




Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
By integrating GPTCache and Milvus with ChatGPT, businesses can create a more robust and efficient AI-powered support system. This approach leverages the advanced capabilities of generative AI and introduces a form of long-term memory, allowing the AI to recall and reuse information effectively.
Read the entire series
- Mastering LLM Challenges: An Exploration of Retrieval Augmented Generation
- Key NLP technologies in Deep Learning
- Exploring the Frontier of Multimodal Retrieval-Augmented Generation (RAG)
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- How to Enhance the Performance of Your RAG Pipeline
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- Pandas DataFrame: Chunking and Vectorizing with Milvus
- How to build a Retrieval-Augmented Generation (RAG) system using Llama3, Ollama, DSPy, and Milvus
- Improving Information Retrieval and RAG with Hypothetical Document Embeddings (HyDE)
- Building RAG with Milvus Lite, Llama3, and LlamaIndex
- Enhancing RAG with RA-DIT: A Fine-Tuning Approach to Minimize LLM Hallucinations
- Top 10 RAG & LLM Evaluation Tools You Don't Want To Miss
Imagine managing an online support service where users frequently report and ask questions about issues with your product. To ensure round-the-clock assistance, you've built your support service using a RAG framework with Milvus and the Open AI large language model (LLM) to handle inquiries. As the system operates, you notice many user difficulties are similar. This realization sparks an idea—what if you could leverage past responses to address new queries swiftly? Not only would this approach decrease the number of tokens you consume per API call to the LLM, thus lowering costs, but it would also significantly enhance response times, improving user experience with your support service.
That is where GPTCache comes in. GPTCache is an open-source library designed by the engineers at Zilliz to create a semantic cache for LLM queries. This blog will explore how integrating GPTCache with ChatGPT and Milvus can transform your LLM use case by utilizing cached responses to improve efficiency. We will see how implementing