




What is Voyager?
Voyager is an Approximate Nearest Neighbor (ANN) search library optimized for high-dimensional vector data.
Read the entire series
- Raft or not? The Best Solution to Data Consistency in Cloud-native Databases
- Understanding Faiss (Facebook AI Similarity Search)
- Information Retrieval Metrics
- Advanced Querying Techniques in Vector Databases
- Popular Machine-learning Algorithms Behind Vector Searches
- Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
- Ranking Models: What Are They and When to Use Them?
- Navigating the Nuances of Lexical and Semantic Search with Zilliz
- Enhancing Efficiency in Vector Searches with Binary Quantization and Milvus
- Model Providers: Open Source vs. Closed-Source
- Embedding and Querying Multilingual Languages with Milvus
- An Ultimate Guide to Vectorizing and Querying Structured Data
- Understanding HNSWlib: A Graph-based Library for Fast Approximate Nearest Neighbor Search
- What is ScaNN (Scalable Nearest Neighbors)?
- Getting Started with ScaNN
- Next-Gen Retrieval: How Cross-Encoders and Sparse Matrix Factorization Redefine k-NN Search
- What is Voyager?
- What is Annoy?
Introduction
Modern AI systems rely on Nearest Neighbor Search (NNS) and vector similarity search to find patterns and relationships within vast datasets. NNS identifies the closest data points to a given query, enabling applications like recommendation engines, search platforms, and AI-driven exploration tools to provide relevant and personalized results. By representing data as high-dimensional vectors, vector similarity search measures the closeness of these vectors using mathematical metrics such as cosine similarity or Euclidean distance.
NNS plays a critical role in AI applications by allowing systems to efficiently compare and retrieve similar items. For example, a recommendation system can identify songs with features similar to a user’s listening history, while an image search engine can retrieve visually related results. The speed and accuracy of these searches are essential for delivering meaningful user experiences in real time.
To address the growing demands of large-scale and real-time vector search, Spotify developed Voyager, an open-source ANN library designed to optimize search performance. Voyager builds on the Hierarchical Navigable Small World (HNSW) algorithm and introduces features like dynamic indexing and multithreading to support scalable and adaptive AI systems. This article will explore Voyager’s architecture, functionality, and role in advancing vector similarity search.
What is Voyager?
Voyager is an Approximate Nearest Neighbor (ANN) search library optimized for high-dimensional vector data. It organizes datasets into a graph-based structure, enabling fast and efficient similarity searches. Designed to support dynamic and real-time systems, Voyager is capable of handling the evolving needs of modern AI-driven applications.
Why Was Voyager Built?
Voyager was developed to address specific challenges encountered with existing ANN libraries, particularly Annoy, which Spotify previously relied on. Annoy uses a tree-based indexing approach, which works well for static datasets but struggles frequently in environments where data changes. Annoy requires a complete rebuild of the index each time new data is added, leading to inefficiencies and operational challenges.
Additionally, as Spotify’s datasets grew into billions of vectors, Annoy’s memory usage and slower query times became bottlenecks. Spotify also explored other libraries, such as HNSWlib, which implemented the HNSW algorithm. While HNSWlib offered better performance and accuracy, it lacked production-ready features like fault tolerance and multi-language support.
Voyager was built to overcome these challenges. Let’s see how Voyager functions.
How Voyager Works
Voyager achieves its efficiency and flexibility through a combination of graph-based navigation, dynamic indexing, and multithreaded operations. These features allow it to handle large-scale, high-dimensional datasets while delivering fast and accurate results.
Core Mechanism: Graph-Based Navigation
At the heart of Voyager lies the HNSW algorithm, which organizes vectors into a graph structure. Each node in the graph represents a data point, and edges connect nodes based on their proximity in vector space. The graph is hierarchical, with layers that balance broad exploration and precise refinement.
Upper Layers: Sparse connections allow for quick exploration of the dataset, narrowing down candidates efficiently.
