




Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
Milvus enables hybrid sparse and dense vector search and multi-vector search capabilities, simplifying the vectorization and search process.
Read the entire series
- Raft or not? The Best Solution to Data Consistency in Cloud-native Databases
- Understanding Faiss (Facebook AI Similarity Search)
- Information Retrieval Metrics
- Advanced Querying Techniques in Vector Databases
- Popular Machine-learning Algorithms Behind Vector Searches
- Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
- Ranking Models: What Are They and When to Use Them?
- Navigating the Nuances of Lexical and Semantic Search with Zilliz
- Enhancing Efficiency in Vector Searches with Binary Quantization and Milvus
- Model Providers: Open Source vs. Closed-Source
- Embedding and Querying Multilingual Languages with Milvus
- An Ultimate Guide to Vectorizing and Querying Structured Data
- Understanding HNSWlib: A Graph-based Library for Fast Approximate Nearest Neighbor Search
- What is ScaNN (Scalable Nearest Neighbors)?
- Getting Started with ScaNN
- Next-Gen Retrieval: How Cross-Encoders and Sparse Matrix Factorization Redefine k-NN Search
- What is Voyager?
- What is Annoy?
Vector databases have seen an incredible rise in popularity. However, most vector databases support only a single vector column, limiting their use for applications with more complex data types. Milvus 2.4 changed the landscape by offering support for multiple vector types within the same database, including sparse and dense vectors. This development opened new possibilities for handling and analyzing different forms of data, such as text and images, within a single system. The ability to work with various data types in one place is particularly important for developing more effective and efficient search and retrieval systems.
In this blog, we will explore how Milvus 2.4 enables the representation of complex data, like products, in a single row in a vector database. This approach simplifies the vectorization and search process, particularly for applications requiring hybrid search, such as text and images.
Let’s get started.
Sparse Vectors Recap
Before diving into some code snippets, let’s briefly recap sparse vectors.
Sparse vectors are different from dense vectors in their structure and usage. Dense vectors are typically the final or penultimate layer of activations in neural networks and are usually of moderate length, with typical sizes being 768, 1024, or 1536 elements. In these vectors, most or all of the values are nonzero, meaning they contain a lot of information in a relatively compact form.
In contrast, sparse vectors are characterized by their length and sparsity. They can be long, often containing tens of thousands of elements, but with few nonzero elements. Due to their structure, sparse vectors are efficiently represented as dictionaries, where the keys are the indices of the nonzero elements, and the values are the magnitudes of these elements.
Sparse vectors are mainly used in two contexts. The first is with traditional search algorithms, such as TF-IDF and BM25, which are methods for scoring and ranking documents based on their relevance to a search query. These algorithms produce sparse vectors because only a few terms in the entire vocabulary are relevant to any given document or query. The second context is in learned models like SPLADE, which generate sparse vectors through machine learning techniques to represent textual or other types of data. These models can learn the importance of adjacent or related tokens that don’t necessarily appear in the text, leading to a “learned” sparse representation that captures all relevant keywords/classes.
How Hybrid Search Works in Milvus
Before Milvus 2.4, combining results from sparse and dense vector searches typically relied on some sort of late fusion. For multiple dense vectors, this was done by "joining" the search results of two different collections together, but for hybrid semantic + lexical text search applications, this required a separate system such as Lucene. Milvus 2.4 changes all that, enabling sparse vector and hybrid search in a single system. It creates separate search requests over the specified vector columns and applies a rank function to the results. Milvus currently supports basic weighted averaging along with reciprocal rank filtering.
# because hybrid search goes across many columns, we have to create individual requests first
req_0 = AnnSearchRequest(query_vector_0, "vector_col_0", search_params_0, limit=topk)
req_1 = AnnSearchRequest(query_vector_1, "vector_col_1", search_params_1, limit=topk)
# with these two search requests in place, we can now submit them into our pymilvus’ hybrid search function
reqs = [req_0, req_1]
res = col.hybrid_search(reqs, rerank=RRFRanker(), limit=topk)
The above example shows how to perform a multi-vector search in Milvus. Either of the two columns (vector_col_0 or vector_col_1) could be specified as a sparse or dense floating-point vector. Once the search requests are in place, they can be sent to Milvus for evaluation.
