




What is ScaNN (Scalable Nearest Neighbors)?
ScaNN is an open-source library developed by Google for fast, approximate nearest neighbor searches in large-scale datasets.
Read the entire series
- Raft or not? The Best Solution to Data Consistency in Cloud-native Databases
- Understanding Faiss (Facebook AI Similarity Search)
- Information Retrieval Metrics
- Advanced Querying Techniques in Vector Databases
- Popular Machine-learning Algorithms Behind Vector Searches
- Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
- Ranking Models: What Are They and When to Use Them?
- Navigating the Nuances of Lexical and Semantic Search with Zilliz
- Enhancing Efficiency in Vector Searches with Binary Quantization and Milvus
- Model Providers: Open Source vs. Closed-Source
- Embedding and Querying Multilingual Languages with Milvus
- An Ultimate Guide to Vectorizing and Querying Structured Data
- Understanding HNSWlib: A Graph-based Library for Fast Approximate Nearest Neighbor Search
- What is ScaNN (Scalable Nearest Neighbors)?
- Getting Started with ScaNN
- Next-Gen Retrieval: How Cross-Encoders and Sparse Matrix Factorization Redefine k-NN Search
- What is Voyager?
- What is Annoy?
Applications like recommendation systems, image search, and natural language processing (NLP) depend heavily on their ability to find patterns and connections within vast datasets. Whether it's suggesting the next movie you’ll love, retrieving visually similar images, or identifying related text, these systems rely on a core process known as vector similarity search to deliver relevant results.
However, as datasets grow to millions or even billions of items, performing similarity search at scale becomes increasingly challenging. ScaNN (Scalable Nearest Neighbors) is a library developed by Google to optimize and accelerate this process. ScaNN leverages advanced techniques to make nearest neighbor search (NNS) faster and more efficient, empowering AI-driven systems to handle complex data with improved speed and accuracy.
Before exploring what makes ScaNN unique, let’s start with the basics: understanding vector search and why it’s essential.
The Basics: Vector Search and Nearest Neighbor Search
At the heart of many AI applications is the concept of vector similarity search, which is a process of comparing vectors—mathematical representations of unstructured data like images, text, or audio—to find the most similar items to a given query point. This process is also called nearest neighbor search (NNS) because it identifies the "closest" matches in a high-dimensional space.
How Vector Search Works
When data is converted into vectors, each vector can be thought of as a point in a multi-dimensional space. The more similar two items are, the closer their points will be in this space. For example:
Recommendation Systems: A movie recommendation engine represents each movie and user preference as vectors. If you’ve enjoyed romantic comedies, the system searches for movies with vectors that are close to romantic comedies in the vector space.
Image Search: A reverse image search engine converts an image into a vector and finds other images with similar features.
NLP: Text embeddings are vectors that capture the meaning of words or sentences. Vector similarity helps identify semantically related text.
To compare vectors, we calculate their "distance" using mathematical metrics like Euclidean distance or cosine similarity. Smaller distance = greater similarity. For example, in a movie recommendation system, a vector representing a romantic comedy would be closer to another romantic comedy than to a horror movie.
The Challenge: Scaling Vector Search
Vector similarity search is straightforward for small datasets, but it becomes computationally expensive as the number of vectors increases. Imagine searching for the nearest neighbor among millions or billions of vectors—it requires comparing each query to every vector, which is infeasible for real-time applications.
Traditional methods for exact nearest neighbor search (like brute force) are too slow to handle these demands. To overcome this, modern systems turn to approximate nearest neighbor search (ANNS), which speeds up the process by sacrificing a small amount of accuracy in favor of significant performance gains.
What is ScaNN (Scalable Nearest Neighbors)?
ScaNN, short for Scalable Nearest Neighbors, is a library designed to address scaling vector similarity search challenges. Developed by Google, ScaNN focuses on approximate nearest neighbor search (ANNS), striking a balance between speed and accuracy, even on large datasets that would traditionally pose challenges for most search algorithms.
