




Advanced Querying Techniques in Vector Databases
Vector databases enhance AI apps with advanced querying techniques like ANN, multivector, and range searches, improving data retrieval speed and accuracy.
Read the entire series
- Raft or not? The Best Solution to Data Consistency in Cloud-native Databases
- Understanding Faiss (Facebook AI Similarity Search)
- Information Retrieval Metrics
- Advanced Querying Techniques in Vector Databases
- Popular Machine-learning Algorithms Behind Vector Searches
- Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
- Ranking Models: What Are They and When to Use Them?
- Navigating the Nuances of Lexical and Semantic Search with Zilliz
- Enhancing Efficiency in Vector Searches with Binary Quantization and Milvus
- Model Providers: Open Source vs. Closed-Source
- Embedding and Querying Multilingual Languages with Milvus
- An Ultimate Guide to Vectorizing and Querying Structured Data
- Understanding HNSWlib: A Graph-based Library for Fast Approximate Nearest Neighbor Search
- What is ScaNN (Scalable Nearest Neighbors)?
- Getting Started with ScaNN
- Next-Gen Retrieval: How Cross-Encoders and Sparse Matrix Factorization Redefine k-NN Search
- What is Voyager?
- What is Annoy?
Introduction
Vector databases play a pivotal role in modern AI and machine learning workflows due to their ability to manage and query high-dimensional vector data. This ability enables speedy and accurate similarity searches, essential for various AI applications, from personalized recommendations and image recognition to natural language processing. By facilitating these operations at scale, vector databases significantly enhance the performance and effectiveness of AI applications, making them indispensable in handling high-dimensional data in an era where speed and accuracy are essential.
Advanced querying techniques significantly enhance the utility of vector databases in AI by improving data retrieval performance. Techniques like multivector queries, nearest-neighbor searches, and scalar data filtering allow for targeted, efficient searches that directly impact the accuracy and effectiveness of AI applications.
Vector Database Fundamentals
A vector database stores data in high-dimensional vectors, a mathematical representation of unstructured data that captures that object's "semantic meaning" within the learned vector space of all things learned by the foundational model. Developers then use these embeddings for similarity search, clustering, and other data retrieval tasks. At a close glance, a vector is an array of numerical values expressing a floating point's location along several dimensions and might look something like this:
Embeddings: [array([-3.09392996e-02, -1.80662833e-02, 1.34775648e-02, 2.77156215e-02,
-4.86349640e-03, -3.12581174e-02, -3.55921760e-02, 5.76934684e-03,
2.80773244e-03, 1.35783911e-01, 3.59678417e-02, 6.17732145e-02,
...
-4.61330153e-02, -4.85207550e-02, 3.13997865e-02, 7.82178566e-02,
-4.75336798e-02, 5.21207601e-02, 9.04406682e-02, -5.36676683e-02],
dtype=float32)]
Dim: 384 (384,)
This example shows a portion of the array of numerical values with 384 dimensions.
Because these vector embeddings contain the semantic meaning of an object, vectors that are clustered together are similar and likely relevant to each other. With this, various use cases have sprung up around vector search (also known as semantic similarity search) making it one of the hottest capabilities every database is keen to adopt. Although the process may seem straightforward, support vector embeddings at first glance—store, index, query—are more complex than they appear.
Advanced Vector Querying Techniques Overview
Advanced querying techniques unlock possibilities for handling complex data retrieval needs. These techniques not only enhance the quality of vector search results but also offer better performance for retrieving data with complex queries. Let’s explore some of these techniques and their real-world applications.
Approximate Nearest Neighbor (ANN) Search
Comparing every vector in vector space until k exact matches appear would be time-consuming, especially for large datasets with high-dimensional vectors. Instead, we perform an approximate search for better performance. To do this, you must build an index beforehand. There are generally four types of vector search algorithms:
Hash-based indexing (e.g., Locality-sensitive hashing)
Tree-based indexing (e.g., ANNOY)
Cluster indexing (e.g., product quantization)
Graph-based indexing (e.g., HNSW, CAGRA)
Different algorithms work better for varying types of vector data, but they all help speed up the vector search process at the cost of a bit of accuracy/recall.
Large Language Models (LLMs) often need to improve their grasping of the underlying intent behind user queries, yielding irrelevant results. However, envision a situation where a company integrates its internal documents into vectors and stores them within a vector database. This setup enables employees to search through documents using ANN queries. The vector database retrieves the closest data embeddings to the employee's query embedding, which are then passed to the LLM as a prompt. The LLM generates a human-like text answer based on the company's data, ensuring relevance. This process, known as Retrieval Augmented Generation (RAG), significantly enhances internal search relevance and mitigates AI hallucinations by incorporating a semantic understanding of the company's documents.
