




Optimizing RAG with Rerankers: The Role and Trade-offs
Rerankers can enhance the accuracy and relevance of answers in RAG systems, but these benefits come with increased latency and computational costs.
Read the entire series
Retrieval-augmented generation (RAG) is a rising AI stack that enhances the capabilities of large language models (LLMs) by supplying them with additional, up-to-date knowledge. A standard RAG application consists of four key technology components:
Embedding models for converting external documents and user queries into vector embeddings,
A vector database for storing these embeddings and retrieving the Top-K most relevant information,
Prompts-as-code that combines both the user query and the retrieved context,
An LLM for generating answers.
Some vector databases like Zilliz Cloud provide built-in embedding pipelines that automatically transform documents and user queries into embeddings, streamlining the RAG architecture.
A basic RAG setup effectively addresses the issue of LLMs producing unreliable or ‘hallucinated’ content by grounding the model’s responses in domain-specific or proprietary contexts. However, some enterprise users require higher context relevancy in their production use cases and seek a more sophisticated RAG setup. One increasingly popular solution is integrating a reranker into the RAG system. This is where 'rag pipelines' come into play, enhancing RAG systems through reranking techniques to ensure the most relevant information is delivered to large language models.
A reranker is a crucial component in the information retrieval (IR) ecosystem that evaluates and reorders search results or passages to enhance their relevance to a specific query. In RAG, this tool builds on the primary vector Approximate Nearest Neighbor (ANN) search, improving search quality by more effectively determining the semantic relevance between documents and queries.
Rerankers fall into two main categories: Score-based and Neural Network-based.
Score-based rerankers work by aggregating multiple candidate lists from various sources, applying weighted scoring or Reciprocal Rank Fusion (RRF) to unify and reorder these candidates into a single, prioritized list based on their score or relative position in the original list. This type of reranker is known for its efficiency and is widely used in traditional search systems due to its lightweight nature.
On the other hand, Neural Network-based rerankers, often called cross-encoder rerankers, leverage a neural network to analyze the relevance between a query and a document. They are specifically designed to compute a similarity score that reflects the semantic proximity between the two, allowing for a refined rearrangement of results from single or multiple sources. This method ensures more semantic relatedness, thus providing useful search results and enhancing the overall effectiveness of the retrieval system.