Now, let's look at ScaNN architecture and how it achieves this efficiency.
How ScaNN Works
ScaNN is built to solve one of the biggest challenges in vector search: efficiently finding the most relevant vectors in high-dimensional spaces, even as datasets grow larger and more complex. Its architecture breaks down the vector search process into distinct stages. These stages are partitioning, quantization, and re-ranking.
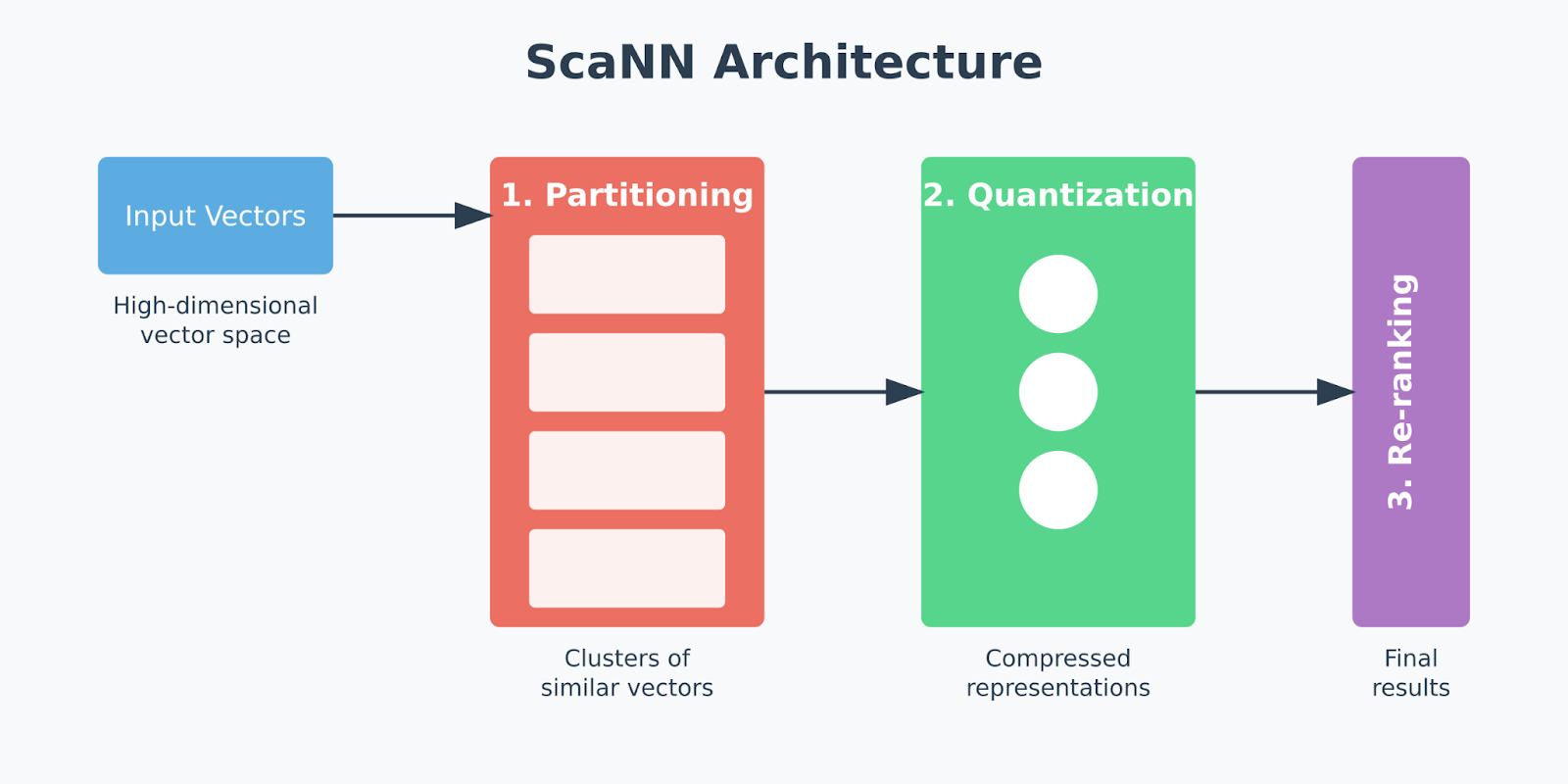 Figure - ScaNN’s architecture.png
Figure - ScaNN’s architecture.png
Figure: ScaNN’s architecture
Each stage tackles specific bottlenecks that would otherwise slow down the search or increase resource consumption. This multi-stage process allows ScaNN to optimize both speed and accuracy, filtering out irrelevant data early and fine-tuning the results toward the end. Let’s discuss the three components in detail.
