




Enhancing RAG with RA-DIT: A Fine-Tuning Approach to Minimize LLM Hallucinations
RA-DIT, or Retrieval-Augmented Dual Instruction Tuning, is a method for fine-tuning both the LLM and the retriever in a RAG setup to enhance overall response quality.
Read the entire series
- Mastering LLM Challenges: An Exploration of Retrieval Augmented Generation
- Key NLP technologies in Deep Learning
- Exploring the Frontier of Multimodal Retrieval-Augmented Generation (RAG)
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- How to Enhance the Performance of Your RAG Pipeline
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- Pandas DataFrame: Chunking and Vectorizing with Milvus
- How to build a Retrieval-Augmented Generation (RAG) system using Llama3, Ollama, DSPy, and Milvus
- Improving Information Retrieval and RAG with Hypothetical Document Embeddings (HyDE)
- Building RAG with Milvus Lite, Llama3, and LlamaIndex
- Enhancing RAG with RA-DIT: A Fine-Tuning Approach to Minimize LLM Hallucinations
- Top 10 RAG & LLM Evaluation Tools You Don't Want To Miss
Retrieval-Augmented Generation (RAG) has proven to be a powerful method for incorporating internal documents as context for Large Language Models (LLMs). By integrating relevant context into our prompts, we reduce the risk of LLM hallucination, where the model generates responses that appear convincing but are incorrect.
However, common RAG implementations have limitations, as LLMs are not inherently trained to effectively utilize retrieved contexts. Therefore, there may be cases where an LLM wouldn’t fully utilize the provided context when generating a response, thus the hallucination still occurs.
This article will discuss a lightweight fine-tuning approach within the RAG framework that optimizes context utilization during response generation. This approach is called Retrieval-Augmented Dual Instruction Tuning (RA-DIT). So, without further ado, let’s briefly introduce the RAG approach and the motivation behind RA-DIT.
The Fundamentals of RAG and the Motivation Behind RA-DIT
LLMs fine-tuned with instruction datasets can generate responses that address the problems specified in the input prompts. While these LLMs perform well for questions widely available on the internet, their answers often contain hallucinations when the problems require internal knowledge. Hallucination refers to a phenomenon where the LLM generates convincing but incorrect responses.
To avoid LLM hallucinations, we need to provide context in our input prompts so that the LLM can use that context to generate relevant answers. This is where the RAG method comes in.
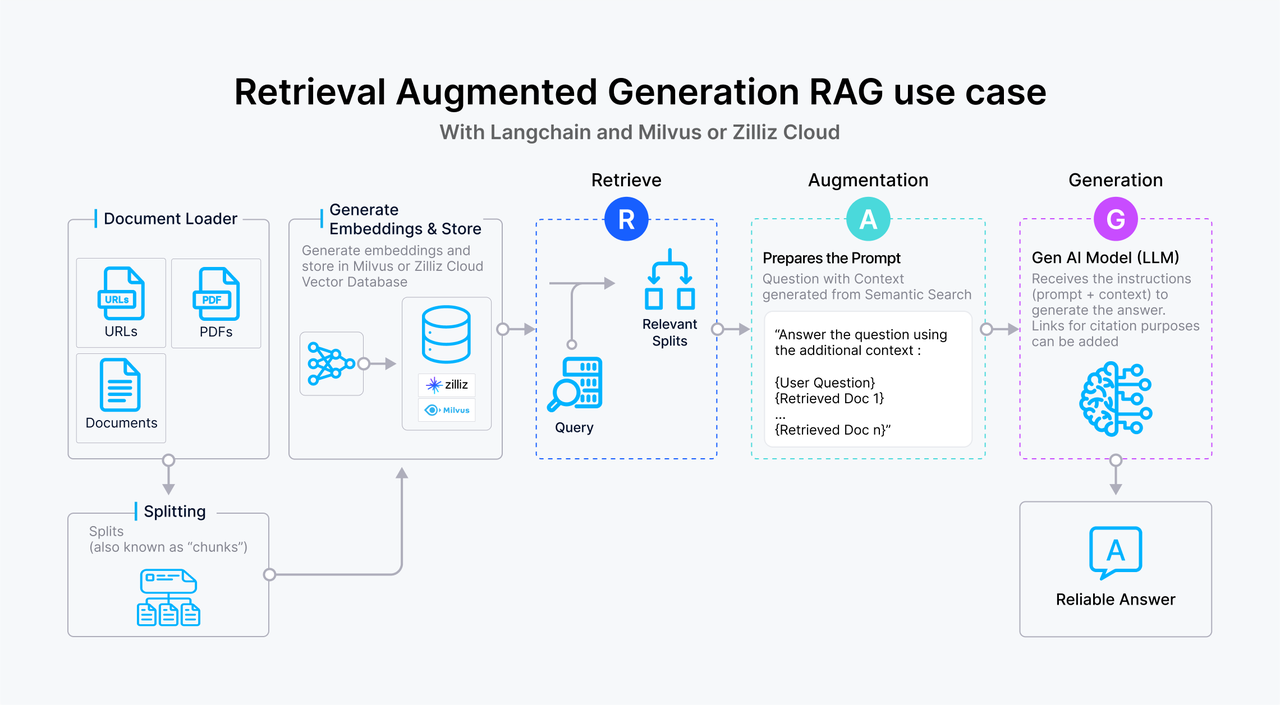 Figure 1- How RAG works
Figure 1- How RAG works
The complete workflow of a RAG application.
