




Mastering LLM Challenges: An Exploration of Retrieval Augmented Generation
This RAG handbook explores its advantages, the challenges it can address, & why its the preferred choice for elevating the performance of gen AI apps.
Read the entire series
- Mastering LLM Challenges: An Exploration of Retrieval Augmented Generation
- Key NLP technologies in Deep Learning
- Exploring the Frontier of Multimodal Retrieval-Augmented Generation (RAG)
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- How to Enhance the Performance of Your RAG Pipeline
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- Pandas DataFrame: Chunking and Vectorizing with Milvus
- How to build a Retrieval-Augmented Generation (RAG) system using Llama3, Ollama, DSPy, and Milvus
- Improving Information Retrieval and RAG with Hypothetical Document Embeddings (HyDE)
- Building RAG with Milvus Lite, Llama3, and LlamaIndex
- Enhancing RAG with RA-DIT: A Fine-Tuning Approach to Minimize LLM Hallucinations
- Top 10 RAG & LLM Evaluation Tools You Don't Want To Miss
A four-part series RAG handbook
Large language models (LLMs) have remade the world of AI with advanced natural language processing (NLP) capabilities. Despite their strengths, LLMs encounter challenges, including hallucinations, slow knowledge updates, and a need for answer transparency in real-world applications. Retrieval-augmented generation (RAG) emerges as a prominent AI framework, effectively tackling these issues by integrating external knowledge into the model's responses.
This four-part series handbook looks into RAG, exploring its architecture, advantages, the challenges it can address, and why it stands as the preferred choice for elevating the performance of generative AI applications.
A brief review of RAG and Milvus
RAG is an AI framework that can enhance the capabilities of LLMs by providing LLM external knowledge in the query context, ensuring more accurate and current responses. A standard RAG system includes an LLM, a vector database like Milvus, and some prompts as code. Imagine constructing a chatbot for employees to access internal documents. With RAG, users can obtain accurate information from reliable private sources, addressing a limitation that even powerful LLMs like ChatGPT struggle to overcome.
Large language model Limitations
While LLMs have showcased impressive capabilities, they have limitations. ChatGPT, for example, has training data only until September 2021. Consequently, it lacks factual knowledge about events occurring after that date. ChatGPT might provide imaginative and believable yet inaccurate information when asked about recent occurrences, known as "hallucinations."
To be more specific, LLMs, including the powerful ChatGPT, face the following challenges:
- Lack of Domain-Specific Information: LLMs predominantly rely on publicly available data, limiting nuanced understanding of domain-specific, proprietary, or private information. The lack of access to private data hinders the model's capacity to tailor solutions or responses for specialized industries or applications.
- Inability to Access Up-to-Date Information: LLMs are trained on static datasets, limiting their access to the most recent or dynamically changing information. They need to update their knowledge base regularly but do not due to high training costs. For instance, training GPT-3 can cost up to 4 million dollars. Therefore, the generated results can be outdated.
- Prone to hallucinations: Because these models derive answers solely from their training data, they may produce misleading, incorrect, or entirely fabricated responses when they lack relevant information.
- Immutable pre-training data: The pre-training data utilized by LLMs is immutable. Any incorrect or outdated information included during the training phase persists, as there is currently no mechanism to modify, correct, or remove such data post-training.
Addressing LLM limitations: Fine-tuning vs. RAG
Two techniques can address LLM limitations: fine-tuning and RAG.
Fine-tuning LLMs
Fine-tuning is continuously training a pre-trained LLM with the latest or domain-specific knowledge, addressing hallucinatory issues, and yielding more accurate results. However, it is complex, resource-demanding, and only suitable for large businesses. For instance, fine-tuning LLMs like Llama 2 or ChatGPT involves gathering and preprocessing massive amounts of relevant data. Additionally, it necessitates a robust computing infrastructure for effective training. The associated costs, including substantial computational resources and memory, can financially burden small businesses. Fine-tuning an LLM is an iterative process. You must fine-tune the model multiple times, adjust hyperparameters, and experiment with different training techniques. Each iteration requires additional computational resources, adding to the overall cost. For example, fine-tuning a GPT-3 model on a custom database may cost millions.
Moreover, post-training, continuous evaluation and fine-tuning are crucial processes. They involve iterative testing, performance improvement, adjusting hyperparameters, and repeating the training process. This ongoing commitment may challenge small enterprises to allocate dedicated resources or hire experts regularly.
