




Key NLP technologies in Deep Learning
An exploration of the evolution and fundamental principles underlying key Natural Language Processing (NLP) technologies within Deep Learning.
Read the entire series
- Mastering LLM Challenges: An Exploration of Retrieval Augmented Generation
- Key NLP technologies in Deep Learning
- Exploring the Frontier of Multimodal Retrieval-Augmented Generation (RAG)
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- How to Enhance the Performance of Your RAG Pipeline
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- Pandas DataFrame: Chunking and Vectorizing with Milvus
- How to build a Retrieval-Augmented Generation (RAG) system using Llama3, Ollama, DSPy, and Milvus
- Improving Information Retrieval and RAG with Hypothetical Document Embeddings (HyDE)
- Building RAG with Milvus Lite, Llama3, and LlamaIndex
- Enhancing RAG with RA-DIT: A Fine-Tuning Approach to Minimize LLM Hallucinations
- Top 10 RAG & LLM Evaluation Tools You Don't Want To Miss
In the previous section, we briefly introduced the basic framework of Retrieval Augmented Generation (RAG) technology. However, this application involves several key technologies you may have heard of but need help understanding, such as embeddings, Transformers, BERT, and LLMs. This article will comprehensively explain these key technologies' development history and fundamental principles.
The development of deep learning has given rise to numerous key Natural Language Processing (NLP) technologies. These include early models like word2vec and the latest model, ChatGPT, and applications ranging from word embeddings to text generation. This article will introduce the applications of these technologies and their progression.
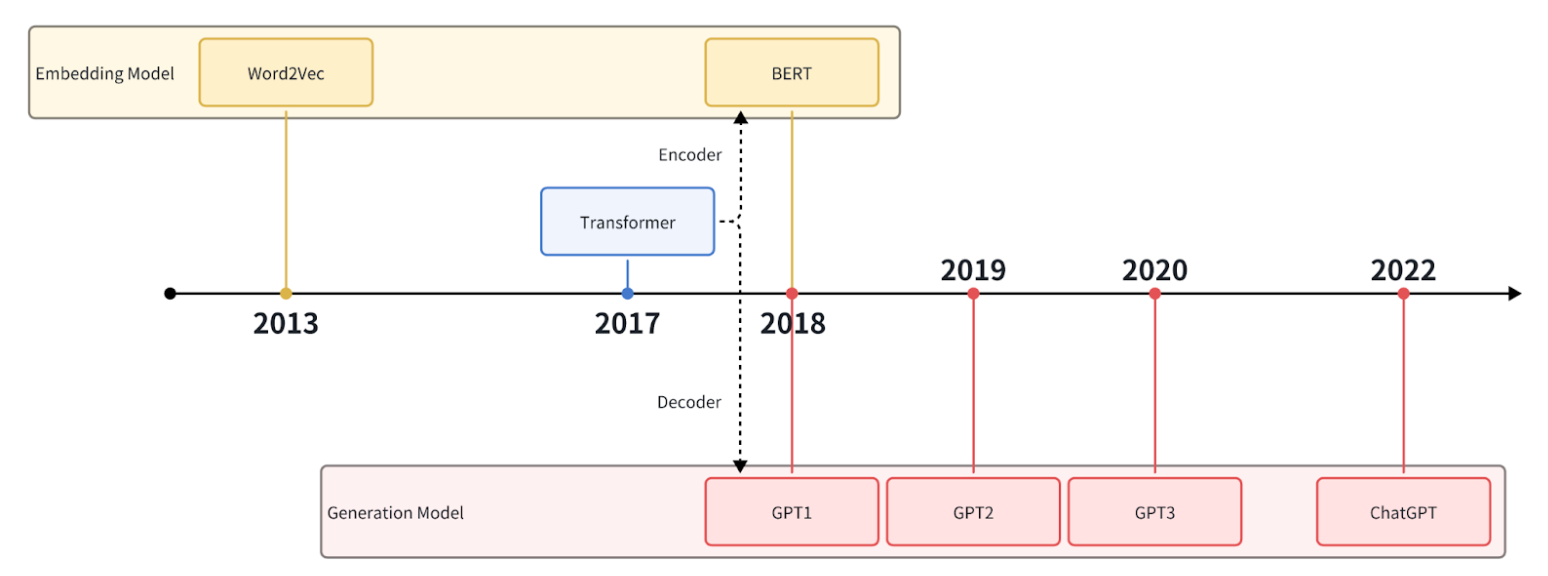 History of ChatGPT.png
History of ChatGPT.png
What is an Embedding?