RAG is a technique in which, alongside the original query, we also provide relevant context that may assist the LLM in answering the query. As the name suggests, RAG consists of three main components: retrieval, augmentation, and generation.
In the retrieval component, promising contexts for a given query are fetched. First, we need to transform a large collection of documents into embeddings using an embedding model, which we will refer to as a retriever in this article. Then, we store all of these document embeddings inside a vector database. Next, we also transform the query into an embedding using the same retriever.
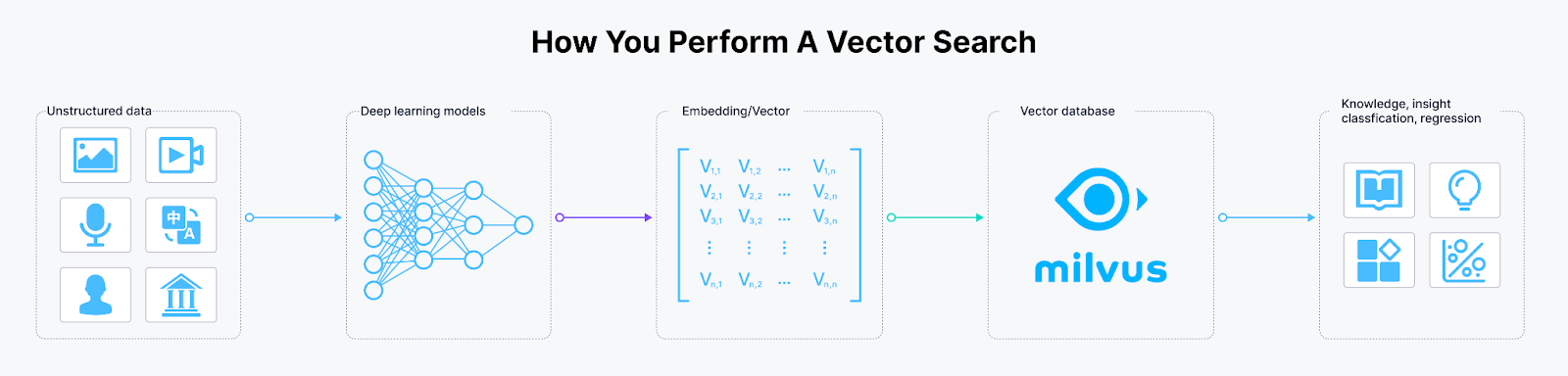 Figure 2- Workflow of storing a large collection of document embeddings inside a vector database
Figure 2- Workflow of storing a large collection of document embeddings inside a vector database
Workflow of storing a large collection of document embeddings inside a vector database.
Once we have the embeddings for both our query and the collection of documents, we can compute the similarity between the query embedding and the document embeddings stored inside a vector database. We then select the top-k most similar documents to our query as context candidates.
In the augmentation component, the retrieved contexts are integrated into the original prompt so that our final prompt contains both the original query and the retrieved contexts. Finally, in the generation component, we provide this final prompt to an LLM, hoping it will use the provided contexts to generate a contextualized response, thereby avoiding hallucination.
