




A Beginner's Guide to Website Chunking and Embedding for Your RAG Applications
This post explains how to extract content from a website and use it as context for LLMs in a RAG application. However, before doing so, we need to understand website fundamentals.
Read the entire series
- Exploring BGE-M3 and Splade: Two Machine Learning Models for Generating Sparse Embeddings
- Comparing SPLADE Sparse Vectors with BM25
- Exploring ColBERT: A Token-Level Embedding and Ranking Model for Efficient Similarity Search
- Vectorizing and Querying EPUB Content with the Unstructured and Milvus
- What Are Binary Embeddings?
- A Beginner's Guide to Website Chunking and Embedding for Your RAG Applications
- An Introduction to Vector Embeddings: What They Are and How to Use Them
- Image Embeddings for Enhanced Image Search: An In-depth Explainer
- A Beginner’s Guide to Using OpenAI Text Embedding Models
- DistilBERT: A Distilled Version of BERT
- Unlocking the Power of Vector Quantization: Techniques for Efficient Data Compression and Retrieval
Introduction
Advancements in Large Language Models (LLMs) have opened a wide range of sophisticated natural language applications, from text generation to personalized chatbots that provide highly contextualized answers.
However, one limitation of popular LLMs like ChatGPT, LLAMA, and Mistral is that their knowledge is limited to the data they've been trained on. For example, ChatGPT has been trained on data up to April 2023, and therefore, it may not provide accurate answers for information newer than its training data.
One way to alleviate this problem is through the Retrieval Augmented Generation (RAG). In a nutshell, with RAG, we provide additional contextual information alongside the query to LLMs in real time, enabling them to provide highly relevant answers. Among other sources such as books or internal documents, information from websites is a popular choice to add context to LLMs.
 How RAG works to alleviate LLM hallucinations.png
How RAG works to alleviate LLM hallucinations.png
How RAG works to alleviate LLM hallucinations
In this post, we'll explain how to extract content from a website and use it as context for LLMs in a RAG application. However, before doing so, we need to understand website fundamentals.
The Fundamentals of Web Architecture
When exploring various websites on the internet, you will encounter a diverse range of layouts, fonts, and information structures. This diversity stems from the fact that websites are typically constructed based on specific architectures. Web architectures dictate how websites are organized, engage with users, and integrate with other systems.
Websites consist of three main components: HTML, CSS, and JavaScript.
HTML (Hypertext Markup Language) defines the structure and content of web pages, laying the groundwork for the website's layout and organization.
CSS (Cascading Style Sheets) controls web pages' visual styling and layout, enhancing the user experience with colors, fonts, and other visual elements.
JavaScript adds interactivity to web pages, enabling users to engage with the website and perform tasks like form submissions and data manipulation.
To create a user-friendly website and extract its content, we also need to understand the concept of a Document Object Model (DOM).
DOM represents the HTML elements as a tree-like data structure generated by the browser when parsing a web page's HTML code. It dynamically reflects the web page and updates in real time as users interact with it.
DOM is composed of several key components:
Elements are the building blocks of the DOM, representing individual HTML elements such as headings, paragraphs, and images.
Attributes add information to elements, such as an image's src attribute or an element's id attribute.
Texts refer to the textual content within an HTML element. These text nodes do not have attributes or child nodes and are considered leaf nodes in the DOM tree.

Understanding these elements is crucial for effective web scraping, enabling the extraction of website content, as we’ll see in the upcoming section.
The Fundamentals of Web Scraping and Its Challenges
For our RAG applications, we can use various websites as sources of information, including Wikipedia, Common Crawl, Google BigQuery Public Datasets, and the Wayback Machine. Web scraping, in essence, involves extracting content from these websites.
One of the most straightforward methods for scraping websites is utilizing their APIs. If a website provides an API, developers can leverage it to extract content in a convenient format. However, not all websites offer APIs, and even when they do, the data may not be available in the desired format. This is where web scraping tools come into play.
Numerous web scraping tools are available online, but for RAG applications, using open-source Python web-scraping libraries like BeautifulSoup, Selenium, and Scrapy is a good choice due to their ease of integration with other frameworks or libraries later on.
However, web scraping can be challenging to conduct due to several reasons:
Variety: Each website has a different and unique HTML structure. Therefore, we generally need a unique scraper script for each website to get the specific content we want.
