




Vectorizing and Querying EPUB Content with the Unstructured and Milvus
In this post, we explore the vectorization and retrieval of EPUB data using Milvus and the Unstructured framework, offering developers actionable insights for enhancing LLM performance.
Read the entire series
- Exploring BGE-M3 and Splade: Two Machine Learning Models for Generating Sparse Embeddings
- Comparing SPLADE Sparse Vectors with BM25
- Exploring ColBERT: A Token-Level Embedding and Ranking Model for Efficient Similarity Search
- Vectorizing and Querying EPUB Content with the Unstructured and Milvus
- What Are Binary Embeddings?
- A Beginner's Guide to Website Chunking and Embedding for Your RAG Applications
- An Introduction to Vector Embeddings: What They Are and How to Use Them
- Image Embeddings for Enhanced Image Search: An In-depth Explainer
- A Beginner’s Guide to Using OpenAI Text Embedding Models
- DistilBERT: A Distilled Version of BERT
- Unlocking the Power of Vector Quantization: Techniques for Efficient Data Compression and Retrieval
Introduction
The digital world teems with eBooks, storing centuries of literature, research, and storytelling. From timeless classics like George Orwell's 1984 to modern bestsellers like J.K. Rowling's Harry Potter, these texts harbor vast linguistic and cultural insights, reflecting diverse societal norms and historical contexts. Large Language Models (LLMs) stand to gain immensely from such rich repositories, leveraging diverse datasets to comprehend human language with precision. By training in eBooks, LLMs acquire a nuanced understanding of writing styles, idioms, and character dialogues, enhancing their adaptability in summarization and sentiment analysis applications.
Despite their prowess, LLMs encounter challenges such as hallucinations and a lack of domain-specific knowledge due to their reliance on limited public data. To mitigate these issues, developers can employ the retrieval augmented generation (RAG) technique, supplementing LLMs with additional knowledge sources like legal documents to improve accuracy. Embedding and similarity retrieval form pivotal stages in the RAG process, facilitating efficient data transformation and retrieval.
In this post, we explore the vectorization and retrieval of EPUB data using Milvus and the Unstructured framework, offering developers actionable insights for enhancing LLM performance.
EPUB Vectorization with the Unstructured and Milvus
Milvus is a blazing-fast open-source vector database. It powers embedding similarity search and GenAI applications and strives to make vector databases accessible to every organization. Milvus can store, index, and manage a billion+ embedding vectors generated by deep neural networks and other machine learning (ML) models.
The Unstructured framework provides a structured pipeline for vectorizing EPUBs and other unstructured data formats like PDF and PowerPoint. It efficiently extracts and processes textual information, making it machine-readable for downstream AI applications. This framework specializes in transforming raw text into vectors that capture the semantic essence of the data.
How does the Unstructured and Milvus work to embed and query EPUB data? Here are the key steps:
Step 1: Data Extraction and Preprocessing: Unstructured employs natural language processing tools to extract and preprocess text from EPUB files. It involves reading raw files, cleaning the data, and structuring it for vectorization.
Step 2: Vectorization: The framework harnesses the power of deep learning models like BERT to convert text into numerical vectors representing the data's semantic meaning. These models transform the text into dense vectors, capturing even the most subtle nuances in meaning.
Step 3: Ingestion into Milvus: Once you vectorize the data, you can use Milvus to store and retrieve the vectors. Milvus enables high-speed similarity searches, which is ideal for large-scale applications.
Step 4: Indexing and Search: Milvus optimizes the search process through indexing, enabling quick and accurate retrieval of vectors that align with search queries. This step makes it easier to find related content across large datasets.
From EPUB to Insights: The Vectorization Journey
It is straightforward to vectorize EPUBs with the Unstructured framework and ingest them into your Milvus database instance. This section will outline the steps to move from raw EPUB data to a fully vectorized format using this open-source framework.
