




Information Retrieval Metrics
Understand Information Retrieval Metrics and learn how to apply these metrics to evaluate your systems.
Read the entire series
- Raft or not? The Best Solution to Data Consistency in Cloud-native Databases
- Understanding Faiss (Facebook AI Similarity Search)
- Information Retrieval Metrics
- Advanced Querying Techniques in Vector Databases
- Popular Machine-learning Algorithms Behind Vector Searches
- Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
- Ranking Models: What Are They and When to Use Them?
- Navigating the Nuances of Lexical and Semantic Search with Zilliz
- Enhancing Efficiency in Vector Searches with Binary Quantization and Milvus
- Model Providers: Open Source vs. Closed-Source
- Embedding and Querying Multilingual Languages with Milvus
- An Ultimate Guide to Vectorizing and Querying Structured Data
- Understanding HNSWlib: A Graph-based Library for Fast Approximate Nearest Neighbor Search
- What is ScaNN (Scalable Nearest Neighbors)?
- Getting Started with ScaNN
- Next-Gen Retrieval: How Cross-Encoders and Sparse Matrix Factorization Redefine k-NN Search
- What is Voyager?
- What is Annoy?
Information Retrieval (IR) systems are designed to traverse extensive, dense datasets using relevant input queries. These systems use statistical algorithms to match the input query with reference documents and retrieve the most relevant information using ranking metrics. IR is used in popular search engines like Google. It is also deployed in local organizations to retrieve company-related documents.
Before deployment, the IR system must be appropriately evaluated using information retrieval metrics. These metrics judge IR systems based on the search relevance between the input query and the retrieved results. This blog will discuss key information retrieval metrics and how they are implemented against IR systems.
Key Information Retrieval Metrics
Some popular basic information retrieval metrics include:
- Precision@k: Precision evaluates the true positives in the retrieved results. It analyzes how many returned results are relevant to the search query. The ‘@k’ appended to the metric describes the top-k results analyzed during evaluation. E.g., Precision@5 would mean precision for the first five outputs.
- Recall@k: Recall evaluates the IR system by analyzing the number of relevant items returned against all the relevant items present in the database. The top-k value highly impacts it since if k is equal to the entire dataset, the recall would be 1. The top-k preference has to be set according to the application requirements.
- F1-Score@k: F1 is the harmonic mean between precision and recall. It provides a balance between the two metrics and is used when both the above evaluations are relevant.
These metrics are order-unaware and are not bothered by the sequence of the returned results.
However, ranked metrics are impacted by the order of the retrieved results. Some popular ranking metrics include:
- MAP (Mean Average Precision): MAP has two parts. First, it calculates the average precision for multiple values for k, ranging from 1 to N, for a single query. The second part takes the mean of the average precision for all possible queries.
- NDCG (Normalized Discounted Cumulative Gain): NDCG considers two ranks associated with each element in the database. The first rank is user-assigned and has a higher value depending on the element relevant to the user query. The IR system provides the second rank. NDCG compares the ground truth and the system-generated rank for evaluation.
Understanding Recall and Precision
Recall and precision, in the context of information retrieval, directly analyze the relevance of the returned results. They have similar workings but different scopes. Precision judges the retrieval system based only on the items returned in the result set. Its formula is

True positives are all the relevant results within the subset (defined by k), and false positives are irrelevant. Given a dataset of 10 images, say we want to evaluate the top 5 results (k=5). Three of these are relevant to the query, while two are not. Precision for this system would be
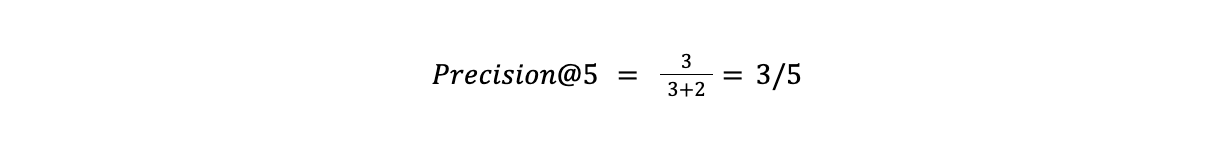
Recall evaluates the relevancy of returned results based on all the relevant results present in the database. Its formula is