Stability: Even when we’ve built a scraper to get the content we want from a specific website, that website can and will change at some point. Therefore, we must constantly adjust our scraper script to continue using it without errors.
Web Content Extraction: From Web-Scraping to Vector Embedding
This post will provide a step-by-step guide on scraping a website and preprocessing the content for a RAG application. This process involves web scraping, chunking, and generating embeddings for each chunk. Let's begin with web scraping.
Extracting Web Content through Web Scraping
As previously mentioned, web scraping involves extracting content or information from websites. There are various methods to scrape a website, and in this post, we will utilize the combination of the BeautifulSoup and requests libraries for web scraping.
requests: A Python library to make HTTP requests.BeautifulSoup: A Python library that enables web scraping and HTML parsing, allowing us to extract textual content from the web effectively.
For our RAG case, we will use Wikipedia articles as our primary source of information. The upcoming section will demonstrate how to utilize these libraries to retrieve textual information from a Wikipedia article.
Let's consider an example where we aim to extract textual information from a Wikipedia article on data science. We can achieve this by sending an HTTP request to the article's URL using the requests library.
import requests
from bs4 import BeautifulSoup
response = requests.get(
url="<https://en.wikipedia.org/wiki/Data_science>",
)
Next, we’re ready to scrape the content of this article. When examining the elements of any Wikipedia article, you will notice that each article on Wikipedia shares a similar Document Object Model (DOM) structure. However, since we’re looking to extract the textual information of the article, we can focus on a div element with an id attribute called bodyContent. This div contains all of the textual contents of any Wikipedia article, as you can see in the following figure:

We can easily extract the text inside of this div element by utilizing BeautifulSoup library as follows:
soup = BeautifulSoup(response.content, 'html.parser')
# Get textual content inside div with id = bodyContent
content = soup.find(id="bodyContent")
print(content.text)
"""
Output:
From Wikipedia, the free encyclopedia
Interdisciplinary field of study on deriving knowledge and insights from data
Not to be confused with information science.
The existence of Comet NEOWISE (here depicted as a series of red dots) was discovered by analyzing astronomical survey data acquired by a space telescope, the Wide-field Infrared Survey Explorer.
Data science is an interdisciplinary academic field[1] that uses statistics, scientific computing, scientific methods, processes, algorithms and systems to extract or extrapolate knowledge and insights from potentially noisy, structured, or unstructured data.[2]
Data science also integrates domain knowledge from the underlying application domain (e.g., natural sciences, information technology, and medicine).[3] Data science is multifaceted and can be described as a science, a research paradigm, a research method, a discipline, a workflow, and a profession.[4]
"""
And that's all we need to do! Once we have the textual content, we need to transform it into vector embeddings, numerical representations of the semantic meaning, context, and correlations within the text data.
However, before transforming this long text into vector embeddings, an intermediate step is necessary: chunking.
Web Chunking
Chunking is necessary when handling extensive text data like Wikipedia articles. Directly transforming the entire text into a single vector may not be the most effective approach for several reasons. Firstly, it results in a high-dimensional vector with potentially millions of dimensions, demanding substantial computational resources for storage and processing. Secondly, condensing an entire document into a single vector risks losing nuanced semantic information and context, compromising subsequent tasks' performance. Furthermore, this method may oversimplify the document's content, introducing ambiguity and overlooking critical details.
Instead, we should split the text into chunks, each consisting of granular and important information from a portion of the text. Several chunking methods are available, such as fixed-size length chunking and context-aware chunking.
In fixed-size length chunking, the length of each chunk needs to be defined in advance, and the chunking process will be performed according to the defined length. As a result, each chunk will have the same length.
On the other hand, content-aware chunking results in varying lengths between each chunk. This approach splits the text based on a specific delimiter set in advance. The delimiter can be anything, such as a period, comma, whitespace, colon, new line, etc.
In our example, we'll split an article using a recursive method based on a predefined chunk size. This means that the splitting process of a text will be done in a sequential order from paragraph, new line, whitespace, and character until the chunk size is equal to the predefined value. To split the text into chunks recursively, we can use RecursiveharacterTextSplitter from LangChain, as shown in the following code snippet:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 512,
length_function=len,
is_separator_regex=False,
)
chunk_text = text_splitter.split_text(content.text)
print(len(chunk_text))
print(chunk_text[3])
"""
Output:
67
Data science is "a concept to unify statistics, data analysis, informatics, and their related methods" to "understand and analyze actual phenomena" with data.[5] It uses techniques and theories drawn from many fields within the context of mathematics, statistics, computer science, information science, and domain knowledge.[6] However, data science is different from computer science and information science. Turing Award winner Jim Gray imagined data science as a "fourth paradigm" of science (empirical,
"""
As you can see above, if we split the textual content of the data science Wikipedia article based on a recursive method, we'll end up with 67 chunks.