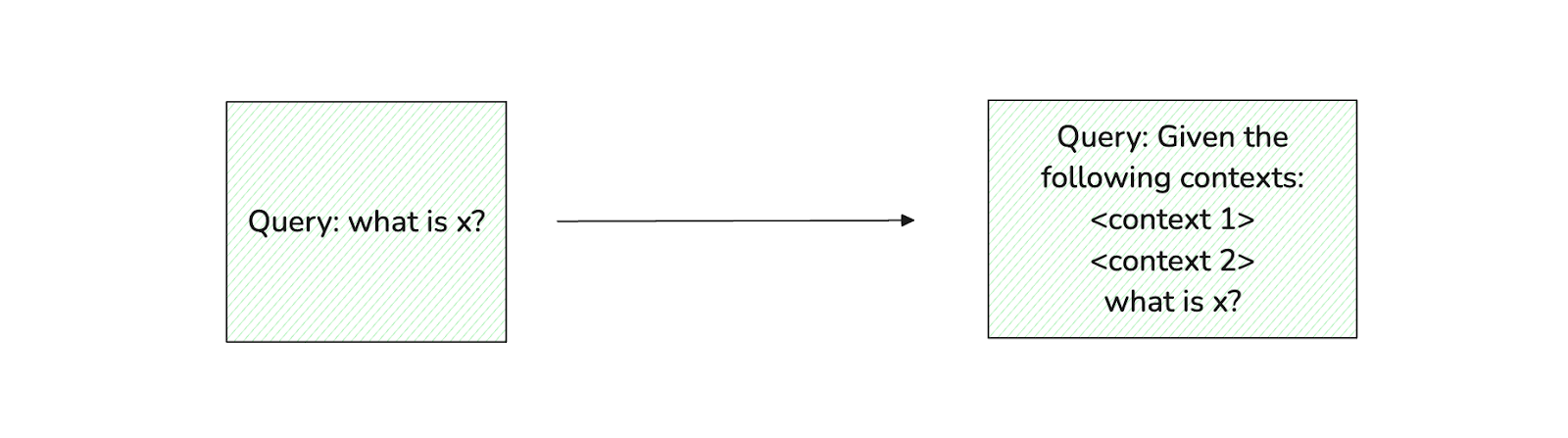 Original prompt vs retrieval-augmented prompt
Original prompt vs retrieval-augmented prompt
Figure: Original prompt vs retrieval-augmented prompt.
The main issue with common RAG implementations is that LLMs are not natively trained with instruction datasets that incorporate retrieved contexts for generating responses to user queries. Consequently, there may be cases where an LLM does not utilize the provided contexts when generating a response. Additionally, there can be instances where the retrieved contexts are irrelevant to answering the query, yet the LLM uses them to generate a response, resulting in poor-quality answers.
Now, the question arises: Can we improve the response quality generated from a RAG application by fine-tuning both the LLM and retriever to incorporate contexts into the instruction dataset? It turns out that we can enhance response quality using a method called Retrieval-Augmented Dual Instruction Tuning (RA-DIT). We will discuss how this method works in the next section.
What is RA-DIT and How it Works
In a nutshell, RA-DIT is a method for fine-tuning both the LLM and the retriever in a RAG setup to enhance overall response quality. Thus, RA-DIT consists of two separate steps:
LLM Fine-Tuning: Given a prompt that includes a query, its corresponding context, and the ground-truth label, the LLM is fine-tuned to optimize its utilization of the provided context as a source for response generation.
Retriever Fine-Tuning: Given a prompt and a ground-truth label, the retriever is fine-tuned to retrieve contexts that increase the likelihood of the LLM generating a correct response.
 Figure-Overview of the RA-DIT approach that separately fine-tunes the LLM and the retriever
Figure-Overview of the RA-DIT approach that separately fine-tunes the LLM and the retriever
Figure: Overview of the RA-DIT approach that separately fine-tunes the LLM and the retriever. Source.
LLM Fine-Tuning
The LLM used for instruction tuning is the Llama model. Specifically, three variants of the Llama model were fine-tuned: 7B, 13B, and 65B. The dataset comprises 20 different sources across five categories: dialogue, open-domain QA, reading comprehension, and chain-of-thought (CoT) reasoning.
