




How to Evaluate RAG Applications
Effective Evaluation strategies for your RAG Application
Read the entire series
- How to Evaluate RAG Applications
- Benchmarking Vector Database Performance: Techniques and Insights
- How to Spot Search Performance Bottleneck in Vector Databases
- Ensuring High Availability of Vector Databases
- Safeguard Data Integrity: Backup and Recovery in Vector Databases
- Scaling Vector Databases to Meet Enterprise Demands
- Introducing an Open Source Vector Database Benchmark Tool for Choosing the Ideal Vector Database for Your Project
A comparative analysis of evaluating RAG (Retrieval Augmented Generation) applications, addressing the challenge of determining their relative effectiveness. It explores quantitative metrics for developers to enhance their RAG application performance.
In previous articles, we briefly introduced the basic framework of RAG applications. However, when comparing two different Retrieval Augmented Generation applications, how do we determine which one is better? And for developers, how can they quantitatively improve the performance of their RAG applications?
Accurately evaluating the performance of RAG applications is crucial for both users and developers. Simple comparisons of a few examples are insufficient to fully measure the quality rag performance of RAG application answers. We need reliable and reproducible metrics to quantitatively evaluate RAG applications. In the following sections, we will discuss evaluating a RAG application from both a black-box and white-box perspective.
RAG evaluation can be likened to testing software systems. There are two ways to assess the quality of RAG systems: black-box evaluation and white-box evaluation.
In a black-box, evaluation framework, we cannot see the internal workings of the RAG application. We can only evaluate RAG's performance based on the input and output information. Generally, we have access to three pieces of information: the user's query, retrieved contexts, and RAG's response. These three pieces of information are used to evaluate the performance of the RAG application. This black-box approach is an end-to-end evaluation method suitable for evaluating closed-source RAG applications.
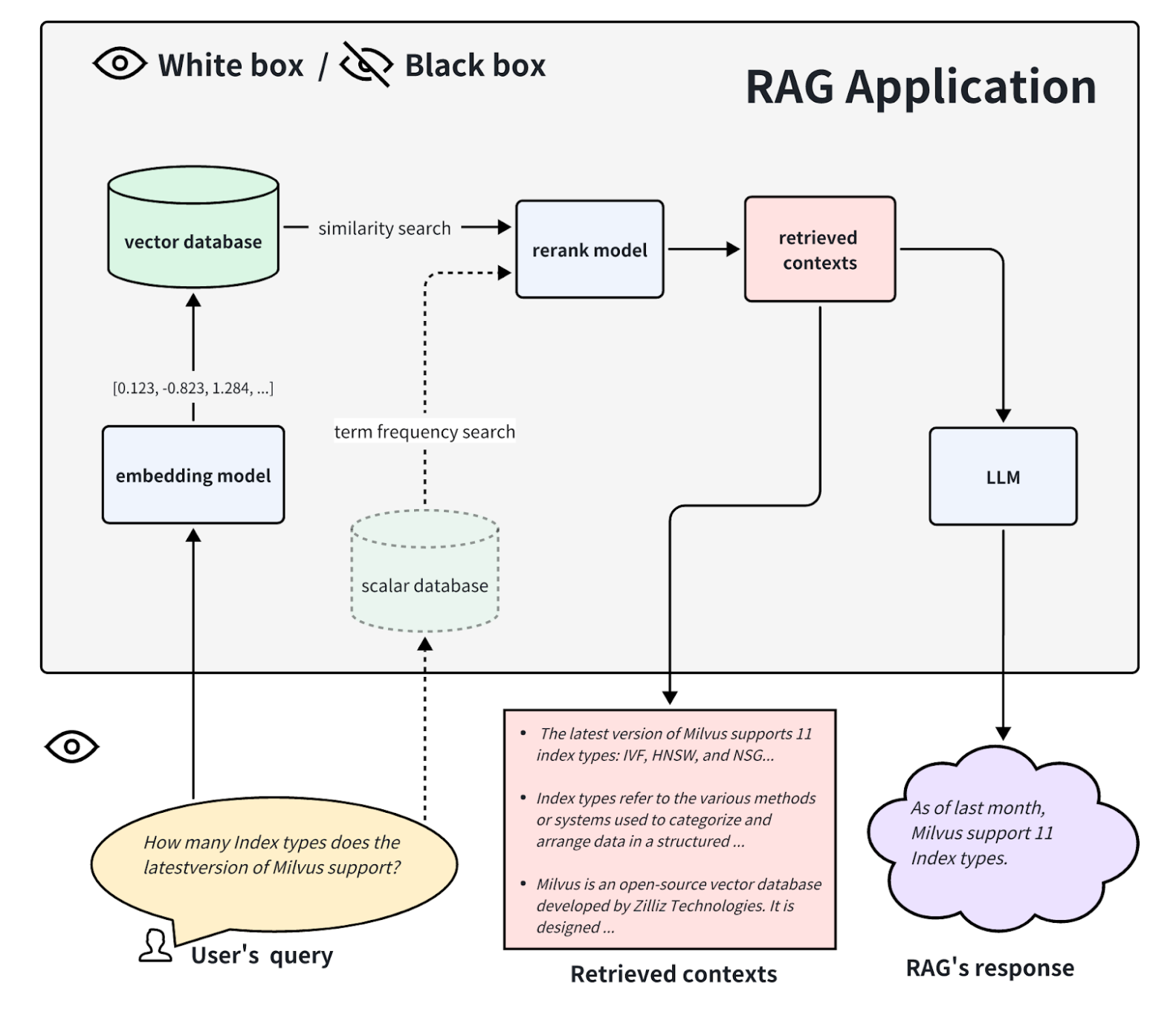
In a white-box evaluation, we can see all the internal processes of the RAG application. Therefore, the application's performance can be determined by key components within it. For example, in the typical RAG application flow, key elements include the embedding model, rerank model, and LLM. Some RAG applications have multi-way retrieval capabilities and may involve term frequency search algorithms. Replacing and upgrading these key components can enhance the performance of the RAG application. This white-box approach helps evaluate open-source RAG applications or improve customized RAG applications.