The false negatives in the formula depict all the relevant items that were not part of the final result set. Continuing our example from before, if we have four relevant results in the remainder of the dataset, its recall would be
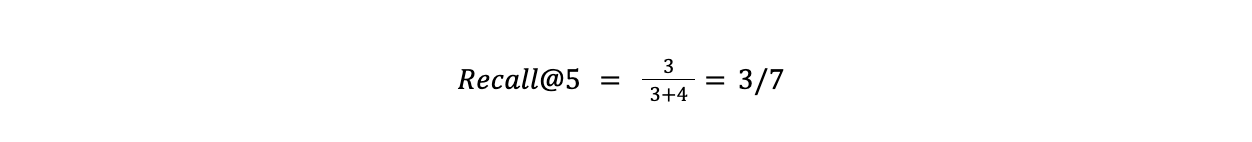
Developers often face the precision-recall trade-off where they have to find a balance. Both metrics are contrasting as precision showcases the system based on the true labels retrieved while recall judges the true labels left behind. An effective IR system must display reasonable values of both.
Advanced Metrics: NDCG and MAP
Advanced metrics, like NDCG and MAP, are order-aware, which means the metric value is impacted depending on the order of the retrieved items.
MAP (Mean Average Precision)
MAP uses the precision metric at its core. However, instead of using a single value of k, MAP takes the average of multiple precision values calculated against different values of k.
If k is set to 5, precision is calculated for 1,2,3,4 and 5 and then averaged to give Average Precision (AP). However, a robust information retrieval system should work for various user inputs. MAP calculates the AP against multiple queries and then takes the mean of all the values. The final MAP value better represents the system performance against different inputs.
NDCG (Normalized Discounted Cumulative Gain)
NDCG uses a ground truth rank associated with every element in the database. The range of the ranks can be user-defined. For example, a user query of ‘White sports car with a red spoiler’ will have several images that relate to it on different levels. An image that matches the description might be given a rank of 5, while a completely irrelevant one will have a rank of 1. Any images that match the description in some parts will have the in-between ranks (2,3,4).
NDCG first takes the sum of the ranks of all the retrieved images. This sum will be higher if the result set contains more relevant images but will remain constant irrespective of the result order. This result is countered by introducing a log-based penalty. The penalty factor penalizes each image rank depending on its value and placement in the results. A lower value, ranked higher in the final set, will be penalized more. This way, the system will receive a lower score if it outputs irrelevant images first.
One final problem with this metric is that the score has no upper bound. This issue is countered by normalizing the final score and limiting it between 0 and 1. The normalization is performed by first calculating the score against the ideal-case scenarios, i.e., when the system ranks all relevant images at the top. Then, the actual score is divided by the ideal to get the final normalized value.
Applying Metrics to Evaluate Systems
IR metrics are used before application deployment for developer-level testing and improvement of the overall search framework. Testers usually have a framework that uses pre-defined queries and labeled documents to evaluate the IR system automatically. The framework highlights queries that show poor performance.
The most prominent use of information retrieval is in search engines like Google and Bing. These engines use statistical algorithms and vector databases to retrieve relevant documents from a dataset of billions. Evaluation metrics help improve the search relevance according to input queries and improve user satisfaction.
Conclusion
Information retrieval metrics evaluate the statistical algorithms that retrieve documents against user queries. These evaluation metrics check the relevance of the retrieved documents against the provided query. There are two categories of evaluation metrics: order-unaware and order-aware.
Order-unaware metrics include Precision, Recal, and F1-Score. These metrics do not care about the order of the retrieved documents and only focus on the overall relevance of the final subset.
Order-aware metrics include MAP and NDCG. These ranking metrics are slightly advanced and aggregate the evaluations against multiple search windows and queries. Order-aware metrics also consider the retrieval order and penalize systems that rank non-relevant documents above relevant ones.
What we have discussed in this article is just the tip of the iceberg. Large enterprises employ more complicated retrieval and evaluation frameworks to create robust search mechanisms. You are encouraged to explore retrieval mechanisms further, such as vector similarity search and vector databases, to better understand modern information retrieval evaluation.
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- Key Information Retrieval Metrics
- Understanding Recall and Precision
- Advanced Metrics: NDCG and MAP
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
Milvus enables hybrid sparse and dense vector search and multi-vector search capabilities, simplifying the vectorization and search process.

Navigating the Nuances of Lexical and Semantic Search with Zilliz
Learn the mechanics, applications, and benefits of lexical and semantic search and how to perform it in Zilliz.

Embedding and Querying Multilingual Languages with Milvus
This guide will explore the challenges, strategies, and approaches to embedding multilingual languages into vector spaces using Milvus and the BGE-M3 multilingual embedding model.