




Unstructured Data Processing from Cloud to Edge
Unstructured data now accounts for about 80% of the data we handle, ranging from text and images to videos, audio, and more complex formats. As its volume grows, so does the need for better ways to process and analyze it.
At a recent webinar, Tim Spann, Principal Developer Advocate at Zilliz, shared his insights on managing unstructured data, particularly from cloud environments to edge devices. He also highlighted how vector databases like Milvus are key to making sense of this data.
In this post, we'll recap Tim’s main points, discussing the challenges in handling unstructured data and how vector databases lead the way. We’ll also look at how edge devices powered by these databases are driving new advancements in AI. If you’re interested in more details, we recommend watching the full replay of Tim’s talk on YouTube.
Understanding Unstructured Data
Unstructured data refers to information that lacks a predefined format or schema. Unlike structured data, which is neatly organized in databases with specific fields and formats, unstructured data is raw and unorganized. It often includes:
Text: Emails, word documents, social media posts
Images: Photos, screenshots, diagrams
Videos: Recorded meetings, surveillance footage, multimedia content
Audio: Voice recordings, music files, podcasts
With the surge in digital content, unstructured data has grown exponentially, offering both opportunities and challenges for organizations. To capitalize on this wealth of information, companies can:
Enhance Customer Experience by analyzing customer interactions and feedback
Improve Operational Efficiency through insights from sensor data and system logs
Drive Innovation by leveraging multimedia content for product development
Traditional databases, designed to handle structured data, struggle with the irregularity of unstructured data, making it difficult to search, query, or extract meaningful insights. This is where vector databases become essential, offering a solution for managing and retrieving unstructured information efficiently.
Why Use a Vector Database for Unstructured Data Processing?
A vector database is a specialized database designed to store, index, and query vector representations of data (also known as vector embeddings), often derived from unstructured data like text, images, and audio. These databases enable efficient similarity searches in a high-dimensional space, making them ideal for semantic search, natural language processing (NLP), recommendation systems, image searches, and retrieval augmented generation (RAG).
Vector databases such as Milvus and Zilliz Cloud offer a range of functionalities beyond high-performance search capabilities that make them crucial for managing unstructured data.
Beyond High-Performance Search
While vector databases are often associated with fast similarity search capabilities, their utility extends much further. They provide other essential functions that ensure the effective management and utilization of unstructured data:
CRUD Operations: Vector databases, like traditional databases, allow you to Create, Read, Update, and Delete (CRUD) data. This ensures that despite working with complex data types, the basic operations remain intuitive and accessible.
Data Freshness: One of the core strengths of vector databases is ensuring that your data remains up-to-date. In use cases like recommendation systems, keeping data current is essential for generating accurate insights.
Persistence: Unlike in-memory data structures, vector databases offer persistent storage, meaning your data is securely stored and accessible even after system reboots.
Availability: Vector databases keep data readily accessible for real-time querying and retrieval. This ensures that even as your data grows, you can still perform fast and efficient searches, enabling AI-driven decisions without delay.
Scalability: As data grows in volume, vector databases scale efficiently to accommodate that growth without performance degradation. This is essential when managing billions of unstructured data points.
Complete Data Management
Beyond the above functions, vector databases provide robust tools for managing your unstructured data including data ingestion, indexing, and querying, allowing for efficient retrieval and analysis of even the largest datasets. Features such as backup and migration ensure that your data remains secure and recoverable, making vector databases a reliable choice for managing critical information.
Operational Ease
Vector databases are also designed to simplify deployment and management:
Cloud or On-Premise Deployment: Many purpose-built vector databases are versatile and can be easily deployed on public clouds or on-premise infrastructure, ensuring flexibility based on the organization’s needs.
Observability: Many vector databases offer monitoring tools to track database health and performance, allowing users to optimize their systems proactively.
Multi-tenancy: Vector databases like Zilliz Cloud support multiple users or applications, ensuring secure access and isolated data handling for each tenant. This makes them ideal for large-scale deployments where multiple teams need isolated data environments.
The Role of Milvus in Managing Unstructured Data
Milvus is an open-source vector database designed to efficiently store, index, and retrieve high-dimensional vectors at a billion-scale, making it ideal for use cases involving AI and machine learning, such as recommendation systems, image recognition, or retrieval-augmented generation (RAG).
Milvus offers multiple deployment options to meet diversified customer needs.
Open-source Milvus: Open-source, self-managed, and can be hosted on any machine with community support. Milvus also offers multiple deployment options for various needs and environments, including Milvus Lite, Milvus Standalone, and Milvus Distributed. See Milvus documentation for more details.
Zilliz Cloud: fully managed version of Milvus, re-engineered for the cloud, and available on leading public clouds such as AWS, GCP, and Azure.
Zilliz BYOC: enterprise-ready Milvus for Private VPCs and can be deployed in your virtual private cloud.