Web Chunk to Vector Embedding
Now that we have transformed the text of the entire article into chunks, let's transform each chunk into a vector embedding. This approach allows us to extract the most relevant chunks as contexts for our LLM in a RAG application.
Two types of vector embeddings are commonly applied in real-world cases: dense and sparse embedding.
Dense embeddings are produced by deep learning models, such as the models from OpenAI or Sentence Transformers. This type of embedding represents text in a compact format, where most elements are non-zero, hence the name.
On the other hand, sparse embeddings are produced by a bag-of-words type of model, such as TF-IDF or BM25. This type of embedding has a higher dimensionality than dense embeddings, where most of its elements are zero, hence the name "sparse."
However, we can also utilize a more advanced sparse embedding model like SPLADE as an alternative to traditional sparse methods. SPLADE adds contextual information to each word in our chunk by integrating BERT into its architecture, producing an information-rich sparse vector compared to the traditional approach.
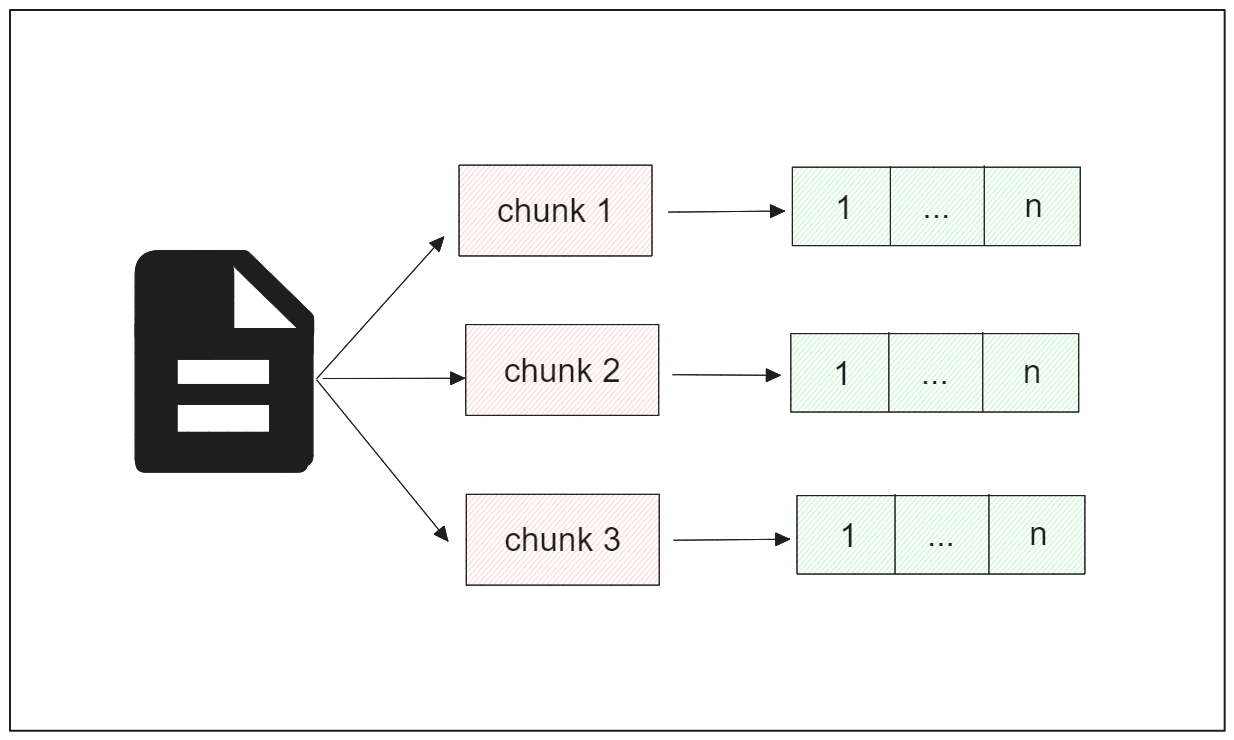
You can use any embedding model you like to transform chunks into embeddings; however, this article will use the all-MiniLM-L6-v2 model from Sentence Transformers. This model produces a dense embedding with a dimension of 384 to represent each chunk. We'll use this model to generate embeddings with the help of LangChain.
