




Building RAG with Milvus Lite, Llama3, and LlamaIndex
Retrieval Augmented Generation (RAG) is a method for mitigating LLM hallucinations. Learn how to build a chatbot RAG with Milvus, Llama3, and LlamaIndex.
Read the entire series
- Mastering LLM Challenges: An Exploration of Retrieval Augmented Generation
- Key NLP technologies in Deep Learning
- Exploring the Frontier of Multimodal Retrieval-Augmented Generation (RAG)
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- How to Enhance the Performance of Your RAG Pipeline
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- Pandas DataFrame: Chunking and Vectorizing with Milvus
- How to build a Retrieval-Augmented Generation (RAG) system using Llama3, Ollama, DSPy, and Milvus
- Improving Information Retrieval and RAG with Hypothetical Document Embeddings (HyDE)
- Building RAG with Milvus Lite, Llama3, and LlamaIndex
- Enhancing RAG with RA-DIT: A Fine-Tuning Approach to Minimize LLM Hallucinations
- Top 10 RAG & LLM Evaluation Tools You Don't Want To Miss
Large Language Models (LLMs) have demonstrated a remarkable capability to generate human-like textual responses. These models can perform various natural language tasks, such as translation, summarization, code generation, and information retrieval.
To conduct all those tasks, an LLM undergoes a pretraining process on massive amounts of data. During this process, the LLM learns natural languages by predicting the next word in a sentence, given the previous words. This method, known as token prediction, allows the LLM to generate coherent and contextually relevant responses. However, because the model is focused on predicting the most probable next word rather than verifying facts, its output can sometimes be inaccurate or misleading. On the other hand, the pretraining dataset can be outdated, making it difficult for the LLM to answer questions related to the most recent data.
It’s challenging to assess the truthfulness of LLMs’ responses unless you possess expertise in the subject on which the response is based. Retrieval Augmented Generation (RAG) is a method that can be used to mitigate this problem, which we’ll discuss in depth in this article. So, without further ado, let's start with a fundamental introduction to RAG.
Understanding Retrieval-Augmented Generation (RAG)
Large language models (LLMs) are undeniably becoming one of the most discussed topics in AI, as they are exceptionally powerful in tackling various natural language problems. However, they have their limitations, including the so-called knowledge cut-off date. This cut-off date refers to the most recent date of the training data used for the LLM.
For example, GPT-4 Turbo has a knowledge cut-off date of December 2023. We risk receiving inaccurate responses if we ask ChatGPT for real-time updates or information beyond that date. This phenomenon is referred to as LLM hallucination.
A hallucination occurs when the response generated by the LLM appears convincing and coherent, yet its truthfulness is completely off. Detecting hallucinations produced by an LLM is quite challenging and remains an active research area.
While we can calculate metrics like perplexity to assess the quality of the generated text, this approach does not directly address the core issue: how can we ensure that the responses generated by an LLM are factually correct? This is where a concept like RAG comes into play.
RAG is designed to mitigate LLM hallucinations. The process is straightforward: first, we submit a query to the LLM. Instead of submitting that query directly to the LLM, we first identify the relevant context that could assist the LLM in providing a more accurate answer.
Next, we provide the LLM with two inputs: the original query and the most relevant context that could help the LLM answer it. Finally, the LLM generates a response by considering the provided context.
This method ensures that the LLM does not simply produce random outputs in response to our query but rather generates a contextualized and relevant answer.
The Components of RAG
As the name suggests, RAG consists of three major components: retrieval, augmentation, and generation. Let’s first discuss the retrieval component.
The Retrieval Component
The main goal of the retrieval component in RAG is to identify promising context candidates based on a given user query. The first step is transforming the input query into its numerical representation called vector embeddings. The dimensionality of the vector embedding varies depending on the embedding model you use. Numerous open-source and free embedding models are available, such as those from HuggingFace or SentenceTransformers.