 Fig 1- Ways of deploying Milvus .png
Fig 1- Ways of deploying Milvus .png
Fig 1: Ways of deploying Milvus
Key Features of Milvus
Milvus is designed for high performance and scalability, offering features like:
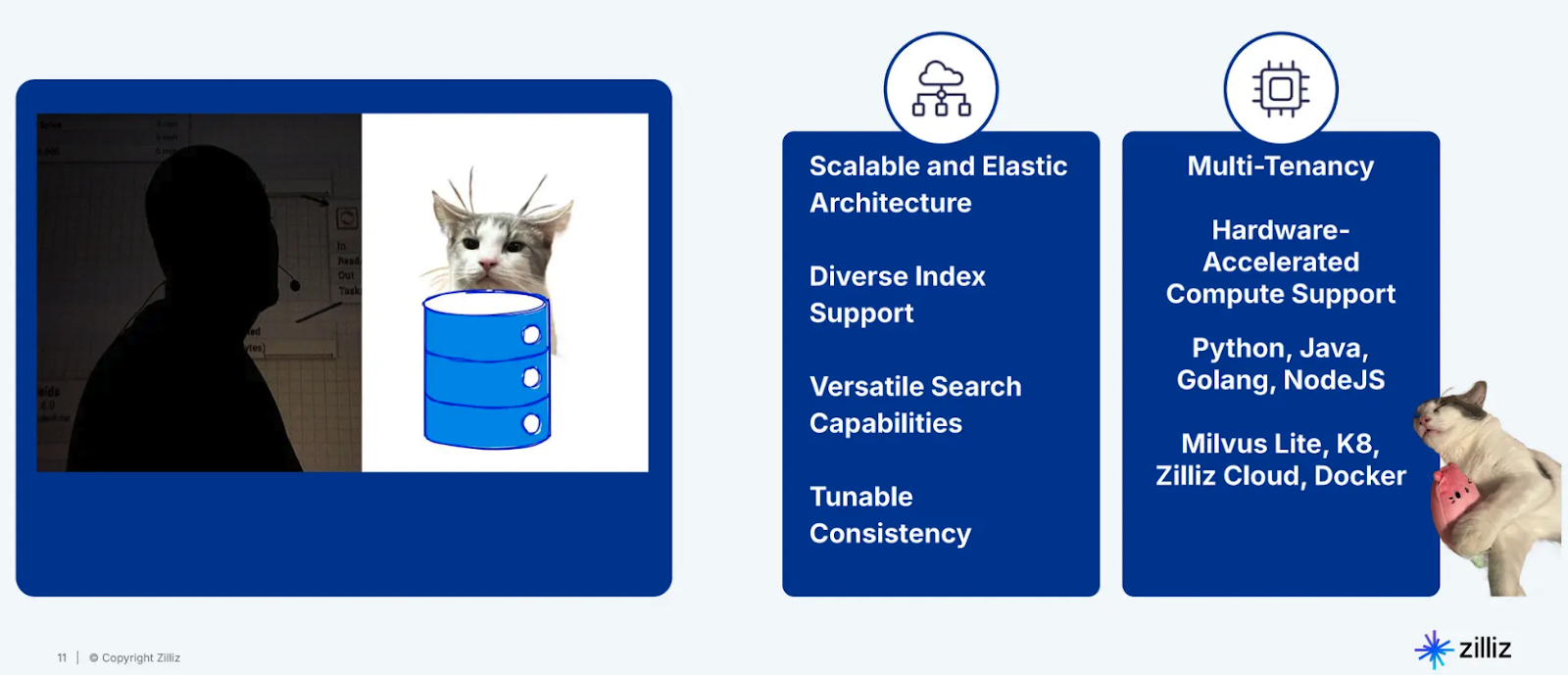 Figure- Milvus key features .png
Figure- Milvus key features .png
Figure: Milvus key features
Multi-tenancy: Milvus allows multiple users or applications to work on the same system without interfering with each other, providing secure access for isolated data.
Hardware-accelerated Compute: Optimized to leverage hardware like GPUs, making it faster and more efficient for resource-intensive tasks such as AI model inference.
Language and API Support: Milvus is highly versatile, supporting Python, Java, Golang, NodeJS, etc making it accessible to a wide range of developers.
Scalable and Elastic Architecture: Milvus is designed to handle growing data needs. It automatically scales to meet the demand, ensuring performance remains optimal as data grows.
Diverse Index Support: It supports multiple types of indexes, including HNSW, PQ, Binary, and DiskANN, allowing flexibility in how data is stored and searched.
Tunable Consistency: Milvus allows you to adjust the consistency levels for your data, enabling you to balance between performance and data accuracy based on the application's needs.
For more detailed information, refer to the Milvus documentation.
