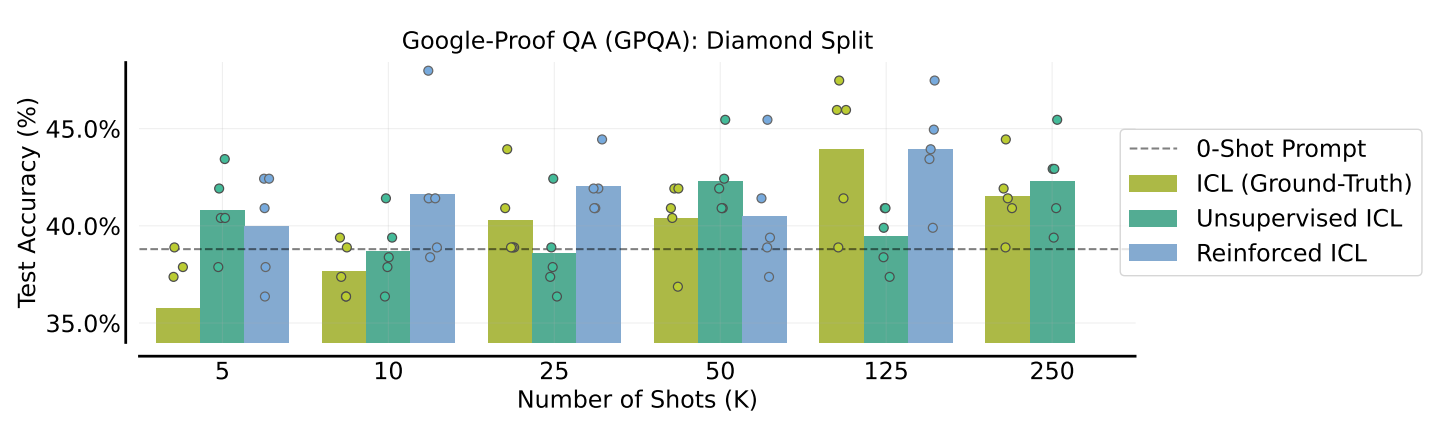 Figure- Many-shot Reinforced and Unsupervised ICL for GPQA
Figure- Many-shot Reinforced and Unsupervised ICL for GPQA
Figure: Many-shot Reinforced and Unsupervised ICL for GPQA | Source
Algorithmic and Symbolic Reasoning
Reinforced ICL consistently outperforms unsupervised ICL on Big-Bench Hard suite of algorithmic reasoning tasks. Both types exceed the performance of a standard 3-shot CoT prompt. Reinforced ICL shows generally monotonic improvement with the number of prompts for 7 out of 8 tasks. In some instances, reinforced ICL with just 3 shots outperforms the human-written 3-shot CoT prompt. This shows the effectiveness of model-generated rationales.
 Figure- Reinforced and Unsupervised ICL with varying numbers of shots on Big-Bench Hard
Figure- Reinforced and Unsupervised ICL with varying numbers of shots on Big-Bench Hard
Figure: Reinforced and Unsupervised ICL with varying numbers of shots on Big-Bench Hard | Source
Overcoming Pre-training Biases
In sentiment analysis tasks using the Financial PhraseBank (FP) dataset, many-shot ICL enables the model to overcome pre-training biases and achieve comparable performance with flipped, abstract, and default labels.
When using flipped or abstract labels that conflict with potential pre-existing sentiment biases, performance initially lags behind default labels in the few-shot regime. However, as the number of shots increases, accuracy with flipped and abstract labels dramatically improves. Eventually, it approaches the performance of default labels. The model's confidence in predictions with flipped labels initially drops but then sharply rises with more shots.