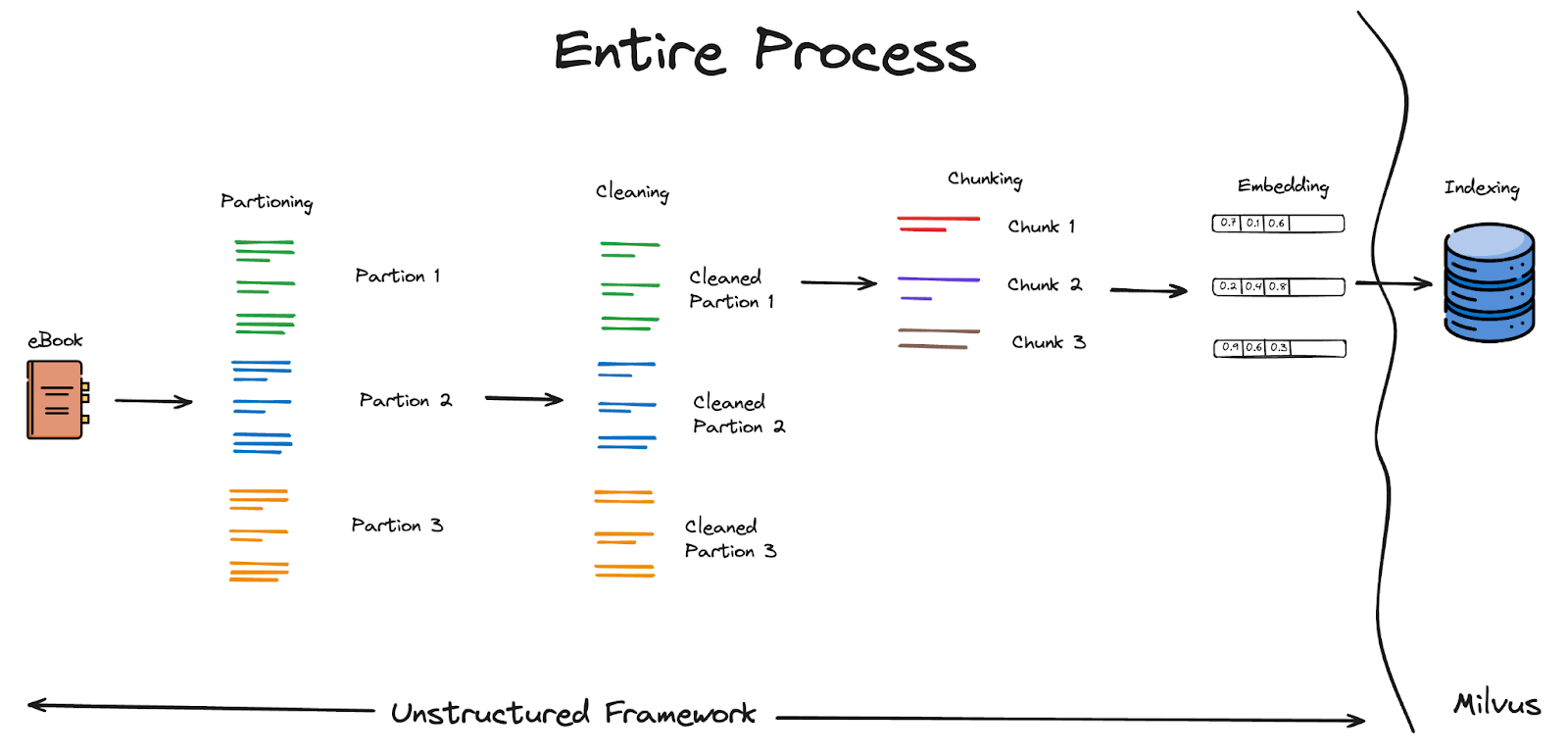 How the Unstructured Framework Vectorizes Ebooks
How the Unstructured Framework Vectorizes Ebooks
These steps include Data Partitioning, Cleaning, Chunking, and Embedding(Vectorizing). Lastly, we will index and search using the Milvus vector database.
1) Data Partitioning
First, we start by installing the required Libraries. The unstructured framework installation below works for plain text files. HTML, XML, JSON, and Emails that do not require any extra dependencies.
pip install unstructured
In the case of epub vectorization, which is our case, we need to specify the epub installation along with the library in the installation command:
pip install "unstructured[epub,]"
Some additional dependencies are required depending on the data type format. In the case of epub data vectorization, we also need the pandoc library.
make install-pandoc
After installing all dependencies, we can utilize the code lines below to partition our epub file. The partitioning function here breaks the raw document into standard, structured elements.
from unstructured.partition.auto import partition
elements = partition(filename="example-docs/eml/book.epub")
print("\n\n".join([str(el) for el in elements]))
2) Data Cleaning
The Unstructured library allows for other necessary features, such as cleaning our data. The cleaning process using the Unstructured library is pretty straightforward.
