




What Are Rerankers and How Do They Enhance Information Retrieval?
Rerankers are specialized components in information retrieval systems that perform a crucial second-stage evaluation of search results.
Read the entire series
- What is Information Retrieval?
- Information Retrieval Metrics
- Search Still Matters: Enhancing Information Retrieval with Generative AI and Vector Databases
- Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
- What Are Rerankers and How Do They Enhance Information Retrieval?
- Understanding Boolean Retrieval Models in Information Retrieval
- Will A GenAI Like ChatGPT Replace Google Search?
- The Evolution of Search: From Traditional Keyword Matching to Vector Search and Generative AI
- What is a Knowledge Graph (KG)?
Introduction
The need for more accurate and relevant search results has led to significant advancements in information retrieval and machine learning. Among these innovations are rerankers, which have emerged as a powerful tool for refining search outcomes and improving the quality of recommendations. This article will explore the concepts behind rerankers and demonstrate how to integrate rerankers with Milvus, a widely adopted open-source vector database, to enhance search and Retrieval Augmented Generation (RAG) applications.
What Are Rerankers and Why Are They Important?
Rerankers are specialized components in information retrieval systems that perform a crucial second-stage evaluation of search results. After an initial set of potentially relevant items is retrieved, rerankers step in to reassess and reorder these results, aiming to push the most relevant items to the top of the list.
The importance of rerankers lies in their ability to refine initial search results, addressing the limitations of traditional one-stage retrieval methods. By applying more sophisticated algorithms, rerankers can capture nuanced relevance signals, handle complex queries more effectively, and ultimately provide more accurate and contextually appropriate results. To understand why rerankers are essential, it's important first to examine how one-stage retrieval works and its inherent limitations.
Traditional One-stage Retrieval and Its Limitations
Traditional one-stage retrieval usually refers to information retrieval systems where the retrieval process is completed in a single step. In this approach, the system directly retrieves the final set of relevant documents or items from a large corpus based on their relevance to a given query without any intermediate stages.
Such one-stage systems rely on algorithms that can quickly scan through massive datasets and return a ranked list of relevant documents. The most widely used one-stage retrieval techniques include TF-IDF, BM25, and vector similarity retrieval. Let's break them down and see how they work.
TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDF evaluates the importance of a word in a document relative to a corpus. It combines two metrics: term frequency (TF), which measures how frequently a term appears in a document, and inverse document frequency (IDF), which measures how important a term is across the corpus. The TF-IDF score helps identify terms significant to a particular document but not common across all documents. This technique is effective for keyword-based retrieval (also known as exact keyword search).
BM25 (Best Matching 25)
BM25 is an enhancement of TF-IDF and belongs to the family of probabilistic retrieval models. It addresses some TF-IDF's limitations by considering term frequency saturation and document length normalization. It uses a probabilistic framework to rank documents based on the query terms' occurrence and distribution across the documents. This model is known for its robustness and effectiveness in handling various types of queries, making it a popular choice in information retrieval systems.
Vector-Based Retrieval (also known as Vector Similarity Search)
Vector-based retrieval or vector similarity search retrieves relevant documents as numerical representations in a high-dimensional space called vector embeddings. These vectors capture various semantic aspects of the data. Similarity measures, such as cosine similarity or Euclidean distance, are then used to compare the query vector with document vectors to retrieve relevant documents. This method allows for more sophisticated retrieval strategies. It is particularly effective when combined with modern machine learning techniques, such as neural network-based models like learned sparse models and dense embedding models.
Limitations of One-Stage Retrieval Systems
Even though one-stage retrieval methods can be effective, they present several challenges.
Initial Relevance but Poor Ranking: In the one-stage retrieval, the system might retrieve relevant documents but not necessarily rank them according to their true relevance to the query. This can happen because the first stage often prioritizes speed over precision. A reranker can analyze the top N documents more thoroughly, using deeper semantic analysis to reorder them, ensuring the most relevant documents appear at the top of the results.