Embeddings are a technique that transforms discrete and unstructured data into continuous vector representations.
In Natural Language Processing, Embeddings are commonly used to map words, sentences, or documents in text data to fixed-length real-valued vectors, allowing for better computer processing and understanding of the text data. Embeddings can represent each word or sentence by a real-valued vector containing semantic information. As a result, similar words or sentences are mapped to similar vectors in the embedding space, and words or sentences with similar semantics have shorter distances in the vector space. This allows for tasks such as matching, classifying, and clustering words or sentences in NLP by calculating distances or similarities between vectors.
 Unstructured Data to Vectors.png
Unstructured Data to Vectors.png
Word2Vec
Word2Vec is a word embedding method Google proposed in 2013. It was one of the more mainstream Word Embedding methods before 2018. Word2Vec has been widely used in various natural language processing tasks as a classic algorithm for word vectors. It learns the semantic and syntactic relationships between words by training on a corpus and maps words to dense vectors in a high-dimensional space. The advent of Word2Vec pioneered the transformation of words into vector representations, extensively promoting the development of the field of natural language processing.
The Word2Vec model can be used to map each word to a vector, which can represent the relationship between words. The figure below shows an example of a 2-dimensional vector space (which could be of higher dimensions).
 2 dimensional vectors.png
2 dimensional vectors.png
The depicted 2-dimensional space showcases unique word distributions, highlighting semantic relationships. For instance, transitioning from "man" to "woman" involves adding a vector in the upper-right direction, akin to a "masculinity-to-femininity transformation." Similarly, a structural vector can be observed, transforming "Paris" to "France," representing "country-to-capital" transitions.
This interesting phenomenon indicates that the distribution of vectors in the embedding space is not chaotic and random. Apparent features indicate which region represents which category and the differences between regions. From this, we can conclude that the similarity of vectors represents the similarity of the original data.
Therefore, vector search actually represents a semantic search of the original data. We can use vector search to implement many semantic similarity search operations.
However, as an early technology, Word2Vec also has certain limitations. Due to the one-to-one relationship between words and vectors, it cannot solve the problem of polysemy. For example, the word "bank" in the following examples does not have the same meaning:
...very useful to protect banks or slopes from being washed away by river or rain...
...the location because it was high, about 100 feet above the bank of the river...
...The bank has plans to branch throughout the country...
...They throttled the watchman and robbed the bank...
Word2Vec is a static method, although it is versatile, it cannot be dynamically optimized for specific tasks.
The Rise of Transformers
Although Word2Vec performs well in word vector representation, it does not capture the complex relationships between contexts. The transformer model was introduced to better handle context dependencies and semantic understanding.
The Transformer is a neural network model based on a self-attention mechanism that Google researchers first proposed and applied to natural language processing tasks in 2017. It can model the relationships between words at different positions in the input sentence, thereby better-capturing context information. The introduction of the Transformer marks a major innovation in neural network models in natural language processing, resulting in significant performance improvements in tasks such as text generation and machine translation.
Initially, the Transformer was proposed for machine translation tasks, and significant performance improvements were achieved. This model consists of an "Encoder" and a "Decoder", where the Encoder encodes the input language sequence into a series of hidden representations, and the Decoder decodes these hidden representations into the target language sequence. Each Encoder and Decoder consists of multiple layers of self-attention mechanisms and feed-forward neural networks.