During the fine-tuning process, for each pair of input query and its corresponding ground-truth response, the top-k contexts relevant to answering the query are retrieved. Each retrieved context is then prepended to the query to form one coherent prompt. For example, if we retrieve the top 10 most relevant contexts for an input query, we will end up with 10 prompts, each containing the same input query but different contexts. In the fine-tuning implementation, the k was set to k=3, meaning we only retrieve the top three most relevant contexts for any given query.
Once we have gathered this collection of prompts, the data needs to be serialized for instruction tuning using the templates shown below:
 Figure- Instruction template used for fine-tuning datasets
Figure- Instruction template used for fine-tuning datasets
Figure: Instruction template used for fine-tuning datasets. Source.
As illustrated, there are three special markers used to serialize the datasets: <inst_s>, <inst_e>, and <answer_s>. These markers denote the start and end of each field. During the fine-tuning process, these markers are randomly applied across the collection of prompts to avoid overfitting.
Now that we have a prompt consisting of an input query and a retrieved context, we can fine-tune the LLM using standard next-token prediction by optimizing the following loss function:
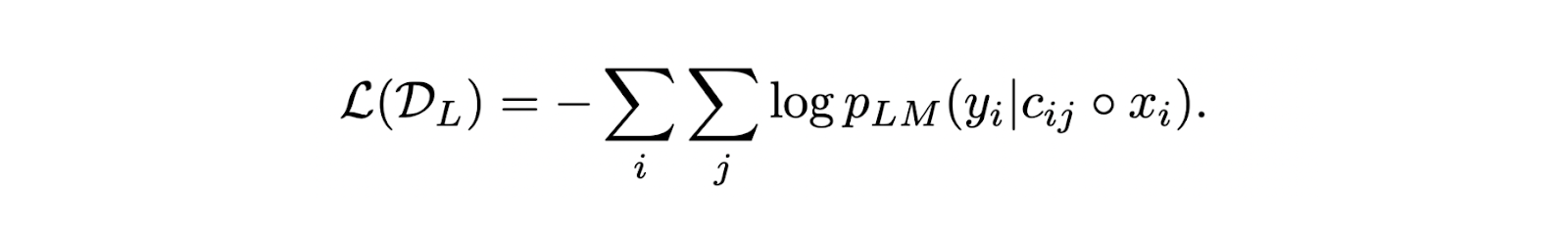
The final LLM probability score can be computed from two components: (1) the LLM probability score of generating correct response given an input query and its corresponding retrieved context, and (2) the context relevance score from the retriever that has been re-normalized after retrieving the top-k relevant contexts.
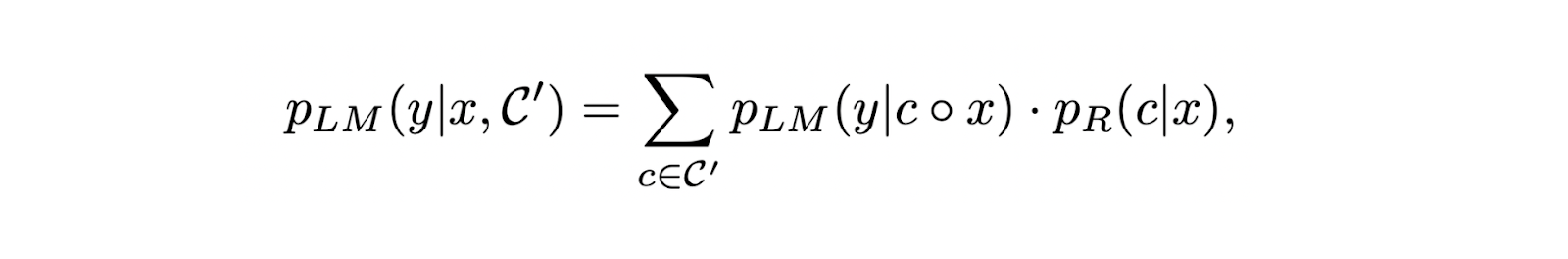
Incorporating retrieved context into our input prompt during LLM fine-tuning offers at least two benefits. First, it encourages the LLM to learn how to utilize provided context as its main source for response generation, thereby further reducing hallucination risk. Second, even if the provided context is irrelevant to answering the query, the loss function during fine-tuning will enhance the LLM’s robustness against unreliable and irrelevant contexts during response generation.