Technologies Powering Milvus for Various Use Cases
Milvus is powered by a suite of technologies that cater to different types of applications, ensuring performance, flexibility, and scalability across various environments:
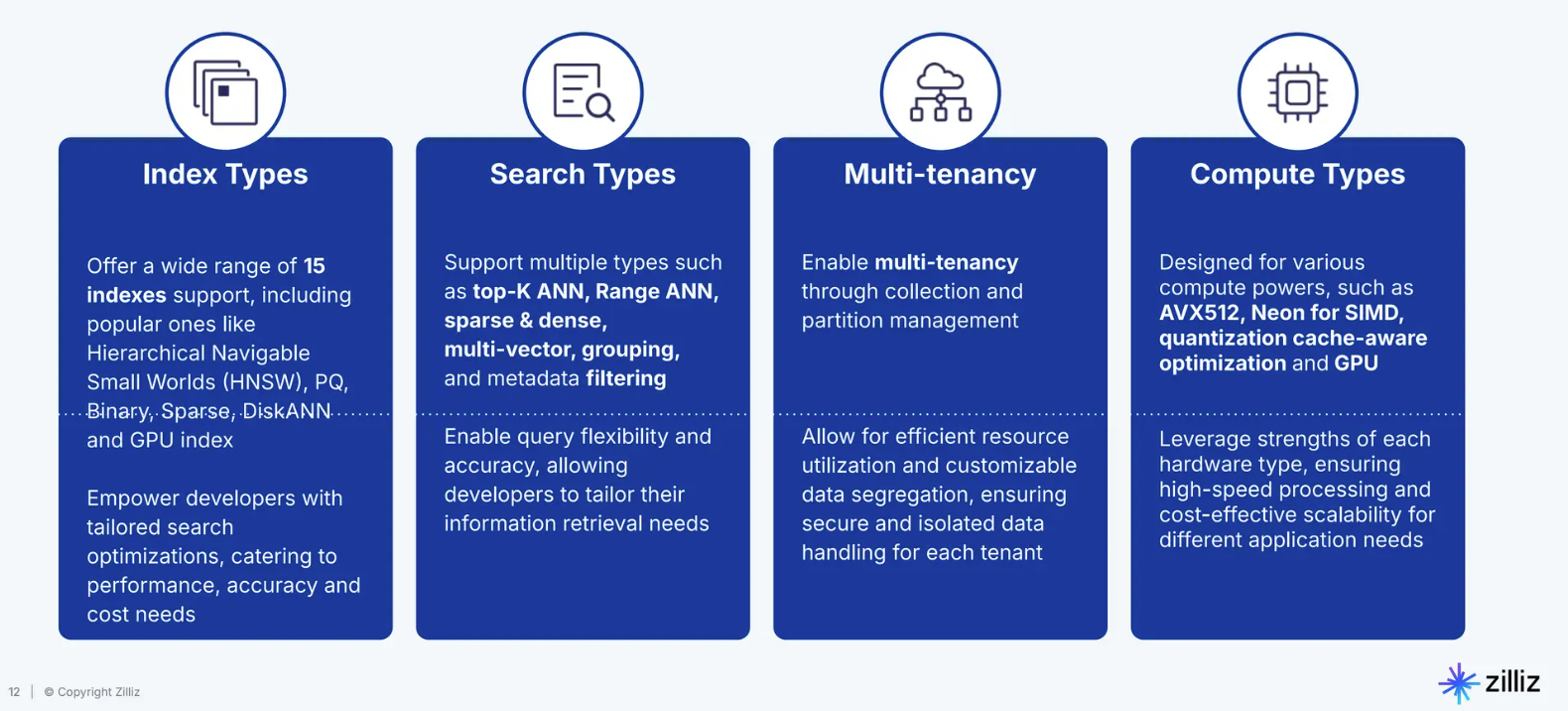 Figure- Milvus technologies for various use cases .png
Figure- Milvus technologies for various use cases .png
Figure: Milvus technologies for various use cases
Compute Types: Milvus is optimized for different hardware environments, including AVX512 (a set of CPU instructions for high-speed computing), Neon for SIMD (Single Instruction, Multiple Data), and GPU acceleration. This ensures Milvus can use high-performance hardware to deliver fast processing and cost-effective scalability.
Search Types: Milvus supports a wide array of search methods, such as top-K ANN (Approximate Nearest Neighbors) for finding the most similar data points, range ANN, sparse & dense searches, and filtered searches. These allow us to tailor the search functionality to the specific needs of our applications, whether that’s identifying similar images, videos, or text.
Multi-tenancy: Milvus supports collection and partition management, enabling multi-tenancy. This feature allows different teams or applications to share the same database without interfering with each other's data, ensuring secure and isolated data handling.
Index Types: Milvus provides a broad range of 15 indexing types, including HNSW (Hierarchical Navigable Small Worlds) for high-speed searches, PQ (Product Quantization) for compact storage, and DiskANN for handling massive datasets. You can choose the indexing type that best balances performance, accuracy, and cost, depending on your use case.
These technologies make Milvus a good choice for a wide range of applications, from large-scale cloud deployments to resource-constrained edge devices.
