




Challenges in Structured Document Data Extraction at Scale with LLMs
One of the core challenges in applying large language models (LLMs) lies in the data processing phase, particularly when handling diverse data formats. You can typically classify data into three types: structured, semi-structured, or unstructured. Since LLMs primarily work with text, they are often applied to unstructured data unless the data is already organized into a relational table.
In a recent webinar, Tim Spann, Principal Developer Advocate at Zilliz, introduced Unstract, an open-source platform designed to streamline the extraction of unstructured data and transform it into structured formats. This tool aims to simplify data management by automating the structuring process.
In this blog, we’ll dive into the primary challenges of structured document data extraction, as outlined by Shuveb Hussain, Co-founder and CEO of Unstract. We'll also explore how Unstract tackles various scenarios, including its integration with vector databases like Milvus, to bring structure to previously unmanageable data.
Current Limitations
Structuring data has long been complex and time-consuming, especially as machine learning models demand ever-increasing amounts of data. Historically, a significant portion of this extraction work has been done manually—such as in the case of scanned handwritten documents—because automation could not fully meet the varied needs of models.
While large language models (LLMs) have advanced the ability to analyze and extract information from documents, they have notable limitations. Documents often appear in various formats, such as tables, forms, charts, and scans, where the quality and consistency of the data play a crucial role in successful extraction. Furthermore, many applications require processing vast quantities of documents, and not all adhere to a uniform structure. This can require additional customization in the extraction process, as LLMs may struggle to handle highly variable or complex layouts without human intervention.
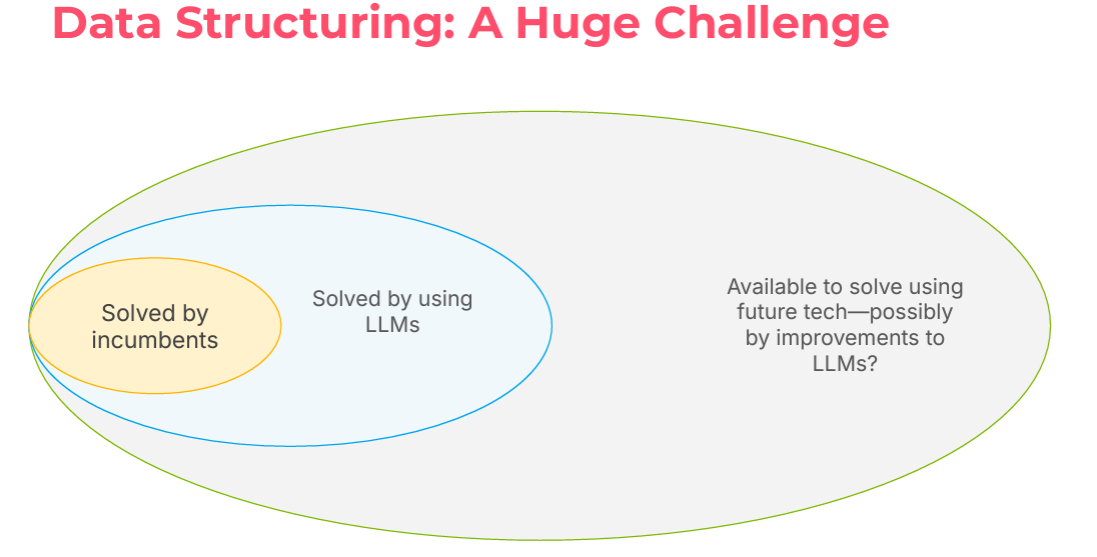 Figure 1: Data Structuring Challenges
Figure 1: Data Structuring Challenges
Figure 1 illustrates a challenge bubble chart showcasing the landscape of current developments in structured document data extraction. The chart highlights three key areas:
A small set of use cases that have been successfully solved by current technology.
A significant portion of the market is actively being addressed by large language models (LLMs).
A vast potential of unsolved business cases that remain open. These cases might be addressed in the future, depending on advancements in various technologies.
This visualization emphasizes the gap between what is currently achievable and the potential breakthroughs in the near future, like AI agents application development.
Document Extraction
Anyone who has attempted to extract text from documents using LLMs knows how challenging it can be to obtain all the necessary information with just a few lines of code. While tools like Co-pilots can assist in this process, they often fall short of providing a fully automated solution. The extracted data may not always have the desired structure, and a human intervention step is frequently required to organize the information into the correct format.