We will explore how LLM fine-tuning using the RA-DIT method improves overall response quality in the next section.
Retriever Fine-Tuning
In addition to fine-tuning the LLM itself, RA-DIT also fine-tunes the retriever. The retriever used for this process is the Dragon+ model, which features dual encoders: one for documents and another for queries.
As the name suggests, the document encoder transforms a collection of documents into embeddings, while the query encoder transforms queries into embeddings. During fine-tuning, only the query encoder is updated, as updating both encoders would negatively impact overall retriever performance.
The datasets used for retriever fine-tuning include QA datasets compiled by the authors of RA-DIT, as well as FreebaseQA and MS-MARCO. Similar to LLM fine-tuning, these datasets are serialized for instruction tuning using templates shown in the table above.
To fine-tune the retriever, RA-DIT employs supervision from the LLM itself. For each pair of input query and its corresponding ground-truth label, the score for each retrieved context is determined using the following equation:
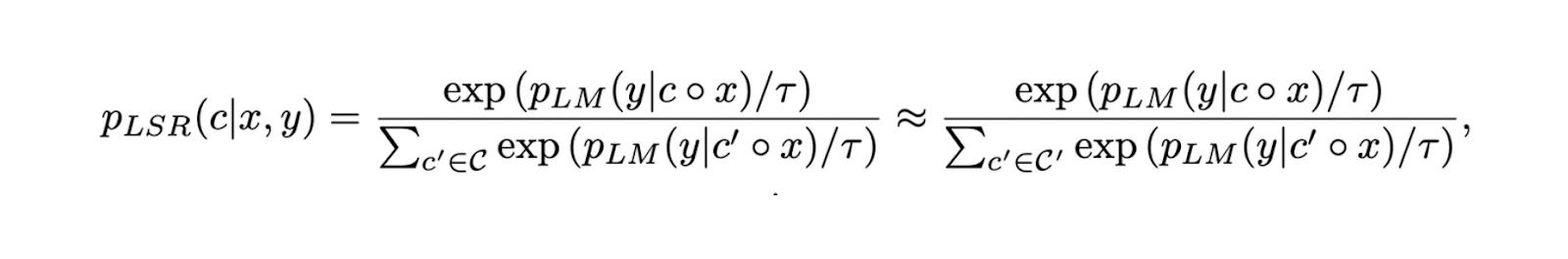
The higher the result from this equation, the more effective a particular context is in improving response quality from an LLM. Therefore, the primary goal of retriever fine-tuning is to assign higher scores to contexts that increase an LLM’s likelihood of generating correct and high-quality responses.
RA-DIT Evaluation Results
To evaluate the results of the fine-tuned retriever, a total of 399 million contexts gathered from Wikipedia and CommonCrawl were compiled to serve as a corpus. Meanwhile, several knowledge-intensive evaluation datasets, such as MMLU, TriviaQA, Natural Questions, and a subset of the KILT benchmark, were used to assess the fine-tuned LLM.
The evaluation focused on comparing the Llama 65B model across three different variants: the one fine-tuned with RA-DIT, the base model, and the original model fine-tuned with an instruction dataset (Llama instruct). Also, the performance of RA-DIT against another state-of-the-art RAG-based approach called REPLUG was also evaluated. It is also important to note that the Dragon+ model was used as a retriever when evaluating the RAG responses for all three variants.
The Dragon+ model was selected over other embedding models because it performed best on several benchmark datasets when used in a RAG framework alongside the Llama model, including MMLU, NQ, TQA, and HoPo. Specifically, the performance of the Dragon+ model was compared against that of Contriever and Contriever-MSMarco.