 White Box and Black Box Eval.png
White Box and Black Box Eval.png
Black Box End-to-End Evaluation
Evaluation Metrics
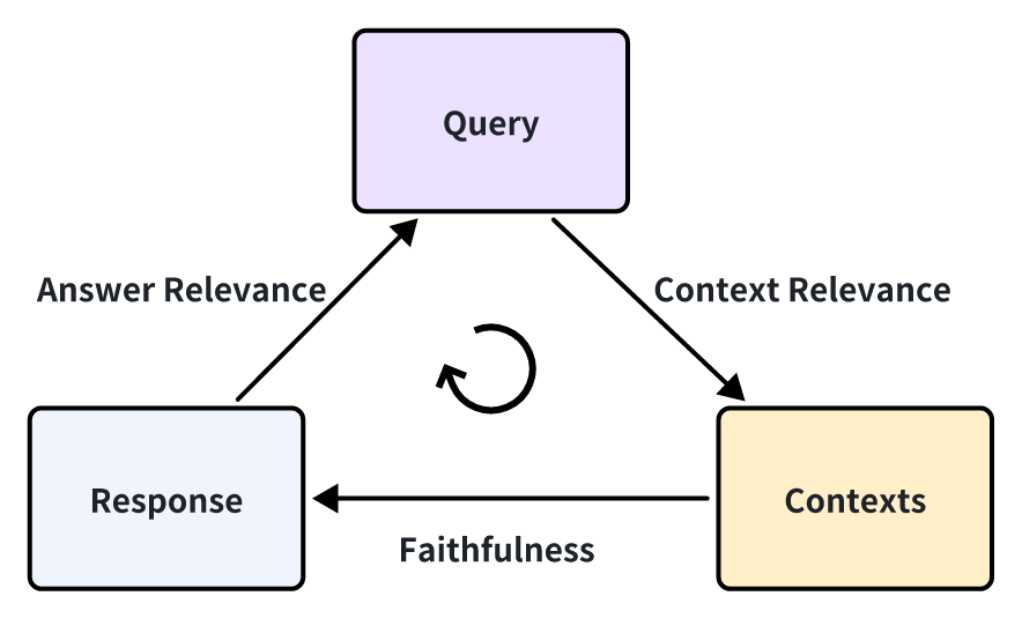
When treating a Retrieval Augmented Generation (RAG) application as a black box, our ability to evaluate its performance hinges on the interplay of three crucial components: the user’s query, the retrieved contexts, and the final response generated by the RAG system. These three elements form the backbone of the RAG evaluation framework and are deeply interdependent. To assess the effectiveness of a RAG application, it’s essential to measure the correlation between these components, as any misalignment can significantly degrade the quality of the output.
Evaluating a RAG application involves several key evaluation metrics that help quantify how well these components work together. By closely analyzing these evaluation metrics, developers can gain insights into the strengths and weaknesses of their RAG system, guiding further optimization and improvement.
 RAG Triad.png
RAG Triad.png
We can use the following evaluation metrics to assess these three aspects in RAG evaluation:
Context Relevance: This metric assesses how well the retrieved contexts (relevant documents) align with the user’s query. The relevance of the context is key, as irrelevant or loosely related content can dilute the quality of the final output. A low context relevance score suggests that the retrieval process has surfaced content that does not adequately support or relate to the query, which in turn can lead to inaccuracies or off-topic answers from the LLM. High context relevance ensures that the LLM has the necessary information to generate a meaningful and accurate response.
Faithfulness: Faithfulness measures the factual consistency of the generated answer in relation to the retrieved relevant documents. It is an important metric that ensures the response is not only relevant but also factually correct based on the provided information. A low faithfulness score indicates discrepancies between the LLM’s output and the retrieved contexts, raising the risk of generating hallucinations—answers that are plausible but not grounded in the retrieved data. Maintaining high faithfulness is essential for applications where accuracy and reliability are paramount.
Answer Relevance: This metric focuses on how directly and completely the generated answer addresses the user’s query. It evaluates the pertinence of the LLM's response, assigning lower scores to answers that are either incomplete, redundant, or fail to adequately address the question. Answer relevance is critical for ensuring that the user receives a response that is not only factually correct but also directly applicable to their query, enhancing the overall utility and user satisfaction with the RAG system.
By systematically evaluating these evaluation metrics, developers can identify areas where their RAG evaluation excels or falls short. This, in turn, allows for targeted improvements, whether through refining retrieval methods, adjusting chunking strategies, or fine-tuning the LLM's response generation capabilities.