Reducing Noise in Retrieved Results: The one-stage retrieval might introduce some noise—documents that are somewhat relevant but not entirely aligned with the user's intent. A reranker can sift through these and push less relevant documents down the list or remove them entirely, leading to a more focused result.
Handling Complex Queries: Queries that involve nuanced understanding or multiple facets can be challenging for a one-stage retrieval process, which might miss out on certain aspects. This issue is mostly pronounced in traditional TF-IDF and BM25 techniques rather than vector-based retrieval systems. A reranker, particularly one based on deep learning models, can better capture the complex relationships within the query and between the query and documents, thus improving the overall retrieval performance.
As you have seen, we can address most limitations by incorporating a reranker as the second stage in the retrieval process. This approach is because rerankers enhance the performance of search systems by directly comparing the query and the retrieved document. Let's take a deep dive and see closely how these rerankers work.
How do Rerankers Work?
The core idea behind re-ranking is to initially retrieve a broad set of potentially relevant documents and then refine this set to prioritize the most relevant results. Take a look at the diagram below that will serve as an example of a vector-based retrieval and a reranking pipeline:
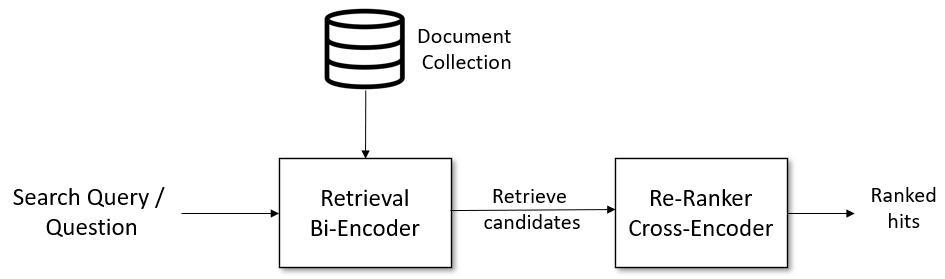 Fig 1- Retrieval & re-ranking pipeline (Image by author)
Fig 1- Retrieval & re-ranking pipeline (Image by author)
In the above Retrieve & Re-Ranking pipeline, the Document Collection represents the large corpus of documents from which the system can access and retrieve content. The Retrieval Bi-Encoder is a neural network model that encodes the search query and documents into dense vectors. The Retrieve Candidates component uses the encoded query and document representations to search the document collection and retrieve the most relevant candidate documents. The Re-Ranker Cross-Encoder is a specialized machine learning model that performs a nuanced, contextual evaluation of the relationship between the search query and each candidate document. Finally, the Ranked Hits component presents a ranked list of the most relevant search results based on the relevance scores assigned by the cross-encoder.
Let’s dive deeper into how the pipeline works:
Steps Involved in Re-Ranking
Search Query / Question:
- The process starts with a user entering a search query or question into the system. This query expresses the user's attempt to find specific information within a large collection of documents in natural language.
Retrieval Bi-Encoder:
- Query and Document Encoding: A bi-encoder model converts the search query into a dense vector. The document vectors for the entire collection are also pre-computed using the same bi-encoder model and stored offline in a vector database like Milvus.
Retrieve Candidates:
- Initial Retrieval: A vector search component computes the similarity between the encoded query vector and the pre-computed document vectors. Based on the similarity scores, it retrieves a set of candidate documents that are likely to be relevant. These documents serve as the input for the re-ranking stage.
Re-Ranker Cross-Encoder:
Contextual Evaluation: The cross-encoder model evaluates each query-document pair by considering the full context of the query and the document. This involves a deeper, more detailed analysis than the initial retrieval step.
Re-Ranking: The cross-encoder assigns new relevance scores to the candidate documents based on this detailed evaluation. The documents are then re-ordered to reflect their true relevance to the query.
Ranked Hits: The system presents the user with a list of documents. The documents are ordered by relevance, with the most pertinent results appearing at the top, providing the user with the most useful information.
The example we covered is intended to help you understand how a reranker works, but not all rerankers are the same.
Types of Rerankers
Rerankers fall into two main types: score-based rerankers and neural rerankers. Let's take a look at how they differ from each other.