Multivector Queries
Multivector queries extend the query capabilities of vector databases by allowing searches to be performed using multiple vectors simultaneously. In most cases, multivector queries are more efficient than performing single-vector queries because the latency is much lower than searching against individual single-vector queries. Other than that, multivector queries could also offer better query results.
In e-commerce websites, for example, multivector queries can dramatically improve product recommendation systems. By using multiple vectors representing different aspects of user preferences (e.g., brand preference, price range, product category, past purchasing history), these queries can retrieve products that more closely match the user's complex preferences, enhancing the shopping experience and potentially increasing conversion rates.
Range Queries
Range queries allow users to retrieve all items within a specified distance or similarity threshold from a query vector. This technique is important for applications that focus on finding a set of items that meet a minimum similarity requirement rather than identifying the single most similar item.
Drug discovery presents immense challenges, spanning from molecules as small as tens of atoms to large biologics comprising tens of thousands of atoms. Developers can leverage machine learning to vectorize each molecule to create a functional representation tailored to its intended purpose, such as targeting specific diseases or symptoms.
Within this framework, range search functionality is proper. Unlike conventional top-k searches, range search extends its reach by identifying all vectors (molecules) within a specified distance from the target, presenting a comprehensive list of relevant candidates rather than a fixed number. This feature proves indispensable in drug discovery and finds applicability in diverse domains like fraud detection and cybersecurity.
Optimizing Queries for Performance
Optimizing advanced queries in vector databases is crucial for achieving high performance and accuracy in AI and machine learning applications. This optimization ensures that the system can handle large volumes of high-dimensional data efficiently, making real-time and relevant data retrieval possible. Below are some best practices for optimizing these queries.
Indexing Strategies
Index plays an important role in speeding up your query, especially with ANN. No index types are perfect for every case. Indexes (e.g., tree-based, hash-based, or graph-based) are optimized for different queries and data characteristics. For instance, tree-based indexes like KD-trees may be suitable for low-dimensional data, while graph-based indexes perform better for high-dimensional data.
Query Optimization Strategies
Partitioning
Partition your data strategically to improve index efficiency. Techniques like clustering can group similar vectors, reducing the search space for queries and improving response times.
Use Approximate Search
For many applications, exact nearest-neighbor searches are unnecessary, and approximate results can significantly reduce query times with a marginal impact on accuracy. ANN algorithms like HNSW (Hierarchical Navigable Small World) or Annoy are designed for this purpose.
Balancing Speed vs Accuracy
Picking an Index and Tuning the Index Parameters
Vector Databases should support more than just one index no matter how simple or popular an Index may be to allow users to pick the Index that best suits their needs. Once you have chosen your index, then you tune the index parameters, followed by tuning the search parameters.
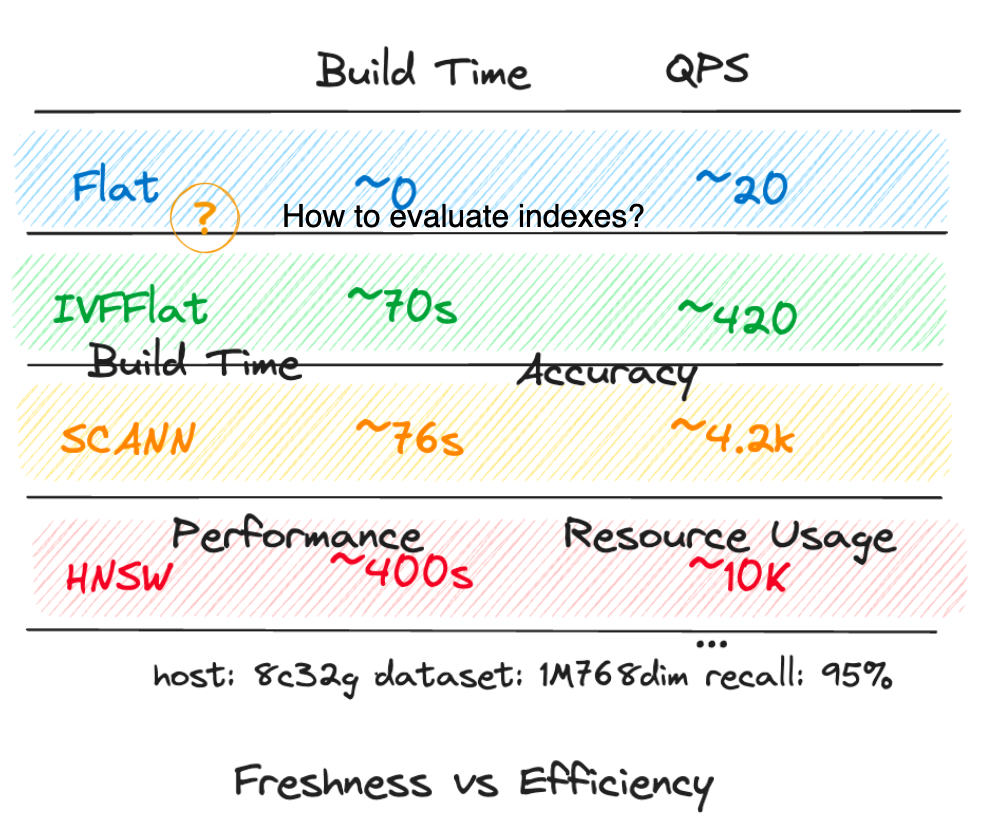
Most vector database systems and ANN libraries offer parameters that control the trade-off between search speed and accuracy (e.g., search depth or the number of trees in a forest). Experimenting with these parameters can help find the optimal balance for your application needs.