To instantiate the all-MiniLM-L6-v2 model and generate embeddings, we only need to call the SentenceTransformerEmbeddings class from LangChain and specify the model name we intend to use.
embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
Now, we can generate the vector embedding of each chunk with the embed_documents method.
chunk_embedding = embeddings.embed_documents([chunk_text[3]])
print(len(chunk_embedding[0]))
"""
Output:
384
"""
And that’s it. Now we have the vector embedding for each chunk. Next, we need to put all of the embeddings inside a vector database like Milvus to use them for RAG.
Vector Database and RAG Integration with Milvus
So far, we've seen an example of how to scrape an article from Wikipedia and preprocess it until it transforms into a ready-to-use embedding. Now, let's apply the same process to five Wikipedia articles that will serve as our data to demonstrate the RAG process later.
We'll fetch the URLs of 5 Wikipedia articles covering data science, machine learning, the Dune 2 film, the iPhone, and London. The code implementation is in this notebook.
The following code will scrape the content of these five articles and turn each of them into chunks:
# Load libraries
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores.milvus import Milvus
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.embeddings import SentenceTransformerEmbeddings
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
import requests
from bs4 import BeautifulSoup
wiki_articles = ["Data_science", "Machine_learning", "Dune:_Part_Two", "IPhone", "London"]
# Extract textual content of each wikipedia article
texts = ""
for article in wiki_articles:
response = requests.get(
url=f"<https://en.wikipedia.org/wiki/{article}>",
)
soup = BeautifulSoup(response.content, 'html.parser')
# Get all the texts
all_texts = soup.find(id="bodyContent")
texts += all_texts.text
# Split texts into chunks
chunk_text = text_splitter.split_text(texts)
Next, we'll transform each chunk into embeddings and store the embeddings in Milvus.
Milvus is an open-source vector database that simplifies storing vector embeddings and performing various tasks, such as vector search, semantic similarity, and question-answering.
We can store all of the embeddings in a Milvus database with the help of LangChain for easy RAG orchestration later.
vector_db = Milvus.from_texts(texts=chunk_text, embedding=embeddings, collection_name="rag_milvus")
And now that we’ve put all the embeddings inside a database called ‘rag_milvus', we are ready to perform RAG with it.
Next, we need to convert our database into a retriever, which means that our vector database will take the input query, convert it into an embedding using the embedding model of our choice, and then retrieve the most similar chunks in the database as a context for our LLM such that it can generate a relevant answer.
retriever = vector_db.as_retriever()
The next step is to define the LLM that will generate the response to our query. For this purpose, we'll use the ChatGPT 3.5 Turbo model, which we can call using the OpenAI wrapper from LangChain. To use this model, you'll need to provide your unique OpenAI API key, which you can obtain from your OpenAI account.
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
Next, we need to define the prompt for our LLMs. Prompting is one technique used to guide LLMs' responses according to the desired format. In a RAG application, you can experiment with your prompts to ensure the model generates responses in the desired format.
In this post, we'll provide an example of a basic prompt that you can use to guide the LLMs' responses.
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
custom_rag_prompt = PromptTemplate.from_template(template)
Finally, let's define the RAG pipeline using LangChain. In this step, we'll provide the necessary information for our RAG application, such as the source of the context (in our case, the Milvus vector database), the source of the query, the prompt for the LLM, and the LLM to be used (in our case, the ChatGPT 3.5 Turbo model).
By configuring these elements to generate responses based on the provided context and query, we can set up the complete RAG pipeline.
def format_docs(docs):
return "\\n\\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| custom_rag_prompt
| llm
| StrOutputParser()
)
And now we’re ready to perform RAG. Let’s say that now we have the following question: “What is a Data Scientist?”, we can get the LLM response based on the context provided by our vector database with the following code:
for chunk in rag_chain.stream("What is a Data Scientist?"):
print(chunk, end="", flush=True)
"""
Output:
A data scientist is a professional who combines programming code with statistical knowledge to create insights from data. They are responsible for collecting, cleaning, analyzing data, selecting analytical techniques, and deploying predictive models. Data scientists work at the intersection of mathematics, computer science, and domain expertise to solve complex problems and uncover hidden patterns.
Thanks for asking!