The Shift to Edge Computing
As the demand for real-time insights from unstructured data grows, many organizations find that relying solely on cloud environments isn't enough. This has led to a shift toward edge computing, where the processing happens closer to where the data is generated, offering distinct advantages for time-sensitive AI applications.
Edge computing refers to the practice of processing data closer to where it is generated, often on edge devices like sensors, cameras, and IoT devices. Instead of sending raw data back to centralized data centers for processing, edge computing allows computations on the devices themselves or in nearby locations.
With the increasing availability of powerful edge devices, it has become possible to deploy machine learning and AI models directly on these devices. This approach enables real-time decision-making in applications such as autonomous vehicles, smart cities, and industrial automation.
Why Process Data at the Edge?
Processing unstructured data at the edge has several advantages:
Low Latency: Since data is processed near its source, there’s minimal delay in obtaining results.
Reduced Bandwidth: By processing data locally, you reduce the need to transmit large volumes of raw data back to the cloud.
Privacy and Security: Sensitive data can remain on the edge device, minimizing the risk of exposure during transmission.
Edge AI and Vector Databases
While edge computing brings data processing closer to the source on devices such as sensors, cameras, and small devices like the Raspberry Pi, it's the vector database that truly empowers these devices to handle the growing flood of unstructured data in real-time.
For example, in an industrial setting, edge devices monitor machinery performance and detect potential issues using sensor data. A vector database like Milvus empowers the edge device to rapidly compare incoming data against historical patterns, identifying anomalies that indicate maintenance needs. Without the vector database, the edge device would either need to send all raw data to a cloud server for processing (introducing delays and higher costs) or risk missing critical insights.
Milvus Lite: Empowering Edge Devices with AI Capabilities
Milvus Lite is the lightweight version of Milvus, designed specifically for resource-constrained environments like edge devices. It provides all the essential capabilities of a vector database but is optimized for deployment on smaller, less powerful hardware. This makes it an ideal solution for empowering edge devices to handle complex AI tasks, even in environments with limited resources.
With Milvus Lite running on an edge device, the device is transformed into an AI-powered data processor. This combination allows the edge device to perform localized image recognition, video similarity searches, or even natural language processing. In a retail setting, for example, a smart checkout system powered by Milvus Lite could instantly recognize products and match them against a stored vector database of items, speeding up transactions without the need for cloud-based systems.
Let’s see a practical example in which Milvus powers an edge device running on a Raspberry Pi.
Building a Real-time Pose Estimation System with Raspberry Pi and Milvus
Raspberry Pi is a series of small, affordable, single-board computers developed by the Raspberry Pi Foundation. In this example, we will use Raspberry Pi as an edge device and Milvus Lite for handling unstructured data.
This pose estimation system will capture video streams, process them to estimate human poses, and store the extracted feature vectors in Milvus for efficient similarity retrieval. Additionally, we’ll integrate Slack for notifications, alerting us when specific poses are detected.
You can check the source code of this example in Tim’s notebook on GitHub.
Prerequisites
Raspberry Pi (with GStreamer and Python installed)
Slack account for notifications
Importing the Necessary Libraries and Initial Setup
Start by importing the necessary libraries and setting up some initial configurations:
import gi
gi.require_version('Gst', '1.0')
from gi.repository import Gst, GLib
import os
import argparse
import multiprocessing
import numpy as np
import setproctitle
import cv2
import time
from datetime import datetime
import uuid
import glob
import torch
from torchvision import transforms
from PIL import Image
import timm
from sklearn.preprocessing import normalize
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
from pymilvus import connections
from pymilvus import utility
from pymilvus import FieldSchema, CollectionSchema, DataType, Collection
from pymilvus import MilvusClient
from pymilvus import MilvusClient
import hailo
from hailo_rpi_common import (
get_default_parser,
QUEUE,
get_caps_from_pad,
get_numpy_from_buffer,
GStreamerApp,
app_callback_class,
)
DIMENSION = 512
MILVUS_URL = "https://in05-7bd87b945683c8d.serverless.gcp-us-west1.cloud.zilliz.com"
COLLECTION_NAME = "rpipose"
TOKEN = os.environ["ZILLIZ_TOKEN"]
PATH = "/opt/demo/images"
time_list = [ 0, 5, 10, 20, 30, 40, 50, 59 ]
The above code imports various libraries for video processing (GStreamer), image processing (OpenCV), deep learning (PyTorch, timm), database operations (pymilvus), and communication (Slack SDK). It also imports the Hailo library for working with the AI accelerator, designed to enable deep learning applications on edge devices. We set up global variables for the Milvus database configuration and define a list of times for periodic actions. MILVUSURL AND TOKEN will authenticate us with the Zilliz cloud.
Milvus Database Setup
Next, we set up our connection to the Milvus vector database. We will use Milvus to store the extracted features from the pose estimation model.
