




A Comprehensive Guide to ANN Benchmarks: Evaluating Approximate Nearest Neighbor Search (ANNS) Performance
A Comprehensive Guide to ANN Benchmarks: Evaluating Approximate Nearest Neighbor Search (ANNS) Performance
Imagine you're building a search engine that needs to quickly find the most similar items from a database containing billions of images, text documents, or other unstructured data. How do you ensure your search algorithm not only returns accurate results but also does so at lightning speed? This is where Approximate Nearest Neighbor (ANN) search comes into play. ANN search is crucial in many real-world applications, from recommendation systems to large-scale image retrieval.
With so many ANN search solutions available in the market, how do we evaluate the effectiveness of different ANN algorithms, especially at scale? Enter the ANN Benchmarks, which have become the gold standard for testing the performance of ANN search methods on large datasets.
In this blog, we'll explore ANN benchmarks, why they matter, and how they help developers and algorithm engineers choose the right vector search solutions for the job. We'll also look at some of the most popular benchmarks used today and what makes them essential in vector search.
What is ANN Search and How Does It Work?
Before diving into benchmarks, it’s important to understand the Approximate Nearest Neighbor (ANN) Search, or ANNS, and how it operates. ANN Search is a powerful technique in machine learning (ML) that allows for efficient semantic similarity search in large datasets often found in vector databases like Zilliz Cloud. It can quickly find items closest to a given query item in a dataset. Unlike exact search methods, which ensure 100% accuracy, ANNS trades off a small amount of accuracy for significant improvements in speed and scalability.
How ANN Search Works:
Data Representation: Each item in the dataset is represented as a vector in a multi-dimensional space. Vectors are usually encoded by an embedding model such as OpenAI text embedding models, Cohere multilingual models, and OpenAI multimodal models. For instance, an image might be represented as a vector of features, such as color or shape, in a 128-dimensional space.
Query Processing: When a query is made, the ANN Search algorithm retrieves the dataset for vectors close to the query vector, using approximations to speed up the process.
Result Ranking: The algorithm ranks the nearest neighbors based on their distance from the query in the high-dimensional space, often using metrics like Euclidean distance or cosine similarity. The closer the vectors are located, the more similar and relevant they are.
Efficiency: ANN Search's key advantage is its ability to deliver results in a fraction of the time it would take for an exact search, making it ideal for large-scale datasets.
ANNS methods use various strategies to quickly approximate the nearest neighbors:
Tree-based Methods: Techniques such as KD-Trees and Ball Trees organize data hierarchically to simplify the search process. While effective in lower dimensions, their performance degrades as dimensionality increases.
Hashing Methods: Locality-sensitive hashing (LSH) groups similar data points into the same hash buckets, reducing the number of comparisons required during the search.
Graph-based Methods: Algorithms like Navigable Small World (NSW) graphs and Hierarchical Navigable Small World (HNSW) graphs create networks of data points to expedite neighbor lookups.
Quantization Methods: Techniques such as Product Quantization (PQ) compress the data into a more manageable form, enhancing search efficiency.
By leveraging these methods, ANNS algorithms can balance between search accuracy and performance, making them suitable for large-scale datasets.
ANN Search vs. KNN Search
Exact K-nearest neighbor search (KNN) and Approximate Nearest Neighbor Search (ANNS) are two fundamental approaches used in vector search, each with its own advantages and trade-offs.
Exact KNN provides precise results by evaluating the distance between the query point and every data point in the dataset, ensuring that the identified neighbors are the closest possible. However, this method can be computationally intensive and slow due to its brute-force nature, particularly when dealing with large datasets or high-dimensional spaces. This makes exact KNN suitable for smaller datasets or scenarios where precision is paramount and computational resources are less of a concern.