Early Stopping Criteria
Implement early stopping in your search algorithms to halt the search process once a "good enough" result is found, reducing the computational overhead of exhaustive searches.
Quality of Service (QoS) Levels
Define different QoS levels for different types of queries or user requests. For example, background tasks might tolerate slower, more accurate searches, whereas user-facing queries might prioritize speed.
Working with Advanced Queries
Performing advanced queries will be dependent on which vector databases you use. For more details, it is better to refer to its official documentation. We will use a managed Milvus vector database on Zilliz in this example.
res = client.search(
collection_name=COLLECTION_NAME,
data=[data["rows"][0]["title_vector"]],
filter='publication not in ["Towards Data Science", "Personal Growth"]',
output_fields=["title", "publication"],
limit=5
)
print(res)
The query above will perform a query search with filters that use ANN. In the example, we filter out publications not “Towards Data Science” and “Personal Growth”.
Challenges and Solutions
Implementing advanced queries in vector databases presents unique challenges. Here are some common challenges and practical solutions.
Scalability
Maintaining query performance becomes a challenge for big data optimization as datasets grow. Fortunately, there are various techniques to make vector databases scalable. One of the solutions is to use database partitions that will distribute the load and leverage parallel processing. As your vector database needs to be distributed, it is better to use an established cloud computing platform, such as Google Cloud, AWS, or even Zilliz Cloud to manage your database.
Dimensionality Reduction
High-dimensional data can lead to the "curse of dimensionality," where the performance of similarity searches degrades. Using dimensionality reduction techniques like PCA (Principal Component Analysis) or autoencoders can help by reducing the dataset's dimensions without losing significant information, making indexing more effective.
Dynamic Data
Keeping the vector database updated with new data without compromising query performance. To solve this problem, implement incremental indexing strategies where new vectors are periodically added to the index without requiring a complete rebuild.
Future Trends in Querying
The future of querying in vector databases will be influenced by advancements in AI, mainly through integrating large language models. Enhanced by emerging technologies, these advancements promise faster, more efficient searches and real-time analytics on vast datasets. The synergy between LLMs and vector databases will lead to more intuitive, powerful data exploration tools, revolutionizing how we interact and extract value from data.
Conclusion
Advanced querying techniques are fundamental to unlocking the full potential of vector databases. By utilizing these querying capabilities, organizations can delve deeper into their data, uncovering insights that were previously out of reach. These techniques enable precise, efficient, and context-aware data retrieval. They cater to the nuanced demands of modern AI and machine learning workflows, where the ability to quickly and accurately process and analyze vast volumes of high-dimensional data can significantly influence outcomes.
Pursuing knowledge and skill development in advanced querying techniques in this rapidly evolving landscape should be a continuous endeavor. Encouraging ongoing learning and experimentation is not just about keeping pace with technological advancements; it's about leading the charge in pioneering novel solutions to complex problems. By fostering a culture of curiosity and innovation, individuals and organizations can leverage advanced queries as tools and as catalysts for transformation in their data-driven projects. text

- Introduction
- Vector Database Fundamentals
- Advanced Vector Querying Techniques Overview
- Optimizing Queries for Performance
- Working with Advanced Queries
- Challenges and Solutions
- Future Trends in Querying
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Understanding Faiss (Facebook AI Similarity Search)
Faiss (Facebook AI similarity search) is an open-source library for efficient similarity search of unstructured data and clustering of dense vectors.

Information Retrieval Metrics
Understand Information Retrieval Metrics and learn how to apply these metrics to evaluate your systems.

Enhancing Efficiency in Vector Searches with Binary Quantization and Milvus
Binary quantization represents a transformative approach to managing and searching vector data within Milvus, offering significant enhancements in both performance and efficiency. By simplifying vector representations into binary codes, this method leverages the speed of bitwise operations, substantially accelerating search operations and reducing computational overhead.