These embeddings preserve the semantic meaning of the original text, ensuring that embeddings of two texts with similar meanings are placed in close proximity to each other in the vector space. As a result, we can compute the similarity between any two arbitrary vectors by calculating their Euclidean distance(L2). Below is an example of how these vectors are positioned in a 2D vector space.
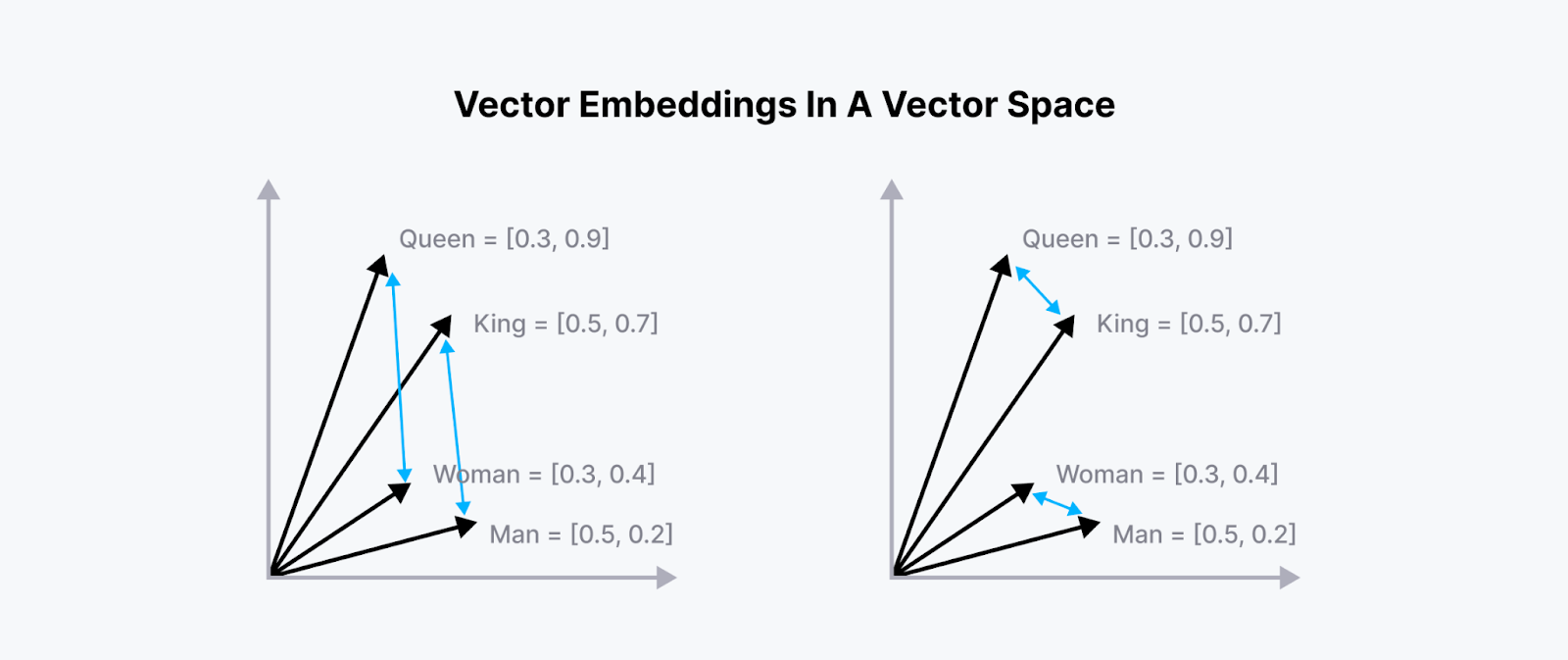 Figure 1- Embeddings in 2D vector space
Figure 1- Embeddings in 2D vector space
Figure 1: Embeddings in 2D vector space
Once you understand the concept of vector embeddings above, grasping how to find promising contexts is straightforward. We must compute the distance between our query's embedding and the contexts' embeddings.