In contrast, ANNS offers a practical solution for handling large-scale data by sacrificing some degree of accuracy for faster performance. ANNS employs various algorithms and techniques, such as tree-based structures, hashing methods, and graph-based approaches, to approximate the nearest neighbors efficiently. This approach significantly reduces computational costs and scales well with massive datasets, making it ideal for real-time applications like search engines and recommendation systems where speed is crucial. While ANNS may not always provide the exact closest neighbors, its ability to deliver near-accurate results quickly makes it a valuable tool in modern data retrieval and analysis tasks.
For more information, see our ANNS glossary page.
What is ANN Benchmark?
The ANN Benchmark is a comprehensive evaluation tool designed to measure and compare the performance of different ANNS algorithms. Hosted on ann-benchmarks.com, it provides standardized tests and metrics to assess various aspects of ANNS methods, including:
Search Speed: How quickly the algorithm can find the nearest neighbors.
Accuracy: The degree to which the algorithm's results approximate the true nearest neighbors.
Scalability: How well the algorithm performs as the dataset size or dimensionality increases.
This benchmark offers a range of datasets and evaluation criteria, allowing developers to gauge the effectiveness of different algorithms under various conditions on a level playing field.
Key Metrics in ANN Benchmarks:
Recall: The percentage of true nearest neighbors successfully retrieved by the algorithm. High recall indicates better accuracy.
Search Time: The time it takes for the algorithm to return a result. Faster search times are crucial for applications that require real-time responses.
Memory Usage: The amount of memory the algorithm requires to store and search the dataset. Efficient memory usage is important for scalability.
Scalability: The algorithm’s ability to maintain performance as the dataset size increases. Scalability is a critical factor in real-world applications where datasets can grow rapidly.
Key datasets used in ANN Benchmarks
ANN Benchmark uses diverse datasets to test algorithms. These datasets cover a range of domains, such as image features, text embeddings, and synthetic data. Key datasets used in the benchmarks include:
| Dataset | Dimensions | Train size | Test size | Neighbors | Distance | Download |
|---|---|---|---|---|---|---|
| DEEP1B | 96 | 9,990,000 | 10,000 | 100 | Angular | HDF5 (3.6GB) |
| Fashion-MNIST | 784 | 60,000 | 10,000 | 100 | Euclidean | HDF5 (217MB) |
| GIST | 960 | 1,000,000 | 1,000 | 100 | Euclidean | HDF5 (3.6GB) |
| GloVe | 25 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (121MB) |
| GloVe | 50 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (235MB) |
| GloVe | 100 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (463MB) |
| GloVe | 200 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (918MB) |
| Kosarak | 27,983 | 74,962 | 500 | 100 | Jaccard | HDF5 (33MB) |
| MNIST | 784 | 60,000 | 10,000 | 100 | Euclidean | HDF5 (217MB) |
| MovieLens-10M | 65,134 | 69,363 | 500 | 100 | Jaccard | HDF5 (63MB) |
| NYTimes | 256 | 290,000 | 10,000 | 100 | Angular | HDF5 (301MB) |
| SIFT | 128 | 1,000,000 | 10,000 | 100 | Euclidean | HDF5 (501MB) |
| Last.fm | 65 | 292,385 | 50,000 | 100 | Angular | HDF5 (135MB) |
Tested ANN Algorithms or Vector Search Engines
The ANN Benchmarks have evaluated a wide range of ANN algorithms and vector search engines, including Annoy, Faiss, Knowhere (Milvus's search engine), and Glass (Zilliz Cloud's legacy search engine). The number of tested algorithms continues to grow. Below is a list of algorithms and search engines tested as of September 2024.
scikit-learn: LSHForest, KDTree, BallTree
NMSLIB (Non-Metric Space Library) : SWGraph, HNSW, BallTree, MPLSH
NGT : ONNG, PANNG, QG
Elasticsearch : HNSW
DiskANN : Vamana, Vamana-PQ
scipy: cKDTree
Note: Zilliz Cloud has launched a new search engine called Cardinal, which delivers three times the performance of the legacy Glass engine and offers search throughput (QPS) up to ten times that of Milvus. However, due to time constraints and other factors, Cardinal's performance is not included in the ANN benchmark results. In the following section, you can explore its performance using VectorDBBench.
