




A Different Angle: Retrieval Optimized Embedding Models
In modern data retrieval systems, users often require more than just one result from a query; they expect multiple relevant results that are ranked based on the query context. This expectation presents challenges for traditional embedding models, which typically focus on binary relationships. Recently, at the SF Unstructured Data Meetup, Robertson Taylor, a solutions architect at Marqo, introduced Generalized Contrastive Learning (GCL). This approach moves beyond binary pairings by integrating rank and query awareness into the model training process.
 Robertson speaking at August Unstructured Data Meetup in SF
Robertson speaking at August Unstructured Data Meetup in SF
This blog will explore the key insights from Robertson’s presentation and demonstrate how GCL can be integrated with Milvus, a leading vector database, to create optimized Retrieval-Augmented Generation (RAG) systems. While Marqo offers vector storage and retrieval solutions, this blog will focus on how users of Milvus can leverage GCL models finetuned with Marqtune, a Marqo finetuning platform, to enhance their retrieval capabilities.
To better understand how GCL addresses these challenges, let’s first look at the limitations of traditional embedding models, such as CLIP.
Watch the replay of Robertson's talk on YouTube.
Embedding Models and Their Limitations
Traditional embedding models, such as CLIP (Contrastive Language-Image Pretraining), are widely used for tasks like image search. These models are designed to minimize the distance between paired items, such as a caption and an image. While this approach works well for simple, binary relationships, it struggles to meet the more complex demands of retrieval systems that require ranked multimodal results.
Robertson began his presentation by addressing several challenges associated with existing models:
Binary Relationships: Models like CLIP learn from pairs of text and images, making them efficient for specific tasks but inadequate when ranking multiple results based on user queries.
Lack of Rank and Query Awareness: Many embedding models treat all queries equally, without adjusting results based on user behavior or interaction data.
Limited Multimodal Capabilities: Most models excel at working with either text or images but struggle to combine these data types effectively.
Ineffective Cross-field Combination: Existing models often fail to effectively combine information from multiple fields e.g., title, description, and reviews into a single vector representation.
These limitations mean that while traditional models perform adequately in controlled environments, they often fall short in real-world scenarios where ranking and multimodal capabilities are critical.
To illustrate how CLIP models are typically trained, let's look at the following diagram:
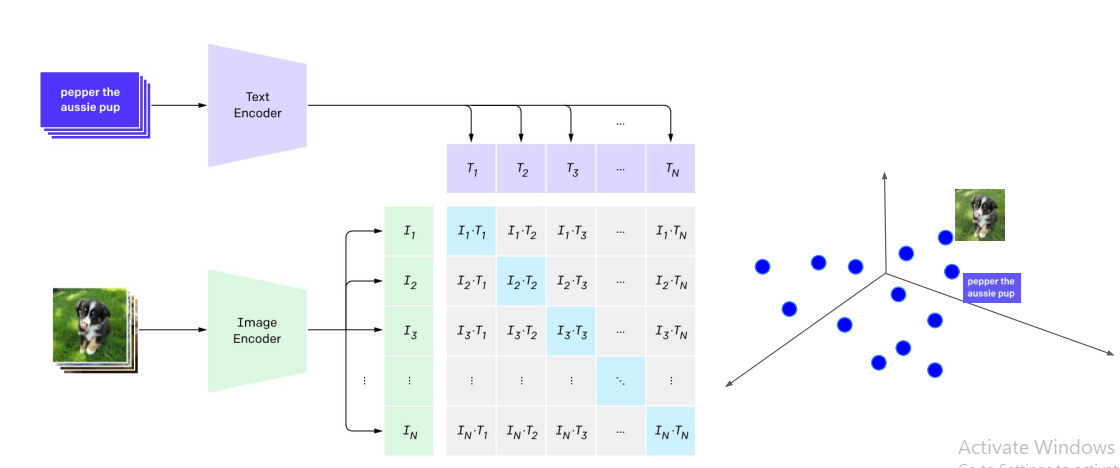 Figure 1: How CLIP is trained
Figure 1: How CLIP is trained
CLIP uses a two-tower architecture with a text encoder and an image encoder. The model is trained to minimize the distance between positive pairs (matching text and image) and maximize the distance between all other pairs. While this approach is effective for certain tasks, it doesn't account for the complexities of real-world retrieval scenarios. This is where GCL steps in.