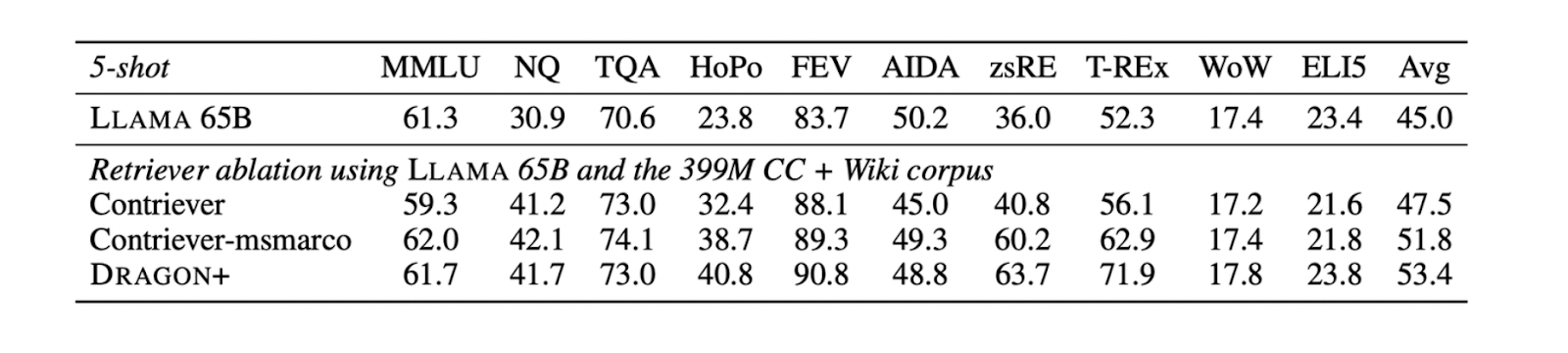 Figure-Performance of different retrievers on benchmark datasets
Figure-Performance of different retrievers on benchmark datasets
Figure: Performance of different retrievers on benchmark datasets. Source.
Based on the evaluation results, the LLM fine-tuned with the RA-DIT approach showed the best performance among the methods tested across various benchmark datasets when incorporating context augmentation in the prompts.
As shown in the table below, regardless of how many contexts we retrieve—whether it’s 1, 3, or even 10—the LLM fine-tuned with RA-DIT consistently outperforms the other two methods. This suggests that the RA-DIT approach has successfully encouraged the LLM to optimize context utilization during response generation. Even when the contexts are not entirely relevant to answering the query, the LLM effectively relies on its internal knowledge acquired during pre-training.