Benchmark Results
The graph below demonstrates the results of testing recall/queries per second of various algorithms based on the GIST1M dataset (1M vectors with 960 dimensions). It plots the recall rate on the x-axis against QPS on the y-axis, illustrating each algorithm's performance at different levels of retrieval accuracy.
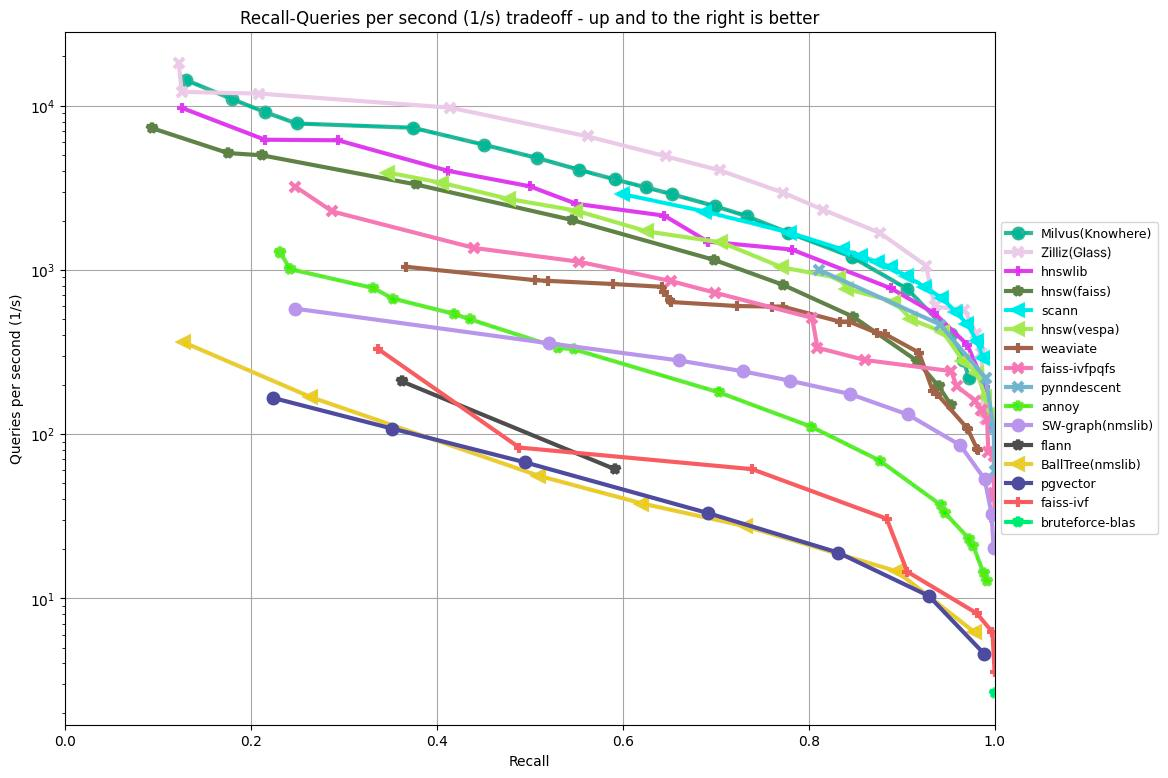 Figure 1: ANN Benchmark results on the GIST1M dataset
Figure 1: ANN Benchmark results on the GIST1M dataset
Figure 1: ANN Benchmark results on the GIST1M dataset
According to the results shown in the graph above, Knowhere (Milvus’ search engine), Glass (Zilliz Cloud’s legacy search engine), and HNSW libraries achieved the top three best results when processing 1,000,000 vectors with 960 dimensions.