Score-based Rerankers
Score-based rerankers refine the initial search results by recalculating their importance using numerical equations, thereby reordering the results based on updated scores. Two common approaches are:
Weighted Reranker: This method recalculates the score by combining weighted scores of the same item from different retrieval paths, such as dense and sparse vector retrieval. The final score reflects the significance of each path's contribution.
Reciprocal Rank Fusion (RRF): RRF also integrates results from multiple retrieval paths. It assigns each item an inverted rank score from the initial search results and sums these scores to create a new ranking. For example, if an item ranks 2nd in one path and 5th in another, its final score is ½ + ⅕, which is then used to determine its new position in the results.
Neural Rerankers
Neural rerankers leverage deep learning models to capture semantic relationships and contextual information more effectively than traditional methods. Key approaches include:
BERT-based Rerankers: BERT (Bidirectional Encoder Representations from Transformers) is a pre-trained language model that understands the context of words in a sentence by looking at both the left and right sides. BERT-based rerankers fine-tune this model to understand the relationship between a query and a document. They evaluate the relevance of documents by considering the full context provided by the query and the document, leading to more accurate reranking.
Rerankers Trained from Large Language Models: Other transformer-based models, such as T5 (Text-to-Text Transfer Transformer) and GPT (Generative Pre-trained Transformer), are pre-trained LLM adapted for reranking tasks. They generate deep contextual embeddings that help accurately determine the relevance of documents.
Advantages and Disadvantages of Rerankers
While rerankers offer significant improvements in search quality, they also come with trade-offs you should consider when implementing them in real-world systems.
Reranker Advantages:
Improved Relevance: Rerankers significantly enhance the relevance of search results by considering more complex features and relationships.
Contextual Understanding: Especially with neural rerankers, systems can better understand the context and intent behind queries.
Adaptability: Many reranking models can be fine-tuned or adapted to specific domains or user preferences.
Reranker Disadvantages:
Increased Latency: The additional processing step increases the overall response time of the search system.
Computational Overhead: Rerankers, particularly neural models, are computationally expensive and require more resources.
Potential for Overfitting: If not correctly designed and trained, rerankers may overfit to specific patterns in the training data, potentially harming generalization.
Since you now have an in-depth understanding of how rerankers work, let's specialize and see how they improve Retrieval Augmented Generation (RAG).
How Do Rerankers Improve RAG?
Retrieval-augmented generation (RAG) is an approach in natural language processing that combines retrieving relevant documents from a knowledge base with using them to generate more accurate and contextually informed responses using large language models.
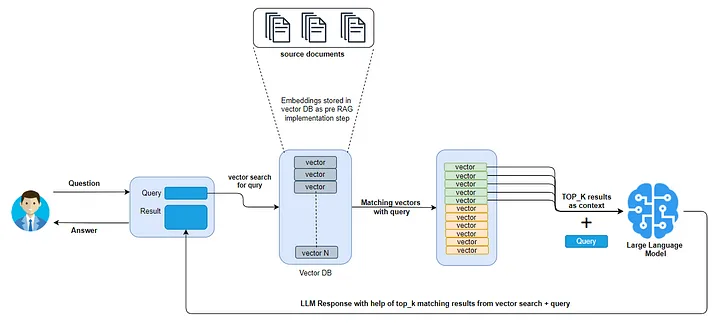 Fig 2- RAG process without reranking
Fig 2- RAG process without reranking
In a RAG system, a query is first encoded into a vector and searched within a vector database such as Milvus containing precomputed document vector embeddings. The database returns the top-k matching documents, which are then used as context by a large language model (LLM). The LLM generates a detailed response by combining the query with the retrieved documents, resulting in an accurate and contextually relevant answer. This approach works with small documents whose retrieved results can all fit in an LLM context window. However, when dealing with a large dataset, all the retrieved results cannot fit in the LLM's context window, leading to potential information loss and reduced response quality.
To address this issue, you should employ a reranker to refine and prioritize the top-k matching documents before they are fed into the LLM.