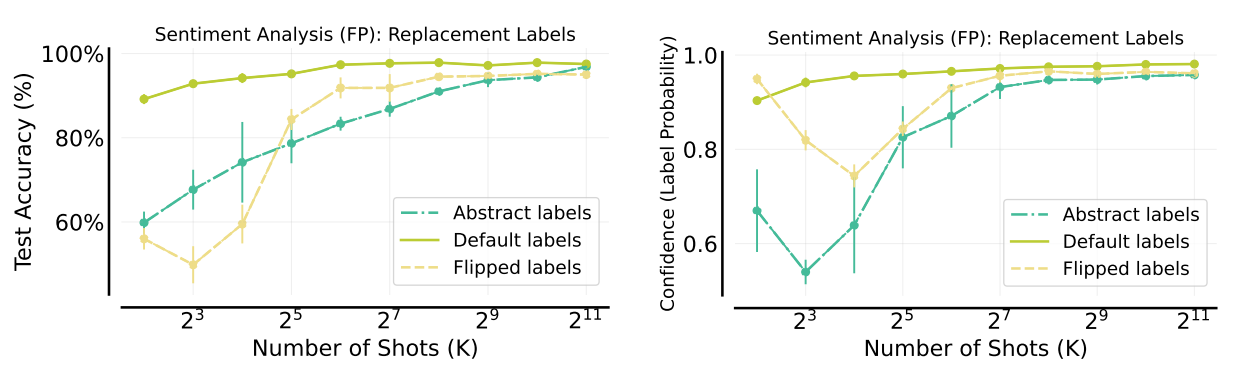 Figure- Overcoming pre-training bias with many-shot ICL
Figure- Overcoming pre-training bias with many-shot ICL
Figure: Overcoming pre-training bias with many-shot ICL | Source
Learning Non-Natural Language Tasks
Many-shot ICL shows the ability to learn abstract mathematical functions with numerical inputs, highlighting its ability to generalize. On binary linear classification tasks with varying input dimensions (16, 32, 64), many-shot ICL greatly outperforms random chance. It nearly matches the accuracy of a k-nearest neighbor's baseline.
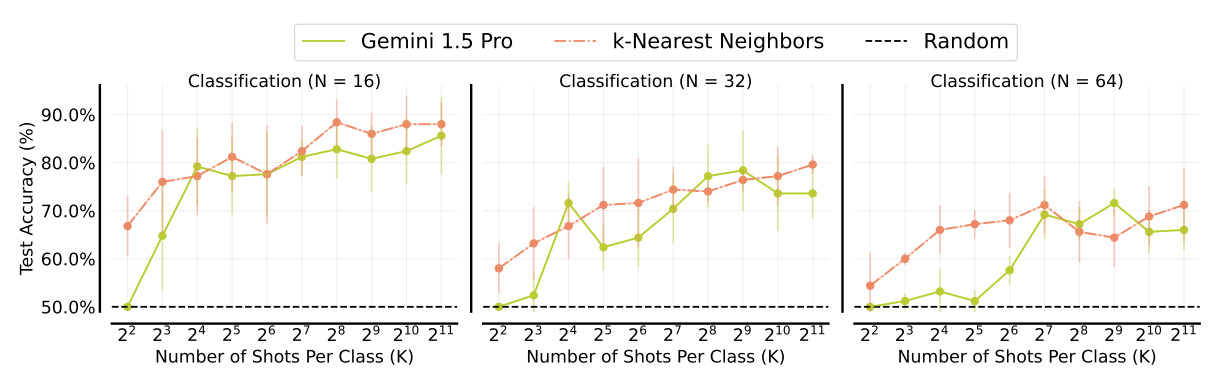 Figure- In-context classification with varying input dimensions
Figure- In-context classification with varying input dimensions
Figure: In-context classification with varying input dimensions | Source
In learning the sequential parity function, many-shot ICL on a large language model surpasses the performance of a GPT-2 Medium model trained from scratch on a dataset 20 times larger.
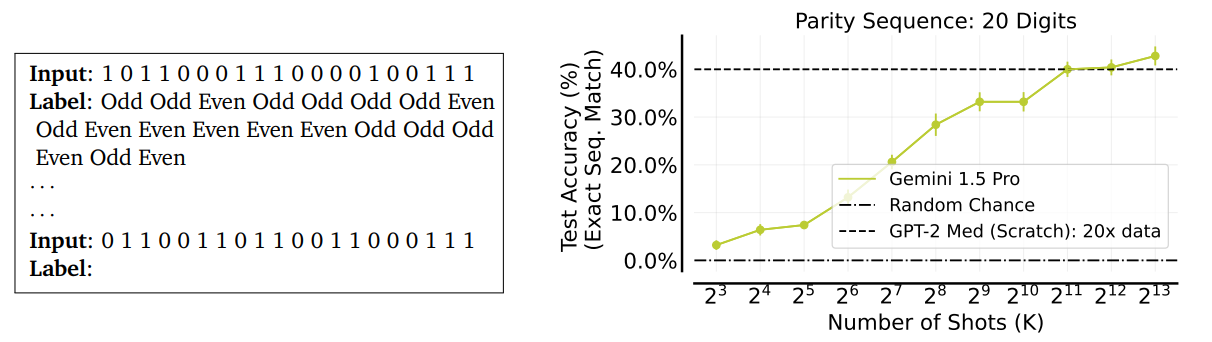 Figure- Learning sequential parity function in-contex
Figure- Learning sequential parity function in-contex
Figure: Learning sequential parity function in-context | Source
Comparison with SFT
In a direct comparison, many-shot in-context learning (ICL) shows performance comparable to supervised fine-tuning (SFT) in low-resource machine translation. This is true when using the same number of examples. This is evidenced by the English to Bemba translation results. This shows that, for certain tasks, many-shot ICL can offer a possible alternative to the computationally expensive process of SFT.
