




Get Ready for GPT-4 with GPTCache & Milvus, Save Big on Multimodal AI
Introduction
As the world becomes increasingly digital, the demand for artificial intelligence (AI) solutions that can comprehend and analyze vast amounts of data is rising. OpenAI's ChatGPT, which GPT-3.5 powers, has already revolutionized the field of natural language processing (NLP) and prompted significant interest in large language models (LLMs). As the adoption of LLMs continues to attract attention and grow across various industries, so does the need for more advanced large AI models that can process multimodal data. The tech world is already buzzing with anticipation for GPT-4, which promises to be even more powerful and versatile by enabling visual inputs. Collaborating GPT-4 with image generation models also holds immense potential. To prepare for this upcoming revolution, Zilliz has introduced GPTCache integrated with Milvus - a game-changing solution that can help businesses to save a fortune on multimodal AI.
Multimodal AI refers to integrating multiple modes of perception and communication, such as speech, vision, language, and gesture, to create more intelligent and effective AI systems. This approach allows AI models to understand better and interpret human interactions and environments and to generate more accurate and nuanced responses. Multimodal AI has applications in various fields, including healthcare, education, entertainment, and transportation. Some examples of multimodal AI systems include virtual assistants like Siri and Alexa, autonomous vehicles, and medical diagnostic tools that analyze images and patient data together.
In this article, we will delve into the details of GPTCache and explore how it works in conjunction with Milvus to provide a more seamless and powerful user experience in multimodal scenarios.
Semantic Cache for Multimodal AI
In most cases, achieving the desired results in multimodal AI applications requires using large models. However, processing such models or calls can be time-consuming and expensive. This is where GPTCache comes in handy - it enables the system to search for potential answers in the cache first before sending a request to a large model. GPTCache speeds up the entire process and helps reduce the costs of running large models.
Exploring Semantic Cache with GPTCache
Semantic cache stores and retrieves knowledge representations of concepts. It is designed to store and retrieve semantic information or knowledge in a structured way. Thus, an AI system can better understand and respond to queries or requests. The idea behind a semantic cache is to provide faster access to relevant information by providing precomputed answers to commonly asked questions or queries, which can help improve the performance and efficiency of AI applications.