This distance computation between two embeddings is manageable when we have only a few contexts to compare. However, what happens when we have millions of contexts? The computational cost would be prohibitively high, and our local machine would likely be unable to store all those embeddings. Therefore, we need a highly scalable and performant vector database like Milvus to handle this task efficiently.
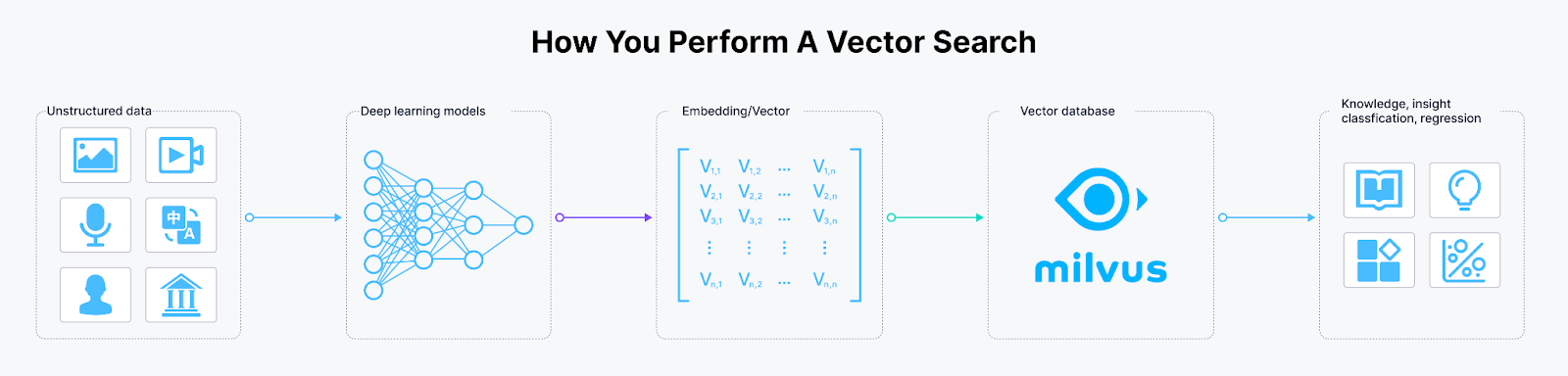 Figure 2- How to perform a vector search
Figure 2- How to perform a vector search
Figure 2: How to perform a vector search
Milvus has advanced indexing algorithms, making it highly efficient for storing billions of context embeddings and performing large-scale vector similarity computations. It also offers easy integration with popular AI frameworks, simplifying the development of RAG-based LLM applications. We will see it in action in the next section.
Augmentation Component
After performing a vector similarity search with the help of a vector database, we move on to the augmentation component. In this stage, the top-k most relevant contexts retrieved from the previous step are combined with the user query to form a complete prompt, which serves as the input to our LLM.
There are many variations of prompts you can try, depending on your specific use case. However, a basic template for the prompt typically looks like this:
Use the following pieces of context to answer the question at the end.
{context}
Question: {question}
Helpful Answer:
And that concludes the augmentation component.
Generation Component
The third and final component of RAG is the generation component. In this stage, the LLM of our choice, such as GPT, Llama, Mistral, Claude, or others, generates a response based on the prompt that contains both the user query and the most relevant contexts.
With this setup, our LLM will generate an answer to the user query based on the provided contexts rather than relying solely on its knowledge from the training data. This approach helps mitigate the risk of hallucination from our LLM.