To illustrate Answer Relevance, consider the following example:
Question: Where is France and what is its capital?
Low relevance answer: France is in western Europe.
High relevance answer: France is in western Europe and Paris is its capital.
How to Quantitatively Calculate these Metrics
Now that you understand that the answer "France is in Western Europe" is considered to get low relevance for the question "Where is France and what is its capital?", which is determined based on prior human knowledge, is there a way to assign a quantitative score to this answer as 0.2 and another answer as 0.4? And how can we ensure that the 0.4 score is better than 0.2?
Furthermore, relying on human scoring for every answer would require a significant amount of manual labor and the establishment of specific guidelines for human raters to learn and adhere to. This way is time-consuming and impractical. Is there a way to automate the scoring process? Fortunately, advanced language models (LLMs) such as GPT-4 have reached a level of proficiency similar to human annotators. They can fulfill both requirements mentioned earlier: quantitatively and objectively scoring answers and automating the process.
In the paper LLM-as-a-Judge, the author proposes using LLM as a judge and conducts numerous experiments based on this concept. The results reveal that good LLM judges like GPT-4 can closely align with controlled and crowdsourced human preferences, achieving over 80% agreement, which is on par with the level of agreement between humans. Therefore, LLM-as-a-judge offers a scalable and explainable approach to approximate human preferences, which would otherwise be costly.
You may think 80% agreement between LLM and human raters is not a high score. However, any two individuals, even under guidance, may not necessarily achieve 100% agreement when rating subjective questions like these. Therefore, the fact that GPT-4 reaches 80% agreement with humans shows that GPT-4 can fully qualify as a competent judge. Regarding how GPT-4 assigns scores, consider Answer Relevance as an example. We use the following prompt to ask relevant document to GPT-4:
There is an existing knowledge base chatbot application. I asked it a question and received a response. Do you think this response is a good answer to the question? Please rate this response. The score should be an integer between 0 and 10. 0 means the response does not answer the question at all, while 10 means the response answers the question perfectly.
Question: Where is France and what is its capital?
Response: France is in western Europe and its capital is Paris.
GPT-4's response:
10
As you can see, by designing an appropriate, prompt template in advance, such as the example above, we can automate the evaluation of all question-answer pairs by replacing the Question and Response. Therefore, prompt design is crucial. The example above is just a sample prompt. In practice, prompts are often lengthy to ensure fair and robust scoring by GPT. This requires advanced prompt engineering techniques such as multi-shot or Chain-of-Thought (CoT). When designing these prompts, it is sometimes necessary to consider LLM biases, such as the common position bias. LLM tends to pay more attention to the initial content when the prompt is long and overlooks some content in the middle.
Fortunately, we don't need to overly concern ourselves with prompt design as the evaluation tools for RAG applications have already been well-integrated, and the community can test their prompt quality over time. We should be more concerned about the high consumption of API tokens when accessing LLMs like GPT-4. In the future, we hope that more cost-effective or on-device LLMs that can act as reliable judges will emerge.
Do we need to annotate ground-truth?
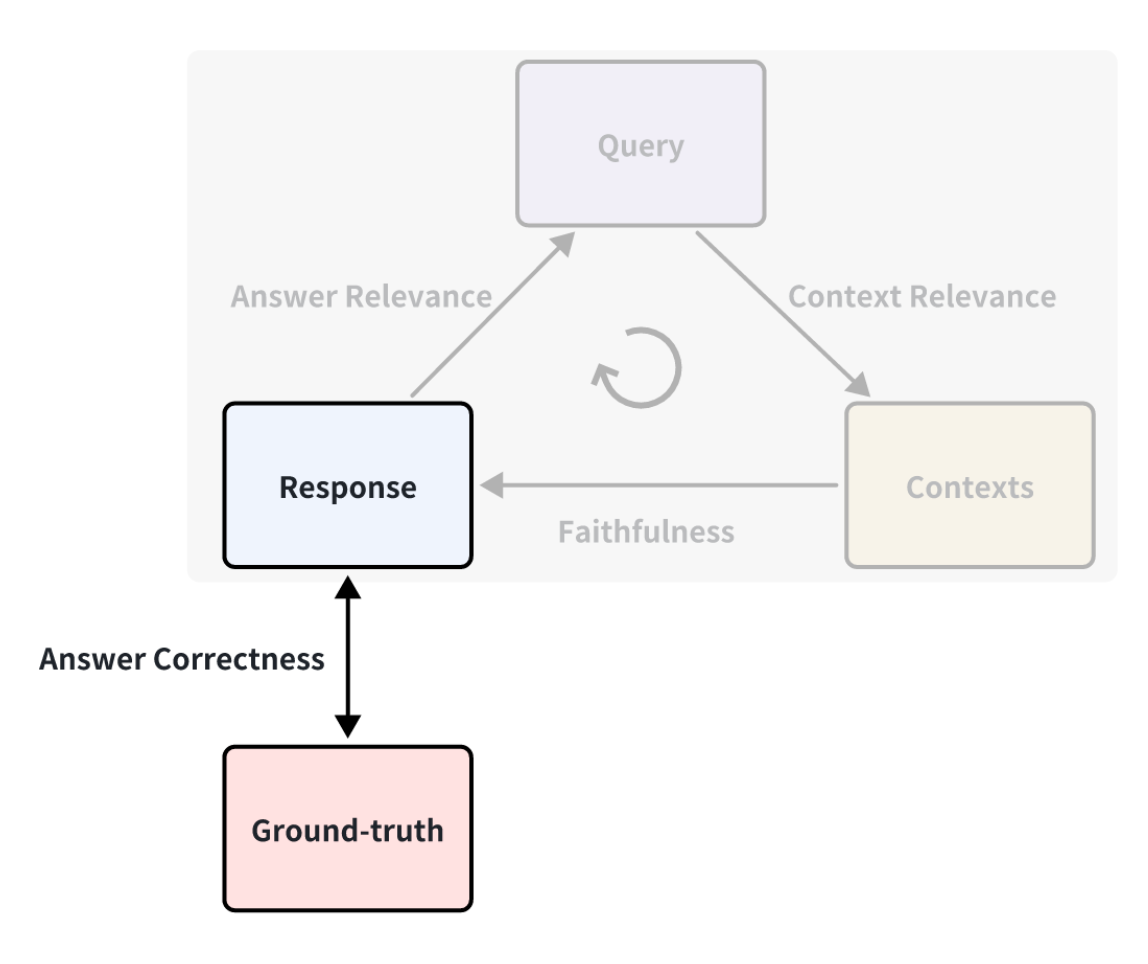
You may have noticed that in the examples above, we did not use ground truth, which refers to the standard answers written by humans that correspond to the questions. For instance, we can define an "Answer Correctness" metric to measure the accuracy of RAG's answers. The scoring method is based on LLM scoring, the same as the Answer Relevance metric mentioned above.