Incorporating a reranker into your RAG applications can significantly improve the precision of the generated answers as the reranker narrows the context to a smaller, curated set of highly relevant documents. As the context is shorter, it is also easier for LLM to “attend” to everything in the context and avoid losing focus.
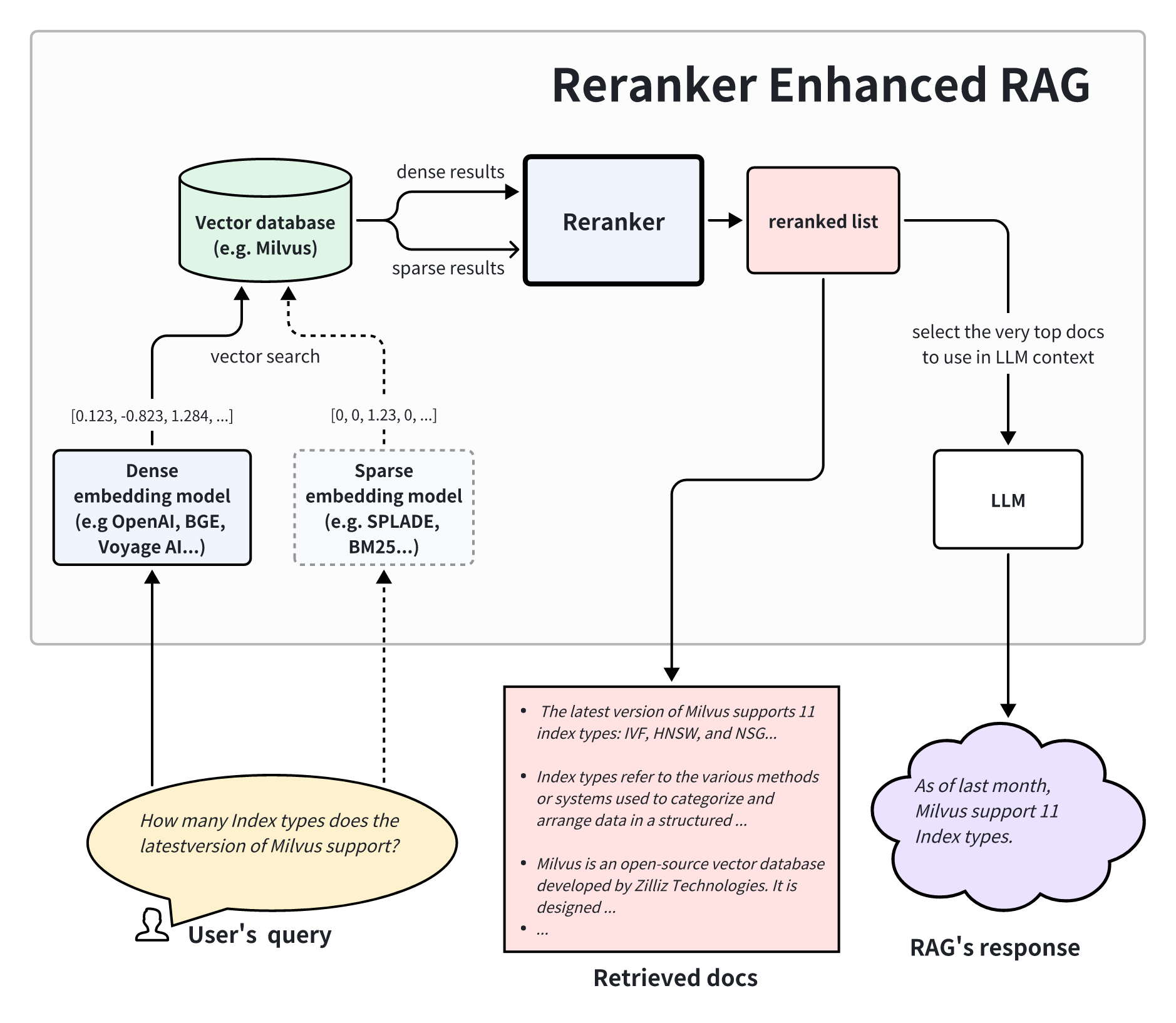
The architecture above shows that a reranker-enhanced RAG contains a two-stage retrieval system. In the first stage, a vector database retrieves a set of relevant documents from a larger dataset. Then, in the second stage, a reranker analyzes and prioritizes these documents based on their relevance to the query. Finally, the reranked results are sent to the LLM as a more relevant context for generating better-quality answers.
Nevertheless, integrating a reranker into the RAG framework comes with its challenges and expenses. Deciding whether to add a reranker requires thoroughly analyzing your business needs and balancing the improved retrieval quality against potential latency and computational cost increases.
Rerankers can enhance the relevance of retrieved information in a RAG system, but this approach comes at a price.
In a basic RAG system without a reranker, vector representations for a document are pre-processed and stored before the user conducts a query. As a result, the system only needs to perform a relatively inexpensive Approximate Nearest Neighbor (ANN) vector search to identify the Top-K documents based on metrics like cosine similarity. A vector search only takes milliseconds in a production-grade vector database like Zilliz Cloud.
In contrast, a reranker, particularly a cross-encoder, must process the query and each candidate document through a deep neural network. Depending on the model's size and hardware specifications, this process can take significantly longer — from hundreds of milliseconds to seconds. A reranker-enhanced RAG would take that much time before even generating the first token.
While offline indexing in a basic RAG workflow incurs the computational cost of neural network processing once per document, reranking requires expending similar resources for every query against each potential document in the result set. This repetitive computational expense can become prohibitive in high-traffic IR settings like web and e-commerce search platforms.
Let's do some simple math to understand how costly a reranker is.