Below is a visualization of the complete components and workflow of RAG that we have discussed so far:
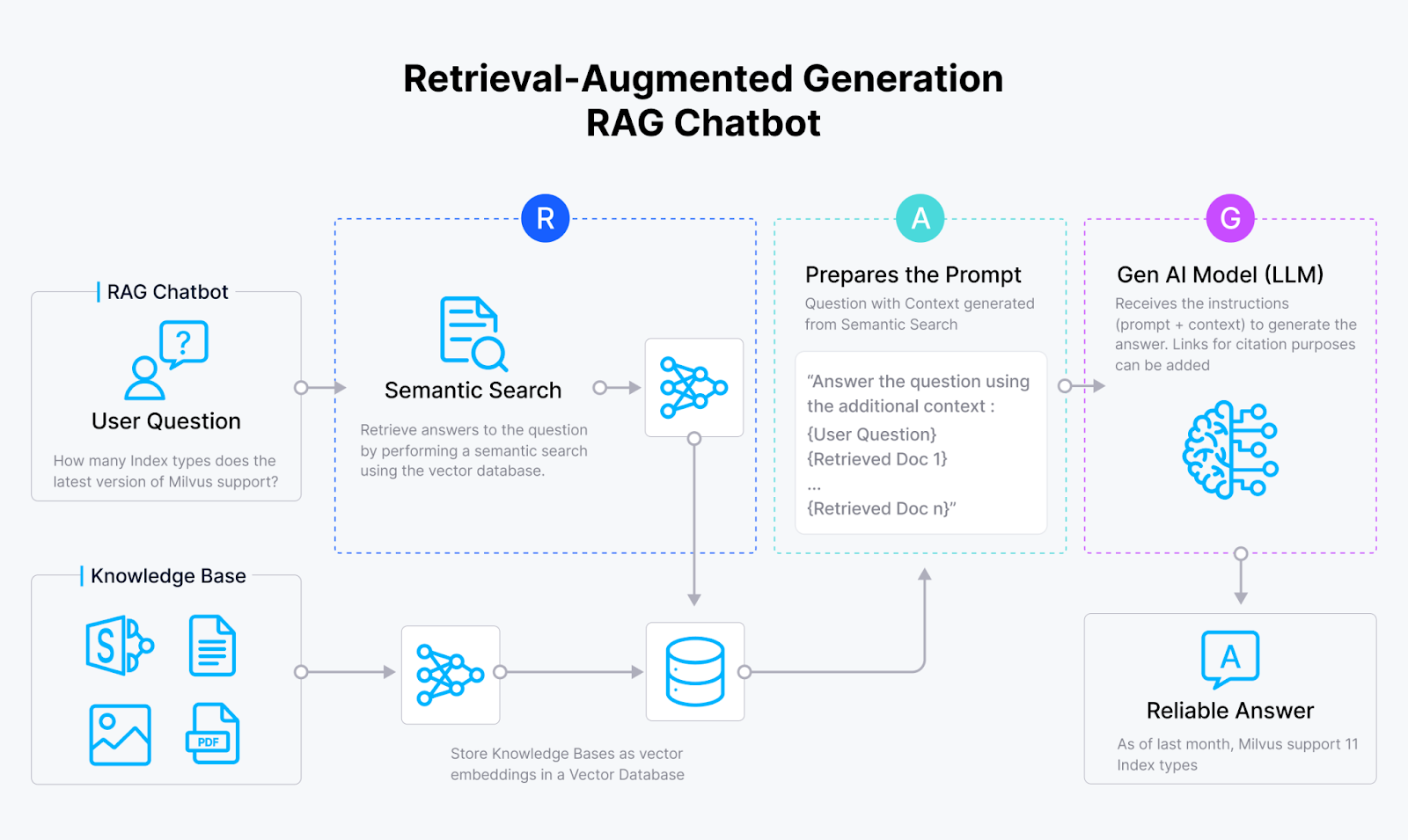 Figure 3- RAG workflow
Figure 3- RAG workflow
Figure 3: RAG workflow
Introduction to Milvus Lite, Llama 3, and LlamaIndex
In the following section, we’ll build a RAG-powered LLM application with Milvus and popular AI frameworks like LlamaIndex. Before diving into the practical implementation, let’s discuss the tools we’ll use in this project.
Milvus Lite
Milvus is an open-source vector database that enables us to store billion-scale vector embeddings and perform efficient vector searches. In the following demo, we’ll use Milvus to store the embeddings of contexts and perform similarity searches between the query and context embeddings.