Lower Layers: Dense connections facilitate precise searches within smaller subsets of data points.
The following diagram illustrates the layered structure of the HNSW graph:
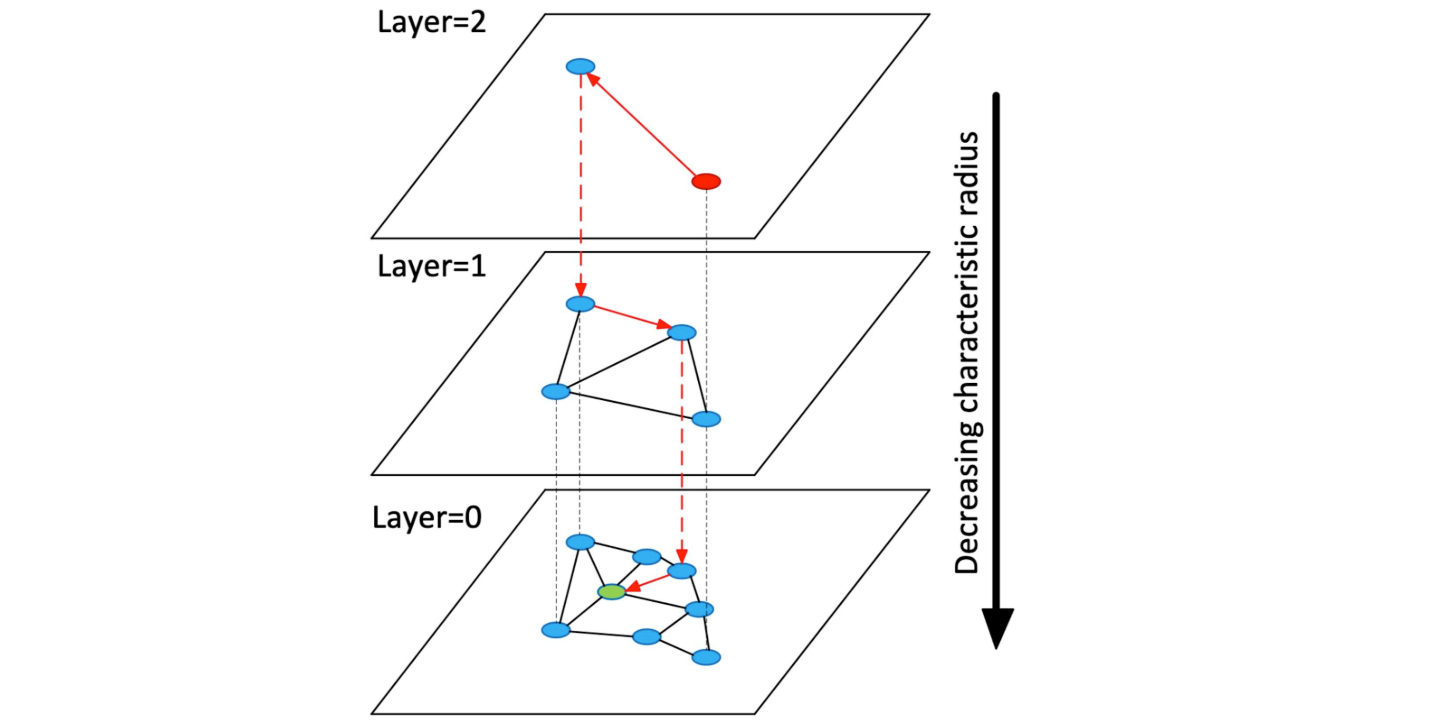 Figure- A diagram from the HNSW paper that visualizes the layered graph concept
Figure- A diagram from the HNSW paper that visualizes the layered graph concept
Figure: A diagram from the HNSW paper that visualizes the layered graph concept. | Source
In the diagram, searches start at Layer 2, where fewer nodes are connected. This allows the algorithm to identify broad regions of relevance quickly. Then, more connections are evaluated to refine the candidates at Layer 1. Finally, at Layer 0, which contains the densest connections, the nearest neighbors are identified with high precision.