 Ground Truth.png
Ground Truth.png
Therefore, if we get the ground truths, we can get a more comprehensive evaluation metric result, as we can measure the performance of Retrieval Augmented Generation applications from various perspectives. However, in most cases, obtaining a dataset with ground truths is expensive. It may require a significant amount of manual labor and time to annotate training data. Is there a way to quickly annotate?
Since a good LLM can generate anything, it is feasible to use LLM to generate queries and ground truths based on knowledge documents. For example, various integrated interfaces can be easily used in the Synthetic Test Data generation of Ragas and the QuestionGeneration of Llama-Index.
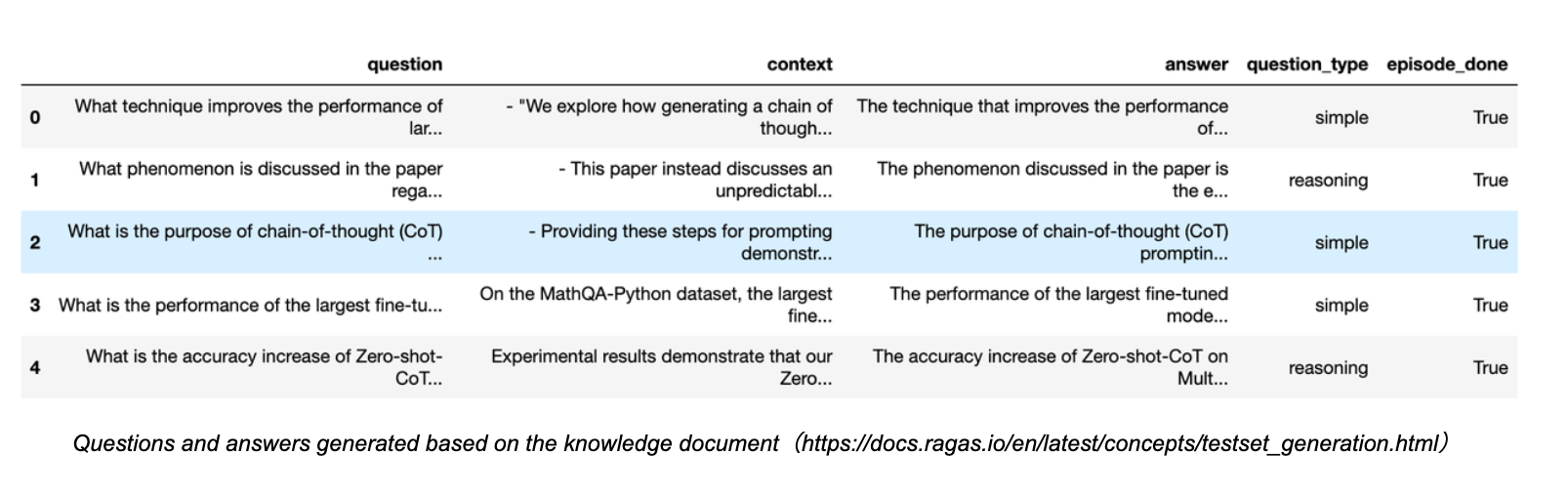
Let's take a look at the generating queries based on knowledge documents in Ragas:
 Ragas queries.png
Ragas queries.png
As you can see, many query questions and their corresponding answers are generated, including the relevant context and sources. To ensure the diversity of generated questions, you can also choose the proportions of different types, such as simple or reasoning questions.
This way, we can conveniently use these generated questions and ground truths to quantitatively evaluate an RAG application without searching for various online baseline datasets. This approach can also be used to evaluate proprietary or customized datasets within an enterprise.