Don't worry if this doesn't make a whole lot of sense right now—we'll explore two examples right now.
Hybrid Search Example with Text
Let’s go over an example of a combined sparse + dense vector search in the Milvus vector database. We’ll start off by getting an instance of Milvus 2.4 up and running:
!wget https://github.com/milvus-io/milvus/releases/download/v2.4.0-rc.1/milvus-standalone-docker-compose-gpu.yml -O docker-compose.yml
!docker compose up -d
!docker ps -a
Name Command State Ports
--------------------------------------------------------------------------------------------------------------------
milvus-etcd etcd -advertise-client-url ... Up 2379/tcp, 2380/tcp
milvus-minio /usr/bin/docker-entrypoint ... Up (healthy) 9000/tcp
milvus-standalone /tini -- milvus run standalone Up 0.0.0.0:19530->19530/tcp, 0.0.0.0:9091->9091/tcp
Be sure to use the latest version of Milvus (2.4.0-rc1 at the time of writing).
Now let's set up the proper libraries. We're going to generate both sparse and dense vectors for the above text using the readily available BGE-M3 within pymilvus[models]. We won't dive too much into the details of BGE-M3 in this post; if you're interested in something more substantial, check out the BGE-M3 paper.
!pip install -U pymilvus
!pip install -U pymilvus[model]
As always, make sure you’re using a virtualenv before starting. Let’s now get our imports set up:
import numpy as np
from pymilvus import (
utility,
FieldSchema, CollectionSchema, DataType,
Collection, AnnSearchRequest, RRFRanker, connections,
)
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
From here, we will define our “dataset” as a list of three sentences. We’ll also use BGE-M3 to generate sparse and dense embeddings for our documents as well as the query text:
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
query = "Who started AI research?"
ef = BGEM3EmbeddingFunction(use_fp16=False, device="cpu")
dense_dim = ef.dim["dense"]
docs_embeddings = ef(docs)
query_embeddings = ef([query])
With this step, we can create a collection to hold our data. In particular, we will specify two vector columns in our schema - one named sparse_vector and another named dense_vector - with the corresponding data types. We’re also going to create indexes over these two columns;
connections.connect("default", host="localhost", port="19530")
fields = [
# Use auto generated id as primary key
FieldSchema(name="pk", dtype=DataType.VARCHAR,
is_primary=True, auto_id=True, max_length=100),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=512),
FieldSchema(name="sparse_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
FieldSchema(name="dense_vector", dtype=DataType.FLOAT_VECTOR, dim=dense_dim)
]
schema = CollectionSchema(fields, "")
col = Collection("sparse_dense_demo", schema)
sparse_index = {"index_type": "SPARSE_INVERTED_INDEX", "metric_type": "IP"}
dense_index = {"index_type": "FLAT", "metric_type": "COSINE"}
col.create_index("sparse_vector", sparse_index)
col.create_index("dense_vector", dense_index)
Status(code=0, message=)
From here, we can insert the documents into Milvus:
entities = [docs, docs_embeddings["sparse"], docs_embeddings["dense"]]
col.insert(entities)
col.flush()
Querying is a tad bit more complex. We must specify a way to co-rank the sparse and dense vectors returned from Milvus. In this example, we’ll use reciprocal rank fusion, which ranks documents based on their reciprocal position for each method. We’ll create two separate search requests for the two columns and merge them using RRFRanker:
sparse_req = AnnSearchRequest(query_embeddings["sparse"],
"sparse_vector", {"metric_type": "IP"}, limit=2)
dense_req = AnnSearchRequest(query_embeddings["dense"],
"dense_vector", {"metric_type": "COSINE"}, limit=2)
res = col.hybrid_search([sparse_req, dense_req], rerank=RRFRanker(),
limit=2, output_fields=["text"])
['["id: 448695871357611268, distance: 0.032786883413791656, entity: {\'text\': \'Alan Turing was the first person to conduct substantial research in AI.\'}", "id: 448695871357611267, distance: 0.016129031777381897, entity: {\'text\': \'Artificial intelligence was founded as an academic discipline in 1956.\'}"]']
That’s all there is to it. We experimented with a small dataset that was easily extensible to millions or even billions of text documents.