GPTCache is a project developed to optimize response time and reduce expenses for API calls associated with large models. We designed GPTcache to create a semantic cache, which stores model responses and leverages the power of Milvus. The technology is built on Milvus, incorporating several vital components, such as the large model adapter, context manager, embedding generator, cache manager, similarity evaluator, and pre/post processors.
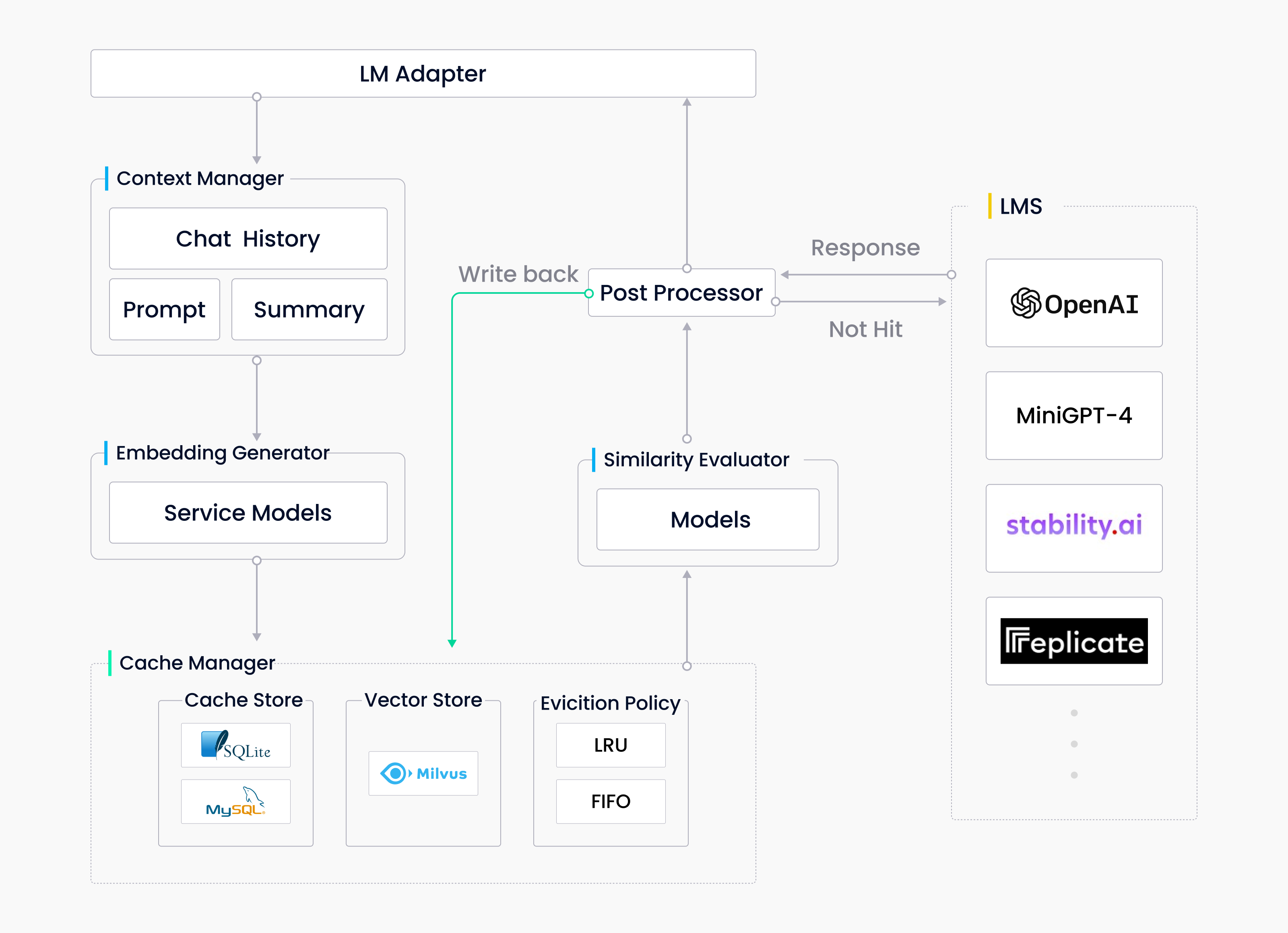 GPTCache Architecture
GPTCache Architecture
The adapter ensures that GPTCache works seamlessly with any large model. The context manager enables more flexibility allowing the system to handle various data at different stages. The embedding generator converts data to embeddings for vector storage and semantic search. All vectors and other valuable data are stored in the cache. Milvus not only supports storage for a large scale of data but also helps speed up and improve the performance of similarity search. Finally, the evaluator is responsible for evaluating whether potential answers retrieved from the cache are good enough for user needs. The following code snippet shows how to initialize a cache with different modules in GPTCache.
from gptcache import cache
from gptcache.manager import get_data_manager, CacheBase, VectorBase, ObjectBase
from gptcache.processor.pre import get_prompt
from gptcache.processor.post import temperature_softmax
from gptcache.embedding import Onnx
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
onnx = Onnx()
cache_base = CacheBase('sqlite')
vector_base = VectorBase(
'milvus',
host='localhost',
port='19530',
dimension=onnx.dimension
)
object_base = ObjectBase('local', path='./objects')
data_manager = get_data_manager(cache_base, vector_base, object_base)
cache.init(
pre_embedding_func=get_prompt, # Pre-process
embedding_func=onnx.to_embeddings, # Embedding generator
data_manager=data_manager, # Cache manager
similarity_evaluation=SearchDistanceEvaluation() # Evaluator
post_process_messages_func=temperature_softmax # Post-process
)
Caching Semantic Data in a Vector Database
One of the cornerstones of a semantic cache such as GPTCache is the vector database. Specifically, the embedding generator of GPTCache converts data to embeddings for vector storage and semantic search. Storing vectors in a vector database, such as Milvus, not only supports storage for a large data scale but also helps speed up and improve the performance of similarity search. This allows for more efficient retrieval of potential answers from the cache.