RAG
As mentioned earlier, RAG is an AI framework that effectively mitigates hallucinations in LLMs by providing them with additional and highly relevant knowledge related to users' queries. The framework boasts several advantages:
- Elevated Accuracy: RAG provides LLMs with external knowledge, mitigating hallucinations in LLMs and yielding more refined answers.
- Flexibility: RAG allows for knowledge updates at any time. This feature ensures strong adaptability and seamless incorporation of new information, with updating a knowledge base taking just a few minutes.
- Horizontal Scalability: RAG adeptly handles extensive datasets without requiring updates to all parameters. It is also horizontally scalable, enabling seamless accommodation of expanding datasets. This scalability aligns perfectly with users' evolving needs and positions RAG as a more efficient and cost-effective alternative to fine-tuning.
- Transparency: By referencing sources, users can verify the accuracy of answers, allowing for increased trust in the model's outputs.
- Security: RAG apps securely store private data in a user-controlled vector database. Additionally, it incorporates built-in roles and security controls within the knowledge base, improving data management and providing enhanced control over data usage.
- Cost-effectiveness: RAG demands significantly fewer computer resources than fine-tuning, resulting in substantial cost savings.
In analogy, RAG functions like an open-book exam, allowing easy adaptation to new challenges by replacing the reference book. On the other hand, fine-tuning resembles a closed-book exam, demanding substantial time investment in learning and digesting new knowledge for every iteration.
How RAG works
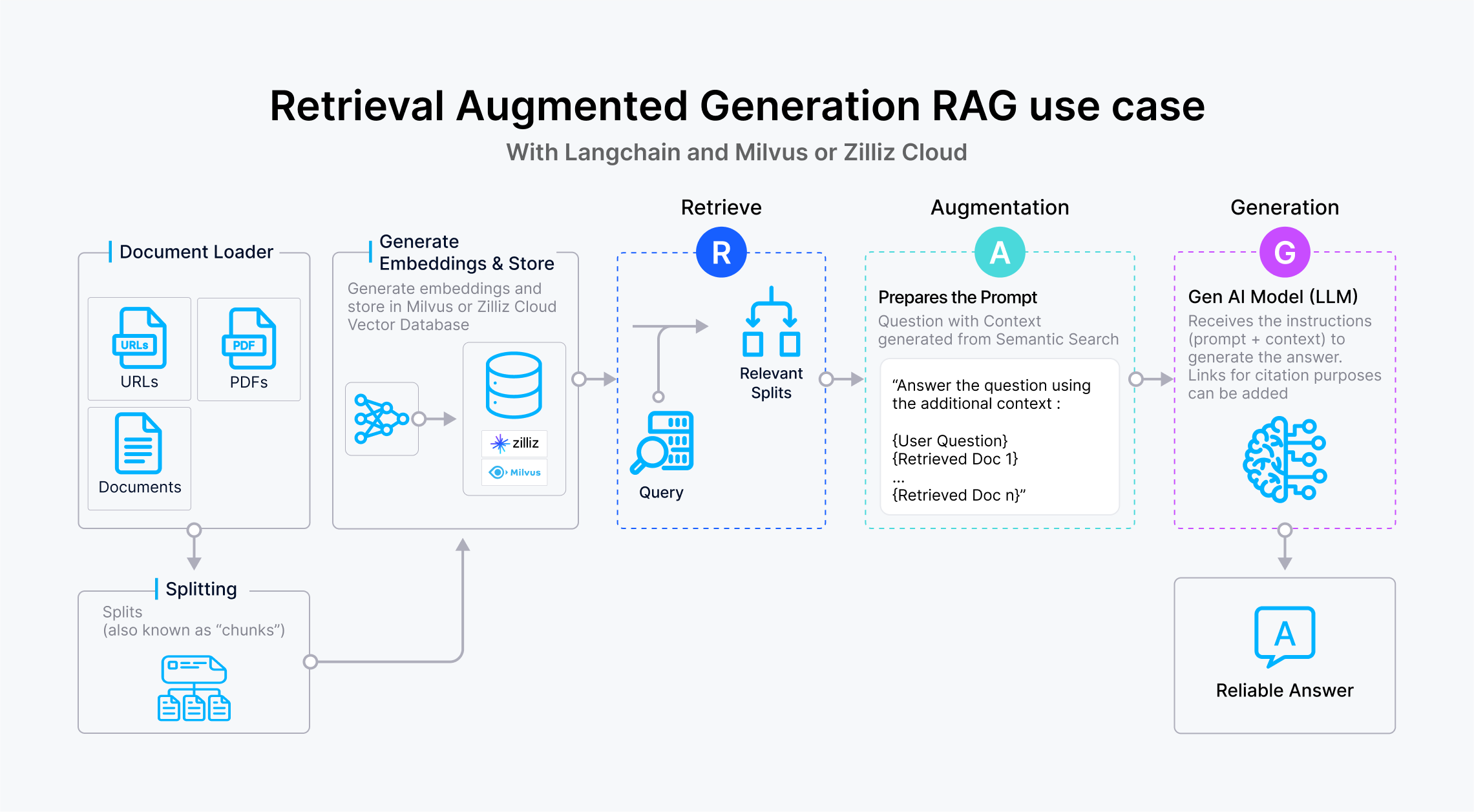 RAG use case with LangChain and Zilliz Cloud
RAG use case with LangChain and Zilliz Cloud
As shown in the graphic above, a RAG system comprises three crucial processes: Retrieval, augmentation, and Generation. The Retrieval process focuses on fetching relevant information for user queries. The Augmented process involves crafting a new prompt that merges the original question with the context information retrieved from the vector database. Lastly, by leveraging LLMs with the provided context, the generation process produces more accurate answers.