ScaNN’s three Core Components
Partitioning is a process that divides the dataset into clusters. This method narrows the search space by focusing only on relevant data subsets instead of scanning the entire dataset, saving time and processing resources. ScaNN often uses clustering algorithms, such as k-means, to identify clusters, which allows it to perform similarity searches more efficiently.
Quantization: ScaNN applies a quantization process known as anisotropic vector quantization after partitioning. Traditional quantization focuses on minimizing the overall distance between original and compressed vectors, which isn’t ideal for tasks like Maximum Inner Product Search (MIPS), where similarity is determined by the inner product of vectors rather than direct distance. Anisotropic quantization instead prioritizes preserving parallel components between vectors, or the parts most important for calculating accurate inner products. This approach allows ScaNN to maintain high MIPS accuracy by carefully aligning compressed vectors with the query, enabling faster, more precise similarity searches.
Re-ranking: The re-ranking phase is the final step, where ScaNN fine-tunes the search results from the partitioning and quantization stages. This re-ranking applies precise inner product calculations to the top candidate vectors, ensuring the final results are highly accurate. Re-ranking is crucial in high-speed recommendation engines or image search applications where the initial filtering and clustering serve as a coarse layer, and the final stage ensures that only the most relevant results are returned to the user.
This three-stage process enables ScaNN to combine the speed of approximate search with the accuracy of exact search methods, making it a balanced choice for applications requiring both. Since you have understood the architecture, let’s now see how to set up ScaNN in different environments to start implementing its capabilities.
For more details on how to implement it with ScaNN, check out this tutorial.
Key Features of ScaNN
ScaNN’s design incorporates a range of features tailored for performance and adaptability. Below are some of the attributes that make ScaNN effective for modern AI and machine learning applications:
Hybrid Coarse and Fine-grained Search
ScaNN combines both coarse and fine-grained search techniques, where coarse search broadly filters the dataset to quickly exclude unrelated data, and fine-grained search then precisely checks the most relevant matches within the filtered results. This coarse-to-fine approach limits the number of vectors ScaNN needs to evaluate, enhancing speed without reducing accuracy. This hybrid method ensures efficiency on both small and large datasets.
Approximate Nearest Neighbor (ANN)
ScaNN relies on Approximate Nearest Neighbor (ANN) search, a technique that sacrifices some precision in favor of speed. ANN ensures that ScaNN can return near-accurate results quickly, which is important in applications where low-latency response times are required. By tuning the degree of approximation, users can control the trade-off between speed and accuracy, making ScaNN adaptable for various search scenarios.
Scalability
ScaNN’s architecture is built to handle extensive datasets, with performance optimizations that ensure it scales smoothly with increasing data volumes. Whether dealing with millions or tens of millions of vectors, ScaNN’s partitioning and quantization mechanisms enable it to operate efficiently, making it suitable for various environments with high scalability demands.
TensorFlow Integration
Seamless integration with TensorFlow enables ScaNN to fit directly into machine learning pipelines. TensorFlow support simplifies implementation, allowing us to incorporate ScaNN into broader workflows without needing extensive modifications. This compatibility facilitates its use in machine learning tasks where efficient nearest-neighbor search is essential.