# Connect to Milvus
# Milvus Lite
# milvus_client = MilvusClient(uri="pipose.db")
# Cloud Server
milvus_client = MilvusClient( uri=MILVUS_URL, token=TOKEN )
# Create Milvus collection which includes the id, filepath of the image, and image embedding
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name='label', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='lefteye', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='righteye', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='confidence', dtype=DataType.FLOAT),
FieldSchema(name='vector', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
milvus_client.create_collection(COLLECTION_NAME, DIMENSION, schema=schema, metric_type="COSINE", auto_id=True)
index_params = milvus_client.prepare_index_params()
index_params.add_index(field_name = "vector", metric_type="COSINE")
milvus_client.create_index(COLLECTION_NAME, index_params)
Here, we're setting up our Milvus database. We create a client connection, define the schema for our collection (including fields for ID, label, eye positions, confidence, and the feature vector), create the collection, and set up an index for efficient similarity searches.
Slack Setup for Notifications
Next, set up a connection to Slack for sending notifications:
slack_token = os.environ["SLACK_BOT_TOKEN"]
client = WebClient(token=slack_token)
This setup will allow us to send messages and files to Slack using a bot token stored as an environment variable.
Implementing the Feature Extractor
Our pose estimation system requires a feature extractor to convert the detected poses into a format suitable for storage in Milvus. Let’s define a class for this.
class FeatureExtractor:
def __init__(self, modelname):
# Load the pre-trained model
self.model = timm.create_model(
modelname, pretrained=True, num_classes=0, global_pool="avg"
)
self.model.eval()
# Get the input size required by the model
self.input_size = self.model.default_cfg["input_size"]
config = resolve_data_config({}, model=modelname)
# Get the preprocessing function provided by TIMM for the model
self.preprocess = create_transform(**config)
def __call__(self, imagepath):
# Preprocess the input image
input_image = Image.open(imagepath).convert("RGB") # Convert to RGB if needed
input_image = self.preprocess(input_image)
# Convert the image to a PyTorch tensor and add a batch dimension
input_tensor = input_image.unsqueeze(0)
# Perform inference
with torch.no_grad():
output = self.model(input_tensor)
# Extract the feature vector
feature_vector = output.squeeze().numpy()
return normalize(feature_vector.reshape(1, -1), norm="l2").flatten()
extractor = FeatureExtractor("resnet34")
This FeatureExtractor class will turn our images into feature vectors. We're using a pre-trained ResNet34 model for this task. The __call__ method opens an image, preprocesses it, runs it through the model, and returns a normalized feature vector.
Defining a User Callback Class
Continue and define a simple user callback class.
class user_app_callback_class(app_callback_class):
def __init__(self):
super().__init__()
This class inherits from app_callback_class and doesn't add any new functionality. It's a placeholder that allows for future customization of the callback behavior.
Creating an Application Callback Function
The app_callback function does most of the processing. This function processes video frames, estimates poses, and stores the results in Milvus.
def app_callback(pad, info, user_data):
# Get the GstBuffer from the probe info
lefteye = ""
righteye = ""
buffer = info.get_buffer()
# Check if the buffer is valid
if buffer is None:
return Gst.PadProbeReturn.OK
# Using the user_data to count the number of frames
user_data.increment()
string_to_print = f"Frame count: {user_data.get_count()}\n"
# Get the caps from the pad
format, width, height = get_caps_from_pad(pad)
# If the user_data.use_frame is set to True, we can get the video frame from the buffer
frame = None
if user_data.use_frame and format is not None and width is not None and height is not None:
# Get video frame
frame = get_numpy_from_buffer(buffer, format, width, height)
# Get the detections from the buffer
roi = hailo.get_roi_from_buffer(buffer)
detections = roi.get_objects_typed(hailo.HAILO_DETECTION)