White-box Evaluation
White-box RAG Pipeline
From a white-box perspective, we can examine the internal implementation pipeline of the RAG application. Taking the common RAG application process as an example, some key components include the embedding model, rerank model, and LLM (Language Model). Some RAG models have the ability for multi-way retrieval and may also involve term frequency search algorithms. Testing these key components can also reflect the performance of the RAG pipeline at a specific step. Replacing and upgrading these key components can also improve the performance of the RAG application. Below, we will introduce how to evaluate these three typical key components separately.
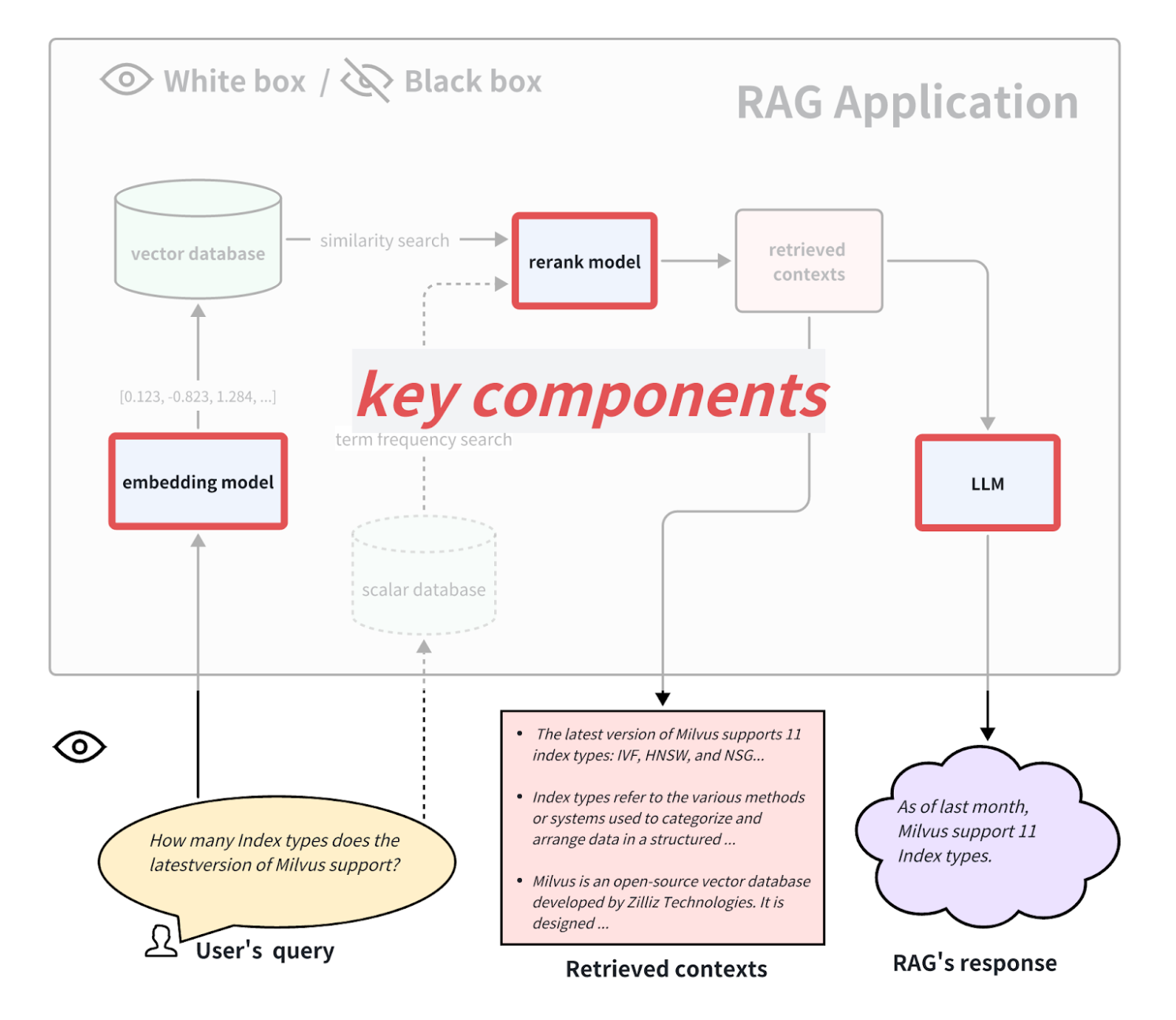 Key Components.png
Key Components.png
How to Evaluate the Embedding Model and Rerank Model
The embedding model and rerank model collaborate in document retrieval. In the previous section, we introduced the Context Relevance metric, which can be used to evaluate the relevance of the retrieved documents. However, when dealing with datasets containing ground truths, it is recommended to use deterministic metrics commonly used in information retrieval to measure retrieval performance. The processing of these metrics is faster, more cost-effective, and more deterministic than the LLM-based Context Relevance metric (but they require ground-truth contexts).
Metrics in Information Retrieval
In information retrieval, there are two types of common metrics: ranking-aware metrics and ranking-agnostic metrics. Ranking-aware metrics are sensitive to the ranking of ground-truth documents among all retrieved documents. In other words, changing the order of all retrieved documents would change the score of this metric. On the other hand, ranking-agnostic and retrieval metrics would not be affected by different rankings.