"""
And we've obtained an accurate response from our LLM! You may have noticed that the LLM's response also contains the sentence "Thank you for asking" at the end, corresponding to our prompt.
If you're curious about which parts of the chunks have been used as contexts for our LLM to generate the response, you can call the invoke method and provide the question as an argument.
contexts = retriever.invoke("What is a Data Scientist?")
print(contexts)
"""
Output
[Document(page_content='A data scientist is a professional who creates programming code and combines it with statistical knowledge to create insights from data.[9]', metadata={'pk': 450048016754672937}), Document(page_content='The professional title of "data scientist" has been attributed to DJ Patil and Jeff Hammerbacher in 2008.[32] Though it was used by the National Science Board in their 2005 report "Long-Lived Digital Data Collections: Enabling Research and Education in the 21st Century", it referred broadly to any key role in managing a digital data collection.[33]', metadata={'pk': 450048016754672955}), Document(page_content='While data analysis focuses on extracting insights from existing data, data science goes beyond that by incorporating the development and implementation of predictive models to make informed decisions. Data scientists are often responsible for collecting and cleaning data, selecting appropriate analytical techniques, and deploying models in real-world scenarios. They work at the intersection of mathematics, computer science, and domain expertise to solve complex problems and uncover hidden patterns in', metadata={'pk': 450048016754672963})]
"""
As you can see, the first chunk used by our LLM to generate the response is highly relevant to answering the question. This helps the LLM produce an accurate and contextualized response, even when querying information from internal documents.
In our prompt, we also instructed the LLM to provide an answer solely based on the provided context and not to make up any answer if the context provided doesn’t contain the answer to the question.
To evaluate this step, let's ask our LLM to "Summarize the plot of Inception", even though we only have information regarding the Dune 2 film. The response we'll receive should be like the following:
for chunk in rag_chain.stream("Summarize the plot of Inception"):
print(chunk, end="", flush=True)
"""
Output:
I'm sorry, I cannot provide information on the plot of Inception based on the context provided. Thanks for asking!
"""
contexts = retriever.invoke("Summarize the plot of Inception")
print(contexts)
"""
Output
[Document(page_content='Plot[edit]', metadata={'pk': 450048016754673364}), Document(page_content='Filmmaker Steven Spielberg praised the film, calling it "one of the most brilliant science fiction films I have ever seen," while further noting that "it\\'s also filled with deeply, deeply drawn characters ... Yet the dialogue is very sparse when you look at it proportionately to the running time of the film. It\\'s such cinema. The shots are so painterly, yet there\\'s not an angle or single setup that\\'s pretentious."[159][160]', metadata={'pk': 450048016754673473})]
"""
Our LLM's response is exactly what we want, as the contexts provided don't really answer the question.
Conclusion
In this post, we've learned the step-by-step guide to using website data as contexts for the responses of our LLMs in a RAG application.
First, we scraped a website's content using available web scraping tools and Python libraries like BeautifulSoup. Then, we split the extracted content into chunks to increase the granularity of the content and improve the quality of the response from our LLM. Next, we transformed each chunk into a vector embedding. Finally, we stored these embeddings in the Milvus vector database and used the database as a retriever for our RAG scenario.
As we pass our query, our vector database converts it into an embedding using the embedding model of our choice and then retrieves the most similar chunks in the database as context for our LLM, enabling it to generate a highly contextualized answer.
You can find all the code demonstrated in this post in this notebook.

- Introduction
- The Fundamentals of Web Architecture
- The Fundamentals of Web Scraping and Its Challenges
- Web Content Extraction: From Web-Scraping to Vector Embedding
- Vector Database and RAG Integration with Milvus
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Exploring BGE-M3 and Splade: Two Machine Learning Models for Generating Sparse Embeddings
In this blog, we’ve journeyed through the intricate world of vector embeddings and explored how BGE-M3 and Splade generate learned sparse embeddings.

Exploring ColBERT: A Token-Level Embedding and Ranking Model for Efficient Similarity Search
Unlike traditional embedding models like BERT, which focus on pooling embeddings into a single vector, ColBERT retains individual token representations. Through its innovative late interaction mechanism, it enables more precise and granular similarity calculations.

Unlocking the Power of Vector Quantization: Techniques for Efficient Data Compression and Retrieval
Vector Quantization (VQ) is a data compression technique representing a large set of similar data points with a smaller set of representative vectors, known as centroids.