A pretrained multimodal model learns a vector space to represent different types of inputs. As a result, it can capture complementary information provided by other modalities. This paradigm enables the system to interpret data with varying modalities in a unified manner, allowing for more accurate and efficient processing via semantic search. Vector databases enable the semantic search for multimodal inputs via vector similarity algorithms. Unlike traditional databases that store data in rows and columns, vector databases store and retrieve unstructured data as vectors. Vector databases manage high-dimensional data, prevalent in multimodal AI applications that process different data types as vectors.
Benefits of using Milvus
The Milvus ecosystem provides helpful tools for database monitoring, data migration, and data size estimation. For more straightforward implementation and maintenance of Milvus, there is a cloud-native service Zilliz Cloud. The combination of Milvus with GPTCache offers a powerful solution for enhancing the functionality and performance of multimodal AI applications. Whether you're working with large amounts of data, complex models, or diverse data types, this approach can help streamline data processing and improve the accuracy and speed of results. Integrating Milvus with GPTCache in multimodal AI can yield several powerful benefits. Here are some of the most notable:
- Efficient storage and retrieval of data
Milvus is purpose-built for storing and retrieving large-scale vector data. Additionally, a vector is the "general language" spoken by deep learning models. Milvus can easily handle vectors, providing fast and efficient access to multimodal data. Using Milvus can lead to faster response times and a better user experience.
- Improved flexibility and scalability
As the amount of data processed by AI applications grows, so does the need for a scalable solution. By incorporating Milvus, the system can scale seamlessly to meet growing demands. Additionally, Milvus provides a wide range of features that can improve the overall flexibility and functionality of multimodal AI.
- Enhanced accuracy and performance
Thanks to the unified storage and retrieval of data provided by Milvus, multimodal AI applications can more quickly and accurately process inputs from various data types. This can lead to more accurate results and improved overall system performance.
- Ease of Use
Milvus offers different options for local deployment, including a quick start with pip. It also provides cloud service via Zilliz Cloud, which allows users to start and scale their Milvus instances quickly. Milvus also supports multiple language SDKs, including Python, Java, and Go (more under development), making it easy to integrate into existing applications. Additionally, Milvus provides a Restful API for easy interaction with the server.
- Popularity and reliability
Milvus has gained immense popularity due to its high scalability and performance. With over 1,000 enterprise users and an active open-source community, Milvus has positioned itself as a reliable solution for managing massive amounts of structured and unstructured data. As a LF AI & Data Foundation graduate project, Milvus also benefits from institutional support, further solidifying its position as a go-to database for organizations seeking efficient and reliable data management solutions.
Overcoming Cache Constraints for Increased Output Diversity
A multimodal AI that can produce diverse outputs is essential for providing a comprehensive and effective solution that can cater to the needs of a wide range of users. The diversity of outputs helps to enhance the user experience and improves the overall functionality of the AI system. Furthermore, output diversity is crucial for applications requiring a wide range of output types, such as virtual assistants, chatbots, and speech recognition systems.
While the semantic cache is an efficient way to retrieve data, it can limit the diversity of user responses. It prioritizes cached answers over generating new ones from a large model. This means the system may keep producing the same or similar outputs, relying heavily on previously cached information. As a result, the output may become repetitive and lack novelty, which can be problematic in contexts where diverse and creative responses are needed.