# Parse the detections
for detection in detections:
label = detection.get_label()
bbox = detection.get_bbox()
confidence = detection.get_confidence()
if label == "person":
string_to_print += (f"Detection: {label} {confidence:.2f}\n")
# Pose estimation landmarks from detection (if available)
landmarks = detection.get_objects_typed(hailo.HAILO_LANDMARKS)
if len(landmarks) != 0:
points = landmarks[0].get_points()
left_eye = points[1] # assuming 1 is the index for the left eye
right_eye = points[2] # assuming 2 is the index for the right eye
# The landmarks are normalized to the bounding box, we also need to convert them to the frame size
left_eye_x = int((left_eye.x() * bbox.width() + bbox.xmin()) * width)
left_eye_y = int((left_eye.y() * bbox.height() + bbox.ymin()) * height)
right_eye_x = int((right_eye.x() * bbox.width() + bbox.xmin()) * width)
right_eye_y = int((right_eye.y() * bbox.height() + bbox.ymin()) * height)
string_to_print += (f" Left eye: x: {left_eye_x:.2f} y: {left_eye_y:.2f} Right eye: x: {right_eye_x:.2f} y: {right_eye_y:.2f}\n")
if user_data.use_frame:
# Add markers to the frame to show eye landmarks
cv2.circle(frame, (left_eye_x, left_eye_y), 5, (0, 255, 0), -1)
cv2.circle(frame, (right_eye_x, right_eye_y), 5, (0, 255, 0), -1)
if user_data.use_frame:
# Convert the frame to BGR
framesave = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
user_data.set_frame(framesave)
time_now = datetime.now()
current_time = int(time_now.strftime("%S"))
if current_time in time_list and len(label) > 4:
# Save Image
strfilename = PATH + "/personpose.jpg"
cv2.imwrite(strfilename, framesave)
lefteye = (f"x: {left_eye_x:.2f} y: {left_eye_y:.2f}")
righteye = (f"x: {right_eye_x:.2f} y: {right_eye_y:.2f}")
# Slack
try:
response = client.chat_postMessage(
channel="C06NE1FU6SE",
text=(f"Detection: {label} {confidence:.2f}")
)
except SlackApiError as e:
# You will get a SlackApiError if "ok" is False
assert e.response["error"]
try:
response = client.chat_postMessage(
channel="C06NE1FU6SE",
text=(f" Left eye: x: {left_eye_x:.2f} y: {left_eye_y:.2f} Right eye: x: {right_eye_x:.2f} y: {right_eye_y:.2f}\n")
)
except SlackApiError as e:
# You will get a SlackApiError if "ok" is False
assert e.response["error"]
try:
response = client.files_upload_v2(
channel="C06NE1FU6SE",
file=strfilename,
title=label,
initial_comment="Live Camera image ",
)
except SlackApiError as e:
assert e.response["error"]
# Milvus insert
try:
imageembedding = extractor(strfilename)
milvus_client.insert( COLLECTION_NAME, {"vector": imageembedding, "lefteye": lefteye, "righteye": righteye, "label": label, "confidence": confidence})
except Exception as e:
print("An error:", e)
print(string_to_print)
return Gst.PadProbeReturn.OK
This callback function processes video frames to detect people, focusing on extracting details like the bounding box, confidence, and eye landmarks. It marks detected eye positions in the frame and saves the frame image if there is a person in the frame. Additionally, it sends notifications to Slack with detection details and the marked image. The function then extracts an embedding vector from the saved image. It updates Milvus with this data, including the embedding (vector), eye coordinates (lefteye and righteye), object label (label), and detection confidence (confidence).
Creating the Utility Function for COCO Keypoints
Create a utility function for getting COCO keypoints. These are specific points on the human body that are used for pose estimation.
def get_keypoints():
"""Get the COCO keypoints and their left/right flip correspondence map."""
keypoints = {
'nose': 1,
'left_eye': 2,
'right_eye': 3,
'left_ear': 4,
'right_ear': 5,
'left_shoulder': 6,
'right_shoulder': 7,
'left_elbow': 8,
'right_elbow': 9,
'left_wrist': 10,
'right_wrist': 11,
'left_hip': 12,
'right_hip': 13,
'left_knee': 14,
'right_knee': 15,
'left_ankle': 16,
'right_ankle': 17,
}
return keypoints
This function returns a dictionary mapping body parts to their corresponding keypoint indices in the COCO dataset format.
Creating the GStreamer Pipeline
Go on and create the main application class that will set up a GStreamer pipeline. This is a sequence of elements that process multimedia data in a specific order. It will process live video streams.