Generalized Contrastive Learning (GCL): A Solution for Retrieval Optimization
To address the limitations of traditional models, Marqo introduced Generalized Contrastive Learning (GCL). This approach enhances embedding models by incorporating rank awareness and query awareness into the training process, which significantly improves the relevance and ranking of retrieval results.
GCL tackles these challenges through several key innovations:
Rank Awareness: GCL solves this by incorporating user interaction data, such as clicks and add-to-cart actions, into the training process. This allows the model to learn how to rank results based on user preferences.
Query Awareness: Instead of treating all queries equally, GCL fine-tunes embeddings to account for the context of a query. For instance, when a user searches for an SLR camera, GCL factors in whether the query comes from a professional photographer looking for high-end gear or a consumer looking for an entry-level model. This query-awareness allows the system to return more relevant results.
Multimodal Capabilities: GCL supports multimodal retrieval by allowing the system to embed and retrieve both text and images in a unified way. For example, in an e-commerce setting, GCL can combine product titles, descriptions, reviews, and images into a single vector, providing more relevant search results.
Cross-field Combination: GCL enables the model to effectively combine information from multiple fields into a single vector representation, improving the overall quality of search results.
Intramodal Understanding: By incorporating various text fields during training, GCL improves the model's ability to handle text-to-text queries more effectively.
To illustrate how GCL works, let's look at the following diagram that shows the process of optimizing multimodal retrieval using GCL:
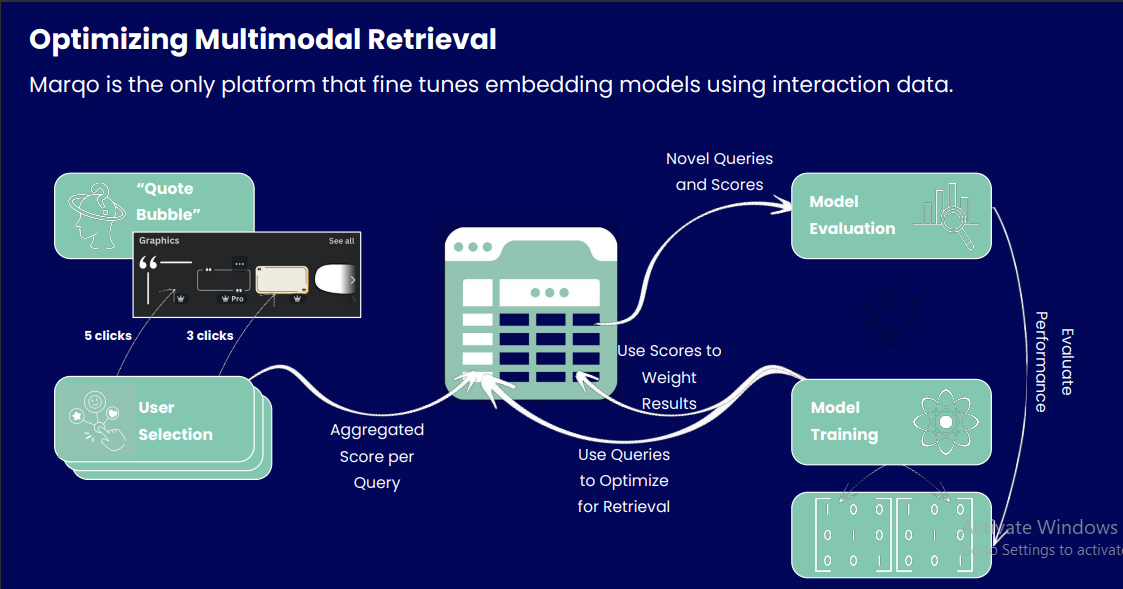 Figure 2: Process of optimizing multimodal retrieval using GCL
Figure 2: Process of optimizing multimodal retrieval using GCL
The system begins by capturing user interactions, such as clicks on search results. These interactions are then aggregated to create a score for each query-result pair. The queries are used to train the model for better retrieval performance, while the aggregated scores are used to weigh the importance of different results during training. The model is then trained using this weighted data, incorporating both query information and user interaction scores. Finally, the trained model is evaluated using novel queries and scores to assess its performance.
This process allows the model to learn from real user behavior and optimize for actual retrieval scenarios, rather than just minimizing distances between pre-defined pairs. Now that we’ve seen how GCL solves key challenges in retrieval optimization, let’s explore how it can be fine-tuned for specific tasks and real-world applications.