To address this issue, temperature in machine learning has become a valuable tool. Temperature determines the randomness or diversity of the response content, with a higher temperature value allowing for more exploration of possibilities beyond the most probable output. This can lead to creative and unexpected outputs, accommodating a wider range of preferences and styles. On the other hand, a lower temperature value generates more focused and deterministic responses, producing precise and coherent results. By overcoming cache constraints through temperature adjustment, multimodal AI applications can produce more comprehensive and effective solutions that cater to the needs of a broader range of users.
Temperature in GPTCache
Choosing an appropriate temperature value is essential in multimodal AI to balance randomness and coherence and align with the user's or application's specific needs and preferences. The temperature in GPTCache mainly retains the general concept of temperature in machine learning. It is achieved through 3 options in the workflow:
- Select after evaluation
Softmax activation on model logits is a common technique involving temperature in deep learning. GPTCache similarly uses a softmax function to convert the similarity scores of candidate answers into a list of probabilities. The higher the score, the more possible it is to be selected as the final answer. Temperature controls the sharpness of possibility distribution. This means an answer with a higher score is more likely selected. The post-processor temperature_softmax in GPTCache follows this algorithm to select an item from a list of candidates given their scores or confidence levels.
from gptcache.processor.post import temperature_softmax
messages = ["message 1", "message 2", "message 3"]
scores = [0.9, 0.5, 0.1]
answer = temperature_softmax(messages, scores, temperature=0.5)
- Call model without cache
We apply the possibility of calling large models directly without searching the cache. This possibility is affected by temperature. A higher temperature means more likely to skip cache searching, while a lower temperature decreases the possibility of skipping cache searching. Here is an example, using temperatuer_softmax to to control the decision of skipping or checking cache by temperature.
from gptcache.processor.post import temperature_softmax
def skip_cache(temperature):
if 0 < temperature < 2:
cache_skip_options = [True, False]
prob_cache_skip = [0, 1]
cache_skip = temperature_softmax(
messages=cache_skip_options,
scores=prob_cache_skip,
temperature=temperature)
)
elif temperature >= 2:
cache_skip = True
else: # temperature <= 0
cache_skip = False
return cache_skip
- Edit result from cache
Using a small model or some tools to edit the answer, this option requires an editor with the ability to convert the data type of output.
Multimodal Applications
More individuals seek assistance from GPT-4 instead of settling for ChatGPT and relying solely on GPT-3.5. In addition, the current trend is shifting from pure LLM to multimodal applications. Multimodal AI primarily interacts with multiple modalities of data, encompassing text, visuals, and audio. As AI technologies evolve, GPTCache and Milvus represent an exciting and innovative approach to building intelligent multimodal systems. The following examples showcase how GPTCache and Milvus have been implemented in multimodal situations.
1. Text-to-Image: Image Generation
Image generation by AI has been a hot topic in recent years. It refers to generating images based on textual descriptions or instructions using a pre-trained multimodal text-image model. This technology has come a long way in recent years. We've seen incredible advances in image generation models and applications that can produce convincing images that are often difficult to distinguish from photographs taken by humans.