# This class inherits from the hailo_rpi_common.GStreamerApp class
class GStreamerPoseEstimationApp(GStreamerApp):
def __init__(self, args, user_data):
# Call the parent class constructor
super().__init__(args, user_data)
# Additional initialization code can be added here
# Set Hailo parameters these parameters should be set based on the model used
self.batch_size = 2
self.network_width = 640
self.network_height = 640
self.network_format = "RGB"
self.default_postprocess_so = os.path.join(self.postprocess_dir, 'libyolov8pose_post.so')
self.post_function_name = "filter"
self.hef_path = os.path.join(self.current_path, '../resources/yolov8s_pose_h8l_pi.hef')
self.app_callback = app_callback
# Set the process title
setproctitle.setproctitle("Hailo Pose Estimation with Milvus")
self.create_pipeline()
def get_pipeline_string(self):
if (self.source_type == "rpi"):
source_element = f"libcamerasrc name=src_0 auto-focus-mode=2 ! "
source_element += f"video/x-raw, format={self.network_format}, width=1536, height=864 ! "
source_element += QUEUE("queue_src_scale")
source_element += f"videoscale ! "
source_element += f"video/x-raw, format={self.network_format}, width={self.network_width}, height={self.network_height}, framerate=30/1 ! "
elif (self.source_type == "usb"):
source_element = f"v4l2src device={self.video_source} name=src_0 ! "
source_element += f"video/x-raw, width=640, height=480, framerate=30/1 ! "
else:
source_element = f"filesrc location={self.video_source} name=src_0 ! "
source_element += QUEUE("queue_dec264")
source_element += f" qtdemux ! h264parse ! avdec_h264 max-threads=2 ! "
source_element += f" video/x-raw,format=I420 ! "
source_element += QUEUE("queue_scale")
source_element += f"videoscale n-threads=2 ! "
source_element += QUEUE("queue_src_convert")
source_element += f"videoconvert n-threads=3 name=src_convert qos=false ! "
source_element += f"video/x-raw, format={self.network_format}, width={self.network_width}, height={self.network_height}, pixel-aspect-ratio=1/1 ! "
pipeline_string = "hailomuxer name=hmux "
pipeline_string += source_element
pipeline_string += "tee name=t ! "
pipeline_string += QUEUE("bypass_queue", max_size_buffers=20) + "hmux.sink_0 "
pipeline_string += "t. ! " + QUEUE("queue_hailonet")
pipeline_string += "videoconvert n-threads=3 ! "
pipeline_string += f"hailonet hef-path={self.hef_path} batch-size={self.batch_size} force-writable=true ! "
pipeline_string += QUEUE("queue_hailofilter")
pipeline_string += f"hailofilter function-name={self.post_function_name} so-path={self.default_postprocess_so} qos=false ! "
pipeline_string += QUEUE("queue_hmuc") + " hmux.sink_1 "
pipeline_string += "hmux. ! " + QUEUE("queue_hailo_python")
pipeline_string += QUEUE("queue_user_callback")
pipeline_string += f"identity name=identity_callback ! "
pipeline_string += QUEUE("queue_hailooverlay")
pipeline_string += f"hailooverlay ! "
pipeline_string += QUEUE("queue_videoconvert")
pipeline_string += f"videoconvert n-threads=3 qos=false ! "
pipeline_string += QUEUE("queue_hailo_display")
pipeline_string += f"fpsdisplaysink video-sink={self.video_sink} name=hailo_display sync={self.sync} text-overlay={self.options_menu.show_fps} signal-fps-measurements=true "
print(pipeline_string)
return pipeline_string
This class sets up our GStreamer pipeline. It runs a pose estimation model on a Raspberry Pi using a Hailo AI accelerator, which is an edge AI processor designed to run deep learning and AI inference tasks on edge devices. It initializes parameters like batch size, input dimensions, color format, and file paths for the neural network model and post-processing. Depending on the input source (e.g., Raspberry Pi camera, USB camera, or video file), it builds a GStreamer pipeline to capture video, process it through the Hailo model, apply post-processing, and display the output. The pipeline configuration is specified in the get_pipeline_string method, which assembles the GStreamer elements required for this task.
Executing the Program
The final step is executing the program.
if __name__ == "__main__":
# Create an instance of the user app callback class
user_data = user_app_callback_class()
parser = get_default_parser()
args = parser.parse_args()
app = GStreamerPoseEstimationApp(args, user_data)
app.run()