For more benchmarking results, see ANN-Benchmark’s website.
VectorDBBench: An Open-source Benchmarking Tool for Vector Databases
Vector search, or vector similarity search, is a broader concept that refers to the process of finding similar vectors within a dataset. ANNS represents a set of algorithms that power vector search. Vector databases are purpose-built solutions for efficient vector similarity searches.
Although the ANN-Benchmark is incredibly useful for selecting and comparing different vector searching algorithms, it does not provide a comprehensive overview of vector databases. We must also consider factors like resource consumption, data loading capacity, and system stability. Moreover, the ANN Benchmark misses many common scenarios, such asfiltered vector searches.
To address such challenges, Zilliz developers proposed VectorDBBench, an open-source benchmarking tool designed for open-source vector databases like Milvus and Weaviate and fully managed services like Zilliz Cloud and Pinecone. Because many fully managed vector search services do not expose their parameters for user tuning, VectorDBBench displays QPS and recall rates separately.
The charts below demonstrate the testing results for QPS and the recall rate of various mainstream vector databases when processing 1,000,000 vectors with 768 dimensions.
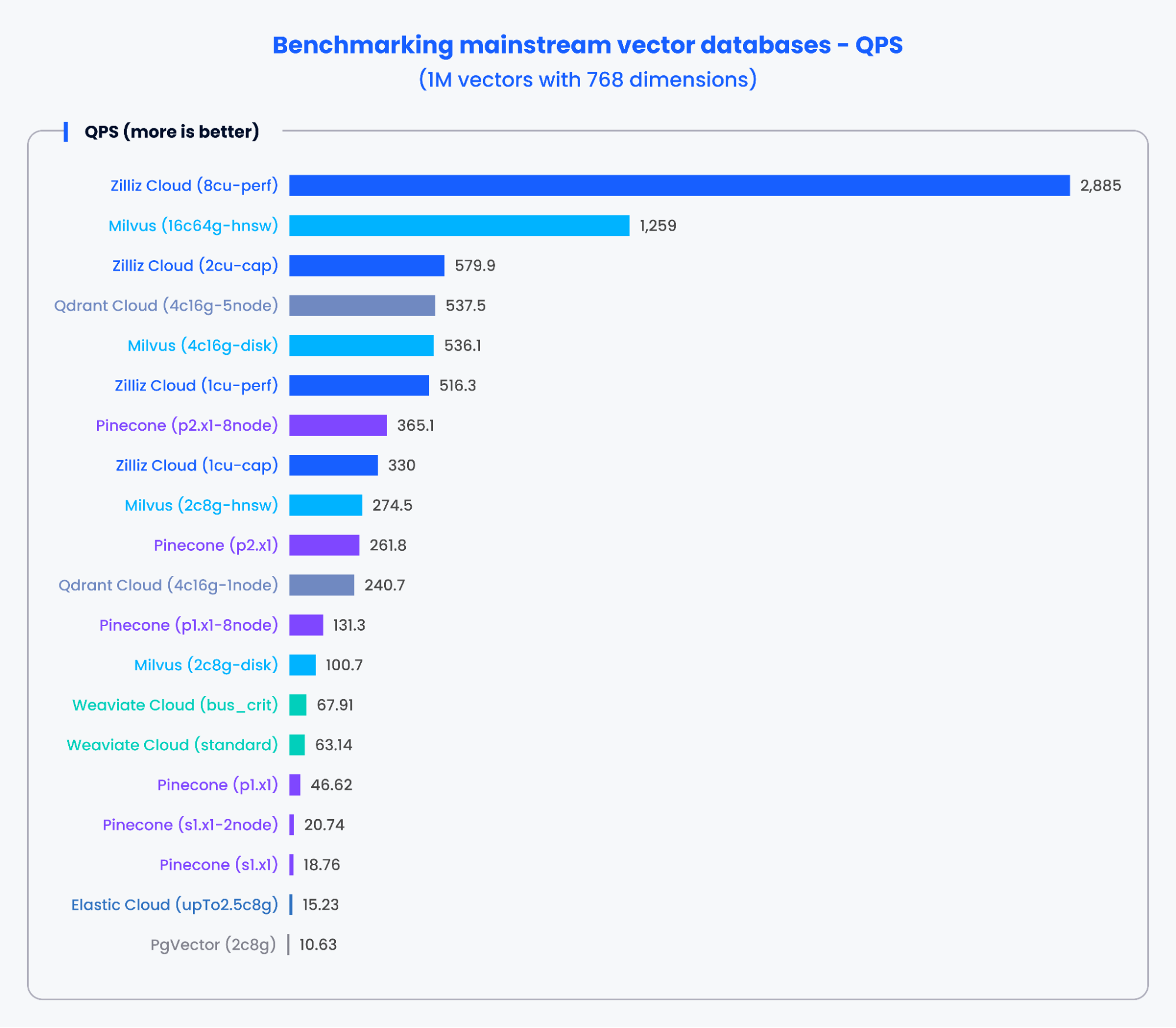 Figure 2: Benchmark results for QPS
Figure 2: Benchmark results for QPS
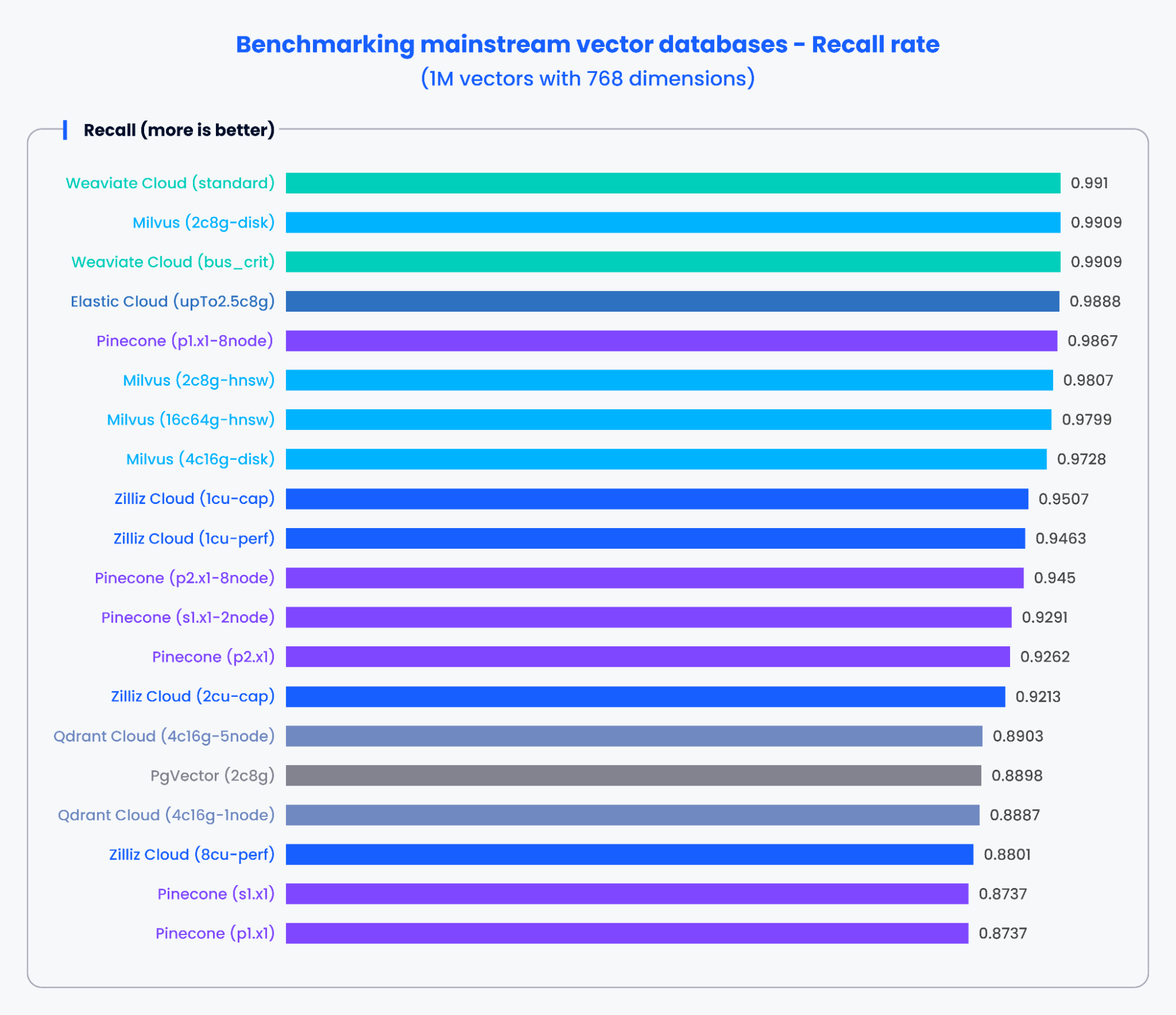 Figure 3: Benchmark results for recall rate
Figure 3: Benchmark results for recall rate
Based on the results in the charts above, purpose-built vector databases like Milvus and Zilliz demonstrated outstanding performance in both QPS and recall rates. These results indicate that purpose-built vector databases can quickly process vast amounts of data and retrieve more precise results. In contrast, vector search add-ons based on traditional databases showed poorer performance.
Download VectorDBBench from its GitHub repository to reproduce our benchmark results or obtain performance results on your own datasets.
VectorDBBench Leaderboard
VectorDBBench also offers a dedicated leaderboard page designed to streamline the presentation of test results and deliver a thorough performance analysis report. This leaderboard allows us to select key metrics such as Queries Per Second (QPS), Query Price ($) metrics, and latency for a comprehensive performance assessment.