Compared with traditional CNN (convolutional neural network) and RNN (recurrent neural network), the Transformer can achieve more efficient parallel computing because the self-attention mechanism allows all input positions to be calculated simultaneously. At the same time, CNN and RNN require sequential calculations. Traditional CNN and RNN encounter difficulties handling long-distance dependency relationships, while the Transformer learns long-distance dependency relationships using self-attention mechanisms.
Due to the outstanding performance of the original Transformer model on large-scale tasks, researchers began to try adjusting its size to improve performance. They found that by increasing the model's depth, width, and number of parameters, the Transformer can better capture the relationships and patterns between input sequences.
Another significant development of the Transformer is the emergence of large-scale pre-trained models. By training on a large amount of unsupervised data, pre-trained models can learn richer semantic and syntactic features and fine-tune them on downstream tasks. These pre-trained models include BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer), etc., which have succeeded dramatically in various natural language processing tasks.
The development of the Transformer has brought about a considerable transformation in artificial intelligence. For example, the encoder part has evolved into the BERT series and various embedding models. The decoder part has developed into the GPT series, which has led to the revolution of LLM (Large Language Model), including the current ChatGPT.
BERT and sentence embedding
The Encoder part of the Transformer has evolved into BERT. BERT uses a two-stage pre-training method: Masked Language Model (MLM) and Next Sentence Prediction (NSP). In the MLM stage, BERT predicts masked vocabulary to help it understand the context of the entire sequence. In the NSP stage, BERT determines whether two sentences are consecutive to help it understand the relationship between sentences. The pre-training in these two stages enables BERT to have powerful semantic learning capabilities and perform excellently in various natural language processing tasks.
One critical application of BERT is sentence embedding, which generates an embedding vector for a sentence. This vector can be used for various downstream natural language processing tasks, such as sentence similarity calculation, text classification, sentiment analysis, etc. Using sentence embedding; sentences can be transformed into vector representations in high-dimensional space, enabling computers to understand and express the semantics of sentences.
Compared to traditional word embedding-based methods, BERT's sentence embedding can capture more semantic information and sentence-level relationships. By taking the entire sentence as input, the model can comprehensively consider the contextual relationships between words within the sentence and the semantic relevance between sentences. This provides a more robust and flexible tool for solving natural language processing tasks.
Why Embedding search works better than search based on word frequency
Traditional algorithms based on term frequency search include TF-IDF and BM25. Term frequency search only considers the frequency of words in the text, ignoring the semantic relationship between words. On the other hand, embedding search maps each word to a vector representation in a vector space, capturing the semantic relationships between words. Therefore, when searching, one can calculate the similarity between words to match relevant texts more accurately.
Term frequency search can only perform exact matches and performs poorly for synonyms or semantically related words. In contrast, embedding search can achieve fuzzy matching for synonyms and semantically related words by calculating the similarity between words, thus improving the coverage and accuracy of the search. Embedding search can better utilize the semantic relationship between words, improving search results' accuracy and coverage and producing better results than frequency-based search.
Using a term frequency-based search method, if we search for "cat," the articles with a higher frequency of the word "cat" may be ranked higher in the results. However, this method does not consider the semantic relationship between "cat" and other animals, such as "British Shorthair" or "Ragdoll." On the other hand, using embedding search, words can be mapped to vectors in a high-dimensional space, where semantically similar words are closer in distance. When we search for "cat," embedding search can find semantically similar words like "British Shorthair" and "Ragdoll" and rank articles related to these words higher in the results. This provides more accurate and relevant search results.
Development of Large Language Models
What is LLM
Currently, most large-scale language models (LLMs) are derived from the "decoder-only" Transformer architecture, such as GPT. Compared to models like BERT, which only uses the Transformer encoder, LLMs that only use the decoder can generate text with a certain contextual semantic.
The training task of a Language Model is to predict the probability of the next word based on historical context. By continuously predicting and adding the next word, the model can obtain more accurate and fluent predictions. This training process helps the language model better understand language patterns and contextual information, improving its natural language processing capabilities.