We can install and instantiate Milvus in different ways, but the easiest method is through Milvus Lite. Milvus Lite is a lightweight version of Milvus, and it is highly recommended for anyone who wants to integrate Milvus into their AI project. It can be used for rapid prototyping, for example, when you want to experiment with different chunking strategies or embedding models for your text documents.
Installing Milvus Lite is very simple. All you need to do is execute the following pip command:
pip install "pymilvus>=2.4.2"
After that, you can immediately instantiate Milvus with Python without any hassle. It's important to note that Milvus Lite would be optimal if you want to store up to a million vector embeddings.
If you want to store more embeddings and use them in a production environment, install and run Milvus in a Docker container or deploy it via Kubernetes clusters. This installation guide explains how to install Milvus in Docker and Kubernetes.
Llama3
In addition to the vector database, another critical component of a RAG system is the LLM itself. Several open-source LLMs are available in the market, with Llama and Mistral being two of the most popular options. In this article, we will use the Llama3 model developed by Meta as our LLM. The Llama3 model has been pre-trained on a dataset seven times larger than the previous Llama2 model, leading to improved performance.
Two different sizes of the Llama3 model are available: one with 8 billion parameters and another with 70 billion parameters. Both models have demonstrated competitive performance on benchmark datasets compared to other LLMs of similar size brackets, as shown in the image below.
 Figure 4- Llama3 performance on benchmark datasets. Source
Figure 4- Llama3 performance on benchmark datasets. Source
Figure 4: Llama3 performance on benchmark datasets. Source.
This article will use the Llama3 model with 8 billion parameters. By default, an 8 billion parameter model requires approximately 32 GB of VRAM, surpassing the typical VRAM available on free GPUs. However, we can reduce the model's size to about 4 GB of VRAM by performing a 4-bit quantization.
There are multiple ways to load the Llama3 model and apply 4-bit quantization. The first method combines the Hugging Face library and the bitsandbytes library. The second method installs Ollama and loads the model directly there. By default, LLMs on Ollama are already quantized to 4 bits.
We will use the Ollama option. With Ollama, you can effortlessly run various LLMs on your local machine. To download Llama3, you first need to install Ollama. Please refer to their documentation for the latest installation steps.
Once you have installed Ollama on your machine, you can download any LLM. In our case, since we are using Llama3, you can execute the following command in the terminal:
ollama run llama3
LlamaIndex
LlamaIndex is a highly useful framework for orchestrating a RAG pipeline. We installed our vector database and LLM for our RAG application in the previous subsections. What’s missing now is the framework that connects these two components to build a fully functioning RAG system. This is where LlamaIndex comes into play.
LlamaIndex provides easy-to-use methods for preprocessing our input data from various sources, converting it into vector embeddings, storing the embeddings in a vector database, fetching relevant contexts, sending them to our LLM, and outputting the response from the LLM.
We can install LlamaIndex using a simple pip command. Below are the commands needed to use LlamaIndex in this project. We will explore the implementation details in the next section.
pip install llama
pip install llama-index-vector-stores-milvus llama-index-llms-ollama llama-index-embeddings-huggingface
Building a Chatbot RAG with Milvus Lite, LLama3, and LlamaIndex
It’s time for us to implement a RAG system with Milvus Lite, Llama3, and LlamaIndex. For our use case, let’s say we want to build a chatbot RAG system to help us answer some questions about the content of a research paper. Specifically, we want our LLM to answer questions about the “Attention is All You Need” paper, which introduced us to the famous Transformer architecture. You can use any research paper that you want.