Utilizing the pre-defined cleaning function such as the replace_unique_quotes method that replaces the â\x80\x99 representation with its human-readable representation, the apostrophe (or ').
from unstructured.cleaners.core import replace_unicode_quotes
replace_unicode_quotes("Philadelphia Eaglesâ\x80\x99 victory")
The below apply function allows us to apply the text cleaning to the document element without instantiating a new element.
from unstructured.documents.elements import Text
element = Text("Philadelphia Eaglesâ\x80\x99 victory")
element.apply(replace_unicode_quotes)
print(element)
The above code modifies the input “Philadelphia Eaglesâ\x80\x99 victory” into a cleaner and more human-readable representation of “Philadelphia Eagles' victory”.
Users can also easily include their cleaning functions for custom data preparation tasks. In the example below, we remove citations from a section of text.
import re
remove_citations = lambda text: re.sub("\[\d{1,3}\]", "", text)
element = Text("[1] Geolocated combat footage has confirmed Russian gains in the Dvorichne area northwest of Svatove.")
element.apply(remove_citations)
print(element)
Please refer to the following cleaning documentation for more information on the unstructured framework's cleaning partition.
3) Chunking
Chunking refers to dividing a large text into smaller, manageable segments (or chunks) before converting them into numerical vectors.
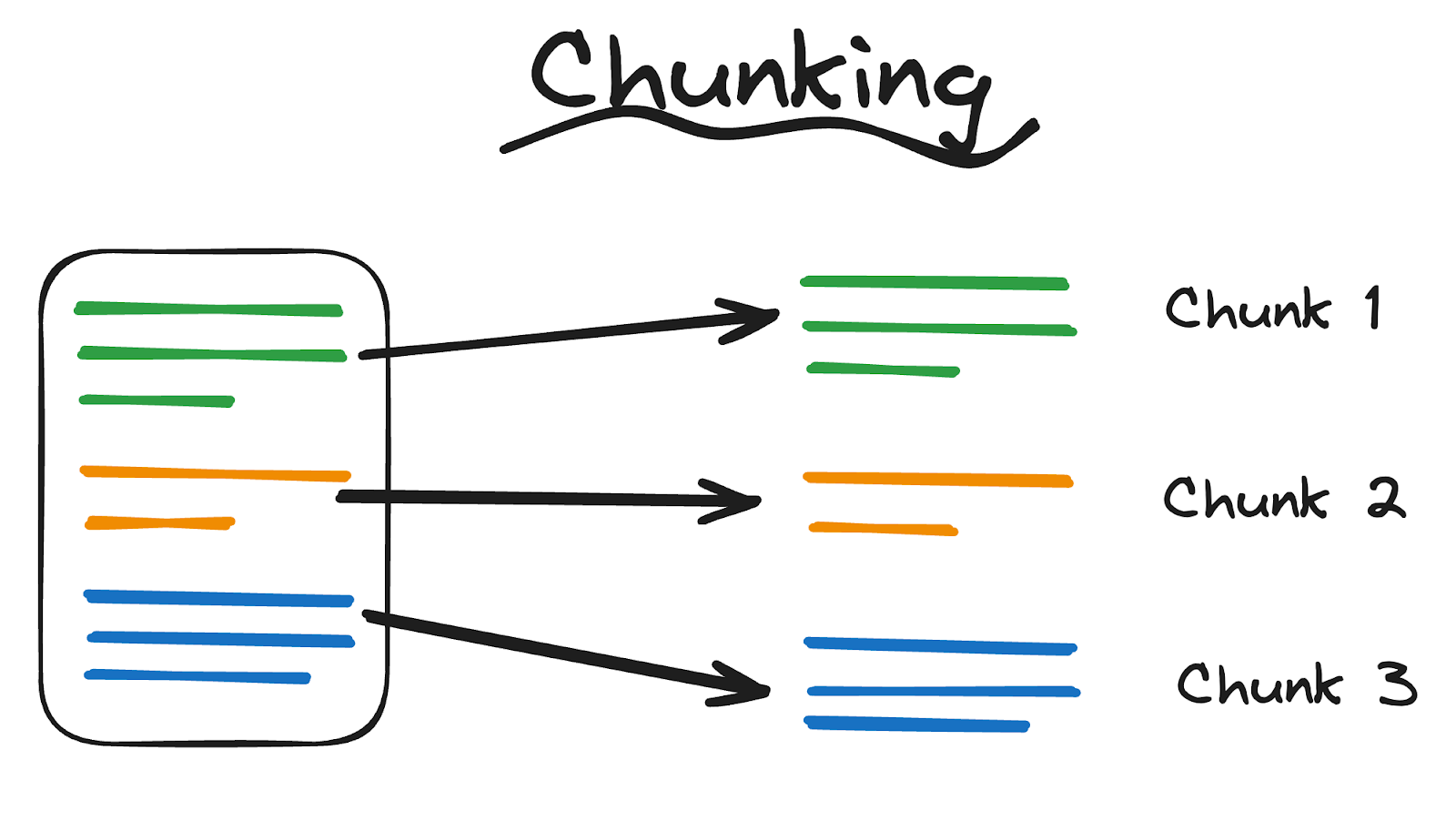 What does chunking mean?