Consider a music streaming service recommending songs similar to a user’s favorite track. At Layer 2, the algorithm navigates through sparse connections, identifying broad categories like pop, rock, or classical, and directs the search to the relevant genre, such as pop. At Layer 1, more connections are evaluated within the pop category, narrowing down to subgenres like synth-pop, indie-pop, or electro-pop. This step focuses the search on tracks with stylistic features closer to the user’s query. Finally, at Layer 0, the algorithm performs precision matching, identifying specific songs within the synth-pop subgenre that share attributes like tempo, vocal style, or instrumentation with the query track. This multi-layered approach ensures both speed and accuracy in generating personalized recommendations.
This hierarchical approach ensures logarithmic complexity for searches, enabling Voyager to efficiently navigate large datasets.
Dynamic Indexing
Unlike static libraries, Voyager supports real-time additions, updates, and deletions of vectors. This feature eliminates the need for complete index rebuilds, ensuring that the system remains responsive even as data evolves. For example, in a music recommendation system, new songs can be added or old ones removed without disrupting the user experience.
Multithreaded Operations
Voyager leverages multithreading to enhance both indexing and querying performance. It achieves this by distributing tasks across multiple CPU cores, which accelerates processing times and increases throughput. This capability is essential for handling high query volumes in real-time environments.
Key Features of Voyager
Voyager includes several features that make it a reliable tool for vector search in modern AI applications.
Scalability
Voyager is designed to handle billions of vectors without compromising performance. It achieves this by using memory-efficient techniques, such as E4M3 8-bit floating-point representations, which reduce resource consumption while maintaining accuracy. This scalability makes Voyager suitable for enterprise-scale deployments.
Real-Time Updates
Dynamic indexing is one of Voyager’s key features, allowing systems to integrate new data or update existing entries without downtime. This capability is crucial for applications like recommendation engines, where data is constantly evolving.
High Accuracy
Despite using approximate methods, Voyager delivers high accuracy through hierarchical graph refinement. Developers can also adjust parameters to balance speed and recall, tailoring Voyager to specific application needs.
Production-Ready Design
Voyager incorporates fault-tolerant features, such as corruption detection for index files. Its cloud-compatible design supports stream-based I/O, simplifying deployment in distributed systems.
Optimized for CPU-Based Operations
Voyager is designed to operate efficiently on CPUs, foregoing GPU acceleration to prioritize simplicity and broad compatibility. This approach simplifies deployment, reduces dependencies on specialized hardware, and ensures that Voyager can be easily integrated into diverse environments.
Comparison with Other Libraries
Voyager exists within a growing ecosystem of ANN libraries. Each has strengths and limitations that make it suitable for specific use cases.
Voyager vs. Annoy
Annoy was one of the earliest libraries Spotify used for ANN search. It relies on tree-based indexing, which is effective for static datasets but requires full index rebuilds for updates. Voyager addresses this limitation with dynamic indexing, making it better suited for real-time and dynamic applications. Additionally, Voyager outperforms Annoy in terms of speed and accuracy, especially as datasets grow larger.
Voyager vs. hnswlib
Hnswlib is a well-known implementation of the HNSW algorithm. While it offers excellent performance and accuracy, it lacks production-grade features like multi-language support and fault tolerance. Voyager builds on hnswlib by adding these enhancements, making it a more robust and versatile tool for real-world deployments.
Voyager vs. ScaNN
ScaNN, short for Scalable Nearest Neighbors, excels in inner-product search but does not support dynamic datasets. This limitation makes it less suitable for real-time systems that require frequent updates. Voyager’s flexibility and support for evolving data make it a better choice for dynamic environments.
Voyager vs. Faiss
Faiss is optimized for GPU-accelerated batch processing, making it ideal for offline tasks like training or preprocessing large datasets. In contrast, Voyager is designed for real-time applications, with CPU-based operations that allow for dynamic indexing and low-latency responses.