This is where Unstract provides a fully automated solution where unstructured documents can be transformed into structured data without the need for human oversight. Unstract uses an LLM-based technology to extract the information.
 Figure 2: Document Extraction
Figure 2: Document Extraction
Unstract Cloud
Unstract is a no-code LLM platform that falls under the category of Intelligent Document Processing (IDP). It streamlines document extraction by dividing the process into two main steps:
Prompt Engineering: Unstract’s Prompt Studio allows users to develop generic prompts for specific document types, which can then be reused to extract structured data from other documents of the same type.
Deployment Phase: Once the prompts are created, they can be deployed in various ways, including as an ETL pipeline, an API endpoint, or as part of a manual review queue for further inspection.
Unstract offers two approaches to achieve accurate data extraction:
Enhanced Accuracy (LLM Challenge): This method involves processing the document with one LLM and using a second LLM to challenge the output of the first. If the two models do not reach a consensus, the specific field being extracted is set to null, avoiding the risk of incorrect data being populated. This significantly reduces the risk of hallucinations, as two models from different vendors are unlikely to produce the same wrong output.
Reduced costs
SinglePass Extraction: Instead of sending multiple prompts for individual fields, this approach consolidates all prompts into a single request. The LLM returns a JSON output containing all required fields in one pass, reducing token usage and latency.
Summarized Extraction: This method creates a summary of the input document using the LLM based on the user’s prompts. The summary is then used to extract the necessary fields, optimizing token usage and further reducing latency.
 Figure 3: Unstract Extraction Strategies
Figure 3: Unstract Extraction Strategies
Figure 4 and 5 show an example of a Single Pass Extraction project, where we can see that several prompts are combined to get a single JSON output.
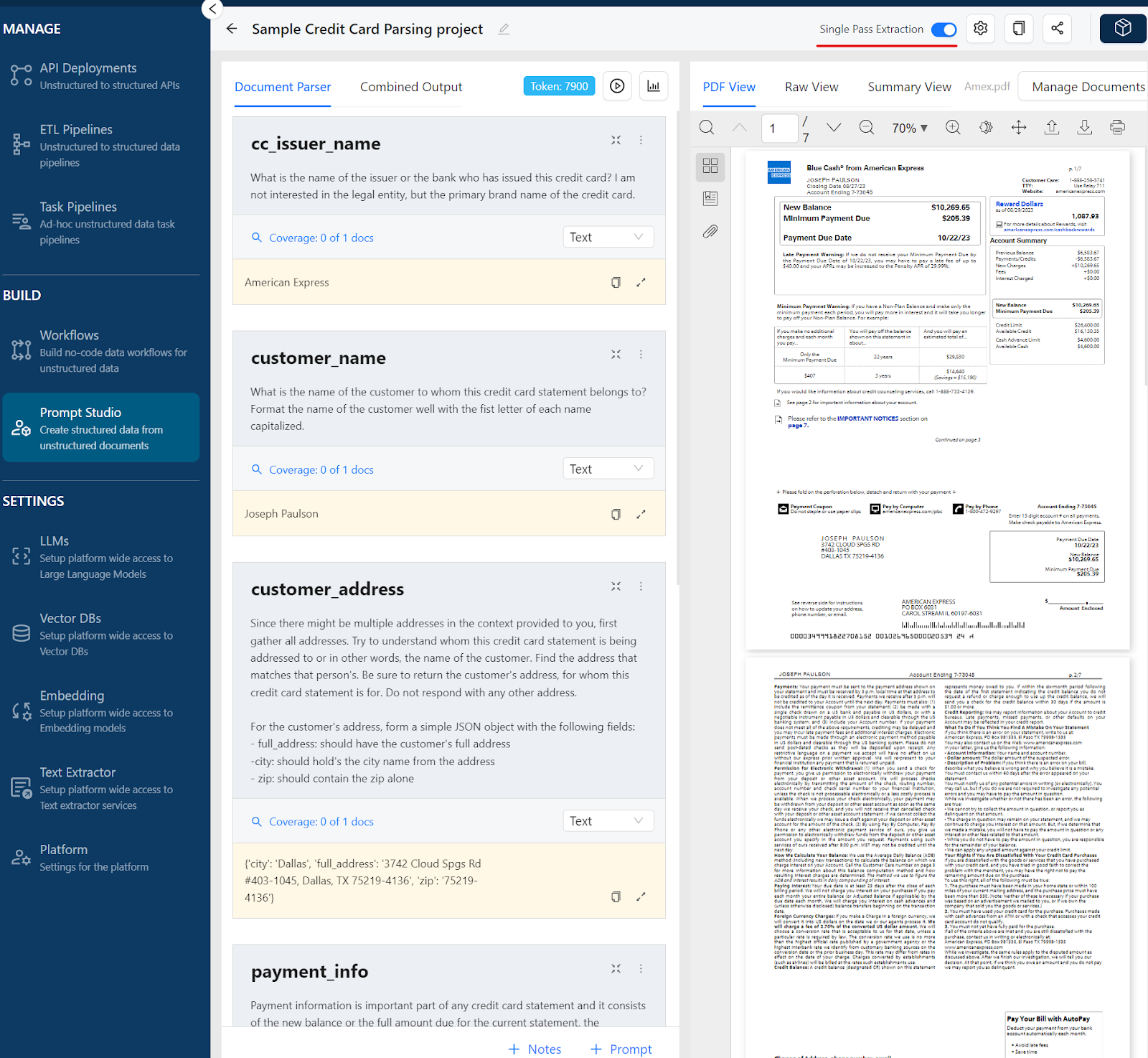 Figure 4: Unstract Prompt Studio (Document Parser)
Figure 4: Unstract Prompt Studio (Document Parser)
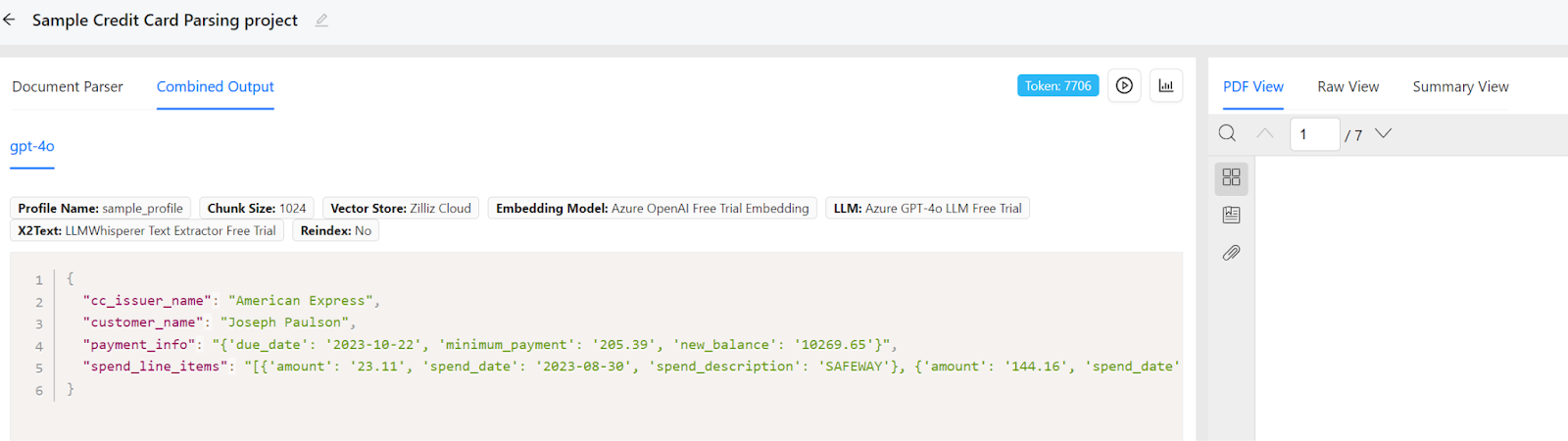 Figure 5: Unstract Prompt Studio (Combined Output)
Figure 5: Unstract Prompt Studio (Combined Output)
Additionally, users can configure various options to tailor the extraction process. These include selecting a vector database like Milvus or Zilliz Cloud to store and retrieve vector embeddings, choosing a second LLM model to compare outputs like costs or latency, or select the challenge LLM option if accuracy has priority over costs.