This example is in our bootcamp, along with the pymilvus examples—feel free to try it out yourself.
Beyond Single-Modality Search
Pure text search is great but has some obvious limitations. In particular, most unstructured data is represented through multiple modalities of data. Take the example of products, a type of unstructured data commonly used in recommender systems. Products can have many attributes, including images, descriptions, reviews, etc. Each attribute can be vectorized and stored as combined to form a single “row” in a vector database. For instance, a product can be represented by both a dense vector derived from its image and a sparse vector derived from its textual description.
Let’s dive into an example using the 2023 Amazon Product Dataset from Kaggle (you can also download it from my Google Drive. In this dataset, we can convert the first image of each product into a dense vector and the product's title into a sparse vector. Let’s load the dataset into a pandas data frame first:
import pandas as pd
df = pd.read_csv("amazon_products.csv")
df = df[df["title"].str.len() > 0]
df.columns
Index(['asin', 'title', 'imgUrl', 'productURL', 'stars', 'reviews', 'price',
'listPrice', 'category_id', 'isBestSeller', 'boughtInLastMonth'],
dtype='object')
We'll employ GResNet to create dense vectors from images.
from collections import OrderedDict
import torch
import torch.nn as nn
from torchvision.models import gresnet50
gresnet = gresnet50()
weights = torch.load("model_426.pth", map_location=torch.device("cpu"))["model_ema"]
weights_ = OrderedDict()
for (k, w) in weights.items():
if k != "n_averaged":
weights_[k.replace("module.", "")] = w
gresnet.load_state_dict(weights_)
gresnet.eval()
gresnet_transforms = partial(ImageClassification, crop_size=224, resize_size=232)()
gresnet.classifier[2] = nn.Identity()
There’s another code here to download the images we’ve left out for simplicity.
For the product description, we can use TF-IDF, a technique that reflects the importance of a word in a document relative to a collection of documents (the corpus). The term frequency portion (TF) of TF-IDF measures the frequency of a word in a specific document, while the inverse document frequency portion (IDF) assesses the rarity of the word across all documents:
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(df["title"])
X
<1426336x429087 sparse matrix of type '<class 'numpy.float64'>'
with 23340037 stored elements in Compressed Sparse Row format>