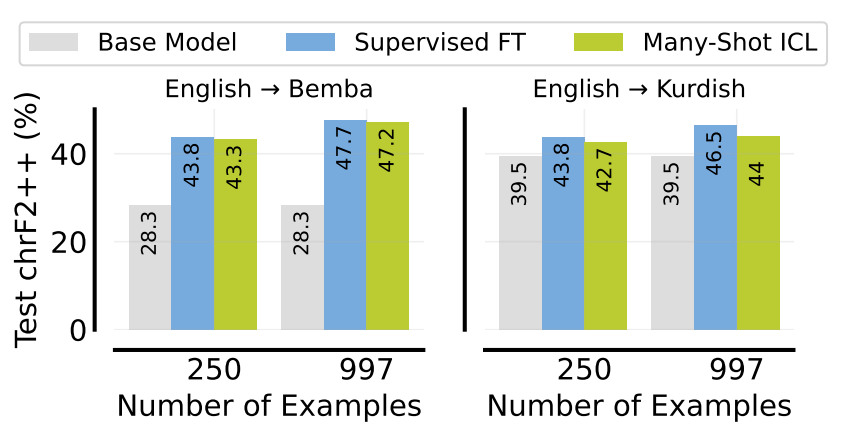 Figure- Comparing SFT with many-shot ICL on low-resource translation.png
Figure- Comparing SFT with many-shot ICL on low-resource translation.png
Figure: Comparing SFT with many-shot ICL on low-resource translation | Source
Many-Shot Abilities of Other LLMs
The majority of the experiments were conducted with Gemini 1.5 Pro. Some evaluations have been conducted using other long-context LLMs, such as GPT-4-Turbo and Claude-3-Opus. These models also benefit from many-shot in-context learning, although the extent of the benefits varies. Smaller LLMs, like Gemini 1.5 Flash, can also use many-shot ICL to achieve performance comparable to or even exceeding that of larger LLMs with stronger few-shot capabilities.
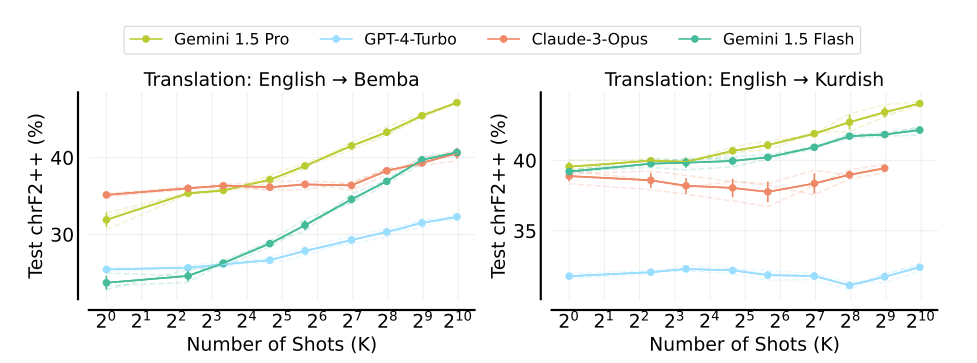 Figure- Many-shot ICL with GPT-4-Turbo and Claude-3-Opus on low-resource machine translation
Figure- Many-shot ICL with GPT-4-Turbo and Claude-3-Opus on low-resource machine translation
Figure: Many-shot ICL with GPT-4-Turbo and Claude-3-Opus on low-resource machine translation | Source
Next-Token Prediction Loss as a Metric
Next-token prediction loss is a commonly used metric for evaluating the performance of language models. It quantifies how well a model predicts the next token in a sequence, given the preceding tokens. A lower next-token prediction loss generally indicates better performance. As context length increases, the prediction loss for the next token tends to decrease consistently. However, relying solely on trends in next-token prediction loss may not be a reliable indicator of ICL performance, particularly for problem-solving and reasoning tasks. This is because:
Multiple Valid Solutions: There can be many correct Chain-of-Thought (CoT) solutions for problem-solving tasks. Calculating the log-likelihood based on only one solution might not accurately reflect the model's problem-solving ability.