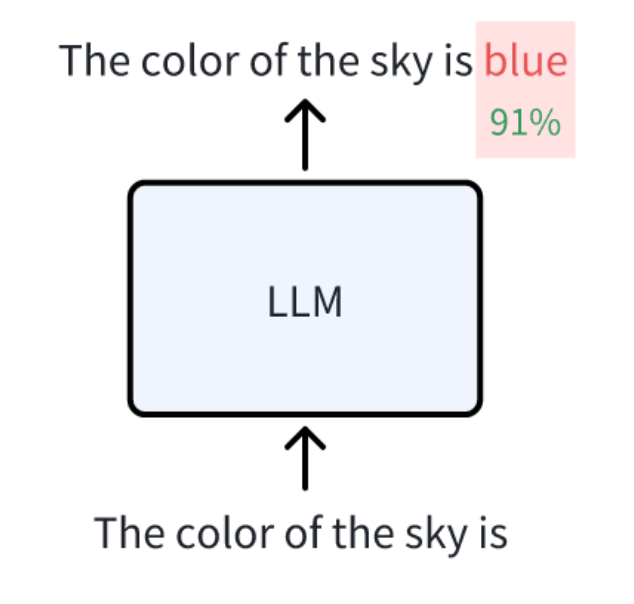 Color of the sky.png
Color of the sky.png
From GPT-1 to GPT-3
The GPT series is a continuously iterated and improved LLM model developed by OpenAI since 2018.
The initial version, GPT-1, had semantic incoherence and repetition issues when generating long texts. GPT-2, released in 2019, addressed these problems by making several improvements based on GPT-1. These improvements included using larger-scale training data, a deeper model structure, and more training iterations. GPT-2 significantly enhanced the quality and coherence of generated text and introduced the capability of zero-shot learning, allowing it to reason and generate text for unseen tasks. GPT-3 further enhanced and expanded the model's scale and capabilities based on GPT-2. With 175 billion parameters, GPT-3 possesses powerful generation capabilities, enabling it to generate longer, more logical, and consistent text. GPT-3 also introduced more contextual understanding and reasoning abilities, allowing for deeper analysis of questions and providing more accurate answers.
| GPT-1 | GPT-2 | GPT-3 | |
|---|---|---|---|
| Parameters | 117 Million | 1.5 Billion | 175 Billion |
| Decoder Layers | 12 | 48 | 96 |
| Context Token Size | 512 | 1024 | 2048 |
| Hidden Layer | 768 | 1600 | 12288 |
| Batch Size | 64 | 512 | 3.2M |
| Pretrain dataset size | 5GB | 40GB | 45TB |
From GPT-1 to GPT-3, OpenAI's language generation models have made significant improvements in data scale, model structure, and training techniques, resulting in higher-quality, more logical, and consistent text generation capabilities. When OpenAI developed GPT-3, it demonstrated some distinct effects compared to previous LLMs. GPT-3 has the following abilities:
- Language completion: Given a prompt, GPT-3 can generate sentences that complete the prompt.
- In-context learning: Following a few examples related to a given task, GPT-3 can reference them and generate similar responses for new use cases. In-context learning is also known as few-shot learning.
- World knowledge: This includes factual knowledge and common knowledge.
ChatGPT
In November 2022, OpenAI released ChatGPT, a chatbot that can answer almost any question. Its performance is excellent, and you can use it to summarize documents, translate, write code, and draft any kind of text. With the help of some tools, you can even order food, book flights, assist in computer takeover, and accomplish tasks you couldn't have imagined before.
Behind this powerful functionality is the support of technologies such as Reinforcement Learning from Human Feedback (RLHF), which enhances the satisfaction of conversations between the model and humans. RLHF is a reinforcement learning method that uses human feedback to align the model's output with human preferences. The specific process involves generating multiple potential answers based on given prompts, having human evaluators rank these answers, training a preference model using these ranking results to learn how to assign scores reflecting human preferences to the answers, and finally fine-tuning the language model using the preference model. This is why you find ChatGPT so useful. Compared to GPT-3, ChatGPT goes even further and unlocks powerful capabilities:
- Responding to human instructions: GPT-3's output usually continues from the prompt, even if it's an instruction. GPT-3 may generate more instructions, while ChatGPT can effectively answer these instructions.