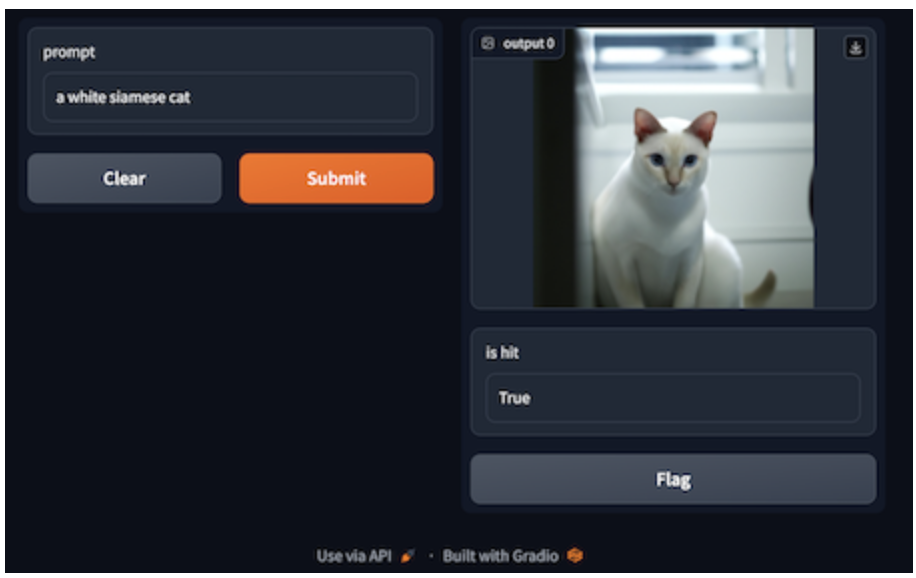 Prompt | a white siamese cat
Prompt | a white siamese cat
The process of generating images involves using textual prompts as input. With GPTCache, image generation is made easier with its semantic search feature for prompts. The system uses Milvus to compare text embeddings and detect similar prompts stored in the cache. It then retrieves the corresponding images from the cache. If the cache does not have satisfactory results, GPTCache will call the image generation model. The image and text outputs of the model are saved by GPTCache, which enriches its database. The embedding generator converts each text prompt to a vector, then stores it in Milvus to facilitate storage and retrieval.
The example code below calls the OpenAI service adapted with GPTCache to generate an image given the text "a whilte siamese cat." The request regulates the diversity of generated images on every occasion through the value temperature and top_k. By changing the temperature from its default value of 0.0 to a higher value of 0.8, the request is more likely to get a different image each time given the same text.
from gptcache.adapter import openai
cache.set_openai_key()
response = openai.Image.create(
prompt="a white siamese cat",
temperature=0.8, # optional, defaults to 0.0.
top_k=10 # optional, defaults to 5 if temperature>0.0 else 1.
)
GPTCache currently has built-in adapters for most popular image generation models or services, containing OpenAI Image Creation, Stability.AI API, Stable Diffusions at HuggingFace. The bootcamp provides a tutorial of Image Generation using OpenAI.
2. Image-to-Text: Image Captioning