According to statistics from VectorDBBench, a vector database handling over 200 queries per second (QPS) incurs only a $100 monthly fee, which breaks down to $0.0000002 per query. In contrast, it can cost as much as $0.001 per query if using a reranker to reorder the top 100 results from the first-stage retrieved documents. That’s a 5,000x increase over the vector search cost alone.
Although a vector database might not always operate at maximum query capacity, and the reranking could be limited to a smaller number of results (e.g., top 10), the expense of employing a cross-encoder reranker is still orders of magnitude higher than that of a vector-search-only retrieval approach.
Viewed from another angle, using a reranker equates to incurring the indexing cost during query time. The inference cost is tied to the input size (tokens) and the model size. Given that both embedding and reranker models typically range from hundreds of MB to several GB, let's assume they are comparable. With an average of 1,000 tokens per document and a negligible 10 tokens per query, reranking the top 10 documents alongside the queries would equate to 10x the computation cost of indexing a single document. This means serving 1 million queries against a corpus of 10 million documents would consume as much computational power as indexing the entire corpus, which is impractical in high-traffic use cases.
While a reranker-enhanced RAG is more costly than a basic vector-search-based RAG, it is substantially more cost-effective than relying solely on LLMs to generate answers. Within a RAG framework, rerankers serve to sift through the preliminary results from vector search, discarding documents weakly relevant to the query. This process reduces time and costs by preventing LLMs from processing extraneous information.
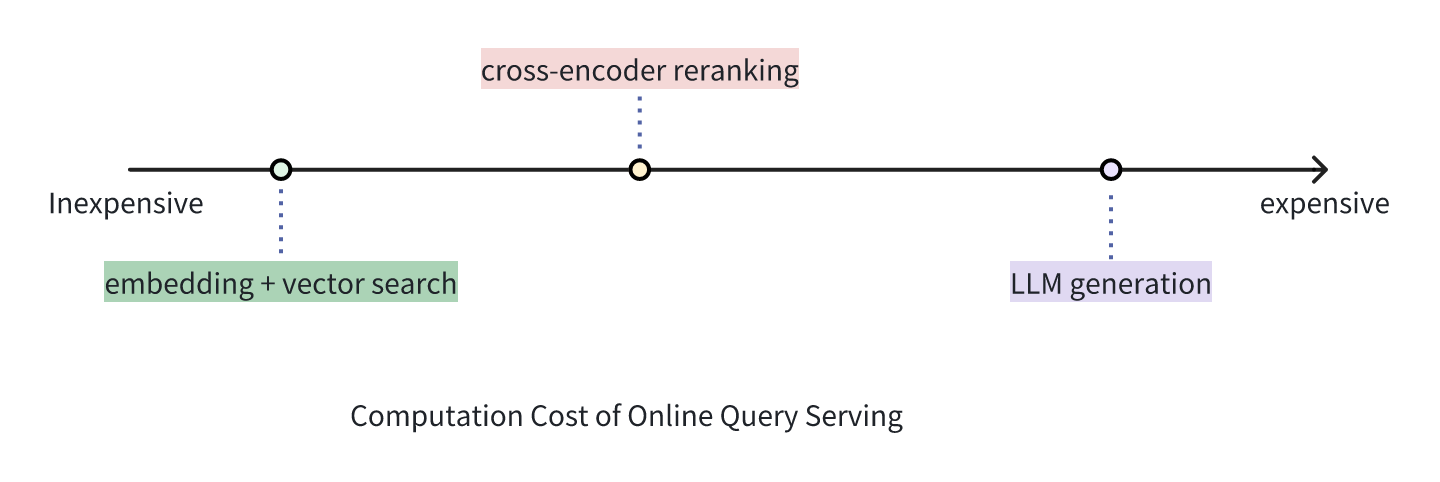
Taking a real-world example: First-stage retrieval, such as vector search engines, quickly sift through millions of candidates to identify the top 20 most relevant documents. A reranker, though more costly, then recomputes the ordering and narrows the Top20 list down to 5. Ultimately, the most expensive large language models (LLMs) analyze these top 5 documents along with the query to craft a comprehensive and high-quality response, balancing latency and cost.