What does chunking mean?
Chunking is essential when dealing with lengthy documents like books or research papers. It allows for more precise and efficient analysis by reducing the size and complexity of the data fed into machine learning models.
Why is Chunking Important?
First, extensive text data can exceed the input limits of many models, such as BERT, with a 512-token limit; thus, chunking breaks large documents into smaller sections.
Moreover, chunking benefits LLMs of all sizes, as smaller chunks ensure each segment has coherent content, helping models better understand the context.
Lastly, efficient chunking prevents memory overload by processing smaller portions of data.
It's crucial to differentiate between chunking and partitioning processes. Chunking operates on document elements, distinct from partitioning, which precedes it. While it's possible to perform chunking concurrently with partitioning, separating these steps enhances clarity and customization. By treating chunking as a distinct phase after partitioning, developers gain better insight and greater control over the data transformation process.
The Unstructured framework offers multiple chunking options:
max_characters: int (default=500) - the hard maximum size for a chunk. No chunk will exceed this number of characters.
new_after_n_chars: int (default=max_characters) - the “soft” maximum size for a chunk. A chunk that exceeds this number of characters will not be extended, even if the next element would fit without exceeding the specified hard maximum.
overlap: int (default=0) - only when using text-splitting to break up an oversized chunk, include this number of characters from the end of the prior chunk as a prefix on the next.
overlap_all: bool (default=False) - also apply overlap between “normal” chunks, not just when text-splitting to break up an oversized element. Because regular chunks are formed from whole elements with a clean semantic boundary, this option may “pollute” regular chunks. You must decide whether this option is right based on your use case.
Furthermore, the Unstructured framework divides the chunking strategy into two main methods:
The basic chunking strategy combines sequential elements to maximally fill each chunk while respecting both the specified max_characters (hard-max) and new_after_n_chars (soft-max) option values.
The by_title chunking strategy also preserves section and, optionally, page boundaries. “Preserving” here means that a single chunk will never contain text that occurred in two different sections. When a new section starts, the existing chunk is closed, and a new one begins, even if the next element would fit the prior chunk.
As shown below, to choose one or the other, import the function you prefer and perform the chunking type selected on the partitioned data.
from unstructured.chunking.basic import chunk_elements
from unstructured.partition.html import partition_html
url = "https://understandingwar.org/backgrounder/russian-offensive-campaign-assessment-august-27-2023-0"
elements = partition_html(url=url)
chunks = chunk_elements(elements)
# -- OR --
from unstructured.chunking.title import chunk_by_title
chunks = chunk_by_title(elements)
for chunk in chunks:
print(chunk)
print("\n\n" + "-"*80)
input()
4) Embedding (Vectorizing)
Embedding is the key and final step, transforming words, phrases, or entire texts into numerical vectors. This process allows computational models to understand and process human language effectively.
In this step, we represent text as numbers, and embeddings map textual information into fixed-size numerical vectors.
The Unstructured framework offers multiple encoders, such as the well-known OpenAIEmbeddingEncoder, utilized in the code below.
import os
from unstructured.documents.elements import Text
from unstructured.embed.openai import OpenAIEmbeddingConfig, OpenAIEmbeddingEncoder
# Initialize the encoder with OpenAI credentials
embedding_encoder = OpenAIEmbeddingEncoder(config=OpenAIEmbeddingConfig(api_key=os.environ["OPENAI_API_KEY"]))
# Embed a list of Elements
elements = embedding_encoder.embed_documents(
elements=[Text("This is sentence 1"), Text("This is sentence 2")],
)
# Embed a single query string
query = "This is the query"
query_embedding = embedding_encoder.embed_query(query=query)
# Print embeddings
[print(e.embeddings, e) for e in elements]
print(query_embedding, query)
print(embedding_encoder.is_unit_vector(), embedding_encoder.num_of_dimensions())
5) Storing, Indexing, and Querying with Milvus
a) Setting Up Milvus
We will begin by fetching the latest Milvus Docker image from the Docker Hub repository and running the Milvus Container.
docker pull milvusdb/milvus
docker run -d --name milvus -p 19530:19530 milvusdb/milvus:latest
Next, we will use the below command to install the PyMilvus library.
pip install pymilvus
Lastly, we will connect to a Milvus instance running on port 19530.
from pymilvus import connections
connections.connect("default", host="localhost", port="19530")
b) Defining Our Vector Database Schema and Creating a New Collection
Import the Necessary Modules and Classes from the “pymilvus” library installed in the earlier step.
from pymilvus import Collection, FieldSchema, CollectionSchema, DataType
Next, we will define the Fields for our Collection Schema. For simplicity, we are going to create only two fields. First, a field named "id" with the data type INT64 (64-bit integer) will mark it as the primary key. The second field would be the "embedding" with the data type FLOAT_VECTOR and a dimension of 768. This field will store the vector embeddings.