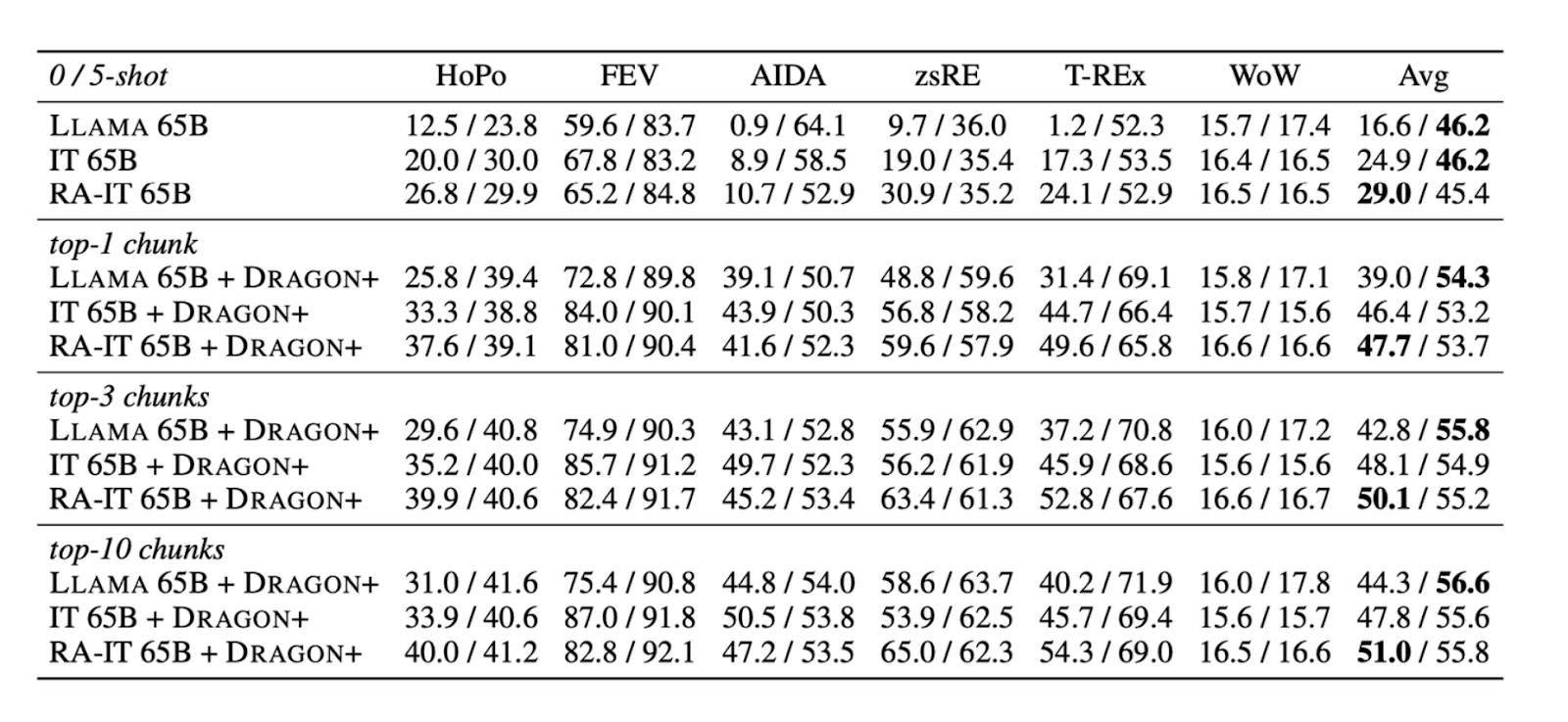 Figure -Performance comparison of Llama 65B fine-tuned with RA-DIT and other methods..png
Figure -Performance comparison of Llama 65B fine-tuned with RA-DIT and other methods..png
Figure: Performance comparison of Llama 65B fine-tuned with RA-DIT and other methods. Source.
For the retriever, we also need to determine which dataset is optimal for fine-tuning. The evaluation results indicate that fine-tuning the retriever on a combination of corpus data (dataset assembled by RA-DIT authors) (95%) and MTI datasets (5%) yields better performance than fine-tuning on either dataset alone. The table below also shows that fine-tuning only the query encoder while freezing the document encoder works best for Dragon+, leading to the decision of fine-tuning only the query encoder.
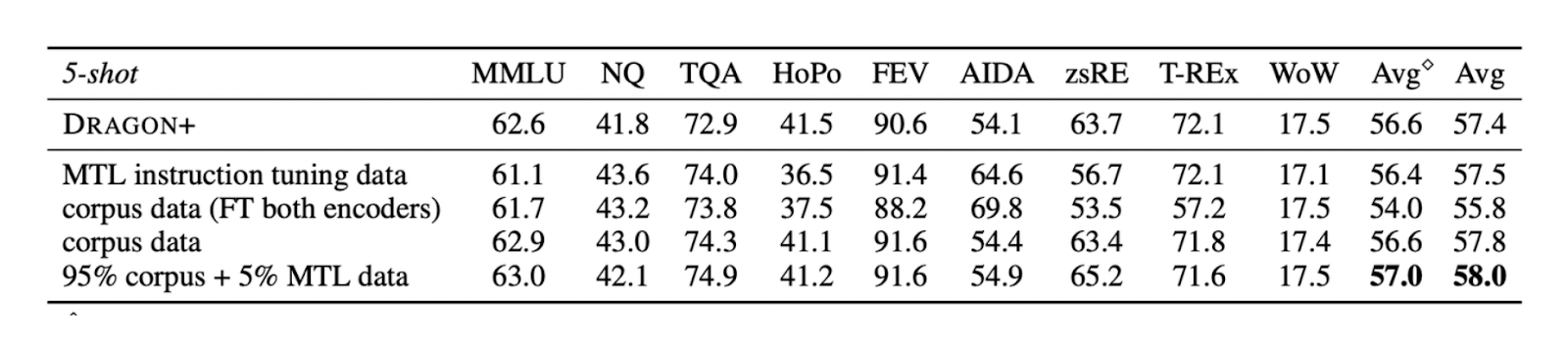 Figure-Performance of Dragon+ fine-tuned on several datasets
Figure-Performance of Dragon+ fine-tuned on several datasets
Figure: Performance of Dragon+ fine-tuned on several datasets. Source.