Thus, the reranker serves as a crucial intermediary between the efficient but approximate initial retrieval stage and the high-cost LLM inference phase.
Incorporating a reranker into your Retrieval-Augmented Generation (RAG) setup is beneficial when high accuracy and relevance of answers are crucial, such as in specialized knowledge bases or customer service systems. In these settings, each query comes with high business value, and the enhanced precision in filtering information justifies the added cost and latency of reranking. The reranker refines the initial vector search results, providing a more relevant context for the Large Language Model (LLM) to generate accurate responses, thereby improving the overall user experience.
However, in high-traffic use cases like web or e-commerce search engines, where rapid response and cost efficiency are paramount, there may be better options than using a cross-encoder reranker. The increased computational demand and slower response times can negatively affect user experience and operational costs. In such cases, a basic RAG approach, relying on efficient vector search alone or with a lightweight score-based reranker, is preferred to balance speed and expense while maintaining acceptable levels of accuracy and relevance.
If you decide to apply a reranker to your RAG application, you can easily enable it within Zilliz Cloud Pipelines or use reranker models with Milvus.
Rerankers refine search results to improve the accuracy and relevance of answers in Retrieval-Augmented Generation (RAG) systems, proving valuable in scenarios where cost and latency can be flexible and precision is critical. However, their advantages are accompanied by trade-offs, including increased latency and computational costs, making them less suitable for high-traffic applications. Ultimately, the decision to integrate a reranker should be based on the specific needs of the RAG system, weighing the demand for high-quality responses against performance and cost constraints.
In my next blog post, I will delve into the intricacies of hybrid search architecture, exploring various technologies, including sparse embedding, knowledge graphs, rule-based retrieval, and innovative academic concepts awaiting production deployments, like ColBERT and CEPE. Additionally, I will employ a qualitative analysis to assess the improvements in result quality and the impact on latency when implementing rerankers. A comparative review of prevalent reranker models in the market, such as CohereBGE, and Voyage AI, will also be featured, providing insights into their performance and efficacy.
Introduction to Reranking in Retrieval-Augmented Generation (RAG)
The Role of Rerankers in RAG Systems
Rerankers play a vital role in RAG systems by enhancing the relevance and quality of generated responses. Selecting an appropriate reranking model is crucial for ensuring accuracy and efficiency in these systems. A reranker is a model that outputs a similarity score for a query and document pair, allowing for the reordering of documents by relevance to a query. Rerankers are used in two-stage retrieval systems to improve the accuracy and relevance of search results. By analyzing the document’s meaning specific to the user query, rerankers can provide more accurate and contextually relevant results than traditional retrieval methods.
The Importance of Relevant Documents in Reranking
Relevant documents play a crucial role in the reranking process, as they directly impact the quality of the generated response. The goal of reranking is to reorder the retrieved documents based on their relevance to the user’s query, ensuring that the most pertinent information is presented to the Large Language Model (LLM) for generation. Relevant documents are those that contain the most accurate and contextually relevant information, which is essential for producing high-quality responses.
The importance of relevant documents in reranking can be seen in the following ways:
Improved response quality: By prioritizing relevant documents, reranking ensures that the LLM works with the most accurate and contextually relevant information, leading to improved response quality.
Increased user satisfaction: Relevant documents help to deliver more accurate and contextually relevant results, which boosts user satisfaction and engagement metrics.
Enhanced RAG pipeline performance: Relevant documents are essential for optimizing RAG pipelines, as they enable the LLM to work with the most pertinent information, leading to improved performance.