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=768)
]
We will then create our CollectionSchema using the defined fields and provide a description ("EPUB Embeddings"). This schema defines the structure of the collection.
schema = CollectionSchema(fields, "EPUB Embeddings")
collection = Collection("epub_embeddings", schema)
c) Inserting Our Vectorized Data into Our Collection
We will begin by initializing the OpenAI encoder with our OpenAI credentials.
embedding_encoder = OpenAIEmbeddingEncoder(config=OpenAIEmbeddingConfig(api_key=os.environ["OPENAI_API_KEY"]))
Add an example list of text elements (replace these fields with your EPUB elements).
elements = [
Text("This is sentence 1"),
Text("This is sentence 2"),
]
In this step, we will embed our selected elements. Note that this step is the same one as the one followed above.
- Embedding(Vectorizing) step.
embedded_elements = embedding_encoder.embed_documents(elements=elements)
Next, we will extract the newly generated embeddings and generate an ID for each.
embeddings = [e.embeddings for e in embedded_elements]
ids = [i for i in range(len(embeddings))]
To ensure that you have the same number of IDs and embeddings, you can add an assertion check before inserting the data into Milvus.
This check will help you catch any discrepancies early and prevent issues during the insertion process.
assert len(embeddings) == len(ids)
Next, we will prepare our data for insertion using the structure given below.
data = [ids, embeddings]
Lastly, we will insert the embedded data into our Milvus vector database.
collection.insert(data)
d) Creating an Index
In the below index_params, the "metric_type" given the value "L2", specifies that the distance metric used for similarity search is L2 (Euclidean distance).
The "index_type," given the value "IVF_FLAT," specifies the type of index to be used. IVF_FLAT (Inverted File with Flat) is one of the indexing methods Milvus supports. It's suitable for large-scale similarity searches.
While "params": {"nlist": 128} defines the additional parameters for the index. “nlist“ is the number of clusters (or inverted lists) used in the index. A larger ”nlist“ value can improve search accuracy but requires more memory and computational resources.
from pymilvus import Index, IndexType
index_params = {
"metric_type": "L2",
"index_type": "IVF_FLAT",
"params": {"nlist": 128}
}
collection.create_index(field_name="embedding", index_params=index_params)
We will then load the collection we have just created.
collection.load()
e) Querying (Searching for Similar Vectors)
First, we will define a search query to search inside the vector database. The below query_vector will include a list of 768 random floating-point numbers between 0 and 1.
query_vector = [random.random() for _ in range(768)]
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
Next, we will perform the similarity search using the given query vector.
results = collection.search(
data=[query_vector],
anns_field="embedding",
param=search_params,
limit=10,
expr=None
)
Conclusion
Vector embeddings are numerical representations of unstructured data, such as ebooks, enabling machines to comprehend and analyze such data effectively. They play pivotal roles in recommendation systems, AI chatbots, and various GenAI applications, facilitating personalized experiences and insightful interactions. Throughout this blog, we've delved into the significance of vectorization and similarity search in constructing such applications.
We also discussed how to harness the power of the Unstructured Framework to seamlessly convert EPUB content into vector embeddings and the Milvus vector database to store and retrieve the most relevant results. By offering a comprehensive step-by-step guide, we equipped readers with the knowledge and tools to implement these operations seamlessly within their applications.

- Introduction
- EPUB Vectorization with the Unstructured and Milvus
- From EPUB to Insights: The Vectorization Journey
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading
A Beginner's Guide to Website Chunking and Embedding for Your RAG Applications
This post explains how to extract content from a website and use it as context for LLMs in a RAG application. However, before doing so, we need to understand website fundamentals.
Image Embeddings for Enhanced Image Search: An In-depth Explainer
Image Embeddings are the core of modern computer vision algorithms. Understand their implementation and use cases and explore different image embedding models.

DistilBERT: A Distilled Version of BERT
DistilBERT maintains 97% of BERT's language understanding capabilities while being 40% small and 60% faster.