Fine-tuning Tasks with GCL
GCL is versatile and can be used to fine-tune models for various retrieval-style tasks beyond basic search. The following image illustrates some of these tasks:
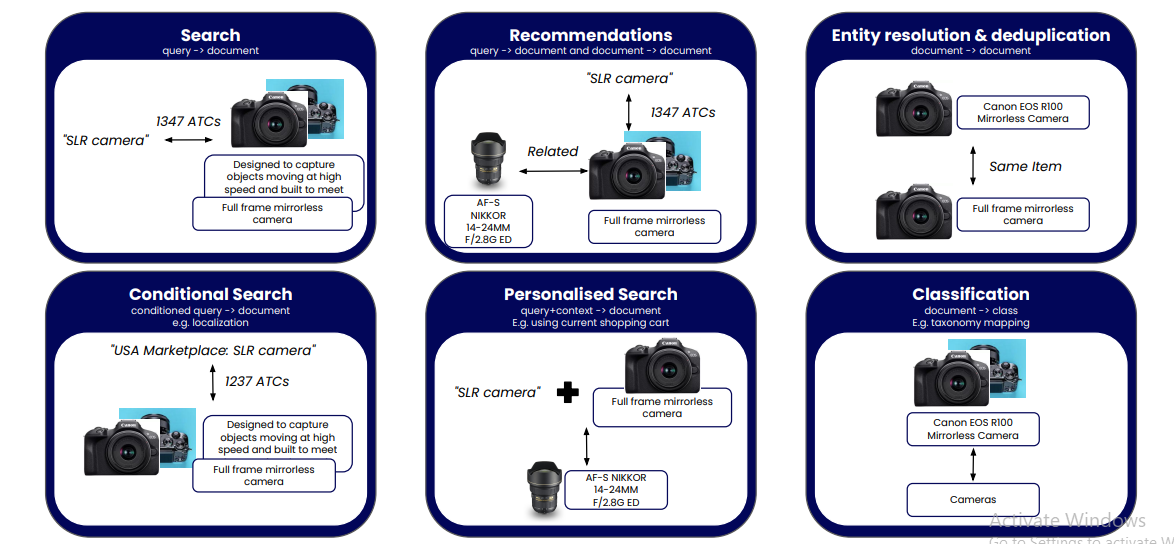 Figure 3: Examples of fine tuning tasks with GCL
Figure 3: Examples of fine tuning tasks with GCL
Let's explore each of these fine-tuning tasks in more detail:
Basic Search Enhancement
GCL improves traditional query-to-document retrieval by incorporating user interaction data. This means that when a user searches for a term, the model doesn't just match keywords but also considers how users have interacted with similar queries and results in the past. For example, if many users who searched for a lightweight laptop clicked on ultrabooks, the model learns to rank ultrabooks higher for this query, even if the term ultrabook isn't explicitly mentioned.
Advanced Recommendations
GCL enables both query-to-document and document-to-document recommendations. This dual approach allows for more nuanced and contextual product suggestions. In query-to-document recommendations, GCL can suggest products based on a user's search query, factoring in not just the query terms but also user behavior patterns. For document-to-document recommendations, GCL can identify related products based on similarities in features, user interaction patterns, or contextual relevance, even when the items aren't overtly similar.
Entity Resolution and Deduplication
GCL's document-to-document matching capabilities make it powerful for entity resolution and deduplication tasks. It can identify similar or identical items across a dataset, even when there are slight variations in how the items are described or categorized. This is particularly useful in e-commerce for identifying duplicate product listings or in data integration projects where the same entity might be represented differently across multiple data sources.
Conditional Search
This feature allows GCL to incorporate contextual information into the search process. For example, a search for winter jackets yields different results based on the user's location (e.g., heavy down jackets for cold climates, lighter jackets for milder winters). GCL learns to adjust its results based on these conditional factors, providing more relevant search outcomes tailored to specific contexts or marketplaces.
Personalized Search
GCL takes personalization a step further by factoring in user-specific context, such as browsing history, items in the current shopping cart, or past purchase behavior. This allows for highly tailored search results that align with the user's current interests and needs. For instance, if a user has been browsing high-end camera equipment, a search for a tripod ****might prioritize professional-grade options over budget alternatives.
Classification and Taxonomy Mapping
GCL can be applied to classification tasks, such as automatically categorizing products into a predefined taxonomy. This is particularly useful for large e-commerce platforms or content management systems where manual categorization would be time-consuming and error-prone. GCL can learn from existing categorizations and user interactions to make intelligent decisions about how to classify new items, ensuring consistency and improving the overall organization of large datasets.