Types of Rerankers
Reranking models are essential for enhancing search and retrieval processes, offering advantages over traditional retrieval methods by performing deep semantic matching and fine-grained relevance judgments. There are several types of rerankers, each with its strengths and weaknesses. Cross-Encoder rerankers process the query and document together through a transformer architecture, allowing for powerful cross-attention between query and document terms. Bi-Encoder rerankers use BERT to encode the document, but with different approaches. Multi-Vector models represent documents as sets of contextualized token embeddings rather than single vectors. LLM-Based rerankers leverage pre-trained language models to perform reranking tasks through few-shot learning or fine-tuning. API-Based solutions offer reranking as a service through API endpoints.
Choosing a Reranker: Considerations and Trade-offs
When selecting a reranker, consider factors such as the type of data, the size of the corpus, and the computational resources available. Consider the trade-off between accuracy and efficiency when selecting a reranker. Cross-Encoders are highly accurate but computationally expensive, while Bi-Encoders are more efficient but may sacrifice some accuracy. Multi-Vector models offer a balance between accuracy and efficiency. LLM-Based rerankers are flexible but may require significant computational resources. API-Based solutions are easy to use but may come with significant costs.
Implementing a Reranker in an Existing Application
Implementing a reranker in an existing application involves integrating the reranker with the existing pipeline. The reranker ranks the documents after the documents are retrieved by the document retriever and returns it back to the function call. The reranker can be integrated with the RAG pipeline to improve the quality of the generated response. Consider using techniques such as hyperparameter tuning and model selection to optimize your reranking setup. Additionally, consider using techniques such as document splitting or using a different reranker to handle long or multiple documents.
Performance of Rerankers
The performance of rerankers is critical in determining the quality of the generated response. Rerankers can significantly enhance the performance of RAG systems by ensuring that the most relevant documents are presented to the LLM for generation. The performance of rerankers can be evaluated using various metrics, including:
Precision: The proportion of relevant documents retrieved by the reranker.
Recall: The proportion of relevant documents that are retrieved by the reranker out of all relevant documents in the database.
F1-score: The harmonic mean of precision and recall, providing a balanced measure of the reranker’s performance.
Practical Implementation Strategies for Reranker-Enhanced RAG Systems
When implementing reranker-enhanced RAG systems in production environments, assigning relevance scores to evaluate and reorder documents can significantly improve performance while managing computational costs.
Caching Mechanisms for Retrieved Documents Reranker Results
One effective approach to mitigate the computational burden of rerankers is implementing a robust caching system. By storing reranking results for common queries, organizations can dramatically reduce computational costs and latency for frequently asked questions. Caching strategies should consider time-based expiration policies to ensure information freshness. Organizations should also implement LRU (Least Recently Used) eviction policies to optimize memory usage and develop partial matching techniques to leverage cached results for similar queries. In high-volume applications, even a modest cache hit rate of 30-40% can translate to substantial cost savings while maintaining high-quality responses.
Adaptive Reranking Thresholds
Not all queries require the same level of reranking precision. Implementing adaptive thresholds can optimize resource allocation. Use confidence scores from first-stage retrieval to determine when reranking is necessary. Apply more intensive reranking only when vector search results show low confidence or high ambiguity. Adjust the number of documents passed to the reranker based on query complexity and initial retrieval quality. This tiered approach ensures computational resources are allocated efficiently, with simple queries bypassing expensive reranking while complex queries receive the full benefit of deeper semantic analysis.
Optimizing Reranker Model Size
The size of reranker models significantly impacts both quality and performance. Consider distilled models that maintain most of the accuracy while reducing parameter count. Quantized models that use lower numerical precision without significant quality degradation are also worth exploring. Domain-specific fine-tuning can improve relevance for specialized knowledge areas. Many organizations find that medium-sized distilled models (100-300M parameters) offer an optimal balance between performance and quality for most enterprise applications.
Hybrid Reranking Architectures
Combining multiple reranking approaches can yield superior results. Use vector similarity search for initial retrieval of candidate documents before applying score-based rerankers for initial filtering followed by more sophisticated cross-encoders. Implement ensemble methods that combine scores from multiple reranker types. Apply different reranking strategies based on document types or query categories. These hybrid approaches can deliver quality improvements while managing computational costs through strategic deployment of expensive components.