These comparisons show Voyager excels as a vector search library, but let’s see how it compares to vector databases, which address additional needs beyond search.
Vector Search Libraries vs. Vector Databases
Vector search libraries and vector databases serve different purposes in managing and searching vector data. While libraries like Voyager focus on speed and efficient in-memory operations, vector databases offer additional features such as persistent storage, distributed scalability, and advanced querying. Deciding between the two depends on the specific needs of the application.
Vector Search Libraries
Vector search libraries are designed for rapid querying and dynamic updates, making them ideal for real-time applications where data changes frequently. They operate entirely in memory, which allows for low-latency responses but limits their ability to handle long-term data storage or complex workloads. For example, libraries like Voyager excel in recommendation engines or personalized search platforms where datasets are updated in real time.
However, these libraries do not provide persistent storage or built-in support for distributed systems, meaning users must manage the infrastructure and data lifecycle manually. This makes libraries well-suited for scenarios that prioritize speed over data permanence or scale.
Vector Databases
Vector databases extend the functionality of libraries by incorporating persistent storage, distributed architectures, and query optimization for large-scale datasets. They are built to manage vector data over time, ensuring durability and accessibility across system restarts. In addition to similarity searches, vector databases often support hybrid queries that combine vector-based retrieval with structured metadata filtering.
Milvus, an open-source vector database created by Zilliz, is a primary example of purpose-built vector databases. It is designed to manage large-scale vector datasets and supports horizontal scaling to handle growing data volumes and query demands. Milvus enables hybrid searches, allowing users to combine similarity searches with filtering on additional attributes, such as timestamps or categories. It also supports hybrid full-text search and vector searches. This capability makes it suitable for e-commerce recommendations, image retrieval, and video analytics applications.
Zilliz also offers Zilliz Cloud, a managed vector database service powered by Milvus that simplifies deployment and maintenance. Zilliz Cloud provides all the functionality of Milvus while eliminating the operational overhead associated with managing infrastructure. This makes it a good option for organizations seeking to scale their vector search capabilities without the need to handle backend complexities.
When to Use Each
Choosing between a vector search library and a vector database depends on the specific requirements of the application:
Use a library like Voyager for applications that require rapid querying and real-time updates. These are ideal for lightweight, in-memory operations where datasets change frequently and long-term storage is not a priority.
Opt for a database like Milvus when persistent storage, distributed scalability, and advanced query capabilities are necessary. Vector databases are well-suited for enterprise use cases involving large datasets, hybrid search needs, or applications requiring high availability and scalability.
Conclusion
Voyager provides an effective solution for Approximate Nearest Neighbor (ANN) search, designed to meet the needs of real-time, high-dimensional data applications. Its dynamic indexing, graph-based navigation, and scalability make it a reliable tool for managing evolving datasets with speed and precision.
Libraries like Voyager are well-suited for lightweight, real-time applications that prioritize fast querying. However, vector databases like Milvus offer a comprehensive alternative when persistent storage, scalability, and advanced search capabilities are required. Together, these tools address a wide range of vector search requirements, supporting the growing demands of modern AI applications.
Further Resources

- Introduction
- What is Voyager?
- Why Was Voyager Built?
- How Voyager Works
- Key Features of Voyager
- Comparison with Other Libraries
- Vector Search Libraries vs. Vector Databases
- Conclusion
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Understanding Faiss (Facebook AI Similarity Search)
Faiss (Facebook AI similarity search) is an open-source library for efficient similarity search of unstructured data and clustering of dense vectors.

Model Providers: Open Source vs. Closed-Source
In this article, we will examine the different providers, their pros and cons, and the implications of each. By the end, you will have the knowledge and understanding to make an informed choice between open-source and closed-source model providers.

Understanding HNSWlib: A Graph-based Library for Fast Approximate Nearest Neighbor Search
HNSWlib is an open-source C++ and Python library implementation of the HNSW algorithm, which is used for fast approximate nearest neighbor search.