These fine-tuning tasks make GCL highly adaptable for various retrieval challenges. Let’s see how GCL is being applied in real-world scenarios.
Real-World Applications of GCL
Robertson shared several examples of how GCL is being used to solve real-world problems. One notable case involved an e-commerce platform that had initially implemented a basic vector search solution using an off-the-shelf model. However, the platform saw a sharp decline in add-to-cart rates and overall engagement, as the system was not providing relevant results.
After integrating GCL, the platform saw significant improvements. Products that were more aligned with user preferences were ranked higher, leading to better engagement and increased sales. The platform was able to leverage unstructured data like user reviews and product images to improve the relevance of search results. By incorporating data from user interactions, such as clicks and purchase behavior, the platform enhanced its ability to deliver personalized, ranked search results.
In the academic research domain, GCL improved the retrieval of relevant research papers by incorporating metadata such as author details and citations into the search process. This not only sped up the search process but also increased the relevance of the results, making the system more effective for researchers navigating large databases.
Let’s now look at how GCL incorporates advanced techniques to further improve performance in production environments.
Advanced Techniques in GCL
Robertson touched on several advanced techniques that can further enhance the performance of GCL models. These include production-aware training methods such as truncation and binarization of embeddings.
 Figure 4: Truncation and binarization of embeddings
Figure 4: Truncation and binarization of embeddings
Truncation-aware training allows for the creation of Matryoshka embeddings, which can reduce the size of embeddings by 2-4x without loss in fidelity. The model learns to create meaningful representations of various sizes from a single model. Learning to binarize is another technique that allows for significant reductions in storage and latency with minimal loss in fidelity by learning embeddings that are only 0 or 1. These techniques are particularly valuable in production environments where storage costs and retrieval speed are critical factors.
GCL also supports the creation of conditional embeddings, which allow for more nuanced control over search results
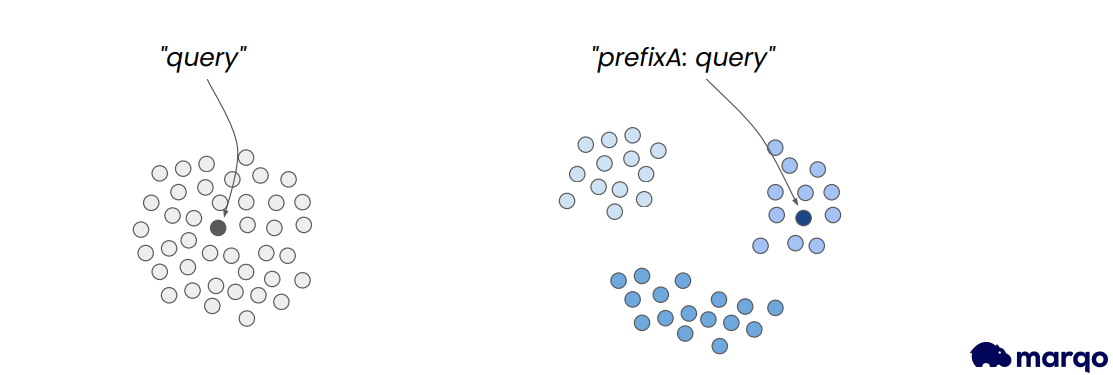 Figure 5: Conditional Embeddings
Figure 5: Conditional Embeddings
By using prefixes or conditional statements in queries, the model can learn to adjust its results based on specific conditions. For example, USA Marketplace: SLR camera could yield different results than UK Marketplace: SLR camera. Conditional embeddings can also be used to influence the style or quality of results, similar to how prompts work in image generation models.
These advanced techniques not only enhance the technical aspects of GCL but also lead to performance improvements in real-world retrieval tasks. Let’s take a look at how GCL-trained models perform compared to traditional approaches.