Retrieval
The retrieval process comprises Knowledge Ingestion and Vector Similarity Search.
- Knowledge Ingestion: Before querying your RAG application, insert all your external knowledge into a vector database like Zilliz Cloud as vector embeddings.
- Vector Similarity Search: When users ask a question, an embedding model converts it into vector embeddings. These embeddings are then sent to the vector database for a similarity search, where the Top-K most relevant results are retrieved. The results serve as the context for users' questions and are forwarded to the LLM along with the original question to generate responses.
Augmented
The "Augmented" process entails assembling the retrieved knowledge into a prompt, representing the "knowledge-based enhancement" of the original question. Below is a prompt example:
{User Question}
{Retrieved Doc 1}
{Retrieved Doc n}
In practice, {User Question} is replaced by the actual user question, and {Retrieved Doc i} is replaced by the retrieved knowledge fragments.
An assembled prompt looks like this:
{What is RAG?}
{Retrieval-augmented generation (RAG) is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM’s internal representation of information.
RAG allows LLMs to build a specialized body of knowledge to answer questions in a more accurate way.}
Generation
The Generation process involves presenting the prompt directly to an LLM for a more accurate answer. Here is ChatGPT’s response to the provided prompt shown above:
RAG stands for Retrieval-augmented generation, which is an AI framework that enhances the quality of responses generated by LLMs by incorporating external sources of knowledge to supplement the model's internal representation of information. It allows LLMs to utilize specialized knowledge to provide more accurate answers to questions.
Conclusion
In this blog, we provided:
- An overview of RAG.
- Highlighting its fundamentals, workflows, and advantages.
- Its role is to address the challenges facing large language models.
We also compared fine-tuning and RAG, two approaches aimed at mitigating hallucinations in LLMs.
While fine-tuning offers the advantage of continuous training for the most current information and domain specificity, its complexity and resource-intensive nature may only be suitable for some developers or businesses, particularly larger ones. On the contrary, RAG stands out for its ability to generate highly accurate and relevant results. It is more cost-effective, scalable, and flexible than fine-tuning and proves highly applicable across a spectrum of generative AI tasks. In our upcoming posts, we will explore further topics, including constructing RAG applications and strategies for their evaluation and optimization. Stay tuned for more insights!
 Cheney Zhang
Cheney ZhangCheney Zhang is an accomplished Algorithm Engineer at Zilliz. With a profound passion for and expertise in cutting-edge AI technologies such as LLMs and Retrieval Augmented Generation (RAG), Cheney has actively contributed to many innovative AI projects, including Towhee, Akcio, and OSSChat. Before joining Zilliz, he worked for CMB Network Technology as an Algorithm Engineer. Cheney holds a master's degree from Nanjing University of Aeronautics and Astronautics.
- A brief review of RAG and Milvus
- Large language model Limitations
- Addressing LLM limitations: Fine-tuning vs. RAG
- How RAG works
- Augmented
- Generation
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Key NLP technologies in Deep Learning
An exploration of the evolution and fundamental principles underlying key Natural Language Processing (NLP) technologies within Deep Learning.

Exploring the Frontier of Multimodal Retrieval-Augmented Generation (RAG)
Multimodal RAG is an extended RAG framework incorporating multimodal data including various data types such as text, images, audio, videos etc.

Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
By integrating GPTCache and Milvus with ChatGPT, businesses can create a more robust and efficient AI-powered support system. This approach leverages the advanced capabilities of generative AI and introduces a form of long-term memory, allowing the AI to recall and reuse information effectively.