Handling Long Documents
Handling long documents is a common challenge in reranking, as many rerankers have input length limitations. To address this challenge, several techniques can be employed, including:
Document splitting: Splitting long documents into smaller chunks, allowing the reranker to process each chunk separately.
Using a different reranker: Selecting a reranker that is specifically designed to handle long documents, such as a multi-vector model or an LLM-based reranker.
Offline Evaluation and Online A/B Testing
Evaluating the performance of a reranking implementation is crucial to ensure that it is effective in improving the quality of the generated response. Offline evaluation and online A/B testing are two common methods used to evaluate the performance of a reranking implementation.
Offline evaluation: Evaluating the performance of the reranking implementation using standard information retrieval metrics on labeled test sets.
Online A/B testing: Evaluating the impact of the reranking implementation on the end-to-end RAG system, comparing the performance of the system with and without the reranking implementation.
Error Analysis and Addressing Potential Biases
Error analysis and addressing potential biases are essential steps in ensuring that the reranking implementation is effective and fair. Error analysis involves identifying cases where the reranking implementation fails to surface relevant documents, while addressing potential biases involves identifying and mitigating biases in the reranking implementation.
Error analysis: Analyzing log data and error tracking to identify areas for improvement in the reranking implementation.
Addressing potential biases: Identifying and mitigating biases in the reranking implementation, such as biases in the training data or biases in the reranking algorithm.
Future Directions in RAG Reranking Technology
The field of reranking for RAG systems continues to evolve rapidly. Several promising developments are likely to shape the landscape in the coming years:
Context-Aware Reranking for User Queries
Next-generation rerankers will move beyond simple query-document relevance to incorporate broader contextual understanding, ensuring that the retrieved information aligns closely with the user's query. Conversation history awareness will help maintain coherence across multi-turn interactions. User preference modeling will enable personalization of reranking based on individual information needs. Task-specific optimization will adapt reranking behavior based on the intended use case. These advances will enable more natural and helpful AI responses that account for the full interaction context rather than treating each query in isolation.
Multimodal Reranking Capabilities
As RAG systems expand to include multimodal content, rerankers will evolve to handle diverse data types. Cross-modal relevance assessment between text queries and image/video content will become increasingly important. Joint understanding of text, tables, and graphical elements within documents will enhance comprehension. Semantic alignment across modalities will enable more comprehensive information retrieval. Organizations working with rich media content will particularly benefit from these capabilities, enabling more comprehensive knowledge access across their information assets.
 Jiang Chen
Jiang ChenJiang is currently Director of Technical GTM at Zilliz. He has years of experience in data infrastructures and cloud security. Before joining Zilliz, he had previously served as a tech lead and product manager at Google, where he led the development of web-scale semantic understanding and search indexing that powers innovative search products such as short video search. He has extensive industry experience handling massive unstructured data and multimedia content retrieval. He has also worked on cloud authorization systems and research on data privacy technologies. Jiang holds a Master's degree in Computer Science from the University of Michigan.
- Introduction to Reranking in Retrieval-Augmented Generation (RAG)
- The Role of Rerankers in RAG Systems
- The Importance of Relevant Documents in Reranking
- Types of Rerankers
- Choosing a Reranker: Considerations and Trade-offs
- Implementing a Reranker in an Existing Application
- Performance of Rerankers
- Practical Implementation Strategies for Reranker-Enhanced RAG Systems
- Handling Long Documents
- Offline Evaluation and Online A/B Testing
- Error Analysis and Addressing Potential Biases
- Future Directions in RAG Reranking Technology
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Build AI Apps with Retrieval Augmented Generation (RAG)
A comprehensive guide to Retrieval Augmented Generation (RAG), including its definition, workflow, benefits, use cases, and challenges.

A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG)
We explored various facets of chunking strategies within Retrieval-Augmented Generation (RAG) systems in this guide.

Building RAG with Dify and Milvus
Learn how to build Retrieval Augmented Generation (RAG) applications using Dify for orchestration and Milvus for vector storage in this step-by-step guide.