We can then create a collection along with two columns for the vectors, insert them into Milvus, and perform a hybrid search, all as above. This enables us to search for similar products given a “query product” that an existing user has already purchased:
res = col.hybrid_search([sparse_req, dense_req], rerank=RRFRanker(),
limit=10, output_fields=["productURL"])
And that’s it! By integrating these two vectors—dense for images and sparse for text—we create a holistic representation of each product that captures both its visual and textual elements. This example illustrates how moving beyond single-modality search and leveraging hybrid models can significantly improve search systems' efficiency and effectiveness.
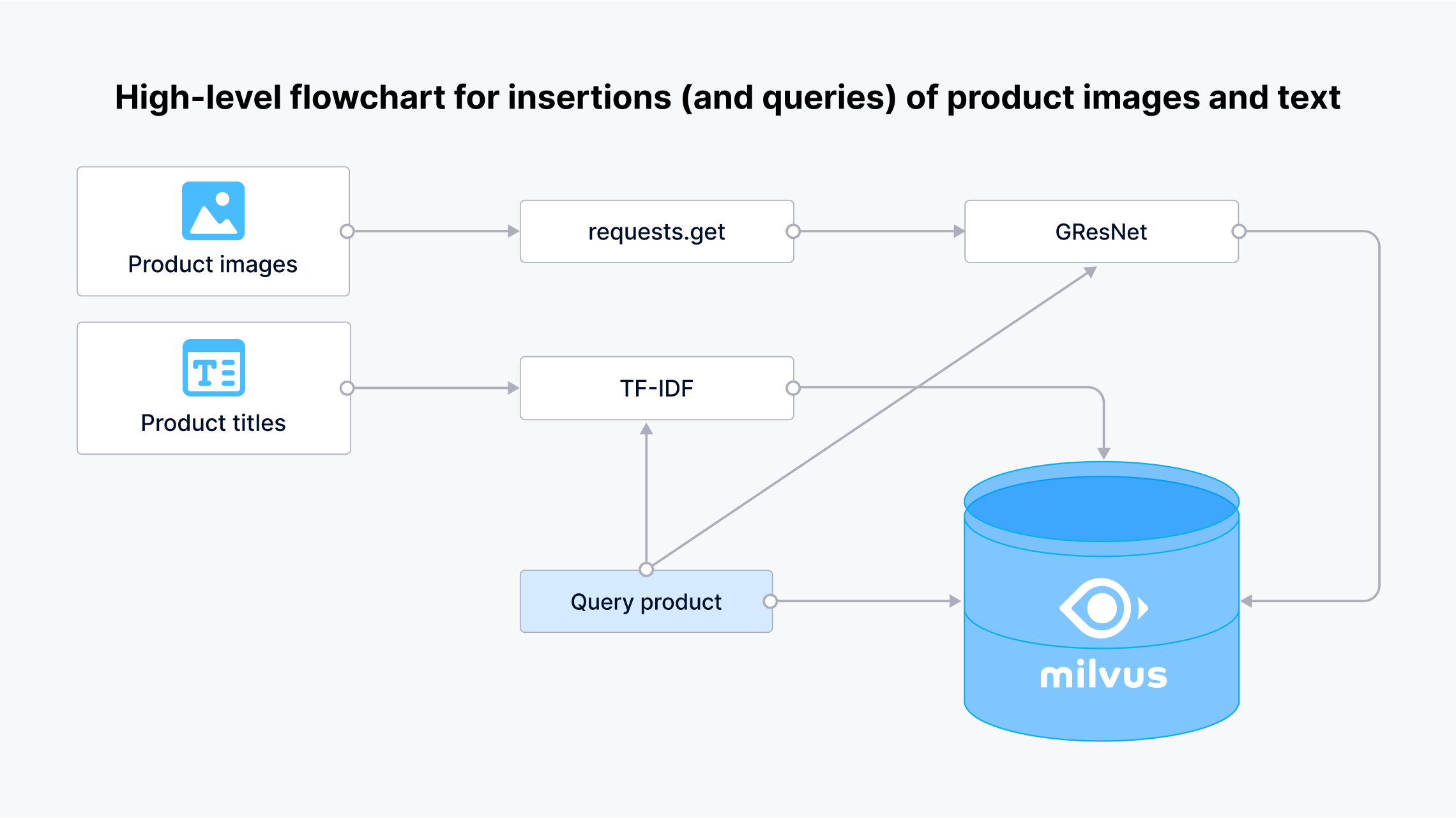 High-level flowchart for insertions (and queries) of product images and text
High-level flowchart for insertions (and queries) of product images and text
Wrapping up
In this post, we’ve explored the practical application of hybrid search in Milvus 2.4 through two hands-on examples. In the first example, we looked at how a single text can be represented by both sparse and dense vector fields, leveraging the strengths of each to enhance search capabilities. In the second example, we demonstrated how different components of unstructured data, specifically a product, can be represented as separate vectors—dense vectors for images and sparse vectors for text descriptions.
This approach of combining text and images will be very common moving forward, but we’re not limited to these two modalities. It’s easy to imagine several modalities of data stored in different formats, with each format occurring in a different column in the vector database.
 Frank Liu
Frank LiuFrank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai and worked as an ML engineer at Yahoo in San Francisco. In his free time, Frank enjoys playing chess, swimming, and powerlifting. Frank holds MS and BS degrees in Electrical Engineering from Stanford University.
- Sparse Vectors Recap
- How Hybrid Search Works in Milvus
- Hybrid Search Example with Text
- Beyond Single-Modality Search
- Wrapping up
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Raft or not? The Best Solution to Data Consistency in Cloud-native Databases
Explain why consensus-based algorithms like Paxos and Raft are not the silver bullet and propose a solution to consensus-based replication.

Getting Started with ScaNN
Google’s ScaNN is a library for ANNS. This guide walks you you through implementing ScaNN and demonstrate how to integrate it with Milvus.

What is Voyager?
Voyager is an Approximate Nearest Neighbor (ANN) search library optimized for high-dimensional vector data.