Customizable Accuracy vs Speed
ScaNN’s tunable parameters allow users to adjust the accuracy-speed trade-off according to their needs. For example, you can prioritize faster search results by lowering accuracy settings or increase accuracy for applications requiring high precision. This flexibility is valuable for businesses with varying performance needs, as it provides the means to optimize ScaNN for their unique data and response requirements.
Memory Efficiency
Memory efficiency is another strong point for ScaNN. Its quantization strategy, in particular, reduces memory usage by compressing vector representations, a feature beneficial for environments with hardware limitations. This makes ScaNN suitable for resource-constrained settings, as it enables large-scale vector search without demanding extensive memory resources.
Best Use Cases for ScaNN
ScaNN’s strengths make it an ideal choice for applications that rely on high-speed, high-accuracy vector similarity search. Some of the common use cases include:
Recommendation Engines: ScaNN’s fast vector search capabilities enhance the user experience by delivering relevant recommendations in real-time.
Image Search: ScaNN can efficiently match images based on visual similarity, helping power visual search engines in sectors like e-commerce.
Natural Language Processing: NLP applications often rely on vectorized representations of language data, and ScaNN’s speed and efficiency make it ideal for tasks like text similarity matching and document retrieval.
Comparison with Other Vector Search Libraries
ScaNN vs Faiss
ScaNN and Faiss are both high-performance tools for nearest neighbor searches, yet they differ significantly in approach. ScaNN is highly optimized for MIPS through anisotropic vector quantization, which prioritizes maintaining ranking accuracy in inner-product search results. This makes ScaNN especially useful in applications like recommendation engines that rely on inner-product similarity. In contrast, Faiss offers a broader set of indexing and quantization options, including product quantization, which gives it flexibility in handling diverse search needs. Faiss’s GPU support enhances performance on larger datasets, although ScaNN’s focus on MIPS allows it to deliver faster responses in latency-sensitive environments.
ScaNN vs Annoy
ScaNN and Annoy, short for Approximate Nearest Neighbors Oh Yeah, are structured differently to address different search needs. Annoy uses random projection trees for indexing, which makes it highly efficient in low-dimensional spaces and environments with limited memory. However, Annoy is not as optimized for high-dimensional or large-scale data, where ScaNN’s partitioning and quantization techniques provide an advantage. ScaNN is a better choice for applications requiring accurate similarity searches in high-dimensional spaces, while Annoy is suitable for simpler or smaller datasets.
ScaNN vs HNSWlib
HNSWlib, based on the Hierarchical Navigable Small World (HNSW) graph approach, excels in high accuracy for vector searches by building multi-layered graphs where nodes represent data points connected by proximity relationships. HNSWlib’s hierarchical structure supports highly precise searches through these graph layers, but it requires more memory than ScaNN’s partitioning and quantization. For applications needing both high accuracy and memory efficiency, ScaNN’s design is more suitable, especially in large-scale data environments.
Challenges and Limitations of ScaNN
While ScaNN offers many advantages, there are certain limitations and trade-offs you should be aware of:
Search Speed vs. Accuracy Trade-off
Although ScaNN allows users to configure the accuracy-speed trade-off, the highest accuracy settings may still lag behind more specialized algorithms designed purely for exact matches. The approximate nature of its search can sometimes yield slightly less precise results, which may not be suitable for all use cases. However, this compromise is often balanced by the speed gains.
Dimensionality Issues
While ScaNN performs well across various datasets, extremely high-dimensional data can still present challenges. The partitioning and quantization methods employed by ScaNN might lose some efficiency or accuracy when the dimensions surpass certain thresholds, though this is a common issue among most high-dimensional vector search techniques.