- Code generation and understanding: The model has been trained extensively with code, allowing ChatGPT to generate high-quality, runnable code.
- Complex reasoning with chain-of-thought: The initial version of GPT-3 had weak or no ability for chain-of-thought reasoning. This ability makes ChatGPT more robust and accurate through prompt engineering in higher-level applications.
- Detailed responses: ChatGPT's responses are generally detailed to the point where users have to explicitly request "give me a concise answer" to receive a more succinct response.
- Fair responses: ChatGPT usually provides balanced responses when dealing with interests from multiple parties, aiming to satisfy everyone. It also refuses to answer inappropriate questions.
- Rejecting questions beyond its knowledge scope: For example, it refuses to answer questions about events occurring after June 2021 because it wasn't trained on data beyond that point. It also refuses to answer questions it hasn't seen in its training data.
However, ChatGPT currently has some limitations:
- Relatively poor mathematical abilities: ChatGPT's mathematical skills could be better. It may confuse or provide inaccurate answers when dealing with complex mathematical problems or advanced mathematical concepts.
- Occasional generation of hallucinations: Sometimes, ChatGPT may generate hallucinations. When answering questions related to the real world, it may provide false or inaccurate information. This could be due to encountering inaccurate or misleading examples during training, leading to deviations in its answers to particular questions.
- Inability to update knowledge in real-time: ChatGPT cannot update its knowledge in real-time. It cannot continuously learn and acquire the latest information like humans do. This limits its application in fields that require timely information updates, such as news reporting or financial market analysis.
Fortunately, we can address these two limitations—generating hallucinations and the inability to update knowledge in real time—using Retrieval Augmented Generation (RAG) technology. RAG combines vector databases with the language model (LLM), and you can refer to our other articles for more information on RAG's introduction and optimization techniques.
Summary of NLP in Deep Learning
In this article, we introduce the current mainstream models and applications of deep learning, especially in NLP, starting with embeddings. From the early days of Word Embedding to the current popularity of ChatGPT, AI development has advanced rapidly. With continuous technological advancements and abundant data, we can expect even more powerful models to emerge. Deep learning applications will become more widespread, extending beyond just natural language processing to other fields such as vision and speech. With breakthroughs in technology and societal progress, we will witness more exciting advancements and innovations in the future.
 Cheney Zhang
Cheney ZhangCheney Zhang is an accomplished Algorithm Engineer at Zilliz. With a profound passion for and expertise in cutting-edge AI technologies such as LLMs and Retrieval Augmented Generation (RAG), Cheney has actively contributed to many innovative AI projects, including Towhee, Akcio, and OSSChat. Before joining Zilliz, he worked for CMB Network Technology as an Algorithm Engineer. Cheney holds a master's degree from Nanjing University of Aeronautics and Astronautics.
- What is an Embedding?
- Word2Vec
- The Rise of Transformers
- BERT and sentence embedding
- Why Embedding search works better than search based on word frequency
- Development of Large Language Models
- Summary of NLP in Deep Learning
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Mastering LLM Challenges: An Exploration of Retrieval Augmented Generation
This RAG handbook explores its advantages, the challenges it can address, & why its the preferred choice for elevating the performance of gen AI apps.

Improving Information Retrieval and RAG with Hypothetical Document Embeddings (HyDE)
HyDE (Hypothetical Document Embeddings) is a retrieval method that uses "fake" documents to improve the answers of LLM and RAG.

Top 10 RAG & LLM Evaluation Tools You Don't Want To Miss
Discover the best RAG evaluation tools to improve AI app reliability, prevent hallucinations, and boost performance across different frameworks.