So far, we have seen the results of fine-tuned LLMs and retrievers when used separately while keeping the other fixed to their pre-training settings. Next, let’s evaluate their performance when using both the fine-tuned LLM and retriever within the same RAG framework. To do this, the performance against the REPLUG method which utilized an instruction-tuned Llama and Dragon+ was evaluated.
As illustrated in the table below, when we use both fine-tuned Llama and Dragon+ together in a RAG framework, there is an average performance increase of 0.8 points compared to the REPLUG method.
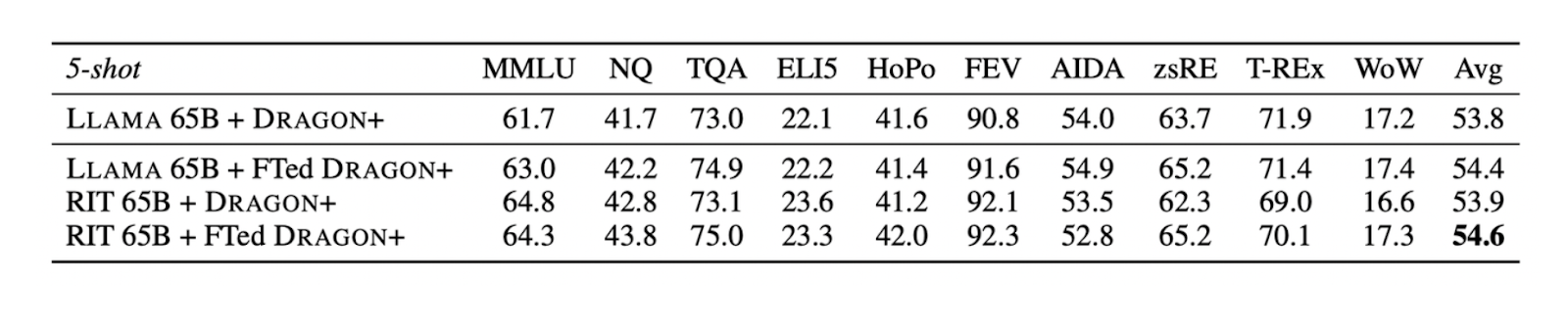 Figure- The impact of LLM and Retriever fine-tuning in the RA-DIT method
Figure- The impact of LLM and Retriever fine-tuning in the RA-DIT method
Figure: The impact of LLM and Retriever fine-tuning in the RA-DIT method. Source.
Conclusion
The RA-DIT approach represents a step-forward improvement in optimizing RAG frameworks by addressing the key limitation of common RAG implementation: LLMs are not natively trained by incorporating contexts in the prompt. By fine-tuning both the LLM and the retriever in a RAG setup, RA-DIT enforces LLM to consider retrieved contexts when generating responses, effectively reducing hallucinations and improving the robustness of generated responses.
The fine-tuned Llama models demonstrated superior performance across various benchmarks, outperforming both baseline and state-of-the-art methods like REPLUG. This underscores RA-DIT's effectiveness in ensuring the relevance and reliability of generated outputs, even when dealing with less relevant contexts. The dual tuning approach implemented in RA-DIT also ensures that not only this method will improve individual components, but also the performance of the entire RAG pipeline.
Relevant Resources

- The Fundamentals of RAG and the Motivation Behind RA-DIT
- What is RA-DIT and How it Works
- RA-DIT Evaluation Results
- Conclusion
- Relevant Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Exploring the Frontier of Multimodal Retrieval-Augmented Generation (RAG)
Multimodal RAG is an extended RAG framework incorporating multimodal data including various data types such as text, images, audio, videos etc.
How to build a Retrieval-Augmented Generation (RAG) system using Llama3, Ollama, DSPy, and Milvus
In this article, we aim to guide readers through constructing an RAG system using four key technologies: Llama3, Ollama, DSPy, and Milvus. First, let’s understand what they are.

Building RAG with Milvus Lite, Llama3, and LlamaIndex
Retrieval Augmented Generation (RAG) is a method for mitigating LLM hallucinations. Learn how to build a chatbot RAG with Milvus, Llama3, and LlamaIndex.