All of the code presented in this article is available in this notebook so you can follow along. First, let’s import all of the necessary libraries:
!pip install arxiv
import arxiv
from llama_index.core import SimpleDirectoryReader
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import VectorStoreIndex, Settings
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from pymilvus import MilvusClient
The first step is downloading the PDF research paper onto our local machine. We can do so with the official Python library from Arxiv.
dir_name = "./Documents/pdf_data/"
arxiv_client = arxiv.Client()
paper = next(arxiv.Client().results(arxiv.Search(id_list=["1706.03762"])))
# Download the PDF to a specified directory with a custom filename.
paper.download_pdf(dirpath=dir_name, filename="attention.pdf")
In the code above, we downloaded the “Attention is All You Need” paper into a local directory by accessing its ID. If you notice, each research paper on Arxiv has its ID in the URL, and you can just copy the ID to the code above to download the research paper of your choice.
Next, we can instantiate the Milvus vector database and the Llama3 model. As an embedding model to transform raw input texts into their vector embedding representations, we’ll use the BGE base model that we can load from HuggingFace.
vector_store = MilvusVectorStore(
uri="./milvus_rag_demo.db", dim=768, overwrite=True
)
embedding_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
llm = Ollama(model="llama3",temperature=0.1, request_timeout=480.0)
As you can see, we instantiated a Milvus vector database with vector embedding of size 768, which is the embedding dimension provided by the BGE base model.
Now let’s ingest the downloaded PDF paper such that it can be processed by our embedding model. With LlamaIndex, we only need to call SimpleDirectoryReader object to do this:
pdf_document = SimpleDirectoryReader(
input_files=[f"{dir_name}attention.pdf"]
).load_data()
print("Number of Input documents:", len(pdf_document))
# OR execute this command if you have multiple PDFs inside the directory
pdf_document = SimpleDirectoryReader(
dir_name, recursive=True
).load_data()
"""
Output:
Number of Input documents: 15
"""
The number of input documents is 15, as our paper consists of 15 pages.
To bind our LLM and embedding model such that they can be used in the whole RAG pipeline, we need to use the Settings class from LlamaIndex. In this class, we can also customize the chunk size and overlap of our PDF data.
Settings.llm = llm
Settings.embed_model = embedding_model
Settings.chunk_size = 128
Settings.chunk_overlap = 64
Next, let’s ingest our PDF data into the Milvus vector database. With the following command, the PDF data will be split into chunks, and each chunk will be transformed into a vector embedding using our BGE base model. Finally, the chunk embeddings will be stored inside the Milvus vector database.
index = VectorStoreIndex.from_documents(pdf_document)
print("Number of nodes:", len(index.docstore.docs))
query_engine = index.as_query_engine()
"""
Output:
Number of nodes: 196
"""
As you can see, we now have 196 chunk embeddings inside our vector database. We also call the as_query_engine method in our index , which allows us to ask questions over our data inside of our vector database.
And that’s all we need to build a fully functioning RAG pipeline with LlamaIndex. Now we can ask a question related to our research paper. For example, let’s ask, “What is the benefit of multi-head attention instead of single-head attention?”. We can do so by executing the following command:
query = "What is the benefit of multi-head attention instead of single-head attention?"
result = query_engine.query(query)
print(result)
"""
Output:
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
"""
Based on the information provided by the research paper, we get a highly contextual answer! Using the same logic, you can easily ask any question related to a complex topic in a research paper with RAG.
Optimizing the RAG Pipeline
Deploying a RAG pipeline in production is more challenging than prototyping. One common issue is assessing the quality of the responses generated by our RAG system. Fortunately, several open-source tools, like Ragas and TruLens-Eval, are available to evaluate the response quality of RAG systems.
With Ragas, you can evaluate two critical components of a RAG system: retrieval and generation. To assess the quality of the retrieval component, Ragas provides methods to evaluate the precision of the contexts used by our LLM to generate answers. Meanwhile, metrics such as faithfulness and answer relevancy are commonly employed to evaluate the generation component. You can find the full details of these metrics in the relevant documentation.