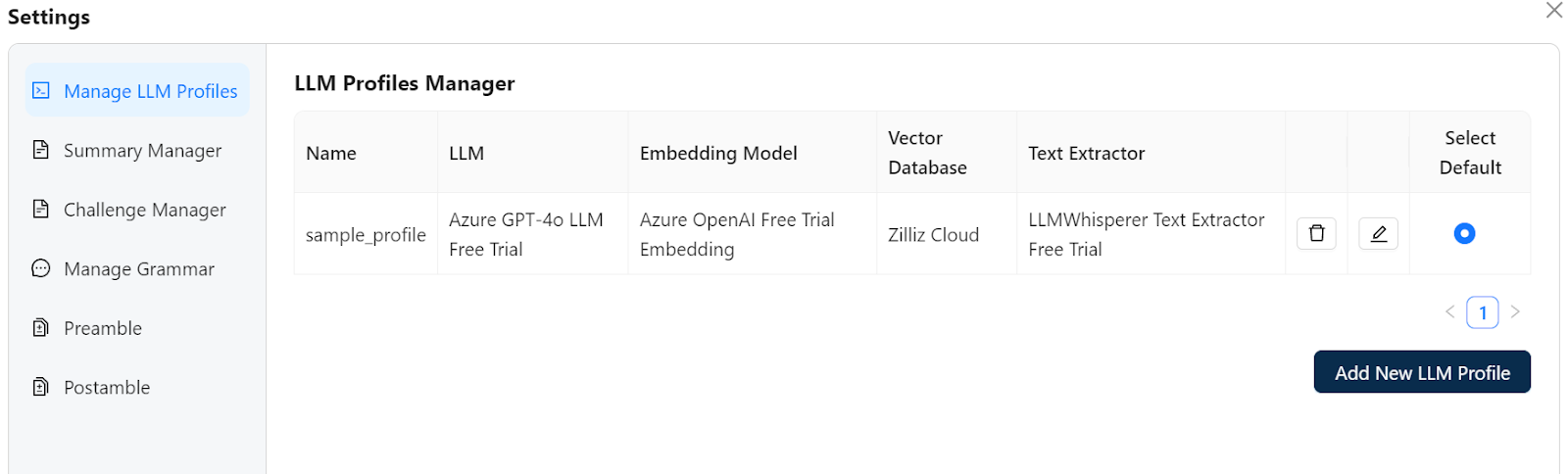 Figure 6: Unstract Prompt Studio: Settings
Figure 6: Unstract Prompt Studio: Settings
Once the settings are defined and the results of the text extraction are satisfactory, you can export the workflow as a tool (Figure 7), select the workflow to be deployed (Figure 8) and get the API endpoint (Figure 9).
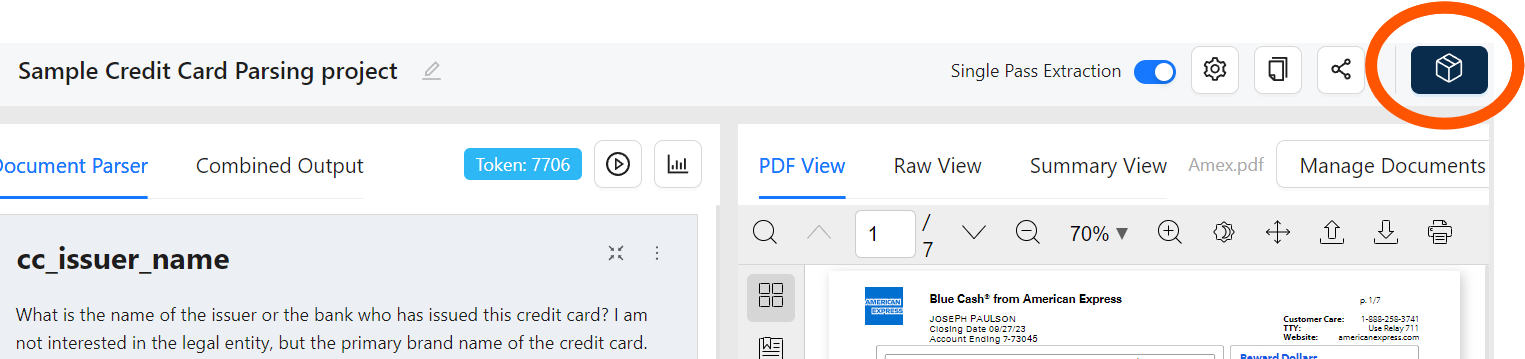 Figure 7: Export the Workflow as a Tool
Figure 7: Export the Workflow as a Tool
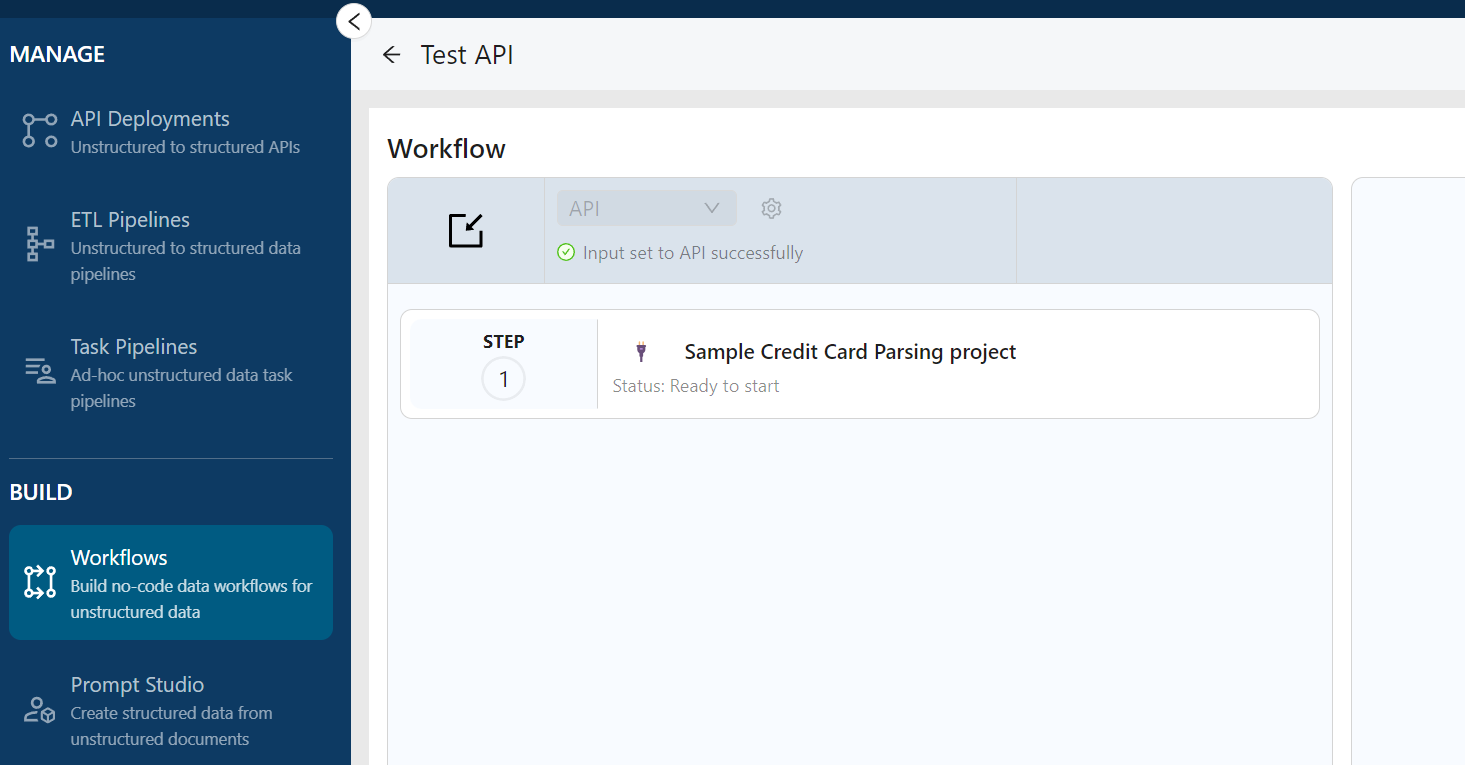 Figure 8: Export the Workflow as a Tool
Figure 8: Export the Workflow as a Tool
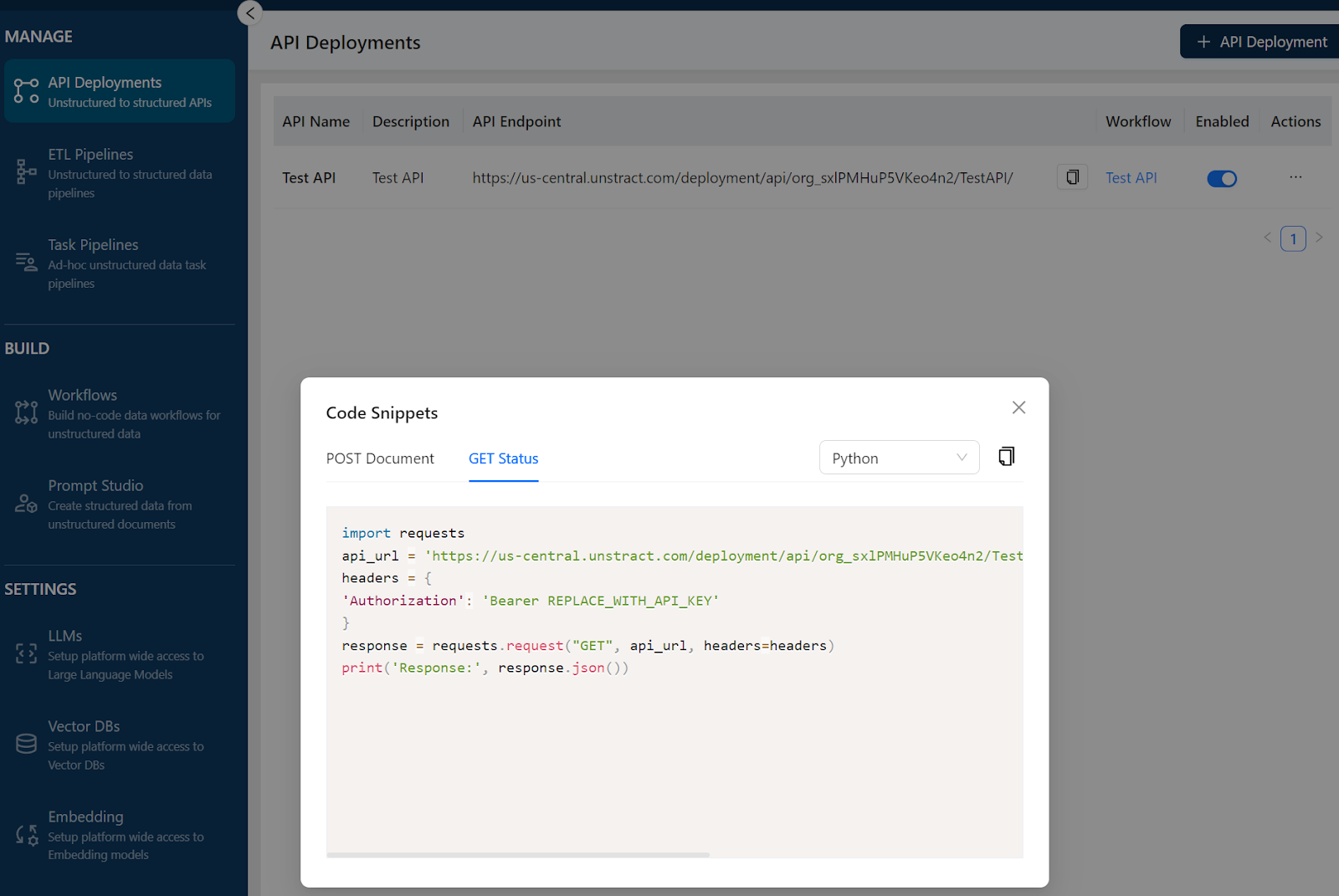 Figure 9: Deploy API Endpoint
Figure 9: Deploy API Endpoint
Unstract Retrieval Strategies
Under Settings, users can choose from two retrieval strategies:
Simple: This strategy uses a single query to retrieve relevant chunks of information, employing a combination of keyword matching and vector search to ensure accuracy.