Image captioning generates a textual description for an image, typically using a pre-trained multimodal image-text model. This technology allows computers to understand the contents of images and describe them in natural language for humans to interpret. Image captioning can also provide a much more robust solution by incorporating it into a chatbot. It allows for a seamless transition between a product's visual and conversational aspects, enhancing the overall user experience.
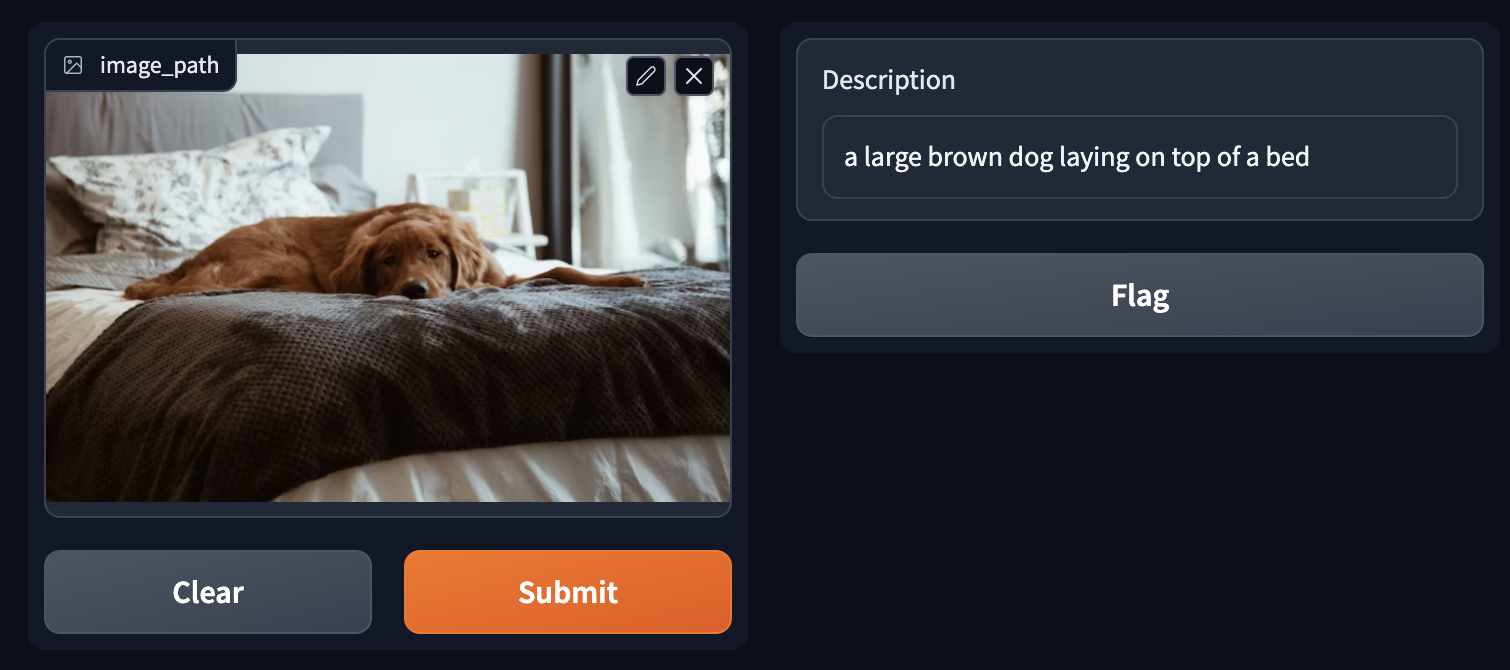 A large brown dog laying on top of a bed
A large brown dog laying on top of a bed
Regarding image captioning, GPTCache starts by scanning through its cache for images resembling the input image, as measured by image embeddings. Then, to ensure the quality of the captions returned, an evaluator performs an additional assessment of the relevancy or similarity between the input image and images or captions retrieved from the cache. For instance, pre-trained visual models such as ResNets or ViTs can evaluate image similarity. In addition, a text-image model like CLIP can be applied to gauge the similarity between image and text. If there is no match in the cache, the system utilizes a multimodal model to generate captions for the given image. Subsequently, GPTCache stores both the image and its corresponding captions, with images and captions being saved as vectors in Milvus.
GPTCache has already adapted popular image captioning services such as Replicate BLIP and miniGPT-4. It plans to support more image-to-text services and local-hosted multimodal models.
3. Audio-to-Text: Speech Transcription
Audio-to-text, also known as speech transcription, converts audio content, such as recorded conversations, meetings, or lectures, into written text. This technology allows individuals who may have difficulty hearing or prefer to read rather than listen to the content, to access and understand the information more easily. In addition to passing transcriptions to a chatbot like ChatGPT, users can use the transcriptions to explore more.