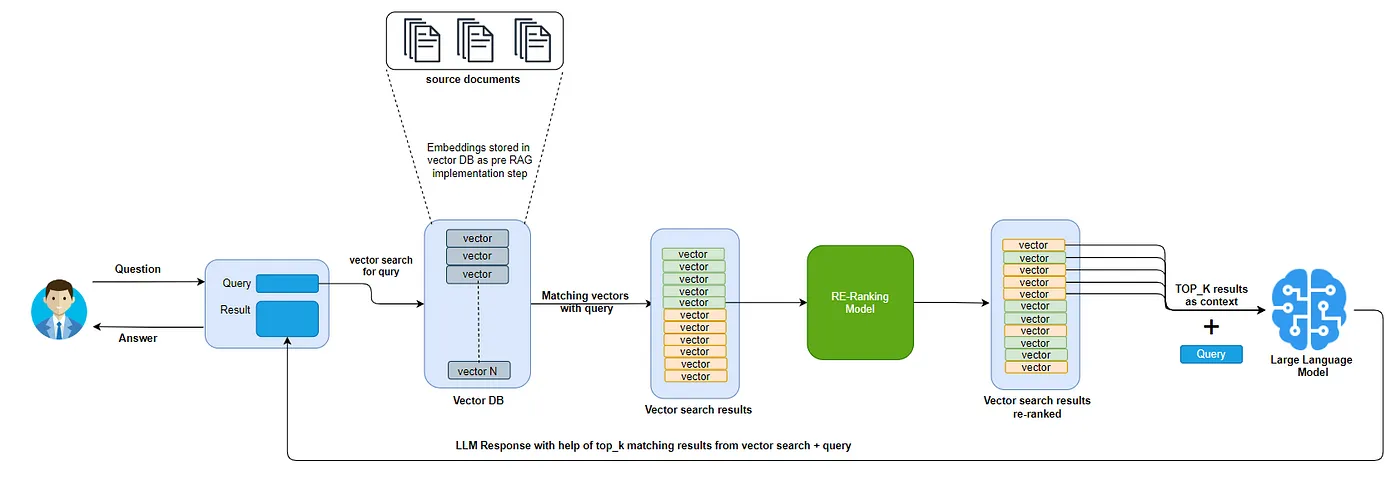 Fig 3- RAG process with reranking employed
Fig 3- RAG process with reranking employed
The reranker reassesses the initial set of retrieved documents and reorders them based on their relevance to the query, ensuring that only the most pertinent information is included within the LLM's context window. This step maximizes the use of the limited context space, enhancing the accuracy and coherence of the generated response.
For you to understand how rerankers improve RAG, let’s look at a practical example while using Milvus as the vector database:
Using a Reranker to Improve Search Results in a Milvus-Powered RAG System
Milvus is an open-source vector database designed specifically for handling billion-scale vector data. It facilitates the efficient storage, indexing, and retrieval of high-dimensional vector embeddings, which are essential for tasks such as similarity search, recommendation systems, Retrieval Augmented Generation(RAG), and more.
Milvus is particularly beneficial in a RAG system, where it retrieves documents highly related to a user query. This is crucial in the reranking process, as the effectiveness of rerankers depends on the quality of the initial retrieval. If the initial set of retrieved documents is low quality, even the best reranker might struggle to provide good results.
Milvus Integration with Popular Reranking Models
Milvus integrates with several advanced reranking models that refine the initial search results, ensuring higher relevance and accuracy. Here are some of the popular reranking models supported by Milvus:
Open Source Rerankers: Milvus integrates with a rich set of open-source cross-encoder models trained on BERT or other architecture neural networks, including
BAAI/bge-reranker-v2-m3,cross-encoder/ms-marco-MiniLM-L-6-v2andms-marco-MiniLM-L-6-v2.Cohere Reranker: Cohere rerankers use Cohere’s large language model to compute a score for the relevance of the query with each of the initial search results. These models require an API key to access and refine search results by understanding the semantic relationships between queries and documents.
Voyage rerankers: Voyage models, accessible via API, enhance the precision of search outcomes by considering multiple factors of relevance. They can easily integrate with vector databases such as Milvus.