Subquestion: This approach involves decomposing a complex query into simpler subquestions. Each subquestion retrieves relevant information, which is then aggregated to provide a comprehensive response to the original complex query.
Although the simple retrieval approach offers speed and cost-efficiency, it may not capture the nuanced understanding that more sophisticated models can provide.
The subquestion retriever is especially valuable for addressing complex questions that need to integrate information from various contexts or domains. By focusing on the specific information requirements of each subquestion, this approach improves the model's capability to handle detailed queries effectively.
Conclusion
The field of structured document data extraction is rapidly changing, thanks to advancements in large language models and innovative tools like Unstract. Unstract offers an effective way to turn unstructured data into structured formats in combination with vector data bases like Zilliz Cloud, while focusing on both accuracy and cost savings. With different retrieval strategies, it helps users handle complex questions in a user-friendly way.
Looking ahead, the potential for further improvements in intelligent document processing is huge as highlighted by Shuveb Hussain during the webinar. As the need for efficient data extraction grows, platforms like Unstract are ready to lead the way. By making these technologies better, they help organizations turn unstructured data into useful insights.
This shift toward fully automated document processing isn't just about technology; it's about changing how data are managed across different industries. By adopting these advancements, organizations can discover new opportunities for growth in an increasingly data-driven world.

Keep Reading

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.