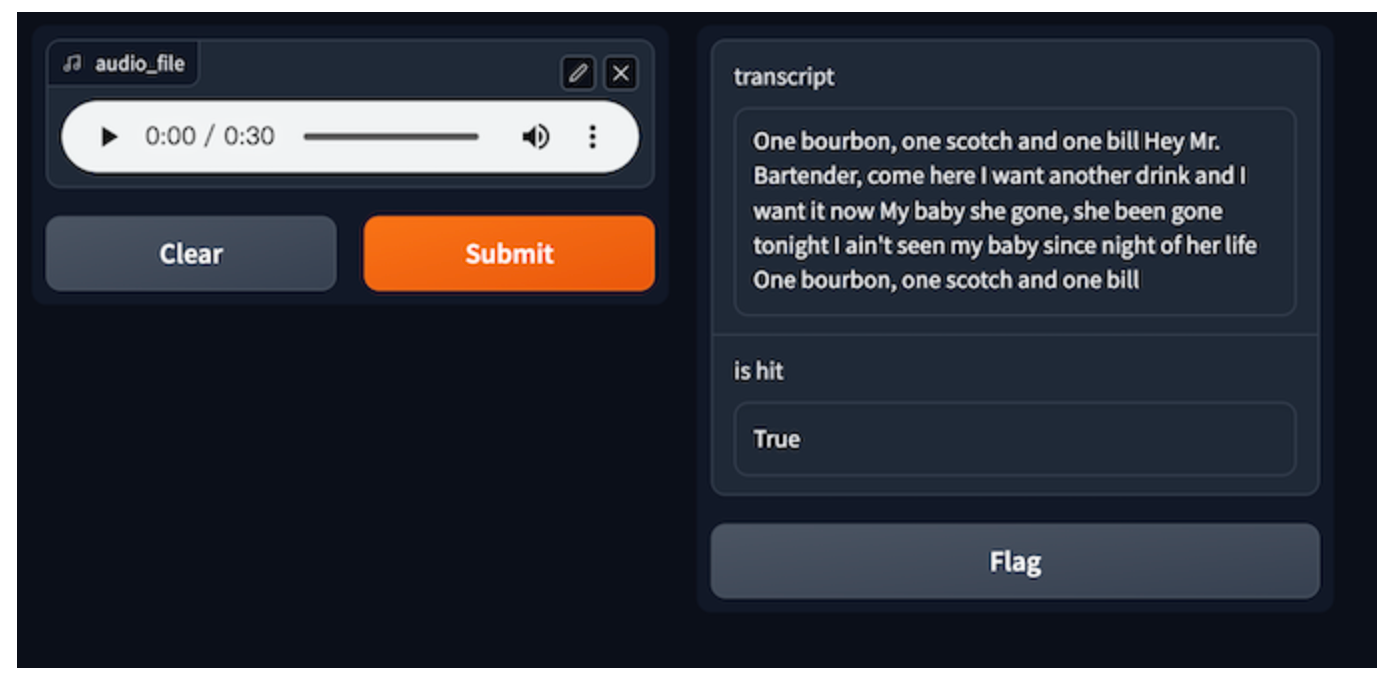 Audio file | One bourbon, one scotch, one bill
Audio file | One bourbon, one scotch, one bill
An audio file typically serves as the initial input for speech transcription. By enabling GPTCache, the first step involves creating an audio embedding for each input. The system then utilizes Milvus for similarity search, retrieving potential transcriptions from the cache. Finally, an Automatic Speech Recognition (ASR) model or service is called when no corresponding answers are found after the evaluation. All pairs of audio and transcriptions generated by the ASR model are stored in the cache. Using Milvus to store audio data as vectors ensures that matching similar audio from the cache is possible. It also allows for scalability as the amount of audio data increases.
GPTCache and Milvus significantly reduce the need for multiple ASR calls, improving speed and efficiency. The GPTCache bootcamp of Speech to Text provides an example tutorial for enabling GPTCache and applying Milvus for the OpenAI Transcriptions.
Conclusion
The use of multimodal AI models is gaining popularity, allowing for more comprehensive analysis and understanding of complex data. With its support for unstructured data, Milvus is an ideal solution for building and scaling multimodal applications. Furthermore, adding more features in GPTCache, such as session management, context awareness, and server support, further enhances the capabilities of multimodal AI. With these advancements, multimodal AI models have more potential uses and scenarios. Stay tuned to the GPTCache Bootcamp for more insights into multimodal AI applications.

Keep Reading

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.