a system that recalls previous interactions provides a form of long-term memory to the LLM, enabling it to handle interactions more effectively and remember relevant information without the need for repeated LLM API calls. This capability enhances user experience and reduces the load on backend servers, improving the capabilities of generative AI models.
Overview of ChatGPT Plugins
Speaking of generative AI model capabilities, ChatGPT plugins are extensions designed to augment the base capabilities of the ChatGPT model and are tailored to specific needs or functionalities. These plugins allow for integration with external services, enhance performance, or introduce new features not inherently present in the primary model. For example, a plugin could be developed to interface with a customer relationship management (CRM) system, providing the AI with access to customer data that can enhance personalized interactions, as illustrated in Figure 1.
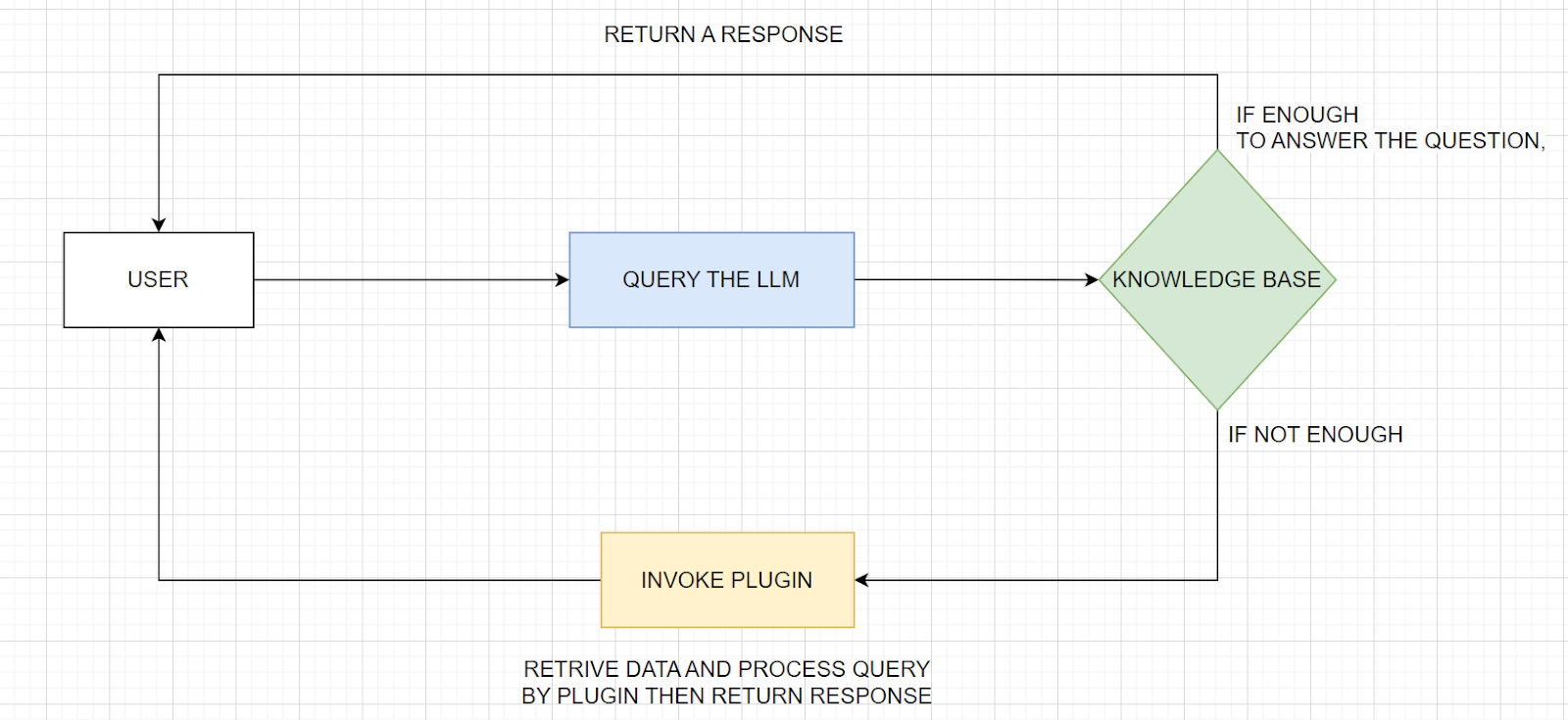 Fig 1. A simplified view of an operations involving a ChatGPT plugin
Fig 1. A simplified view of an operations involving a ChatGPT plugin
Let see the difference GPTCache brings
There has been an explosion of GPT-based apps. This has come with challenges such as increased service cost, as the OSS Chat app builders will tell you, motivating the building of a caching mechanism for GPT. GPTCache allows users to customize the cache according to their needs, including options for embedding functions, similarity evaluation functions, storage location, and eviction policy, as we illustrated in Figure 2 and demonstrated on the colab notebook.
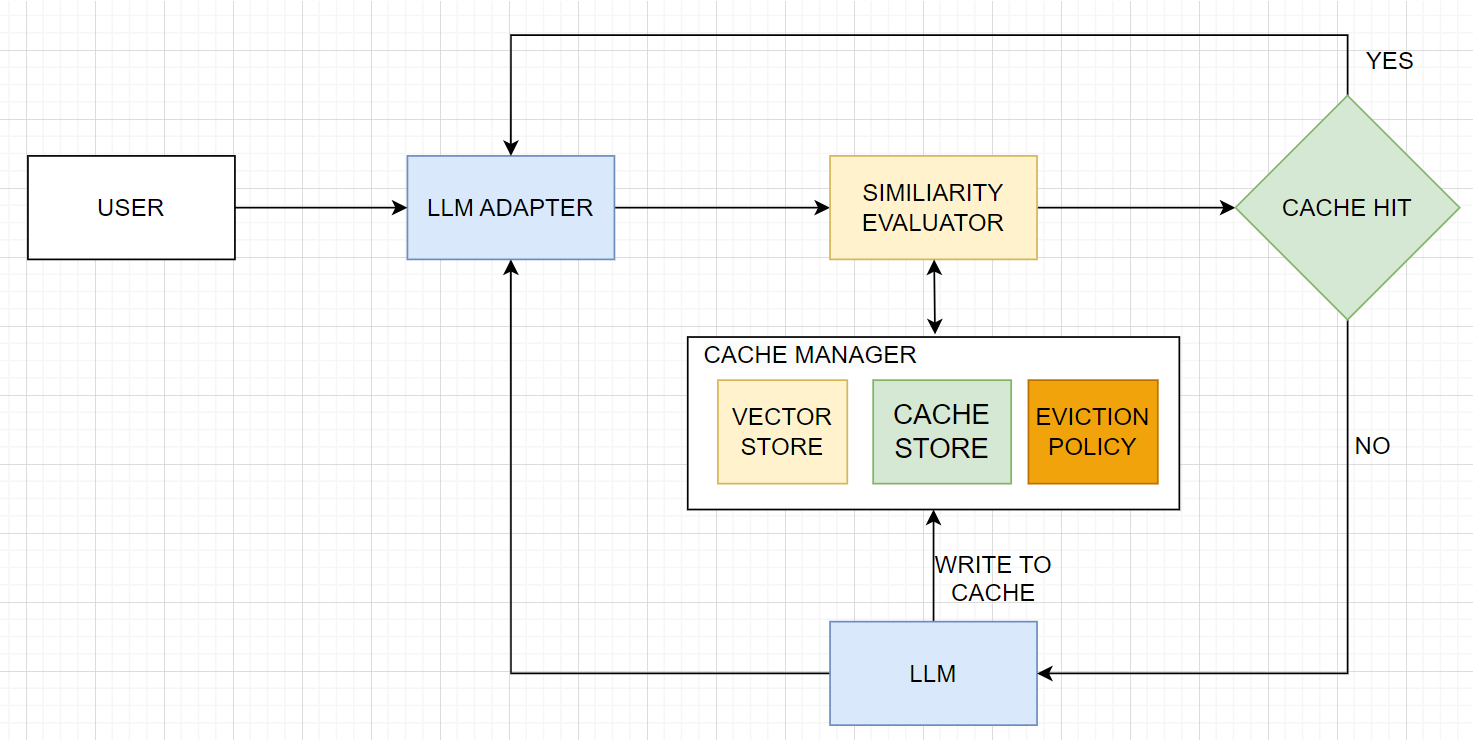 Fig 2. Flowchart of GPTCache in action
Fig 2. Flowchart of GPTCache in action
When a user submits a query, the first step is to generate an embedding to enable similarity searching. GPTCache supports several methods for embedding contexts, including OpenAI, Cohere, Huggingface, ONNX, and Sentence Transformers, as well as two LLM adapters: OpenAI and Langchain. These tools convert text and potentially image or audio queries into dense vectors. The LLM adapter allows the selection of a specific model to handle the task.