Scaling Complexity
Adjusting ScaNN’s parameters to fit a specific dataset and use case can be complex. As ScaNN offers multiple tunable features, it may require fine-tuning for each scenario, which can be time-intensive. Some users may need experimentation to optimize the performance for their specific datasets and resources.
For some use cases, these limitations might lead users to consider a complete vector database solution instead of a standalone library.
Vector Search Library vs. Vector Databases
Vector search libraries and vector databases address different data handling needs.
Vector search libraries like ScaNN, Faiss, and Annoy are designed for high-speed similarity searches. They focus on efficient retrieval of nearest neighbors in vector spaces but lack capabilities for persistent data storage or complex querying. These libraries are ideal for situations where vector data is transient or embedded within broader data processing workflows. For example, Faiss, developed by Meta, is optimized for managing dense vector collections, suitable even for datasets that may exceed in-memory limits.
On the other hand, purpose-built vector databases such as Milvus, along with its fully managed version, Zilliz Cloud, go beyond simple similarity search to provide robust storage, indexing, and querying capabilities for even billion-scale vector data. These vector databases also support real-time updates and distributed scalability, hybrid sparse and dense vector search, multi-replica, multi-tenancy and so many enterprise-ready features, making them well-suited for production applications.
Additionally, Milvus natively supports various ANN algorithms, including ScaNN, HNSW, IVF, DiskANN, and more, each optimized for different use cases and requirements.
Benchmarking Vector Search: ScaNN Performance
ANN-Benchmark is a comprehensive evaluation tool designed to measure and compare the performance of different ANNS algorithms on various datasets.
On the glove-100-angular dataset, ScaNN has shown high performance, managing nearly twice as many queries per second at a similar accuracy level compared to other libraries. This makes it well-suited for handling extensive datasets where speed and accuracy are equally important.
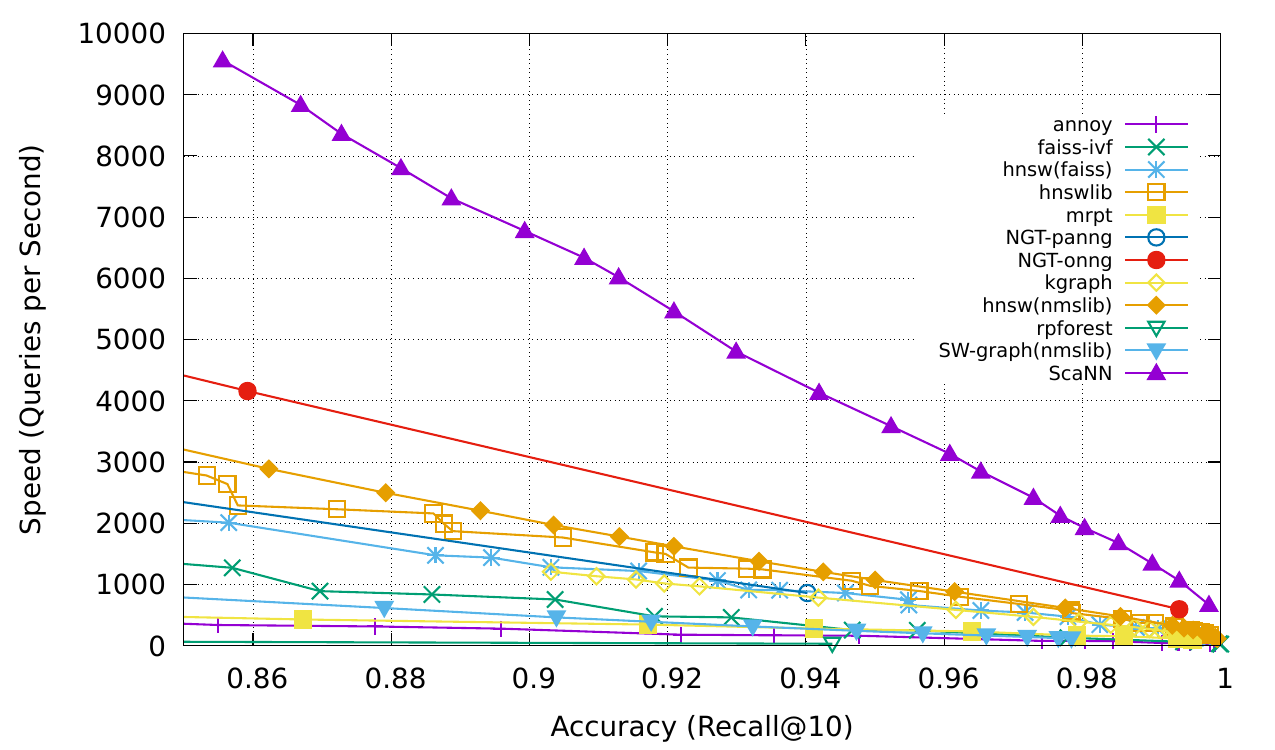 Figure - Benchmarking result.png
Figure - Benchmarking result.png
Figure: Benchmarking result
These benchmarking results highlight ScaNN's capability to deliver quick and accurate vector similarity searches, making it a strong choice for applications that require efficient handling of vast, high-dimensional data.
Conclusion