This is where we connect everything. We create an instance of our user_app_callback_class, parse any command-line arguments, create our GStreamerPoseEstimationApp, and run it.
Here is a sample result of what to expect when you run the program.
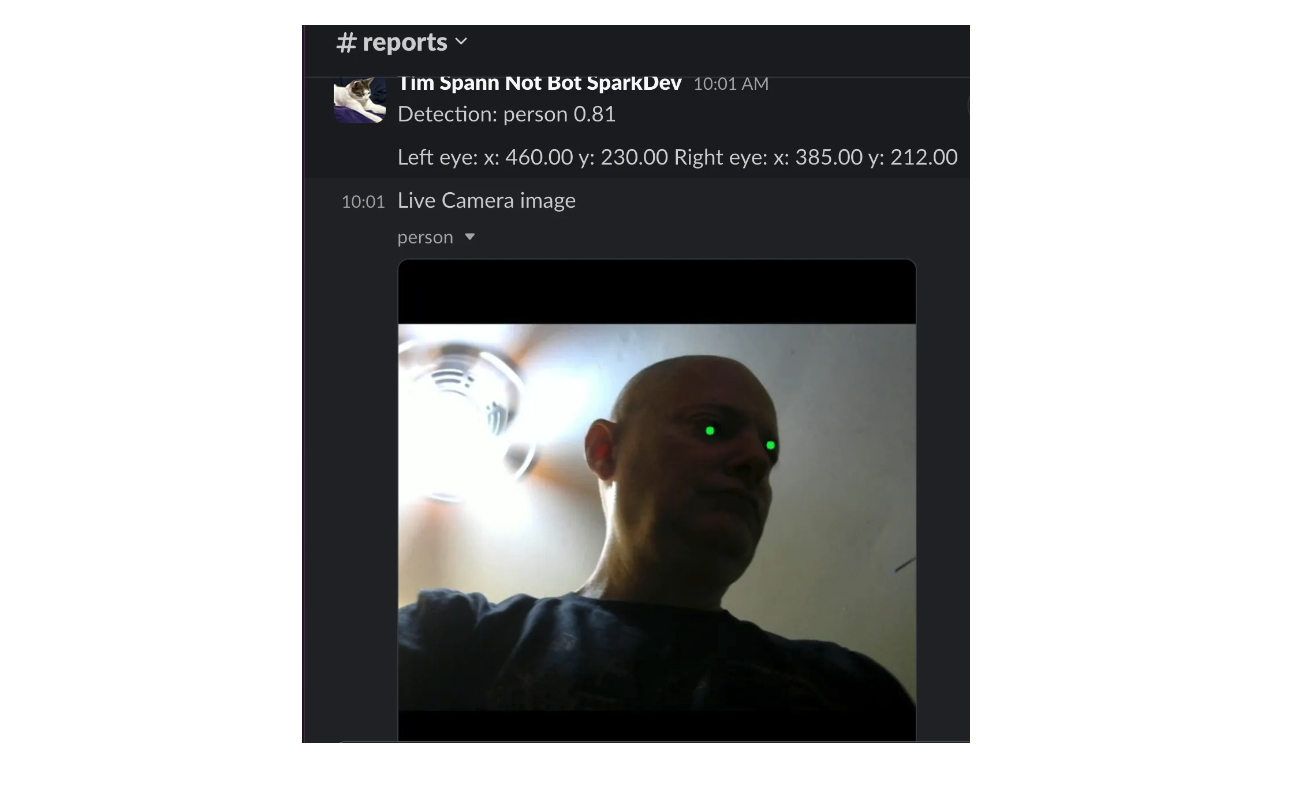 Fig 2- Output of a pose estimation program in Slack with eye landmarks marked with green dots.png
Fig 2- Output of a pose estimation program in Slack with eye landmarks marked with green dots.png
Fig 2: Output of a pose estimation program in Slack with eye landmarks marked with green dots
This is the update to Slack when a person is detected. It has a confidence score of 81%, the coordinates of the left and right eyes, and the image with marked eye landmarks (green circles on the left and right eye positions).
Use Cases of Combining AI and Vector Databases
Combining edge AI and Vector databases brings about numerous use cases. Below are some examples.
Robotics
Edge AI and vector databases enhance the capabilities of autonomous robots, allowing them to process sensor data locally and make instant decisions. This technology significantly improves efficiency and adaptability in dynamic environments.
Example: In warehouse automation, autonomous mobile robots (AMRs) use onboard cameras and local vector databases for real-time object recognition. As they navigate the warehouse, these robots instantly identify and categorize products by comparing visual data to locally stored vectors. This enables them to adapt to changing warehouse conditions and optimize their routes without relying on cloud infrastructure.
Smart Cities
Edge AI and vector databases play a crucial role in optimizing urban operations, from traffic management to public safety. These technologies enable rapid data processing and decision-making at the edge, improving city efficiency and resident quality of life.
Example: Intelligent traffic management systems leverage edge AI to process video feeds from intersection cameras locally. The system converts traffic patterns into vector representations and compares them to historical data stored in a local vector database. This allows for real-time traffic light adjustments to reduce congestion, ensuring rapid response times without the need for constant data transmission to central servers.
Industrial Automation
Edge AI and vector databases drive predictive maintenance and equipment monitoring in manufacturing and industrial settings. This approach allows for real-time analysis of machine health, preventing downtime and optimizing production processes.
Example: Smart manufacturing plants deploy sensors on critical machinery to continuously collect vibration data. Edge devices convert this data into vector representations and compare them to known "healthy" and "faulty" vibration patterns stored in a local vector database. This real-time analysis enables immediate detection of potential equipment failures, facilitating proactive maintenance and minimizing costly disruptions.
Healthcare
Edge AI and vector databases transform patient care by enabling continuous health monitoring without compromising privacy. These technologies allow for sophisticated analysis of health data directly on wearable devices or local systems.
Example: Wearable ECG monitors utilize edge AI to process heart rhythm data locally. The device converts ECG patterns into vectors and compares them to a database of normal and abnormal rhythms stored onboard. This approach enables immediate detection of potential cardiac issues while keeping sensitive health data on the device, enhancing both responsiveness and patient privacy.
Conclusion
As unstructured data grows in scale and importance, efficient processing solutions become increasingly crucial. Tim did a good job at highlighting the transformative potential of vector databases like Milvus, offering advanced capabilities for both cloud and edge deployments. Whether for large-scale AI applications or resource-constrained edge devices, Milvus and its lightweight counterpart, Milvus Lite, enable organizations to harness unstructured data for real-time decision-making, innovation, and operational efficiency. With the flexibility to scale from cloud to edge, these technologies are at the forefront of modern AI-driven solutions.
Further Resources
Tim’s AI projects on GitHub:
Keep Reading

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.