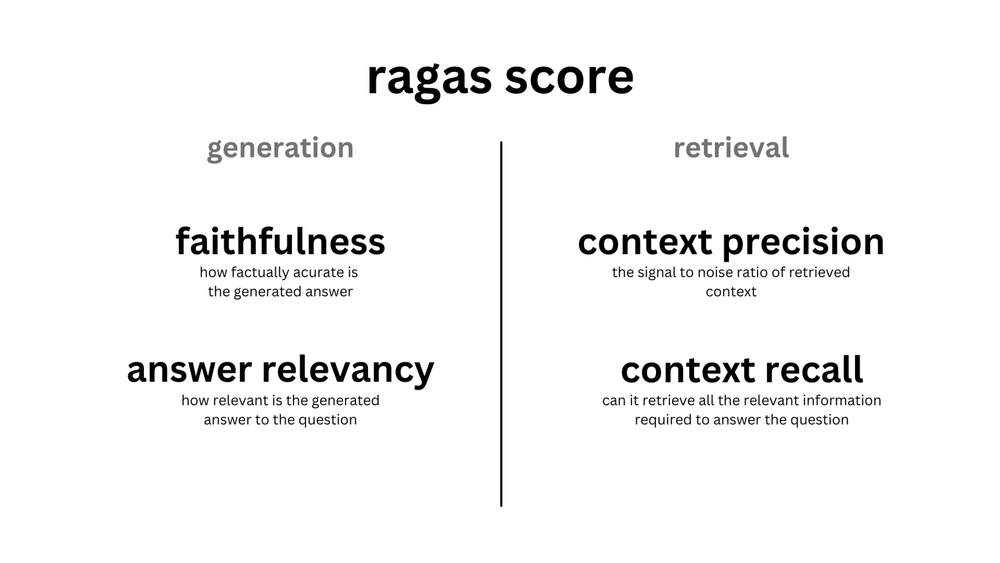 Figure 5- Figure RAG evaluation metrics using Ragas
Figure 5- Figure RAG evaluation metrics using Ragas
Figure 5: Figure RAG evaluation metrics using Ragas
Assessing these metrics is an important first step if we notice any deterioration in our RAG’s response quality. If we identify poor results from our RAG based on these assessments, we need to take steps to improve it. However, it is crucial to start by evaluating the quality of our data.
We must ask ourselves: Do we have the right data in the vector database to effectively answer the questions? Are we splitting our data into appropriate chunk sizes? Do we need to clean our data before splitting it into chunks?
Once we are confident that data quality is not the issue, we can enhance our RAG pipeline by, for example, replacing the LLM and embedding the model with more performant alternatives.
For more information about techniques and tools for RAG observability, evaluation and optimization, we recommend reading the following blogs:
Conclusion
Building a RAG pipeline has never been simpler, thanks to the introduction of various AI frameworks like Ollama, LlamaIndex, and HuggingFace. With Milvus, we can efficiently store a massive number of context embeddings and offer seamless integration with various AI frameworks. As a result, we can build a RAG pipeline with just a few lines of code.
The RAG use case presented in this article is just one of countless applications you can implement. The addition of Milvus Lite allows you to quickly set up a vector database and prototype several RAG use cases easily with a single pip install command. Be sure to try it out to build your own RAG system!
Additional Resources

- Understanding Retrieval-Augmented Generation (RAG)
- The Components of RAG
- Introduction to Milvus Lite, Llama 3, and LlamaIndex
- Building a Chatbot RAG with Milvus Lite, LLama3, and LlamaIndex
- Optimizing the RAG Pipeline
- Conclusion
- Additional Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

How to Enhance the Performance of Your RAG Pipeline
This article summarizes various popular approaches to enhancing the performance of your RAG applications. We also provided clear illustrations to help you quickly understand these concepts and techniques and expedite their implementation and optimization.

Pandas DataFrame: Chunking and Vectorizing with Milvus
If we store all of the data, including the chunk text and the embedding, inside of Pandas DataFrame, we can easily integrate and import them into the Milvus vector database.
How to build a Retrieval-Augmented Generation (RAG) system using Llama3, Ollama, DSPy, and Milvus
In this article, we aim to guide readers through constructing an RAG system using four key technologies: Llama3, Ollama, DSPy, and Milvus. First, let’s understand what they are.