ScaNN is highly efficient in vector similarity searches, leveraging techniques like partitioning, quantization, and re-ranking to deliver a balance of speed and accuracy for high-dimensional data. It is ideal for building fast-paced AI applications such as recommendation engines, image retrieval, and natural language processing (NLP), where performance is prioritized. ScaNN also provides flexibility, allowing users to fine-tune the trade-offs between accuracy and speed to suit specific use cases, making it effective for scalable and memory-efficient solutions.
However, ScaNN and similar libraries like Faiss, Annoy, and HNSWlib are best suited for prototyping, small-scale applications, or relatively static datasets that don’t require frequent updates. For production-grade scenarios involving billion-scale datasets or advanced capabilities like high availability, multi-tenancy, hybrid sparse and dense search, or filtered search, purpose-built vector databases such as Milvus offer a more robust and scalable solution. These databases are designed for dynamic, enterprise-grade environments, providing the features necessary to manage large, evolving datasets seamlessly.
FAQs of ScaNN
What is ScaNN?
ScaNN is a vector similarity search library developed by Google, designed to efficiently handle large, high-dimensional datasets for applications like recommendation engines, image search, and NLP.
What are the core components of ScaNN's architecture?
ScaNN's architecture is built on three main components: partitioning, quantization, and re-ranking. These stages work together to enhance speed and accuracy in vector similarity searches.
When should I choose ScaNN over a full vector database like Milvus or Zilliz Cloud?
ScaNN is a great choice when you need efficient, scalable similarity search without the need for persistent storage or complex queries or you just want to prototype or experiment with vector searches. For building apps for production environments or handling large-scale datasets up to billions of vectors, a purpose-built vector database like Milvus or a more hassle-free service, Zilliz Cloud, may be more suitable.
Further Resources
 Fendy Feng
Fendy FengFendy Feng is the Product Marketing Manager at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.

- The Basics: Vector Search and Nearest Neighbor Search
- What is ScaNN (Scalable Nearest Neighbors)?
- Key Features of ScaNN
- Comparison with Other Vector Search Libraries
- Challenges and Limitations of ScaNN
- Vector Search Library vs. Vector Databases
- Benchmarking Vector Search: ScaNN Performance
- Conclusion
- FAQs of ScaNN
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
Milvus enables hybrid sparse and dense vector search and multi-vector search capabilities, simplifying the vectorization and search process.

Getting Started with ScaNN
Google’s ScaNN is a library for ANNS. This guide walks you you through implementing ScaNN and demonstrate how to integrate it with Milvus.

What is Voyager?
Voyager is an Approximate Nearest Neighbor (ANN) search library optimized for high-dimensional vector data.