Continued NLL Decrease: Negative log-likelihood (NLL) continues to decrease even when actual task performance levels off or begins to decline. For example, while the success rate on tasks like MATH and GPQA starts to decrease after a certain number of attempts, NLL continues to decline.
Misalignment with Transfer Performance: When knowledge is transferred from one problem-solving domain to another (e.g., using MATH prompts to solve GSM8K problems), the change in NLL is minimal despite improvements in actual transfer performance.
 Figure- Negative Log-Likelihood (NLL) as a function of number of shots.png
Figure- Negative Log-Likelihood (NLL) as a function of number of shots.png
Figure: Negative Log-Likelihood (NLL) as a function of number of shots | Source
Implications of Many-Shot In-Context Learning
Many-shot in-context learning (ICL) for LLMs has several significant implications for the field. These include:
Reduced Reliance on Fine-tuning: ****Many-shot in-context learning (ICL) can perform nearly as well as supervised fine-tuning (SFT) in some cases. This indicates a possible change in how we approach training LLMs. Using many-shot ICL could reduce the need for computationally expensive and task-specific fine-tuning, making LLMs more versatile and adaptable.
Enhanced Performance: The most noticeable benefit is the significant performance improvement seen across various tasks when moving from few-shot to many-shot in-context learning. This indicates that giving LLMs more in-context examples helps them understand the details of a task better and generalize more effectively.
Expanding Application Beyond NLP: Many-shot ICL learning high-dimensional functions with numerical inputs opens up new possibilities for applying ICL beyond traditional NLP tasks. This indicates that LLMs could be used for tasks involving numerical data, such as regression, classification, and scientific modeling, expanding their applicability to new domains.
Conclusions and Potential Future Research Directions
Many-shot In-Context Learning (ICL) has become a valuable technique for improving the abilities of large language models (LLMs). By providing LLMs with a large number of in-context examples (shots), significant performance improvements were observed across various tasks. These include machine translation, summarization, problem-solving, and reasoning. Many-shot ICL offers the potential to reduce reliance on fine-tuning, making LLMs more adaptable and versatile. Notably, smaller LLMs can also benefit substantially from many-shot ICL, potentially surpassing the performance of larger models.
Future Research Directions
Several promising directions for future research could lead to significant advancements and new discoveries. It's important to explore these paths to boost our understanding and tackle current challenges.
Evaluating Many-Shot Abilities of Diverse LLMs: It is crucial to expand the evaluation of many-shot ICL to encompass a wider range of LLMs. This includes models with different architectures, sizes, and training data. This diversity is important for comprehensively understanding the factors influencing many-shot performance.
Optimizing Many-Shot Prompts: Investigating techniques for optimizing many-shot prompts could enhance effectiveness. This includes exploring different example selection strategies, ordering methods, and prompt engineering techniques.
Developing Robust Evaluation Metrics: It is important to design evaluation metrics that accurately understand the multifaceted aspects of many-shot ICL performance. This is particularly crucial for complex tasks like reasoning and problem-solving. This could include exploring metrics that account for solution diversity, reasoning quality, and robustness to distributional shifts.
Unsupervised ICL Potential: Unsupervised ICL is still in its early stages and requires more investigation to understand its capabilities and limitations. Future research can explore its feasibility across a broader range of tasks and potentially develop techniques to improve its effectiveness.
Addressing Performance Degradation: In some cases, performance can decline when the number of examples in the prompt exceeds a certain threshold, as in tasks like MATH and GPQA. Future research should investigate the reasons behind this performance degradation and develop strategies to reduce it.
Related Resources
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- Few-shot In-Context Learning vs Many-shot In-Context Learning
- Scaling In-Context Learning with Expanded Context Windows
- Overcoming the Data Bottleneck: Reinforced and Unsupervised ICL
- Evaluation and Insights of Many-Shot In-Context Learning
- Implications of Many-Shot In-Context Learning
- Conclusions and Potential Future Research Directions
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading
LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
LoRA (Low-Rank Adaptation) is a technique for efficiently fine-tuning LLMs by introducing low-rank trainable weight matrices into specific model layers.

Everything You Need to Know About LLM Guardrails
In this blog, we'll examine LLM guardrails, technical systems, and processes designed to ensure LLMs' safe and reliable operation.

Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
Discover how Chain-of-Agents enhances Large Language Models by effectively managing context injection, improving response quality while addressing token limitations.