Performance Improvements with GCL
Using GCL improves performance across several various scenarios. Let us take a look at some of those shared by Robertson:
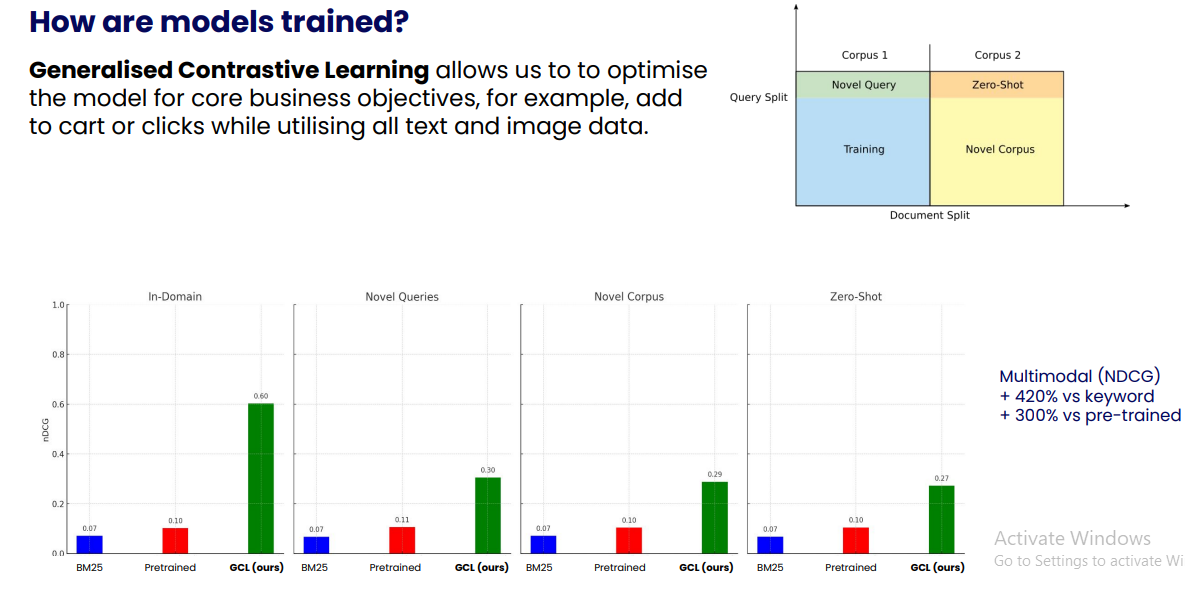 Figure 6: Performance comparison between GCLtrained embedding models versus others
Figure 6: Performance comparison between GCLtrained embedding models versus others
In-domain performance showed a 6x increase in NDCG (Normalized Discounted Cumulative Gain) compared to pre-trained models. For novel queries not seen during training, GCL still outperformed pre-trained models by nearly 3x. When applied to new datasets not seen during training, GCL maintained its performance advantage. Even in zero-shot scenarios, GCL showed improvements in NDCG compared to traditional models. These results demonstrate the robustness and generalizability of GCL across various retrieval scenarios.
With such significant improvements in retrieval effectiveness, especially in novel and zero-shot scenarios, GCL is poised to redefine performance in retrieval systems. Now, let’s see how you can bring these advantages to your own RAG applications by leveraging GCL with Milvus.
Leveraging GCL with Milvus for RAG Applications
While Marqo provides a comprehensive solution for embedding-based retrieval, many organizations already rely on Milvus for their vector database needs. If you're using Milvus or planning to integrate it into your data infrastructure, you can still benefit from GCL fine-tuned models in your Retrieval-Augmented Generation (RAG) applications.
Here's how you can integrate GCL with Milvus for RAG:
Fine-Tuning with Marqtune: Use Marqtune, Marqo's fine-tuning platform, to apply GCL to pre-trained models. This process optimizes the model for your specific retrieval tasks.
Downloading the Fine-tuned Model: After fine-tuning, download the optimized model from Marqtune.
Integration with Milvus: Use the fine-tuned model to generate embeddings, which can then be stored and searched in Milvus.
Efficient Retrieval: Leverage Milvus's optimized large-scale, high-speed vector retrieval capabilities. When combined with GCL's query-aware embeddings, Milvus can efficiently rank and return relevant results, even in complex, multimodal datasets.
Scalability: As your dataset grows, Milvus can handle the increasing demands of storing and searching billions of embeddings, ensuring that performance remains consistent.
With the combined power of GCL and Milvus, retrieval-augmented systems can achieve impressive scalability and performance. But what makes Milvus such an ideal fit for these applications?
Why Choose Milvus for Your GCL-Enhanced RAG System?
When implementing a Retrieval-Augmented Generation (RAG) system using Generalized Contrastive Learning (GCL) fine-tuned models, choosing the right vector database is crucial. Milvus stands out as an excellent choice due to its robust features and advanced technologies. Let's explore why Milvus is well-suited for handling GCL-generated embeddings and powering efficient RAG applications.