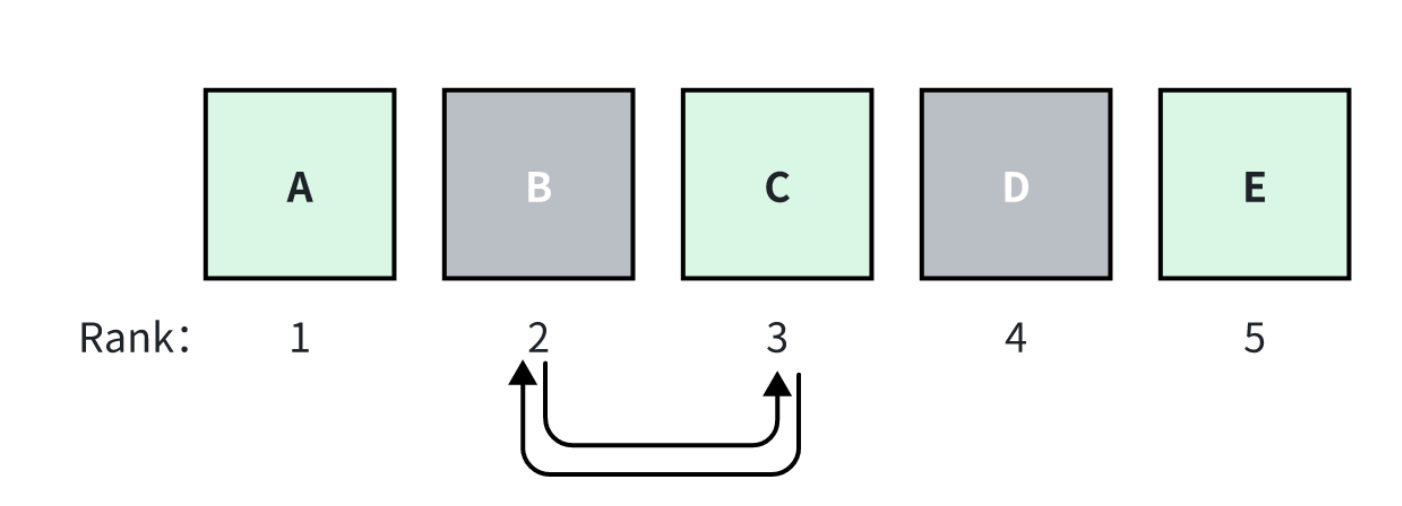 Ranking.png
Ranking.png
For example, assume that the RAG retrieved the top_k=5 documents, A, B, C, D, E. And the A, C, E are ground-truth documents. A is ranked first with the highest relevance score, and the scores decrease from left to right. If the ranking positions of B and C are swapped, the score of ranking-aware metrics would change, but the score of ranking-agnostic metrics would remain the same.
Here are some specific metrics:
Ranking-agnostic metrics:
- Context Recall: measures what proportion of all relevant contexts are retrieved.
- Context Precision: measures what proportion of the retrieved contexts are relevant.
Ranking-aware metrics:
- Average Precision (AP): Measures the weighted score of retrieving all relevant blocks. The average AP on a dataset is often referred to as MAP.
- Reciprocal Rank (RR): Measures the position of the first relevant block in your retrieval. The average RR on a dataset is often referred to as MRR.
- Normalized Discounted Cumulative Gain (NDCG): Accounts for the cases where your classification of relevancy is non-binary.
The Most Popular Evaluation Benchmark: MTEB