Jina AI rerankers: Jina AI reranking models are optimized for fast response times in information retrieval applications. They use the JinaBERT architecture, a variant of the BERT architecture enhanced with a symmetric bidirectional variant of ALiBi. This architecture enables support for long text sequences. These models are available through an API and integrate seamlessly with Milvus.
To have a deep look at how to use these models, take a look at this guide.
In the following section, we will show you how to build the reranking stage with models supported by pymilvus[model] (the client library of milvus) and models not yet supported.
Step-by-Step Guide on Integrating Milvus With Reranking Models to Improve RAG Search Results
In this section, you will see how to build a Milvus-powered RAG pipeline and proceed to improve the retrieved search results returned by Milvus through reranking. You can also check this notebook for the complete code.
Setting Up the Environment
Begin by launching your Python IDE and installing the necessary libraries.
pip install pymilvus[model] torch transformers
The pymilvus library is for interacting with the Milvus vector database, torch for PyTorch functionalities, and transformers for providing the embedding and reranking models.
After installing the libraries, make sure you have a Milvus instance running on your computer. If you don’t have Milvus installed, follow this guide to install and run it. The environment is ready for coding after this.
Importing Necessary Packages
After installing the libraries in your environment, you need to import them into your project to call and use their functions.
# Import necessary packages
from pymilvus import MilvusClient, DataType
from pymilvus.model.dense import SentenceTransformerEmbeddingFunction
You will use MilvusClient to establish a connection with the Milvus server, DataType during the creation of the collection schema, and SentenceTransformerEmbeddingFunction to vectorize your documents.
Initializing the Milvus Client and Creating a Collection
After importing the libraries the next step is to connect with the Milvus server and create a collection in which you will later store your documents and their embeddings.
# Initialize Milvus client
client = MilvusClient(uri="./milvus.db")
collection_name = "reranking_collection"
# Drop collection if it exists
if client.has_collection(collection_name):
client.drop_collection(collection_name)
# Define the collection schema
schema = client.create_schema(
auto_id=True,
enable_dynamic_field=True,
)
# Add fields to schema
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=65535)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=384)
# Create the collection
client.create_collection(
collection_name=collection_name,
schema=schema,
description="Example collection for document search"
)
By initializing the client with a URI , you establish a connection to your Milvus instance, allowing you to interact with and perform operations to the vector database. The first operation is creating the collection using a specified schema. In the above code, the collection schema has three fields: id , text , and vector . The id field is an integer and serves as the primary key. The text field is a variable-length string, and the vector field is a float vector with 384 dimensions, which will store our document embeddings. The dimension should match the dimensions of the embedding model you are planning to use.
Creating an Index
After creating a collection, you need to create an index for it. This will help to highly improve the retrieval time.
# Create index before inserting data
index_params = [{
"field_name": "vector",
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128}
}]
client.create_index(collection_name, index_params)
print("New index created successfully.")
Here, you create an index on the vector field using the IVF_FLAT index type and L2 distance metric. The nlist parameter determines the number of clusters used in the indexing process, affecting search speed and accuracy.
Generating and Inserting Embeddings into Milvus
After creating an index, the next step is to prepare your documents and insert them and their embeddings into Milvus.
# Initialize the Sentence Transformer embedding function
ef = SentenceTransformerEmbeddingFunction(model_name="all-MiniLM-L6-v2")
# Data from which embeddings are to be generated
docs = [
"John McCarthy was a pioneer in the field of artificial intelligence. He coined the term 'artificial intelligence' in 1955.",
"The Dartmouth Conference, held in 1956, is widely considered the founding event of artificial intelligence as an academic discipline.",
"Alan Turing is often credited with laying the theoretical foundations for artificial intelligence with his work on the Turing machine.",
"In 1956, John McCarthy, along with Marvin Minsky, Nathaniel Rochester, and Claude Shannon, organized the Dartmouth Conference, which is considered the birth of AI.",
"Artificial intelligence (AI) was officially founded as an academic discipline in 1956 at the Dartmouth Conference organized by John McCarthy, Marvin Minsky, Nathaniel Rochester, and Claude Shannon. The conference is widely considered the birth of AI.",
]
# Generate embeddings
embeddings = ef.encode_documents(docs)
# Insert embeddings into Milvus
data = [
{"text": docs[i], "vector": embeddings[i].tolist()}
for i in range(len(embeddings))
]
client.insert(collection_name=collection_name, data=data)
In the above code, you initialize the embedding function using the all-MiniLM-L6-v2 model. You then define a list of documents and generate their embeddings. These embeddings, along with the corresponding text, are inserted into your Milvus collection.