Key Features of Milvus
Multi-tenancy Support: Milvus allows multiple users or applications to work on the same system without interfering with each other. This feature provides secure, isolated data access, making it ideal for enterprise environments where different teams or projects may need to use the same Milvus instance. In the context of GCL-enhanced RAG systems, you can run multiple retrieval tasks for different departments or use cases on a single Milvus deployment, maintaining data separation and security.
Scalable and Elastic Architecture: Designed to handle growing data needs, Milvus automatically scales to meet demand. This ensures that performance remains optimal as your data volume increases. This scalability is crucial for RAG applications, which often deal with rapidly expanding document collections. As you fine-tune more models with GCL and generate more embeddings, Milvus can effortlessly accommodate the growth without compromising retrieval speed or efficiency.
Diverse Index Support: Milvus supports multiple types of indexes, including HNSW (Hierarchical Navigable Small World), PQ (Product Quantization), Binary, and DiskANN. This variety allows you to choose the most appropriate index type for your specific use case, balancing search speed, accuracy, and storage efficiency. For instance, HNSW might be ideal for high-speed searches in GCL-generated embeddings, while PQ could be used for more compact storage of large embedding sets.
Tunable Consistency: Milvus allows you to adjust the consistency levels for your data, enabling a balance between performance and data accuracy based on your application's needs. In the context of RAG systems, this feature is particularly useful. You might prioritize search speed for real-time applications, or opt for stronger consistency in scenarios where data accuracy is paramount, such as in financial or medical applications.
Hardware-accelerated Compute: Optimized to leverage hardware like GPUs, Milvus offers faster and more efficient processing for resource-intensive tasks. This is especially beneficial when working with GCL models, which can be computationally demanding. The hardware acceleration ensures that even as your embedding database grows, retrieval times remain swift, maintaining the responsiveness of your RAG system.
Advanced Technologies Powering Milvus
Flexible Compute Types: Milvus is optimized for various hardware environments, including AVX512 (Advanced Vector Extensions), Neon for SIMD (Single Instruction, Multiple Data), and GPU acceleration. This flexibility allows Milvus to leverage high-performance hardware effectively, delivering fast processing and cost-effective scalability. For GCL-enhanced RAG systems, this means you can choose the most suitable compute type based on your available hardware and performance requirements.
Versatile Search Capabilities: Milvus supports a wide array of search methods, including top-K ANN (Approximate Nearest Neighbors), range ANN, and filtered searches. These diverse search types allow you to tailor the retrieval functionality to your specific needs. For instance, top-K ANN could be used to find the most relevant documents for a given query embedding, while filtered searches could combine semantic similarity with metadata filters for more precise retrievals.
Advanced Indexing Techniques: With support for 15 different indexing types, Milvus offers flexibility in how data is stored and searched. This includes advanced techniques like HNSW for high-speed searches and DiskANN for handling massive datasets. The right choice of index can significantly impact the performance of your RAG system, allowing you to optimize for either search speed or memory efficiency, depending on your priorities.
Language and API Flexibility: Milvus provides support for multiple programming languages, including Python, Java, Go, and Node.js. This versatility makes it easy to integrate Milvus into existing tech stacks and allows developers to work with their preferred languages. For RAG systems, this means you can seamlessly incorporate Milvus into your existing codebase, regardless of the language it's built-in.
Robust Data Management: Milvus offers sophisticated data management capabilities, including collection and partition management. This allows for efficient organization and retrieval of large-scale embedding datasets. For GCL-enhanced RAG systems, you can structure your embeddings into logical collections (e.g., by document type or domain) and partitions, enabling more targeted and efficient searches.
Given its robust architecture and advanced capabilities, Milvus provides the ideal infrastructure for leveraging GCL-enhanced models in retrieval-augmented systems.
Conclusion
Robertson did a great job of showing how Generalized Contrastive Learning (GCL) enhances retrieval by introducing rank and query-awareness, improving the relevance and ranking of results. This approach moves beyond traditional binary models, making it highly effective for applications like e-commerce and academic research.
We have also seen how Milvus further supports these advancements with its scalable architecture and efficient handling of embeddings, enabling high-speed retrieval and optimized performance for complex, multimodal datasets. Together, GCL and Milvus provide a robust solution for building next-generation retrieval-augmented systems.
Keep Reading

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.