The Massive Text Embedding Benchmark (MTEB) is a comprehensive benchmark designed to evaluate the performance of text embedding models on various tasks and datasets. MTEB covers eight embedding tasks: bitext mining, classification, clustering, classification, reranking, retrieval, semantic text similarity (STS), and summarization. It covers 58 datasets spanning 112 languages, making it one of the most comprehensive text embedding benchmarks to date.
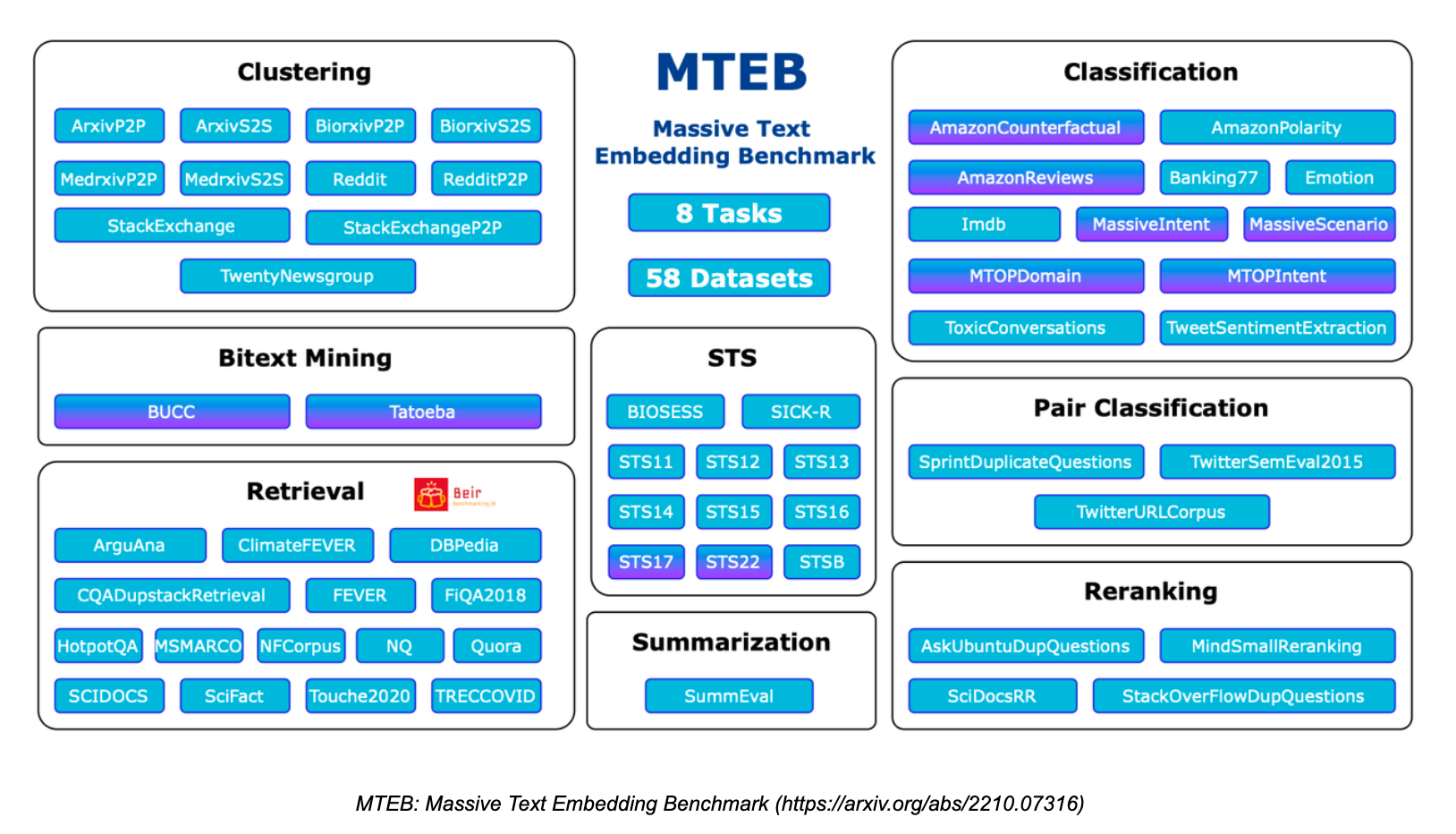 MTEB.png
MTEB.png
MTEB includes retrieval and reranking tasks. When evaluating embedding and reranking models in the RAG application, it is important to focus on the models that score high in these two tasks. The MTEB paper suggests NDCG as the most important metric for embedding models, while MAP is the most important metric for reranking models.
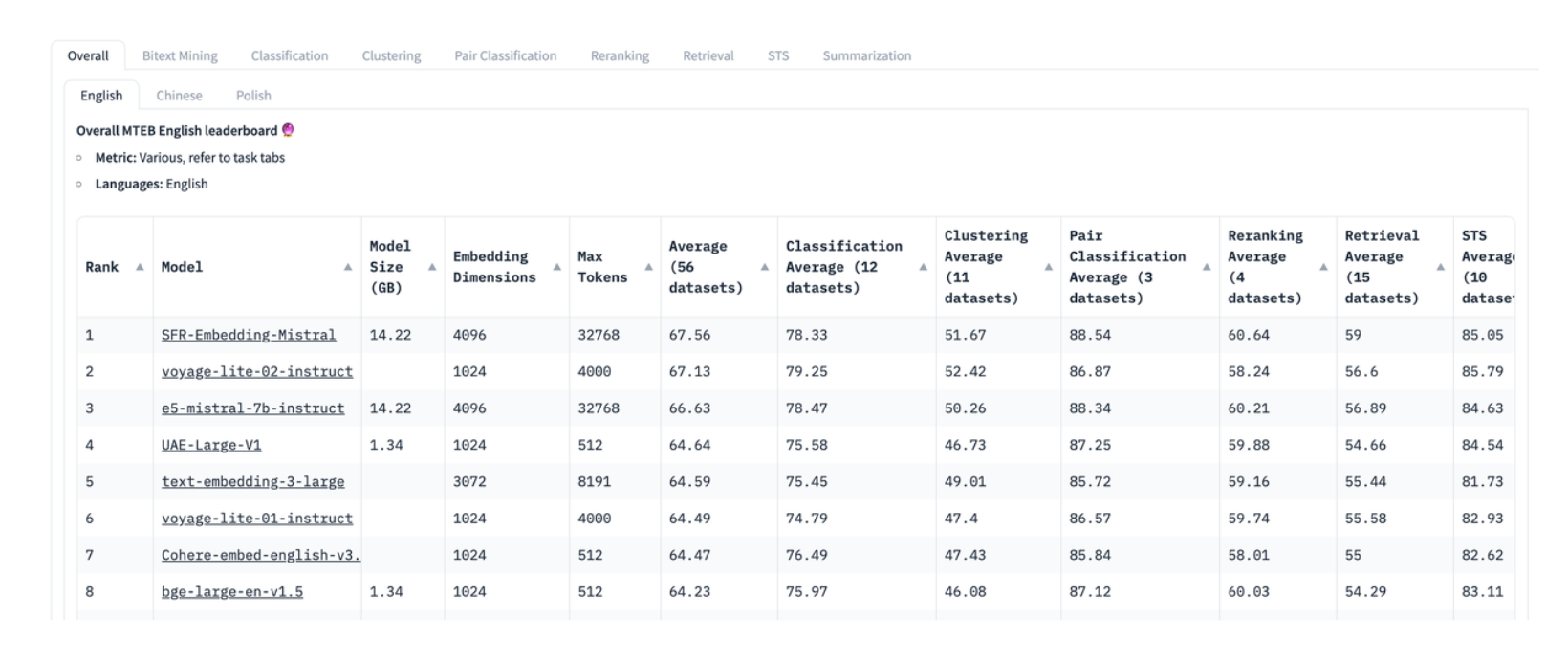 Hugging Face.png
Hugging Face.png
MTEB is a highly regarded leaderboard on HuggingFace. However, since the dataset is public, some models may have to overfit this dataset, which will degrade performance on actual data sets. Therefore, when evaluating retrieval performance, it is also essential to focus on the evaluation performance of customized datasets consistent with the actual business domain.