Loading the Collection and Performing an Initial Search
Since you have the documents in Milvus, the next step is to load the collection, store them in memory, and query it.
# Load collection into memory
client.load_collection(collection_name)
# Perform a search
query = "Who were the organizers of the Dartmouth Conference in 1956?"
query_embedding = ef.encode_queries([query])[0]
search_params = {
"metric_type": "L2",
"params": {"nprobe": 10}
}
search_results = client.search(
collection_name=collection_name,
data=[query_embedding.tolist()],
anns_field="vector",
search_params=search_params,
limit=3,
output_fields=["text"]
)
# Print the search results
print("Initial Search Results:")
for hit in search_results[0]:
entity = hit['entity']
print(f"Text: {entity['text']}")
print(f"Distance: {hit['distance']}")
print("---")
The above code loads the collection into memory and performs a search using a query about the organizers of the Dartmouth Conference in 1956. It then generates an embedding for the query and searches the collection. Here are the initial search results. After reranking later, they will help us know whether the search results are improving.
 Fig 4- Initial results of querying Milvus before reranking
Fig 4- Initial results of querying Milvus before reranking
The search results are all relevant to the query, but as you can see, the first result does not talk about the organizers of the Dartmouth Conference in 1956. The second result does. Hence, we expect the reranker to switch the results and return the above second result as the first since it is the one that directly answers the query.
Reranking Search Results Using Milvus-Supported Reranker Models
Let us see how you can improve the results using the models we discussed earlier.
from pymilvus.model.reranker import BGERerankFunction
# Initialize the BGE rerank function
reranker = BGERerankFunction(model_name="BAAI/bge-reranker-v2-m3", device="cpu")
# Extract documents from search results
initial_docs = [result['entity']['text'] for result in search_results[0]]
reranked_results = reranker(query, initial_docs)
# Print reranked search results
print("nReranked Search Results:")
for i, doc in enumerate(reranked_results):
print(f"Rank {i + 1}: {doc}")
print("---")
In this code, you import the BGERerankFunction which will help you use the BGE models. Then, initialize the BGE reranker using the BAAI/bge-reranker-v2-m3 model. The code proceeds to extract the documents from the initial search results and use the reranker to reorder them based on their relevance to the query. Here are the results.
 Fig 5- Reranked results using BGE model
Fig 5- Reranked results using BGE model
The reranked results show that the model reranked the initial search results to prioritize the results that answered the query directly, as we expected.
Reranking Search Results Using Other Reranker Models
The model we used above can be called via PyMilvus model. Let’s look at how to achieve the same results with other models outside Milvus. Let’s use a cross-encoder model.
from transformers import BertTokenizer, BertForSequenceClassification
import torch
# Initialize reranking model
tokenizer = BertTokenizer.from_pretrained('cross-encoder/ms-marco-MiniLM-L-6-v2')
model = BertForSequenceClassification.from_pretrained('cross-encoder/ms-marco-MiniLM-L-6-v2')
def rerank(query, docs):
inputs = tokenizer([query] * len(docs), docs, return_tensors='pt', padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
scores = outputs.logits[:, 0]
ranked_indices = scores.argsort(descending=True).tolist()
return [docs[i] for i in ranked_indices]
# Rerank search results
initial_docs = [result['entity']['text'] for result in search_results[0]]
reranked_docs = rerank(query, initial_docs)
# Print reranked search results
print("nReranked Search Results:")
for i, doc in enumerate(reranked_docs):
print(f"Rank {i + 1}: {doc}")
print("---")
The above code initializes the cross-encoder model using cross-encoder/ms-marco-MiniLM-L-6-v2 . It then defines a rerank function that uses this model to evaluate the query and document pairs and rerank the documents based on their relevance scores. Here are the results.