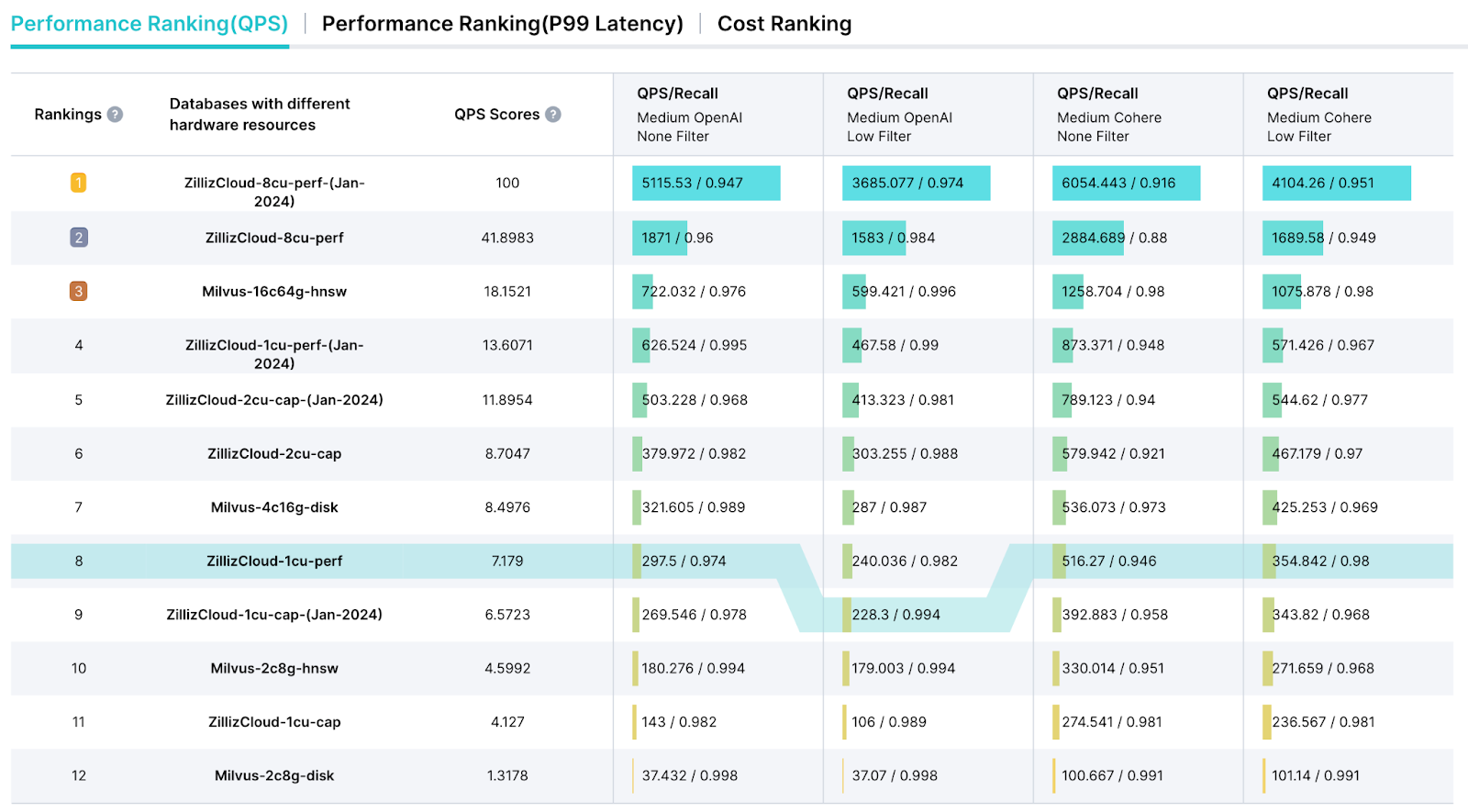 a screenshot of the vectordbbench leaderboard
a screenshot of the vectordbbench leaderboard
Figure 4: A screenshot of the VectorDBBench Leaderboard
ANN Benchmarks vs. VectorDBBench
ANN Benchmarks evaluate vector index algorithms, aiding in selecting and comparing different vector-searching libraries. However, they are unsuitable for assessing complex and mature vector databases and overlook situations like filtered vector searching.
The engineers at Zilliz created VectorDB Bench to be tailored for comprehensive vector database evaluation. It considers essential factors such as resource consumption, data loading capacity, and system stability. By segregating the test client and vector database and ensuring independent deployment, VectorDB Bench allows for testing that closely mirrors real-world production environments.
Factors Influencing Performance Evaluation
Several factors impact the performance of a vector database or an ANN algorithm, including the dataset, network conditions, and database configuration.
Network
Network conditions are critical. Latency can slow query responses, while limited bandwidth affects data transfer rates. Network stability is also important, as fluctuations can cause inconsistent performance.
Datasets
Dataset size influences memory and disk usage—larger datasets require more resources. Vector dimensionality affects operation complexity and query times. The data distribution and indexing structure (e.g., hierarchical, flat) also impact search efficiency and accuracy.
Database Configuration
Index parameters (e.g., number of trees) and search settings (e.g., nearest neighbors) directly affect retrieval efficiency and speed. Caching can improve response times for frequently accessed data.
Environmental Factors
The operating system and background processes can influence resource availability and system responsiveness, affecting overall performance.
Considering these factors helps you understand and optimize your vector database’s performance.
Further Resources
- What is ANN Search and How Does It Work?
- What is ANN Benchmark?
- VectorDBBench: An Open-source Benchmarking Tool for Vector Databases
- ANN Benchmarks vs. VectorDBBench
- Factors Influencing Performance Evaluation
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free