How to evaluate LLM
In general, the generation process can directly use the LLM-based metric introduced in the previous section, which is Faithfulness, to evaluate from Context to Response.
However, for some relatively simple query tests, such as those with only a few simple phrases as standard answers, classic metrics can also be used. For example, ROUGE-L Precision and Token Overlap Precision. This deterministic evaluation also requires well-annotated ground-truth contexts.
- ROUGE-L Precision measures the longest common subsequence between the generated answer and the retrieved context.
- Token Overlap Precision calculates the precision of token overlap between the generated answer and the retrieved context. For example, for relatively simple questions like the one below, ROUGE-L Precision and Token Overlap Precision can still be used to evaluate.
Question: How many Index types does the latest version of Milvus support?
Response: As of last month, Milvus supports 11 Index types.
Ground-truth Context: In this version, Milvus supports 11 Index types.
However, it should be noted that these metrics are not suitable for complex RAG scenarios, where we should use LLM-based metrics. For example, for open-ended questions like this:
Question: Please design a text search application based on the features of the latest version of Milvus and list the application usage scenarios.
Introduction to Common Evaluation Tools
Professional tools are now available in the open-source community that users can use to conveniently and quickly perform quantitative evaluations. Here are some commonly used and good RAG evaluation tools.
Ragas: Ragas is a dedicated tool for evaluating RAG applications, providing a simple interface for the evaluation criteria. It offers a wide range of metrics for RAG applications, and it does not rely on any specific RAG building framework. We can monitor the evaluation process using langsmith, which helps analyze the reasons for each evaluation and observe the consumption of API tokens.
Continuous Eval: Continuous-eval is an open-source package for evaluating LLM application pipelines. It offers a cheaper and faster evaluation option. Additionally, it allows the creation of trustworthy ensemble evaluation pipelines with mathematical guarantees.
TruLens-Eval: TruLens-Eval is a tool specifically designed for evaluating RAG metrics. It integrates well with LangChain and Llama-Index, making it easy to evaluate RAG applications built on these two frameworks. Additionally, we can launch in a browser to monitor and analyze each evaluation and observe the consumption of API tokens.
Llama-Index: Llama-Index is well-suited for building RAG applications, and its ecosystem is currently quite robust, with rapid and iterative development. It also includes features for evaluating RAG and generating synthetic datasets, making it convenient for users to evaluate RAG applications built using Llama-Index.
In addition, other evaluation tools are functionally similar to the ones mentioned above. Examples include Phoenix, DeepEval, LangSmith, and OpenAI Evals.
These evaluation tools are also constantly evolving, and the respective official documentation provides specific features and usage instructions.
Summary of RAG Evaluation
RAG evaluation is crucial for users and developers. This article will introduce quantitative RAG evaluation methods for your applications from black-box and white-box perspectives and provide practical evaluation tools to help readers quickly understand evaluation techniques and get started. For more information about RAG, please refer to other articles in this series.
 Cheney Zhang
Cheney ZhangCheney Zhang is an accomplished Algorithm Engineer at Zilliz. With a profound passion for and expertise in cutting-edge AI technologies such as LLMs and Retrieval Augmented Generation (RAG), Cheney has actively contributed to many innovative AI projects, including Towhee, Akcio, and OSSChat. Before joining Zilliz, he worked for CMB Network Technology as an Algorithm Engineer. Cheney holds a master's degree from Nanjing University of Aeronautics and Astronautics.
- Black Box End-to-End Evaluation
- How to Quantitatively Calculate these Metrics
- Do we need to annotate ground-truth?
- White-box Evaluation
- The Most Popular Evaluation Benchmark: MTEB
- Introduction to Common Evaluation Tools
- Summary of RAG Evaluation
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Benchmarking Vector Database Performance: Techniques and Insights
Deep diving into key evaluation metrics and tools for vector databases and offering insights to aid in evaluating vector databases for informed decision-making.

Scaling Vector Databases to Meet Enterprise Demands
In this blog, we will explore the concept of database scalability and unravel Milvus's scaling capability. We will also introduce its scalability techniques and explore how they pave the way for unparalleled performance and innovation in unstructured data management.

Introducing an Open Source Vector Database Benchmark Tool for Choosing the Ideal Vector Database for Your Project
Introducing VectorDBBench, an open-source vector database benchmark tool for choosing the ideal vector database for your project.