Reranked Search Results:
Rank 1: In 1956, John McCarthy, along with Marvin Minsky, Nathaniel Rochester, and Claude Shannon, organized the Dartmouth Conference, which is considered the birth of AI.
Rank 2: Artificial intelligence (AI) was officially founded as an academic discipline in 1956 at the Dartmouth Conference organized by John McCarthy, Marvin Minsky, Nathaniel Rochester, and Claude Shannon. The conference is widely considered the birth of AI.
Rank 3: The Dartmouth Conference, held in 1956, is widely considered the founding event of artificial intelligence as an academic discipline.
The results are similar to those obtained using the Milvus-supported reranking models. This shows that you can improve the search results of your RAG applications by including a reranker in your pipeline. But is it always advisable to use a reranker?
When to Use a Reranker in Your RAG
Here are some situations where we recommend you use a reranker.
Complex Queries: Complex queries often involve multiple facets and require a deep understanding of context and semantics. Rerankers can reassess and prioritize documents that best capture the intricate details and relationships within the query, leading to more accurate and relevant responses.
High-Stakes Applications: In applications where the precision of the information is critical, such as in healthcare, legal advice, or technical support, the accuracy and reliability of the generated content are paramount. Rerankers enhance the relevance of the initial results, ensuring that the information used for generation is precise and trustworthy.
Ambiguous Queries: Ambiguous queries can have multiple interpretations, making it challenging for one-stage retrieval methods to identify the correct context. Rerankers can analyze the nuances of the query and prioritize documents that align closely with the likely intent, providing more coherent and contextually appropriate responses.
When Not to Use a Reranker in Your RAG
In the following scenarios, using a reranker is not advisable:
Simple Queries: For straightforward queries, initial retrieval methods like TF-IDF, BM25, or basic vector-based approaches often provide sufficiently accurate results. Adding a reranker in such cases might not significantly improve the results and could introduce unnecessary complexity and processing time.
Low-Stakes Applications: In applications where the precision of the response is not critical (e.g., casual queries, entertainment), the added computational overhead of rerankers might not be justified. Simple one-stage retrieval methods can offer a good balance of speed and relevance without reranking.
Real-Time Constraints: Rerankers add an extra layer of processing, which can increase response times. In scenarios where quick responses are essential, such as real-time chatbots or interactive applications, the latency introduced by reranking could negatively impact user experience. In such cases, prioritizing speed over the additional refinement of results is more beneficial.
Conclusion
Rerankers have significantly improved information retrieval by refining search results to provide more accurate and contextually appropriate outcomes. Integrating rerankers with a robust vector database like Milvus enhances the relevance and efficiency of search systems, particularly in complex applications such as Retrieval Augmented Generation (RAG).
Further Resources
 Denis Kuria
Denis KuriaDenis is a machine learning engineer who enjoys writing guides to help other developers. He has a bachelor's in computer science and loves hiking and exploring the world.
- Introduction
- What Are Rerankers and Why Are They Important?
- Traditional One-stage Retrieval and Its Limitations
- How do Rerankers Work?
- Types of Rerankers
- Advantages and Disadvantages of Rerankers
- How Do Rerankers Improve RAG?
- Using a Reranker to Improve Search Results in a Milvus-Powered RAG System
- Step-by-Step Guide on Integrating Milvus With Reranking Models to Improve RAG Search Results
- When to Use a Reranker in Your RAG
- When Not to Use a Reranker in Your RAG
- Conclusion
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

What is Information Retrieval?
Information retrieval (IR) is the process of efficiently retrieving relevant information from large collections of unstructured or semi-structured data.

Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
Milvus enables hybrid sparse and dense vector search and multi-vector search capabilities, simplifying the vectorization and search process.

What is a Knowledge Graph (KG)?
A knowledge graph is a data structure representing information as a network of entities and their relationships.