GPTCache utilizes vector storage to manage and retrieve the K most similar requests based on embeddings derived from user inputs. It supports vector search libraries like FAISS and vector databases like Milvus for efficient search capabilities. For caching these responses from the LLM, GPTCache can integrate with various database options, including SQLite, MySQL, and PostgreSQL. Milvus stands out as a pivotal backbone for AI memory systems, particularly its ability to handle high-performance fast vector searches across massive datasets, making it highly scalable and reliable. This is especially crucial for generative AI models like ChatGPT, where maintaining a responsive and dynamic memory system enhances overall performance and user interaction quality. Additionally, Milvus fosters a developer-friendly community with multi-language support, contributing to its accessibility and adaptability for various programming environments.
Once GPTCache is in place, a crucial step is to establish a method for determining if an input query matches cached answers. This is where the similarity evaluation process comes into play. The evaluation function, using user-defined parameters, compares the user's request data with the cached data to assess match suitability. If a similarity is found, indicating a cache hit, a cached response is delivered to the user. If not, the model generates a new response which is then saved in the cache store. To manage cache efficiently, GPTCache implements eviction policies like Least Recently Used (LRU) or First-In-First-Out (FIFO) to discard older or less frequently accessed data.
As you notice on the colab notebook, before GPTCache, every user query is processed individually by ChatGPT, leading to higher latency, which also translates to increased operational costs due to the repetitive processing of similar questions. However, after GPTCache, when a query is received, GPTCache first checks if a similar question has been asked before. If a match is found in the cache, the stored response is used, drastically reducing response time and computational load.
Challenges and opportunities
According to a paper published by Zilliz, titled “GPTCache: An Open-Source Semantic Cache for LLM Applications Enabling Faster Answers and Cost Savings”, the authors argue that the effectiveness of GPTCache heavily relies on the choice of embedding model, which is critical because accurate vector retrieval depends on the quality of these embeddings. If the embeddings don't effectively capture the input text's features, they might return irrelevant cached data, affecting cache hit rates which don't typically exceed 90%. Further challenges include the limitations of current embedding models, which are optimized for search but not necessarily for caching, and the need for rigorous similarity evaluations to filter incorrect hits without drastically reducing overall cache effectiveness.
To improve cache accuracy, large models are being distilled into smaller models specialized for textual similarity, addressing issues with distinguishing between positive and negative cache hits. Additionally, large token counts in inputs pose challenges, as they may exceed the LLM's processing limits, leading to potential data loss in caching scenarios. Summary models are used to manage long texts, though this can destabilize the cache. Alternative methods such as using traditional databases for caching with textual preprocessing to standardize inputs are being explored, potentially allowing for simpler string matching or numeric range techniques to achieve cache hits.
Conclusion
By integrating GPTCache and Milvus with ChatGPT, businesses can create a more robust and efficient AI-powered support system. This approach leverages the advanced capabilities of generative AI and introduces a form of long-term memory, allowing the AI to recall and reuse information effectively. Such innovations underscore the transformative potential of AI in operational settings, promising substantial improvements in service quality and operational efficiency. To remain up to date with the recent advances in AI, check out more content on Zilliz Learn for free and the resources below.
Resources
Guest Post: Enhancing ChatGPT's Efficiency – The Power of LangChain and Milvus*
ChatGPT+ Vector database + prompt-as-code - The CVP Stack - Zilliz blog
https://zilliz.com/blog/langchain-ultimate-guide-getting-started
Caching LLM Queries for performance & cost improvements - Zilliz blog
Dense Vectors in AI: Maximizing Data Potential in Machine Learning

- Overview of ChatGPT Plugins
- Let see the difference GPTCache brings
- Challenges and opportunities
- Conclusion
- Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Key NLP technologies in Deep Learning
An exploration of the evolution and fundamental principles underlying key Natural Language Processing (NLP) technologies within Deep Learning.

Pandas DataFrame: Chunking and Vectorizing with Milvus
If we store all of the data, including the chunk text and the embedding, inside of Pandas DataFrame, we can easily integrate and import them into the Milvus vector database.
How to build a Retrieval-Augmented Generation (RAG) system using Llama3, Ollama, DSPy, and Milvus
In this article, we aim to guide readers through constructing an RAG system using four key technologies: Llama3, Ollama, DSPy, and Milvus. First, let’s understand what they are.